이 글은 프로그래머스 - 실무 자바 개발을 위한 OOP와 핵심 디자인 패턴 강의를 정리한 내용입니다.
이번 포스팅에서는 Getter와 Setter를 활용해서 가독성 높고 유지보수 하기 좋은 코드를 작성하는 방법에 대해 알아보겠습니다.
캡슐화가 깨진 코드
CalculateCommand
public class CalculateCommand {
private CalculateType calculateType;
private int num1;
private int num2;
public CalculateCommand(CalculateType calculateType, int num1, int num2) {
if(calculateType == null) {
throw new RuntimeException("CalculateType은 필수 값 입니다.");
}
if(calculateType.equals(CalculateType.DIVIDE) && num2 == 0) {
throw new RuntimeException("0으로 나눌 수 없습니다.");
}
this.calculateType = calculateType;
this.num1 = num1;
this.num2 = num2;
}
public CalculateType getCalculateType() {
return calculateType;
}
public int getNum1() {
return num1;
}
public int getNum2() {
return num2;
}
}Client
public class Client {
public int someMethod(CalculateCommand calculateCommand) {
CalculateType calculateType = calculateCommand.getCalculateType();
int num1 = calculateCommand.getNum1();
int num2 = calculateCommand.getNum2();
int result = calculateType.calculate(num1, num2);
return result;
}
}이전 포스팅에서 if문을 제거한 코드입니다. if문이 줄어 코드의 가독성은 높아졌지만, 객체지향 관점에서 이 코드는 문제가 있습니다.
바로 CalculateCommand를 Client가 너무 잘 알고있다는 것입니다. 좀 더 구체적으로 얘기하면 CalculateCommand의 내부 필드를 Client가 너무 잘 알고 있습니다.
😵💫 그럴리가요...? 분명 내부 필드는 private으로 직접 접근하지 못하게 감추고, getter를 통해서만 값을 사용할 수 있도로 코드를 작성했는데요?
물론 private 접근 제한자와 Getter를 활용해서 내부 필드를 외부에 공개하지 않고 있는건 맞습니다. 하지만 Client는 간접적으로 CalculateCommand의 내부 필드를 알고있는 상태나 마찬가지입니다.
왜냐하면 우리가 필드의 타입이나 이름을 변경하는 경우, 혹은 해당 필드를 제거해버린다면 해당 필드를 간접적으로 사용하고 있는 Client 코드에 영향이 갈 수 밖에 없습니다.
바로 다음과 같이 말이죠!
필드를 제거한 CalculateCommand
public class CalculateCommand {
// private CalculateType calculateType; -> calculateType 필드 제거!
private int num1;
private int num2;
public CalculateCommand(CalculateType calculateType, int num1, int num2) {
if(calculateType == null) {
throw new RuntimeException("CalculateType은 필수 값 입니다.");
}
if(calculateType.equals(CalculateType.DIVIDE) && num2 == 0) {
throw new RuntimeException("0으로 나눌 수 없습니다.");
}
this.calculateType = calculateType;
this.num1 = num1;
this.num2 = num2;
}
// 필드가 제거되었으므로 해당 필드에 대한 getter 메서드도 제거!
// public CalculateType getCalculateType() {
// return calculateType;
// }
public int getNum1() {
return num1;
}
public int getNum2() {
return num2;
}
}CalculateCommand의 필드 제거로 인해 영향을 받는 Client
public class Client {
public int someMethod(CalculateCommand calculateCommand) {
// CalculateCommand에서 해당 getter 메서드를 제거해서 사용할 수 없다!
// CalculateType calculateType = calculateCommand.getCalculateType();
int num1 = calculateCommand.getNum1();
int num2 = calculateCommand.getNum2();
int result = calculateType.calculate(num1, num2); -> 해당 코드에 영향!!!!
return result;
}
}CalculateType이 제거된다고 가정하면, CalculateType을 반환하는 getter 메서드도 제거가 되어야합니다. 그리고 그 영향은 제거된 메서드를 사용하고 있던 Client 코드에 그대로 가게 됩니다.
그리고 그 영향은 다시 Client 내부에서 getter 메서드 등을 통해 받아온 calculateType을 사용하고 있는 다른 코드에도 영향을 줄 것입니다.
Client 외에 CalculateCommand에서 제공했던 getter 메서드를 사용하는 코드가 더 있다면, 그 코드들 역시 똑같이 영향을 받게되고 전부 코드를 수정해줄 수 밖에 없습니다.
이처럼 잘못된 getter 메서드 사용을 통해 간접적으로 해당 클래스의 내부 필드를 알고 있는 상태가 되는 코드는 오히려 캡슐화를 깨뜨려버립니다.
그럼 이런 문제를 어떻게 해결할 수 있을까요?
코드 수정을 통해 캡슐화 살리기
CalculateCommand 수정
public class CalculateCommand {
private CalculateType calculateType;
private int num1;
private int num2;
public CalculateCommand(CalculateType calculateType, int num1, int num2) {
if (calculateType == null) {
throw new RuntimeException("CalculateType은 필수 값 입니다.");
}
if(calculateType.equals(CalculateType.DIVIDE) && num2 == 0) {
throw new RuntimeException("0으로 나눌 수 없습니다.");
}
this.calculateType = calculateType;
this.num1 = num1;
this.num2 = num2;
}
public int getCalculateResult() {
CalculateType calculateType = this.calculateType;
int num1 = this.num1;
int num2 = this.num2;
int result = calculateType.calculate(num1, num2);
return result;
}
}Client 수정
public class Client {
public int someMethod(CalculateCommand calculateCommand) {
int result = calculateCommand.getCalculateResult();
return result;
}
}기존 CalculateCommand에 있던 getter 메서드들을 모두 제거하고, Client 내부에 있던 값 계산 로직을 CalculateCommand가 수행하도록 코드를 이동시켰습니다.
값 계산에 필요한 필드들은 모두 CalculateCommand가 자신의 내부 필드로 가지고 있기 때문에 직접 접근이 가능합니다. 따라서 자신이 가지고 있는 내부 필드들을 연산해서 결과를 반환합니다.
Client는 이제 더이상 CalculateCommand 내부에 어떤 필드가 있는지 전혀 모릅니다. 오직 getCalculateResult() 메서드만 알고 있습니다. 계산 결과는 해당 메서드가 알아서 수행하고 반환해주기를 기대하는 것 입니다. 이제 Client 코드는 getCalculateResult 메서드가 변하지 않는 이상 수정에 영향을 받지 않습니다.
지금의 수정된 CalculateCommand는 잘 캡슐화가 되어있다고 볼 수 있습니다.
😵💫 캡슐화... 캡슐화... 캡슐화는 대체 무엇을 이야기 하는 건가요...
캡슐화에 대해
캡슐화는 클라이언트 코드에게 서버 코드 정보를 숨기는 것을 의미합니다.
물론 당연하지만 모든 것을 숨길 수는 없습니다. 그러나 적어도 CalculateCommand가 내부적으로 가지고 있는 것들(field)을 보여주고 있지는 않습니다. 단지 CalculateCommand가 어떤 일을 할 수 있는지 공개하는 것 뿐입니다!
결국 모든 필드는 private이 되고, 공개하고 싶은 메서드는 public이 됩니다.
물론 생성자를 통해서는 CalculateCommand가 어떤 필드를 가지고 있는지 간접적으로 노출되기는 합니다. 그러나 생성의 경우, 제한적인 영역에서 사용이 되기 때문에 크게 문제가 되지 않습니다. 만약 생성 역시 영향을 받는 코드를 제한하고 싶다면 Factory 관련 디자인 패턴을 적용하면됩니다.
캡슐화된 코드를 다르게 표현하면 결합도는 낮추고, 응집도는 높아진 코드라고 얘기할 수 있습니다.
🤔 그럼 결합도와 응집도는 뭘 이야기하는 건가요?
결합도와 응집도
결합도
결합도에 대해서는 포스팅 초반에 소개했던 예제 코드에서 느낄 수 있습니다.
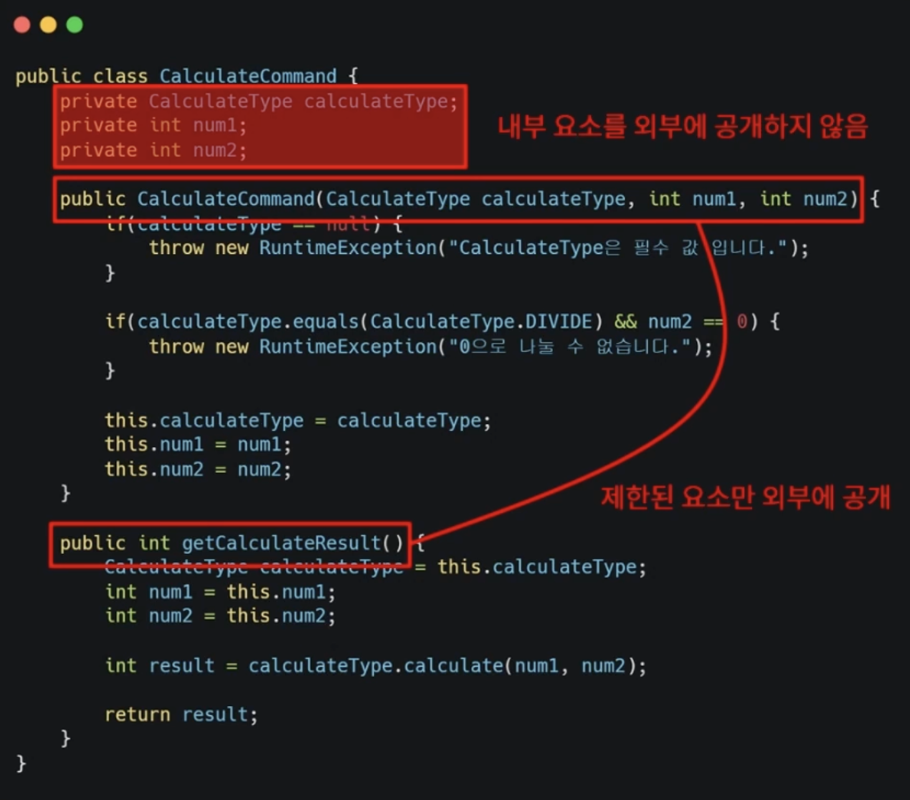
Client는 CalculateCommand의 내부 필드에 대해서 잘 알고있습니다. 따라서 Client는 CalculateCommand의 작은 변화에도 그대로 노출됩니다.
이런 상황을 Client와 CalculateCommand의 결합도가 높다고 얘기합니다. 구체적으로는 Client가 CalculateCommand에 지나치게 의존하고 있는 것 입니다.
이렇게 결합도가 높은 코드는 코드 변경을 어렵게 만들고, 한쪽에서 일어난 변경을 다른쪽으로 전파하는 문제점을 가집니다. 따라서 우리는 결합도가 낮은 코드를 만들어야합니다.
응집도
응집도는 관련 있는 것들끼리 얼마나 모여있는가?를 의미합니다.
캡슐화가 깨진 CalculateCommand
public class CalculateCommand {
private CalculateType calculateType;
private int num1;
private int num2;
public CalculateCommand(CalculateType calculateType, int num1, int num2) {
if(calculateType == null) {
throw new RuntimeException("CalculateType은 필수 값 입니다.");
}
if(calculateType.equals(CalculateType.DIVIDE) && num2 == 0) {
throw new RuntimeException("0으로 나눌 수 없습니다.");
}
this.calculateType = calculateType;
this.num1 = num1;
this.num2 = num2;
}
public CalculateType getCalculateType() {
return calculateType;
}
public int getNum1() {
return num1;
}
public int getNum2() {
return num2;
}
}캡슐화가 깨진 Client
public class Client {
public int someMethod(CalculateCommand calculateCommand) {
CalculateType calculateType = calculateCommand.getCalculateType();
int num1 = calculateCommand.getNum1();
int num2 = calculateCommand.getNum2();
int result = calculateType.calculate(num1, num2);
return result;
}
}포스팅 초반에 언급한 캡슐화가 깨진 예제 코드입니다.
CalculateCommand의 필드들은 그 필드들을 활용하여 계산 결과를 만드는 로직과 분리되어있습니다. 필드는 CalculateCommand가 가지고 있지만, 계산 로직은 Client에서 가지고 있습니다. 이런 코드가 바로 응집력이 낮은 코드입니다.
앞에서 우리는 이 로직들을 모두 CalculateCommand안에 넣어줘서 필드와 로직이 모두 CalculateCommand안에 머물도록 코드를 개선하였습니다. 같은 클래스 안에 필드와 메서드가 모여 있기 때문에 응집도가 높아졌다고 할 수 있습니다.
🔥 객체지향적인 코드는 결합도는 낮고, 응집도는 높은 코드
결과적으로 객체지향적인 코드는 결합도는 낮으면서, 응집도는 높은 코드를 의미합니다.
지금은 캡슐화를 통해 결합도와 응집도에 대해 알아보았지만, 다른 객체지향 개념들 역시 결합도는 낮추고, 응집도를 높이는 방향인건 동일합니다. 결합도가 낮고, 응집도가 높은 코드가 코드의 변경에 영향을 적게 받기 때문에, 변경에 강하다고 얘기할 수 있습니다.
따라서 그런 코드가 유지보수하기 좋은 코드라고 이야기 할 수 있습니다.
생성자와 Setter
지금까지는 Getter를 기준으로 이야기했습니다. 이번에는 생성자와 Setter를 가지고 이야기해보겠습니다.
public class CalculateCommand {
private CalculateType calculateType;
private int num1;
private int num2;
public CalculateCommand(CalculateType calculateType, int num1, int num2) {
if (calculateType == null) {
throw new RuntimeException("CalculateType은 필수 값 입니다.");
}
if(calculateType.equals(CalculateType.DIVIDE) && num2 == 0) {
throw new RuntimeException("0으로 나눌 수 없습니다.");
}
this.calculateType = calculateType;
this.num1 = num1;
this.num2 = num2;
}
public int getCalculateResult() {
CalculateType calculateType = this.calculateType;
int num1 = this.num1;
int num2 = this.num2;
int result = calculateType.calculate(num1, num2);
return result;
}
}CalculateCommand의 생성자 로직을 다음과 같이 Setter 로직으로 변경할 수 있습니다.
public class CalculateCommand {
private CalculateType calculateType;
private int num1;
private int num2;
public void setCalculateType(CalculateType calculateType) {
this.calculateType = calculateType;
}
public void setNum1(int num1) {
this.num1 = num1;
}
public void setNum2(int num2) {
this.num2 = num2;
}
public int getCalculateResult() {
CalculateType calculateType = this.calculateType;
int num1 = this.num1;
int num2 = this.num2;
int result = calculateType.calculate(num1, num2);
return result;
}
}여기서는 잠시 유효성에 대한 검사는 생략하고, 기존 생성자 로직을 Setter로 변경하면 어떤 문제가 발생할 수 있는지 생각해보겠습니다.
가장 먼저 떠올릴 수 있는건 Getter와 마찬가지로 CalculateCommand의 내부 필드가 그대로 외부에 노출된다는 문제가 있을 수 있습니다.
이것도 물론 문제지만 더 큰 문제는 불완전한 CalculateCommand의 인스턴스가 만들어진다는 것입니다.
Setter를 사용하는 CalculateCommand
public class CalculateCommand {
private CalculateType calculateType;
private int num1;
private int num2;
public void setCalculateType(CalculateType calculateType) {
this.calculateType = calculateType;
}
public void setNum1(int num1) {
this.num1 = num1;
}
public void setNum2(int num2) {
this.num2 = num2;
}
public int getCalculateResult() {
CalculateType calculateType = this.calculateType;
int num1 = this.num1;
int num2 = this.num2;
int result = calculateType.calculate(num1, num2);
return result;
}
}SetterCodeExampleMain
public class SetterCodeExampleMain {
public static void main(String[] args) {
CalculateCommand calculateCommand = new CalculateCommand();
// 실수로 아래 코드를 누락한다면?
// calculateCommand.setCalculateType(CalculateType.ADD);
calculateCommand.setNum1(100);
calculateCommand.setNum2(3);
Client client = new Client();
int result = client.someMethod(calculateCommand);
System.out.println(result);
}
}예제 코드를 살펴보면 생성자가 없기 때문에 기본 생성자로 생성된 파라미터가 없는 생성자를 사용하여 CalculateCommand 인스턴스를 생성해주었습니다. 그리고 Setter 메서드를 통해 인스턴스의 필드 값을 초기화 해주고 있습니다.
여기서 Main 코드를 작성하는 개발자가 실수로 calculateType을 초기화 해주는 코드를 누락 한다면 이 상태에서는 어떤 연산을 해야하는지 정의되어 있지 않기 때문에 계산 결과를 구할 수 없습니다. CalculateCommand가 완전히 정의되지 않았으니까요.
즉, CalculateCommand 인스턴스가 불완전한 상태로 실행이 되는 것입니다. 물론 예외가 발생한 후 수정을 할 수도 있습니다. 그리고 API 문서에 CalculateCommand는 반드시 모든 필드가 초기화 된 상태에서 사용해야한다고 기술할 수 있습니다.
그런데 이런 방법이 기존 코드처럼 모든 필드를 파라미터로 받아서 생성자로 초기화하는 것 보다 직관적인 방법일까요? 당연히 아닙니다. 모든 필드를 초기화해야하는 생성자가 있다면 코드를 작성하는 개발자는 자연스럽게 그 생성자를 사용하게 될 것입니다. 그럼 불완전하지 않은 인스턴스를 생성할 수도 있는 위험에서 자유로울 수 있습니다.
따라서 Setter 메서드를 사용하기 보다는 생성자를 적극적으로 활용하는게 더 좋은 방법입니다.
기술적인 문제로 Getter가 필요한 경우
Getter와 Setter 메서드를 지양하는 것은 객체지향적인 코드를 작성하는 좋은 방법 중 하나라고 소개하였습니다. 그러나 상황에 따라 Getter를 사용할 수 밖에 없는 경우도 있습니다.
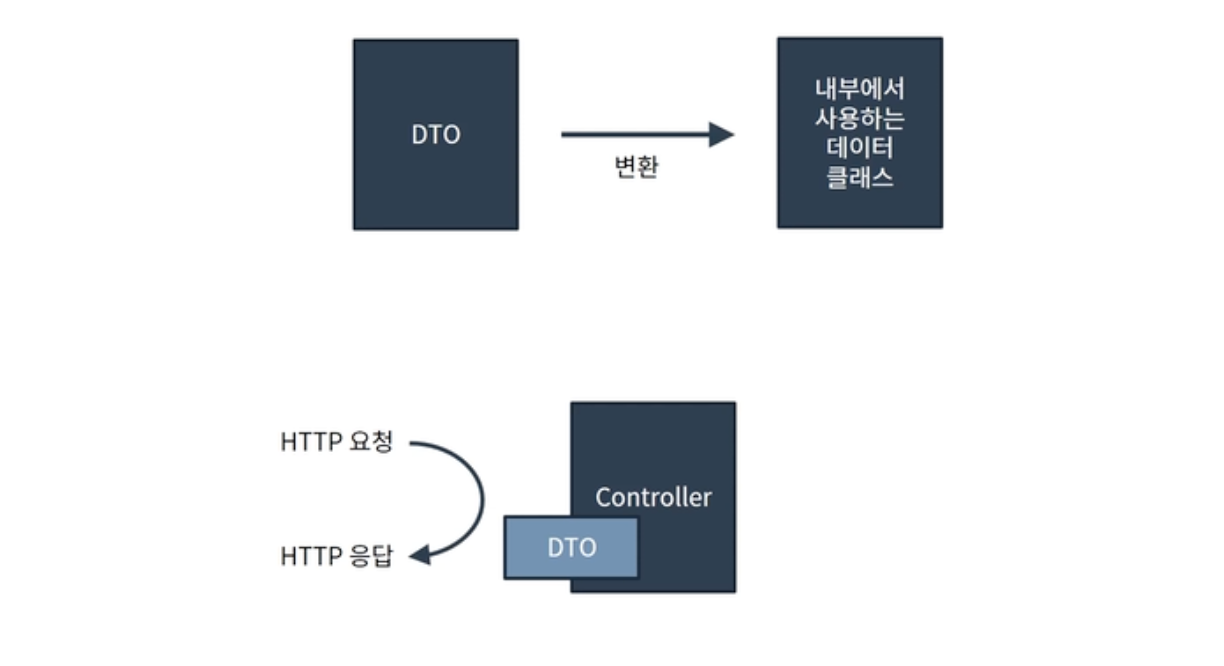
바로 내부에서 사용되는 데이터 클래스와 외부와 접점이 있는 데이터 클래스를 나눠서 사용하는 경우입니다.
대표적인 데이터 클래스 중 하나인 DTO를 예로 들어보겠습니다. 외부에서 들어오는 요청을 DTO로 받은 후 내부에서는 이 DTO를 그냥 사용하는게 아닌 별도의 내부 클래스로 변환하여 사용합니다. 변환 과정을 거칠때는 DTO 내부 값을 꺼내야 하는데, 이때 DTO의 Getter 메서드를 통해서 데이터를 꺼내야합니다.
또다른 경우는 DTO가 컨트롤러의 반환 값으로 사용되는 경우입니다. 컨트롤러는 HTTP 요청의 수신과 응답을 담당하는데, 이때 DTO를 응답 데이터로 설정하는 과정에서 DTO의 Getter 메서드를 사용합니다.
만약 DTO 내부에 Getter 메서드가 존재하지 않는다면 HTTP 응답 데이터로 변환되지 못합니다. 따라서 HTTP 응답을 의도한 대로 진행하지 못하고 이것 때문에 삽질을 하는 경우가 생길 수 있습니다.
좋은 메서드 이름
여기까지는 유지보수의 관점에서만 이야기 했고, 마지막으로 코드의 가독성에 관한 이야기도 해보겠습니다.
Getter와 Setter 메서드를 지양하는 방식은 가독성이 높은 코드를 만드는데 도움이 될 수도 있습니다.
Getter 메서드를 사용하는 Client
public class Client {
public int someMethod(CalculateCommand calculateCommand) {
CalculateType calculateType = calculateCommand.getCalculateType();
int num1 = calculateCommand.getNum1();
int num2 = calculateCommand.getNum2();
int result = calculateType.calculate(num1, num2);
return result;
}
}Getter 메서드를 지양하는 Client
public class Client {
public int someMethod(CalculateCommand calculateCommand) {
int result = calculateCommand.getCalculateResult();
return result;
}
}첫 번째 코드는 'CalculateType이랑 num1, num2를 가져와서 뭔가 로직을 실행하고...'의 과정에서 그 실행하는 로직을 파악하려면 코드를 열심히 읽어보면서 분석해야 이해할 수 있습니다.
하지만 두 번째 코드는 Client의 코드만으로 '해당 코드는 계산 결과를 가져오는 코드'라는걸 메서드명을 통해 빠르게 유추할 수 있습니다. 따라서 상대적으로 코드의 가독성이 더 올라갈 수 있습니다.
물론 지금이야 두 코드 모두 라인수도 짧고 복잡한 로직이 아니라서 크게 체감이 오지 않을 수 있습니다. 하지만 실무에서 마주치는 코드는 비교할 수 없을 정도로 복잡하고 긴 코드가 많고, 여기서 잘 작명한 이름을 가진 메서드는 코드의 가독성을 크게 향상시켜줍니다.
마무리
지금까지 Getter & Setter를 중심으로 이야기했지만, 그 본질은 캡슐화와 결합도, 그리고 응집도에 대한 내용임을 명심해야 합니다.
