2021 NIPA AI 온라인 실무 응용 교육과정
딥러닝 시작하기 과정 용어, 플로우 정리
-
딥러닝이란?
머신러닝의 여러 방법론 중 하나.
인공신경망에 기반하여 컴퓨터에게 사람의 사고방식을 가르치는 방법 -
인공신경망이란?
생물학의 신경망에서 영감을 얻은 학습 알고리즘 사람의 신경 시스템을 모방함<참고>
딥러닝의 역사
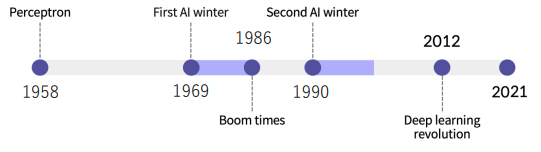
-
퍼셉트론
퍼셉트론은 각각의 노드에서 가중치와 입력치를 모두 더한 값이 활성함수에 의해 판단하는 방법으로 동작한다. 만약 값이 임계값을 넘어가면 결과값이 1이 출력된다.(뉴런의 활성화)<활성화 함수>
활성화 함수(Activation function)는 입력된 DATA의 가중치의 합계를 OUTPUT 신호로 바꿔주는 함수. 활성화 여부는 이전 레이어에 대한 가중합의 크기에 따라 결정됨.<딥러닝 모델 구성요소>
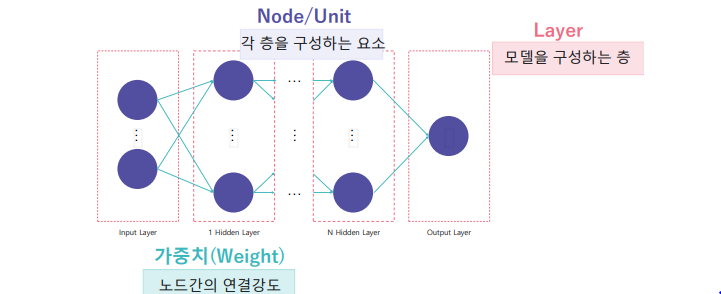
- 경사하강법
경사 하강법(Gradient descent)
딥러닝 모델의 학습 방법 중 하나
가중치를 Loss function 값이 작아지게 업데이트 하는 방법
가중치는 Gradient 값을 사용하여 업데이트를 수행함
Gradient 값은 각 가중치 마다 정해지며,
역전파(Backpropogation)를 통하여 구할 수 있음
<딥러닝 모델의 학습 순서>
1. 학습용 feature 데이터를 입력하여 예측값 구하기 (순전파)
2. 예측값과 실제값 사이의 오차 구하기 (Loss 계산)
3. Loss를 줄일 수 있는 가중치 업데이트 하기 (역전파)
4. 1~3번 반복으로 Loss를 최소로 하는 가중치 얻기
<딥러닝 모델 구현 순서>
텐서플로우로 딥러닝 구현하기
1. 데이터 전 처리하기
2. 딥러닝 모델 구축하기
3. 모델 학습시키기
4. 평가 및 예측하기
- 텐서플로우
Tensorflow 딥러닝 모델은 Tensor 형태의 데이터를 입력 받는다.
Tensor란 다차원 배열로서 tensorflow에서 사용하는 객체
코드1)
#pandas를 사용하여 데이터 불러오기
df = pd.read_csv(‘data.csv’)
feature = df.drop(columns=[‘label’])
label = df[‘label’]
#tensor 형태로 데이터 변환
dataset = tf.data.Dataset.from_tensor_slices((feature.values, label.values)
코드2)
model = tf.keras.models.Sequential
([
tf.keras.layers.Dense(10, input_dim=2, activation=‘sigmoid’),
#2개의 입력 변수, 10개의 노드
tf.keras.layers.Dense(10, activation=‘sigmoid’), # 10개의 노드
tf.keras.layers.Dense(1, activation='sigmoid’), # 1개의 노드
])
model = tf.keras.models.Sequential()
model.add(tf.keras.layers.Dense(10, input_dim=2, activation=‘sigmoid’))
model.add(tf.keras.layers.Dense(10, activation=‘sigmoid’))
model.add(tf.keras.layers.Dense(1, activation='sigmoid’))
- 이미지 처리를 위한 데이터 전 처리
이미지 처리를 위한 딥러닝 모델 :
합성곱 신경망(Convolution Neural Network)
- 피쳐맵의 크기 변형 Padding, Striding
- Pooling Layer
- 분류를 위한 Softmax 활성화 함수
- Convolution Layer 는 특징을 찾아내고, Pooling Layer 는 처리할 맵(이미지) 크기를 줄여줌. 이를 N 번 반복함. 반복할 때마다 줄어든 영역에서의 특징을 찾게 되고, 영역의 크기는 작아졌기 때문에 빠른 학습이 가능해짐.
- 자연어 처리를 위한 데이터 전 처리 :
- 토큰화(Tokenizing)
예제)
“딥러닝 기초 과목을 수강하고 있습니다.”
=> ['딥', '러닝', '기초', '과목', '을', '수강', '하고', '있습니다', '.']
문장을 토큰(Token)으로 나눔,
토큰은 어절, 단어 등으로 목적에 따라 다르게 정리
- 불용어 제거(StopWord removal)
stopword 예시) 아, 휴, 아이구, 아이쿠, 아이고, 쉿, 그렇지 않으면, 그러나, 그런데, 하지만, ...
불필요한 단어를 의미하는 불용어(StopWord) 제거 - Bag of Words , 토큰 시퀀스
- 자연어 처리를 위한 딥러닝 모델 자연어 분류를 위한 순환 신경망(Recurrent Neural Network)
