이 글은 Reddit에 올라온 Data Version Control 1.0 release. 5 lessons from 3 years of building open-source ML tool.을 공부하면서 정리한 글입니다.
Overview
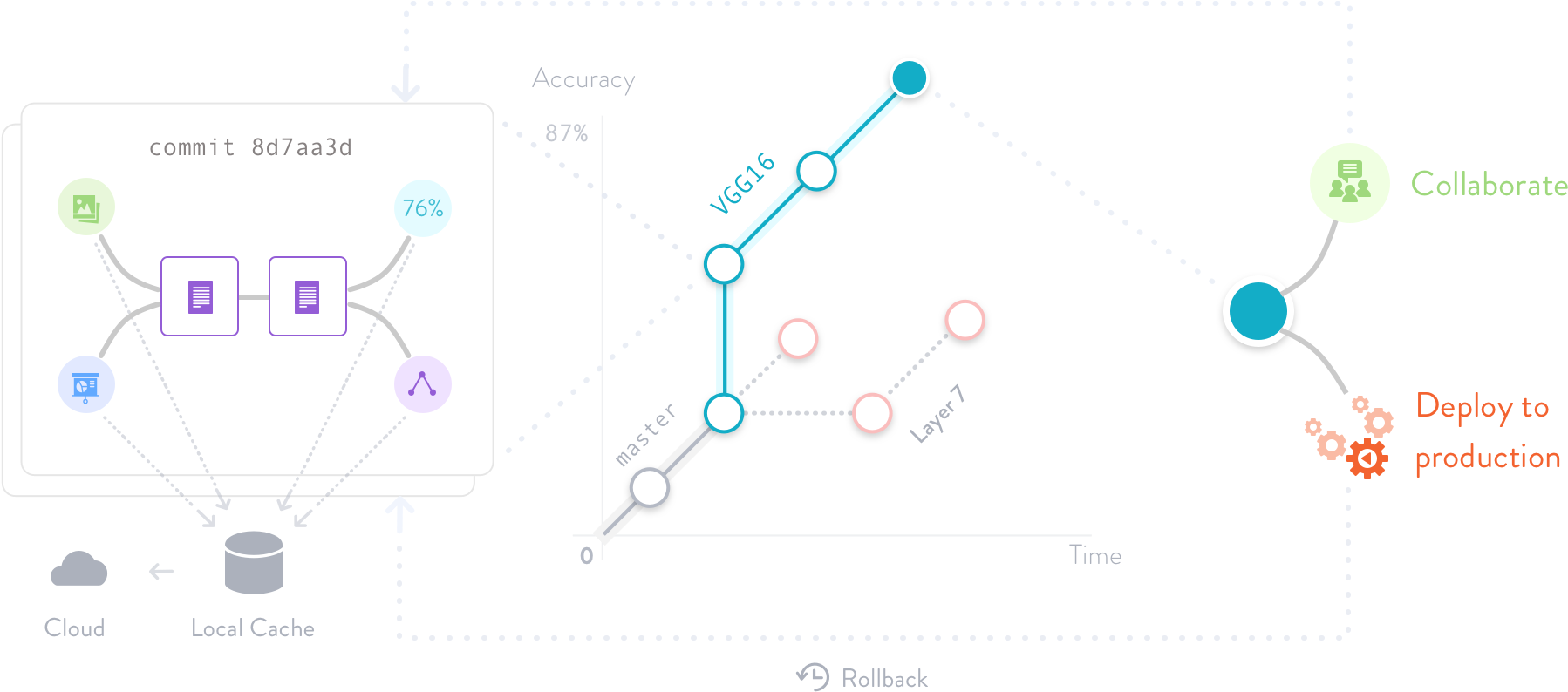
Data Version Control 은 데이터 프로젝트의 Git으로 알려져있습니다. 기술적으로 DVC는 Git이 실질적인 버저닝을 하듯 데이터와 머신러닝 파이프라인을 텍스트 메타파일로 기술합니다(with pointers to actual data in S3/GCP/Azure/SSH). DevOps하는 분들은 이를 GitOps라고 부르거나 DataOps 또는 MLOps라고 부르기도 하지요.
3년 전부터 우리는 1.0 버전을 위해서 달려왔습니다. 저의 개인적인 프로젝트는 이제 100명이 넘는 코드 기여자들과 함께하고 있으며, 100명이 넘는 문서 기여자 그리고 수천 명의 유저와 함께하게 되었습니다.
커뮤니티는 우레엑 많은 것을 가르쳐주었습니다. 그 중 몇가지 중요한 가르침은 다음과 같습니다.
-
사용자들은 서버리스하고 분산환경의 특성이 DVC가 가진 최고의 기능("killer features")이라고 이야기했습니다.
-
팀 내에서 ML 프로젝트를 공유할 때, 파일과 파이프라인만 고려하는 것은 충분하지 않습니다. 메트릭, 플롯 그리고 하이퍼파라미터 또한 추적해야 할 필요성이 있습니다. 우리는 DVC 1.0에서 Git의 역사를 따라 hyper-parameter diffs, metrics and plot diffs를 시행했습니다.
-
DataOps에서 데이터 전송 최적화(data transfer optimization)는 엄청난 일입니다. 커다란 딥러닝모델, 수백 만 장의 이미지가 있는 데이터셋 등등... 우리는 더 끈질기게 optimizing 1.0을 만들었습니다.
-
ML 파이프라인은 데이터 엔지니어링 파이프라인보다 빠르게 발전하고 있으며, 쉽게 변화를 적용할 수 있어야 합니다. 1.0에서 우리는 파이프라인 메타파일 포맷을 간략하게 만들었습니다.
-
많은 팀이 DVC를 ML을 위한 CI/CD 파트에서 사용합니다. DVC는 Continuous Delivery for Machine Learning (CD4ML)의 심장부에서 사용되고 있습니다. 이에 대한 자세한 설명은 Martin Fowler의 블로그에 자세히 기술되어 있습니다. 우리는 1.0을 CI/CD 유저들을 생각하며 만들었습니다.
더 자세한 내용들은 홈페이지를 참조하세요.
궁금한 점이 있다면 저희 디스코드에 함께하셔도 좋습니다.
Original Text
Data Version Control (https://dvc.org/) is known as Git for data projects. Technically, DVC codifies your data and machine learning pipelines as text metafiles (with pointers to actual data in S3/GCP/Azure/SSH) while you use Git for the actual versioning. DevOps folks call this approach GitOps or more specifically in this case - DataOps or MLOps.
We’ve been working towards 1.0 since we started 3 years ago. What began as my pet project now has 100+ code contributors, 100+ documentation contributors, and thousands of users.
Our community has taught us a lot - here are some of the biggest lessons:
Users say the serverless and distributed nature of DVC (inherited from the underlying Git) is one of its "killer features".
To share ML projects within and between teams, it’s not enough to track only files and pipelines. You also need metrics, plot and hyperparameter tracking. In DVC 1.0 we implemented hyper-parameter diffs, metrics and plot diffs right from Git history.
In DataOps, data transfer optimization is huge. Large deep learning models, millions of images in datasets, etc. We doubled down on optimizing 1.0.
ML pipelines evolve faster than data engineering pipelines and need to be easy to change. In 1.0, we’ve simplified the pipeline metafile format.
More and more teams use DVC as a part of CI/CD for ML. DVC is used under the hood in the CD4ML tool that was described in the canonical post on Martin Fowler’s blog: https://martinfowler.com/articles/cd4ml.html. We built 1.0 with CI/CD users in mind.
More details on https://dvc.org/blog/dvc-1-0-release.
Happy to answer any questions here or at DVC Discord chat - https://dvc.org/chat.
