24.01.28 최초 작성
1. Topdown approach (Intel)
PMU (Performance Monitoring Unit): cpu가 수행하는 작업에 대한 기록을 담당하는 HWPerf Topdown approach: Intel cpu의 성능 분석 방법론으로 병목현상을 찾아내는데 유용
-
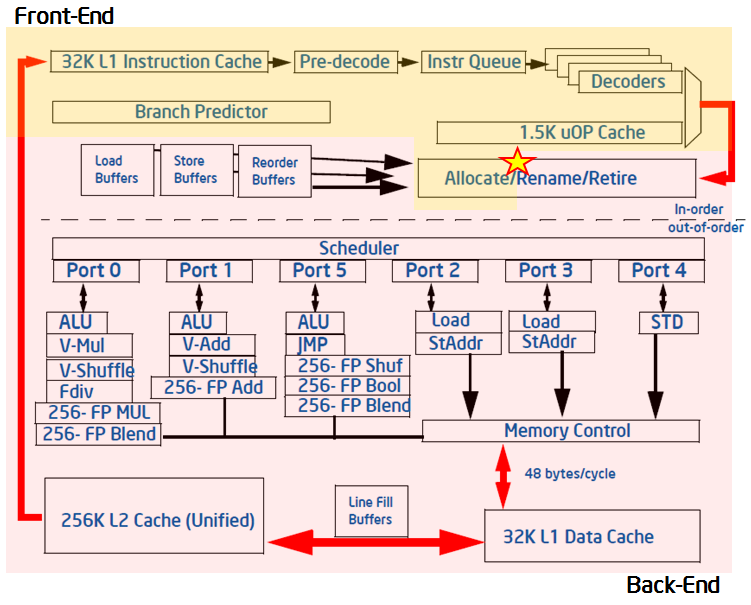
Front end영역에서scheduler에 명령을 전달하면scheduler가 알아서 이를 동작시킴 -
In-order,Out-of-order: 순서대로 / 순서에 상관없이 명령어 실행 -
Front-end: 메모리에서 명령을 가져와 해석하고uOP단위로 쪼개scheduler로 전달
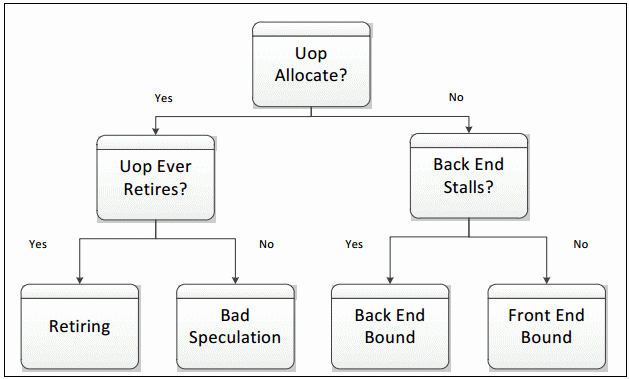
categorization
-
Front End Bound:Front end에서 병목현상 발생
(명령어fetch,decode에서 병목현상 발생) -
Back End Bound:Back end에서 병목현상 발생
(명령어 실행, 메모리 접근 과정에서 병목현상 발생) -
Bad Speculation: 실행될 명령어 예측이 틀렸는데 이를 실행하려고 할 때 발생 -
Retiring: 정상적으로 실행 중
1.1 Frontend bound
-
Fetch Latency: 명령어 인출에 걸리는 시간이 느려 성능에 영향ITLB Miss: 명령어TLB에서 miss가 발생하는 경우iCache Miss: 명령어cache에서 miss가 발생하는 경우Branch Resteers: 명령어 분기 예측에 실패해 파이프라인이 초기화되는 경우
-
Fetch Bandwidth: 한번에 가져올 수 있는 명령어의 최대 갯수에 막혀 성능에 제한 발생Fetch src1,Fetch src2: 하나의 명령어 인출이 두 cpu에 동시에 실행될 시 인출이 번갈아가며 발생해 성능에 영향이 가는 경우- 코드가 runtime에 동적으로 결정되는 경우
- 너무 많은 가상 메모리를 사용해
page mapping을 커버할 수 없는 경우
...
1.2 Bad Speculation
-
Branch miss predicts: 명령어 분기 예측이 실패하는 경우 (복잡한 조건문, 메모리 접근에 의해 발생) -
Machine clears:
1.3 Backend bound
Core Bound: cpu의 한계에 의해 연산처리가 지연Divider: 나눗셈 연산에 의해 지연이 발생Execution ports Utilization: 특정 실행 포트에 작업이 집중되는 경우 발생
Memory Bound: 메모리의 한계에 의해 메모리의 접근이 지연Stores bound: 메모리의 저장 연산에 의해 지연이 발생L1,L2... :cache의 miss나 공유 문제에 의해 지연이 발생Dram: 외부 메모리에 의해 지연 발생
1.4 Retiring
-
Base: 기본 명령이 정상적으로 실행 됨Floating Point arithmatic
-
Micro Sequencer: 마이크로코드를 통해 구현한 코드가 정상적으로 실행 됨
2. pmu-tools
./toplev [—force-cpu [cpu arch]] -l1 --per-socket --interval 5 -v
# - level1 까지의 내용을 cpu단위로
# 5초 간격으로 자주 보여줌
> Frontend bound, Bad Speculation, Backend bound, Retiring의 비율 보여 줌3. 예제
#include <stdio.h>
#include <stdlib.h>
#include <time.h>
int get_random_value() {
return rand();
}
int unpredictable_branch() {
if (get_random_value() > RAND_MAX / 2) {
return get_random_value() * 2;
} else {
return get_random_value() / 2;
}
}
void invoke_branches() {
int result = 0;
srand(time(NULL));
for (int i = 0; i < 1000000; i ++){
result += unpredictable_branch();
}
printf("Result : %d \n", result);
}
int main() {
invoke_branches();
return 0;
}#include <stdio.h>
int main() {
int sum = 0;
for (int i = 0; i < 10000000; ++i){
sum += i;
}
printf("Sum : %d \n", sum);
return 0;
}#include <stdio.h>
int fib(int n) {
if(n <= 1)
return n;
else
return (fib(n-1) + fib(n-2))
}
int main() {
int n = 40;
printf ("Fibonacci number : %d \n", fib(n));
return 0;
}4 Perf + Flamegraph
git clone https://github.com/brendangregg/FlameGraph
perf record -g l
perf script | stackcollapse-perf.pl | flamegraph.pl > output.svg