참고한 링크
https://jojoldu.tistory.com/493
https://abbo.tistory.com/267
https://docs.spring.io/spring-batch/docs/current/reference/html/scalability.html#scalability
https://backtony.github.io/spring/2022-01-29-spring-batch-11/
병렬화
일반적으로 스프링 배치는 단일 스레드에서 실행된다
따라서 모든 것이 순차적으로 실행되는데, 이를 병렬화 할 수 있다.
배치 스텝을 병렬화하는 방법에는 다중스레드 스텝을 통한 작업 분할, 전체 스텝의 병렬 실행, 비동기 ItemProcessor,ItemWriter 구성, 원격 청킹, 파티셔닝 이 다섯 가지의 방법이 있다
다중 스레드 스텝
Spring batch의 멀티쓰레드 Step은 Spring의 TaskExecutor를 이용해서 각 스레드가 chunk단위로 실행되게 하는 것
주의사항
- 멀티쓰레드 환경이 되기 위해서는 Reader 와 Writer가 thread-safe 한 상태인지 먼저 체크해주기 -> Reader의 read에 synchronized를 걸어야 한다, 이렇게 되면 Reader가 동기화 방식이 되지만 그래도 Processor/Writer가 멀티쓰레드로 작동한다
- 순차적으로 chunk 실행이 아니다보니 실패 지점에서 재시작이 불가능
병렬 스텝 처리
Flow 객체를 활용한다
Flow?
Step을 순차적으로만 구성하는 것이 아닌 상태에 따라 흐름을 전환하도록 구성할 수 있다.
Flow는 병렬처리 외에도 Step이 실패하더라도 Job은 실패로 끝나면 안되는 경우나 Step이 성공할때와 실패했을 때를 구분해서 다음 작업을 해야하는 경우 등 step을 컨트롤할때도 쓰인다.
sampleParallelJob은 최초 parallelStepFlow라는 것을 호출하고
parallelStepFlow는 add()를 통해 합쳐진 flow들을 병렬처리하겠다고 선언한다.
@Beanpublic
Job sampleParallelJob(Step sampleParallelStep1, Step sampleParallelStep2, Step sampleParallelStep3, Step sampleParallelStep4) {
Flow flow1 = new FlowBuilder<Flow>("flow1")
.start(sampleParallelStep1)
.next(sampleParallelStep4)
.build();
Flow flow2 = new FlowBuilder<Flow>("flow2")
.start(sampleParallelStep2)
.build();
Flow flow3 = new FlowBuilder<Flow>("flow3")
.start(sampleParallelStep3)
.build();
Flow parallelStepFlow = new FlowBuilder<Flow>("parallelStepFlow")
.split(new SimpleAsyncTaskExecutor())
.add(flow1, flow2, flow3)
.build();
return
jobBuilderFactory.get("sampleParallelJob")
.start(parallelStepFlow)
.next(sampleParallelStep1)
.build()
.build();}비동기 ItemProcessor,ItemWriter
어떠한 사례에서는 ItemProcessor에 병목현상이 발생할 수 있다
위와 같은 사례에서 일부 step을 병렬화한다
step 안에서 ItemProcessor가 비동기적으로 동작하게 한다
SynchonousItemProcessor 는 ItemProcessor 가 호출될 때마다 같은 스레드에서 실행하게 만들어주는데 AsynchonousItemProcessor 는 ItemProcessor호출 결과를 반환하는 대신 각 호출에 대해 Future을 반환한다
청크 내에서 반환된 Future 목록은 AsynchonousItemWriter로 전달되어서 ItemWriter에 전달한다

사실 여기까지의 방법은 단일 JVM에서 실행되기 때문에 확장성의 한계가 있다
이후 2가지의 방법은 여러 JVM에서 분산 처리가 가능하다
원격 청킹
마스터 노드에서 표준 ItemReader를 사용
지속 가능한 통신 형식 (rabbitMQ와 같은 메세지 브로커)를 통해 메세지 기반 POJO로 구성된 원격 워커 ItemProcessor로 전송한다
처리가 완료되면 워커는 업데이트된 아이템을 다시 마스터로 보내거나 직접 기록한다
네트워크 사용량이 많아진다는 문제가 있긴 하다 (실제 처리에 비해 IO 비용이 적은 시나리오에 적합)
파티셔닝
MasterStep이 SlaveStep을 실행시키는 구조
SlaveStep은 각 스레드에 의해 독립적으로 실행된다
SlaveStep은 ItemReader / ItemProcessor / ItemWriter 등을 갖고 동작하며 작업을 독립적으로 병렬 처리한다
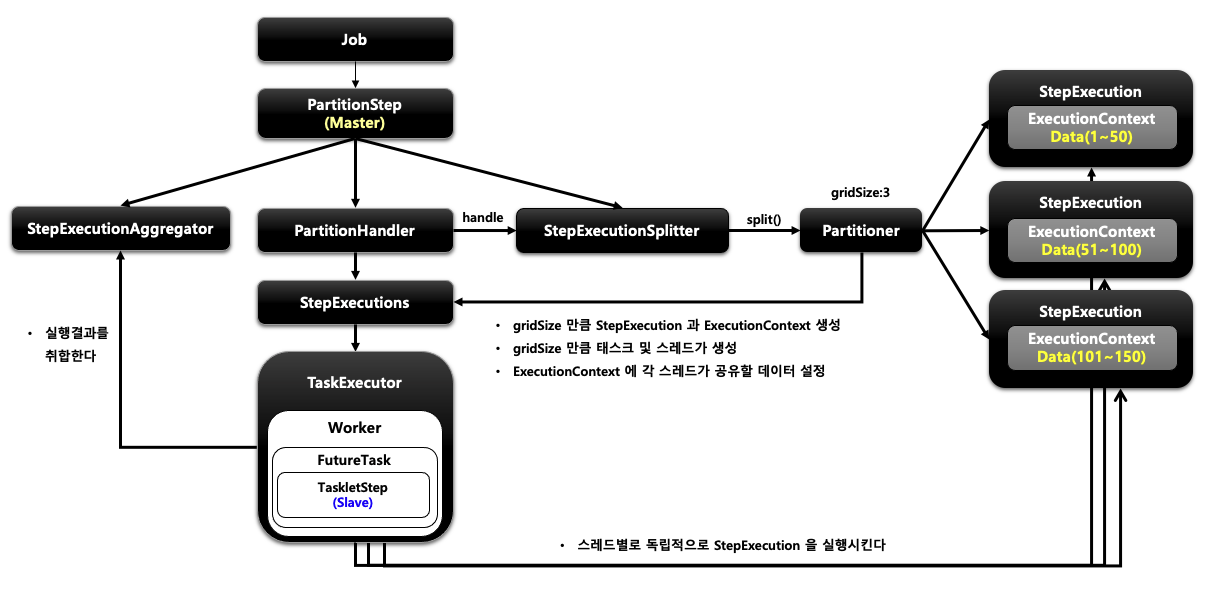
MasterStep에서 Partitioner가 gridSize 만큼 StepExecution을 만들고 각 StepExecution의 ExecutionContext 안에 데이터 정보를 넣어둔다.
그리고 gridSize 만큼 스레드를 생성해서 SlaveStep을 각 스레드별로 실행시킨다.
결국 각 스레드는 같은 SlaveStep을 실행하지만 서로 다른 StepExecution 정보를 가지고 수행한다
서로 다른 StepExecution 정보를 갖는다는 것은 결국 서로 작업 scope가 다르다는 이야기이고 따라서 각 스레드마다 타겟 빈을 새로 만들기 때문에 서로 다른 타겟 빈을 바라보게 되어 동시성 이슈가 없다.
