Summarize Model - 이론
Summarize Model과 프로젝트
개발 구현 진행 중에 있는 프로젝트는 학습지원을 카테고리로 강의록이나 학습자료 파일을 입력 받았을 때 그것의 요약본과 문제파일(내용을 바탕으로 질문과 정답 제공)을 제공해주는 프로젝트이다.
프로젝트가 주로 제공하고자 하는 기능이 요약인 만큼 Summarize Model을 활용해서 주어진 텍스트를 요약한 뒤 결과값을 제공하고자 한다.
Summarize Model 소개
생성요약과 추출요약
문서 요약의 방법에는 생성요약(Abstractive summary)과 추출요약(Extractive Summary)이 있다.
보조금 집행 위법행위·지적사례 늘어 특별감사반, 2017~2018년 축제 점검 충주시가 민간에게 지원되는 보조사업의 대형축제와 관련해 선정·집행·정산 등 운영실태 전반에 대한 자체 감사를 실시할 계획이라고 밝혔다. 이는 최근 민간보조사업의 증가와 더불어 보조금 집행관리에 대한 위법 부당 행위와 지적사례가 지속적으로 증가함에 따라, 감사를 통해 취약요인을 점검해 올바른 보조금 사용 풍토를 정착시키겠다는 취지다. 시는 감사담당관실과 기획예산과 보조금 관련 주무관으로 특별감사반을 편성해 2017년부터 2018년까지 집행된 축제성 보조금 집행에 대한 철저한 점검과 감사를 통해 부정 수급 및 부정 집행이 확인되면 엄정한 조치를 취할 방침이다. 시는 지난 15일부터 25일까지 10일간의 사전감사를 통해 보조금 실태를 파악한 후, 8월15일까지 세부감사를 진행할 예정이라고 전했다. 축제성 관련 부정수급 유형을 보면 허위·기타 부정한 방법으로 보조금 신청, 사업 실적을 부풀려 보조금을 횡령·편취, 보조금 교부 목적과 다른 용도로 집행, 보조금으로 취득한 재산에 대해 지자체장의 승인없이 임의 처분 등이 해당된다. 시는 불법보조금 근절과 효율적인 점검 및 적극적인 시민관심을 유도하기 위해 '지방보조금 부정수급 신고센터(☏850-5031)'를 설치 운영하고 있다. 지방보조금 부정수급 신고 시 직접방문 및 국민신문고(www.epeople.or.kr), 충주시홈페이지(www.chungju.or.kr)를 통해 접수하면 되고, 신고취지와 이유를 기재하고 부정행위와 관련한 증거자료를 제시하면 된다. 단, 익명 신고는 접수치 않는다. 시 관계자는 "이번 자체 점검 및 감사를 통해 축제보조금이 제대로 쓰이는지에 대한 반성과 함께 보조금 집행의 투명성 및 행정의 신뢰성을 확보하는데 최선을 다하겠다"고 말했다. 한편 시는 감사 및 예산부서 합동으로 컨설팅 위주의 상반기 보조금 특정감사(1월10일~20일)를 실시해 주의 11건, 시정 6건, 권고 1건을 자체 적발하고 조치한 바 있다.
기사 출처: 충청투데이
다음의 기사를 예시로 생성요약과 추출요약에 대해 설명하려고 한다.
생성요약
생성요약은 요약하고자 하는 문서를 구성하는 문장 속 토큰 간의 관계를 파악해서 해당 문서에는 존재하지 않는 새로운 요약문을 생성하는 기술이다.
위의 예시 기사문을 활용해서 생성요약을 하면 다음과 같은 결과를 얻을 수 있다.
충주시는 민간보조사업의 증가와 보조금 집행관리에 대한 부당 행위가 증가함에따라 15일부터 25일까지 보조금 실태를 파악한 후 8월15일까지 세부감사를 진행, 운영실태 전반에 대한 자체 감사를 실시할 계획이라고 밝혔다.
생성요약문 출처: AI hub 문서요약 텍스트
원문 기사와 비교해보면 확인할 수 있듯이 원문에 포함되지 않는 새로운 문장이 요약문으로 생성되었다.
추출요약
추출요약은 요약하고자 하는 문서에 포함된 문장을 추출해서 요약문을 추려내는 기술이다.
이 때 추출요약은 토큰 간의 관계를 파악해서 각 문장의 중요도를 계산한 뒤 중요도가 높은 순으로 문장을 뽑아낸다.
위의 예시 기사문을 활용해서 추출요약을 하면 다음과 같은 결과를 얻을 수 있다.
충주시가 민간에게 지원되는 보조사업의 대형축제와 관련해 선정·집행·정산 등 운영실태 전반에 대한 자체 감사를 실시할 계획이라고 밝혔다. 시는 감사담당관실과 기획예산과 보조금 관련 주무관으로 특별감사반을 편성해 2017년부터 2018년까지 집행된 축제성 보조금 집행에 대한 철저한 점검과 감사를 통해 부정 수급 및 부정 집행이 확인되면 엄정한 조치를 취할 방침이다.
추출요약문 출처: AI hub 문서요약 텍스트
원문기사와 비교했을 때 원문 기사의 3,5번째 문장이 추출요약문으로 추출된 것을 확인할 수 있다.
이번 프로젝트에서는 구현이 비교적 간단하고 가벼운 문장단위의 추출요약 을 목표로 하고 있다.
본래 텍스트 요약 성능 평가는 ROUGE Model을 활용하지만 문장단위의 추출요약을 하는 model을 개발하고자 하기 때문에 문장 속 단어나 bigram을 분석할 필요가 없어 본 과정은 생략하기로 했다.
→ 성능 평가에 대한 부분을 추후에 더 고민해봐야 할 것 같다.
데이터 수집
Bert Model : Bert fine-tuning을 위해 pre-trained BERT Model이 필요하다. 이에 따라 ETRI(한국전자통신연구원)에서 배포한 형태소 기반 한국어 언어모델인 파이토치 프레임워크를 사용한 형태소 기반 모델을 사용하기로 했다. 본 Bert Model은 여기서 신청하여 받을 수 있다.
데이터 : fine-tuning을 위한 훈련 데이터 셋은 AI hub 문서요약 텍스트 데이터를 활용한다. 해당 데이터는 뉴스기사의 원문, 추출요약의 문장 번호 index 배열을 제공해준다.
이외에도 다양한 강의자료나 학습자료를 활용해서 추출요약 참조 요약문을 직접 labeling 하여 추출요약의 문장번호를 index 배열 형태로 제공할 예정이다.
전처리
1)BERT Model input 데이터 생성
본 프로젝트에서 활용할 BERT모델은 앞서 설명한 바와 같이 형태소 기반 BERT 모델이다. 따라서 BERT 모델의 인풋으로 들어갈 파일은 형태소 분석이 되어야 한다.
우리는 형태소 분석 API를 활용해서 형태소 분석 인풋을 넣어주기로 했고 활용한 API는 ETRI 형태소 분석 API이다.
이 과정은 보다 자세하게 다음링크 에서 다루고 있다.
2)Embedding
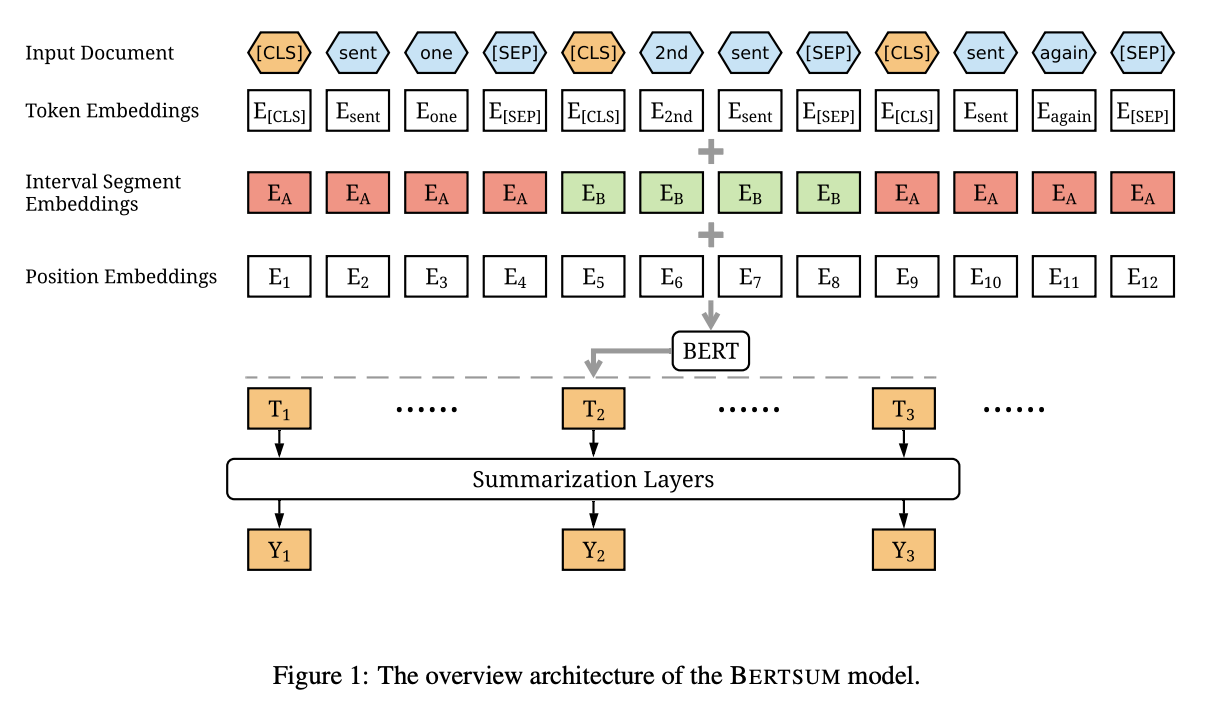
BERT input에는 token embedding, segment embedding, position embedding 이렇게 세 가지 임베딩이 있다.
우선 위에서 형태소 분석한 내용에서 추가로 문장의 시작과 끝을 표시하는 토큰이 필요하다. 따라서 각 문장마다 문장의 시작에 [CLS], 문장의 끝에 [SEP] 토큰을 넣어서 문장단위를 구분해준다.
Token Embedding
이 과정은 나눠진 토큰을 BERT index로 바꾸어주는 과정이다. 앞의 형태소 분석+ 문장 나누기로 나눠진 토큰은 ETRI-BERT 모델에 단어/형태소 쌍의 인덱스가 저장된 BERT 사전을 활용해서 BERT index로 바꾸어준다.
Segment Embedding
이 과정은 홀수 번째 문장을 0, 짝수 번째 문장을 1로 해서 문장 간의 순서와 관계를 BERT 모델이 파악할 수 있도록 하는 과정이다.
Position Embedding
토큰 임베딩 직전에 사용했던 [CLS]토큰 (문장의 시작을 나타내는 토큰)의 포지션값을 저장해주어서 문장의 index값을 저장한다.
학습
ETRI 에서 받은 형태소 기반 BERT MODEL에 앞서 전처리한 파일을 넣어 모델 학습을 한다.
BERT Model은 비지도 학습 모델 이기 때문에 데이터 자체를 이해하고 공부하는 과정만을 거친다.
fine-tunning layer인 Summarization layer를 encoder로 활용해서 추가적으로 요약기능과 관련된 학습을 할 수 있도록 구현해야 한다.
이 부분은 추후에 구체적으로 구현할 예정이다.

잘 읽었어요~ 김현수교수