
문제
int형 배열 nums가 주어졌을 때 임의의 i번째 인덱스의 원소와 i-k <= j <= i+k를 만족하는 j번째의 원소 중 같은 원소가 있다면 true를 리턴하고 없으면 false를 리턴한다.
첫번째 풀이
이 문제는 이중 반복문으로 쉽게 해결할 수 있다. i번째 인덱스를 기준으로 j = i+1 ~ i+k 반복하면서 동일한 원소가 있으면 true를 리턴한다.
class Solution {
public boolean containsNearbyDuplicate(int[] nums, int k) {
for (int i = 0; i < nums.length; i++) {
int end = Math.min(nums.length, i + k + 1);
for (int j = i + 1; j < end; j++) {
if (nums[i] == nums[j]) {
return true;
}
}
}
return false;
}
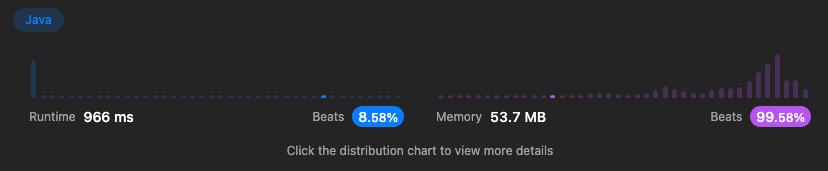
}공간복잡도는 을 갖지만 시간복잡도가 이라는 굉장히 안좋은 성능을 갖게 된다. 물론 Accepted가 되긴하지만 실행시간이 966ms로 굉장히 느리다.
두번째 풀이
이 문제는 기준(key)를 원소의 값으로 하고 값(value)를 가장 최근의 인덱스로 정의하고 풀이할 수 있다. 그러면 에서 로 만들 수 있게 된다. 저번에 풀었던 RansomNote는 기준이 되는 문자를 인덱스(int)로 표현할 수 있어 배열로 해결할 수 있었다. 이 문제의 원소의 범위가 -10억 ~ +10억 사이로 모든 원소에 10억을 더해 양수로 만들어도 int형을 넘지는 않아 인덱스로 활용할 수 있다.
하지만 이 문제는 배열로 해결하기 어렵다. 배열은 생성과 동시에 길이를 초기화해야하는데 모든 원소를 인덱스로 정한다면 20억 길이의 int형 배열이 만들어야한다. 그렇게되면 int형 배열의 메모리는 약 8GB라는 메모리를 필요로 하기 때문에 배열로는 해결하기 어렵다.
따라서 key를 원소의 값으로 하고 value를 key의 가장 최근 인덱스로 정의한 HashMap을 사용해 풀 수 있다. 이렇게 되면 nums.length <= 10^5으로 HashMap에 최대 10만개까지 저장되므로 메모리 문제를 해결할 수 있게된다.
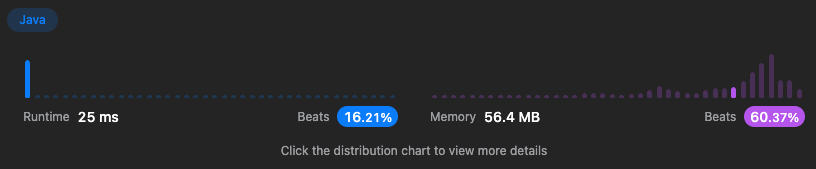
HashMap으로 풀이하면 시간복잡도는 으로 줄일 수 있지만 공간복잡도는 으로 증가된다. 하지만 시간복잡도가 개선되어 더 뛰어난 성능을 기대할 수 있다.
class Solution {
public boolean containsNearbyDuplicate(int[] nums, int k) {
Map<Integer, Integer> indexs = new HashMap<>();
for (int i = 0; i < nums.length; i++) {
int recentIndex = indexs.getOrDefault(nums[i], -100001);
if (i - recentIndex <= k) {
return true;
}
indexs.put(nums[i], i);
}
return false;
}
}
Solution을 보고 개선하기
두번째 풀이에서 시간복잡도를 으로 줄여 첫번째 풀이보다 약 940ms로 개선했지만 여전히 하위 실행속도에 속한다. 나는 두번째 풀이에서 더 개선할 방법을 찾지 못하고 결국 Solution을 참고했다.
Solution에도 HashMap을 통한 풀이로 거의 두번째 풀이와 동일했다. 다른 점은 HashMap의 접근을 반으로 줄인 것이다. 나는 HashMap.getOrDefault()로 nums[i]의 가장 최근 인덱스를 가져와 비교한 뒤 HashMap.put()으로 nums[i]의 가장 최근 인덱스를 i로 업데이트하였다.
하지만 HashMap.put() 한 번으로 위 두 과정과 동일하게 수행할 수 있다. HashMap.put(key, value)는 기존 key에 해당하는 값이 존재하면 새로운 value로 업데이트하고 없으면 새로운 key-value를 할당한다. 뿐만아니라 return으로 기존 key가 존재할 경우 기존 value를 return하고 key 존재하지 않으면 null을 return한다.
public V HashMap.put(K key, V value)
Associates the specified value with the specified key in this map. If the map previously contained a mapping for the key, the old value is replaced.
Returns:
the previous value associated with key, or null if there was no mapping for key. (A null return can also indicate that the map previously associated null with key.)
따라서 HashMap.put() 함수를 활용하면 기존 HashMap의 접근을 반으로 줄일 수 있다.
class Solution {
public boolean containsNearbyDuplicate(int[] nums, int k) {
Map<Integer, Integer> indexs = new HashMap<>();
for (int i = 0; i < nums.length; i++) {
Integer recentIndex = indexs.put(nums[i], i);
if (recentIndex != null && i - recentIndex <= k) {
return true;
}
}
return false;
}
}시간복잡도와 공간복잡도는 두번째 풀이와 동일하며 개선된 결과로 25ms → 14ms로 줄일 수 있었다.

Solution을 보고 개선하게 된 것은 Java에서 제공하는 자료구조의 메소드 put()을 제대로 알고 사용하지 않았기 때문이다. 평소에도 많이 쓰는 함수임에도 불구하고 void형 메소드인줄 알고 사용해왔다.. 앞으로는 메소드를 사용할 때 javadoc을 잘 읽어보며 사용해야겠다.
