유니코드
옛날에는 1byte(0~255)를 통해 데이터를 표현했다. '영어'와 몇가지 '특수문자'만 사용했지만 이후 다른 나라의 언어를 표현하기 위해 국제적으로 전세계 언어를 모두 표시할 수 있는 표준코드를 만들었다. 이것이 바로 유니코드(Unicode)다.
유니코드는 글자와 코드가 1:1 매핑되어 있는 '코드표' 이다.
유니코드를 통해 코드표가 정의되었다. 남은 것은 그 '코드'가 컴퓨터에 어떻게 저장되어야 하는 것이다. 다른 말로 인코딩(encoding)이라고 하는데, 컴퓨터가 이해할 수 있는 형태로 바꿔주는 것이다. A가 '가'는 0001로, '나'는 0010이라고 하자. A가 '가나나가'라고 말하면 0001 0010 0010 0001로 저장한다. 글자당 1 byte로 할당해 4byte로 저장할 수 있고 00010010 00100001처럼 2byte로 저장할 수도 있다. 이건 전적으로 A와 컴퓨터간의 약속이다. A 혼자만 쓸 때는 문제가 없지만 전세계 사람들이 사용하려면 약속이 필요하다. 이때 나타난 것이 UTF방식 인코딩이다.
UTF는 몇 bit를 사용하여 Index를 표현할 것인가를 뜻한다
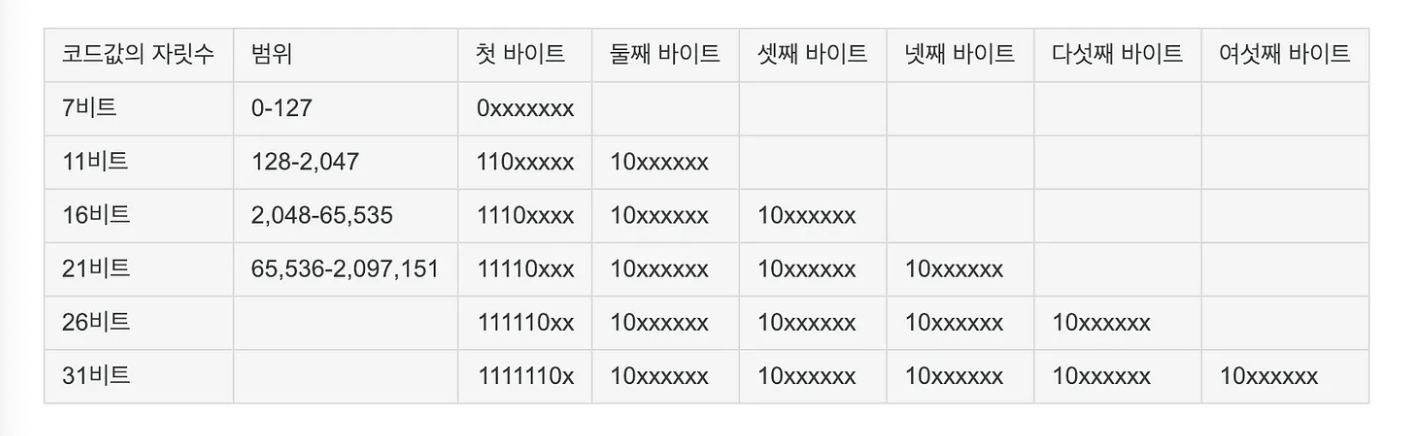
UTF-8
8bit를 이용하여 1개의 index로 표현한다. 가변 인코딩 방식으로 글자마다 byte 길이가 다르다.
'a'는 1byte이고 '가'는 3byte이다. 가변을 구분하기 위해 첫 바이트에 표식을 넣었는데 2byte는 110으로 시작하고 3byte는 1110으로 시작한다. 나머지 바이트는 10으로 시작한다.
UTF-16
UTF-16은 16bit를 이용하여 1개의 index로 표현한다. 주로 사용되는 기본 문자들은 그대로 16bit값으로 인코딩되고 그 이상의 문자는 특별히 정해진 방식으로 32bit로 인코딩 된다.
UTF-16 인코딩은 유니코드 한 문자를 나타내기 위해 2byte~4byte까지 사용한다.
영문 byte 수 : 2byte
한글 byte 수 : 2byte
UTF-32
32비트 단위로 문자를 표현하는 인코딩 방식으로, 모든 유니코드 문자를 하나의 32비트 코드 단위로 표현한다. 이러한 특성으로 인해 UTF-32는 모든 문자에 대한 접근이 일관적이고 편리하다는 장점을 가지고 있다. 하지만 UTF-16보다 더 많은 메모리를 사용하기 때문에 저장 및 전송에는 더 많은 비용이 든다.
일반적으로 UTF-8 인코딩과 비교하여 UTF-16, UTF-32는 보다 높은 메모리 사용량과 더 높은 저장 및 전송 비용을 가져올 수 있지만, 모든 유니코드 문자에 대한 일관적인 처리하 필요한 경우에 사용한다
참고
영어권에서는 UTF-8 인코딩시 1byte로 언어를 표현하지만, 한글은 3byte로 표현한다. 이러한 이유때문에 한글 등 다국어를 이용하는 문화권에서는 UTF-16이 더 효율적일 수 있다.
