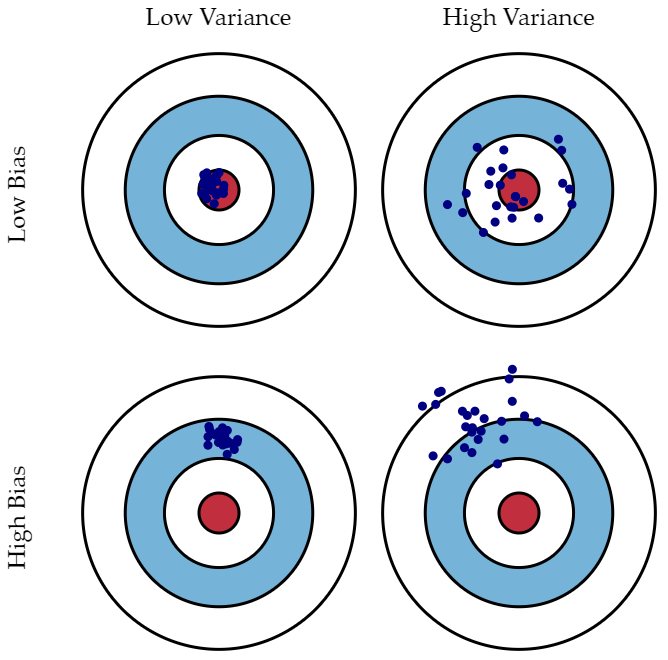
편향과 분산
이미지 출처: http://scott.fortmann-roe.com
개념 설명
- 편향 (bias) : 예측값이 정답과 얼마나 멀리 떨어져 있는가
- 지나치게 단순한 모델로 인한 Error
- 편향이 크면 과소적합 (underfitting) 야기
- 분산 (variance) : 예측값 사이의 차이 정도
- 지나치게 복잡한 모델로 인한 Error
- 분산이 크면 과대적합 (overfitting) 야기
Error 구성 설명
- : 편향의 제곱
- : 분산
- : 줄일 수 없는 error항
Trade-off
- 편향을 줄이기 위해
- 모델을 복잡하게 만들면
- 예측값 사이의 분산이 커지게 됨
- 분산을 줄이기 위해
- 모델을 단순하게 만들면
- 예측값과 정답 간 차이가 커져 편향이 커지게 됨
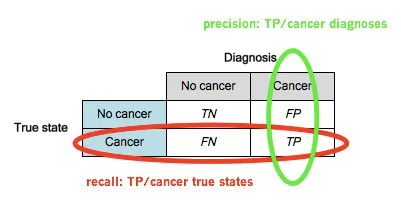
Precision과 Recall
이미지 출처 : https://datascience-george.medium.com/the-precision-recall-trade-off-aa295faba140
개념 설명
-
Precision (정밀도)
- 모델이 True로 예측한 값 중, 실제 True인 비율 -
Recall (재현율)
- 실제 True 값 중, 모델이 True로 예측한 비율
Trade-off
- Precision을 높이기 위해,
- 즉, FP의 수를 줄이기 위해
- 분류 임계치 값을 높여 True일 확률이 확실할 때에만 True로 분류하게 된다면
- 실제 True임에도 불구하고 False로 분류되는 FN의 수가 커져 Recall 값이 작아지게 됨
- Recall을 높이기 위해,
- 즉, FN의 수를 줄이기 위해
- 분류 임계치 값을 낮춰 실제 True였을 때 False로 평가되는 경우를 줄이게 된다면
- 실제 False임에도 불구하고 True로 분류되는 FP의 수가 커져 Precision 값이 작아지게 됨

Steadily