
교재 Must Have 이재환의 자바 프로그래밍 입문을 학습하며 정리한 내용입니다.
22. 내부 클래스, 람다식
22.1 내부 클래스
자바에서 클래스 안에 클래스를 선언할 수가 있는데, 안쪽에 있는 클래스를 중첩 ㅡㄹ래스라고 하고 중첩 클래스를 가지고 있는 클래스를 외부클래스라고 한다.
중첩클래스는 두가지로 구분된다.
- 스태틱 중첩 클래스 : 중첩이지만 내부 클래스는 아니다.
- 논스태틱 중첩 클래스 : 내부 클래스라고 부른다.
- 멤버 내부 클래스
- 지역 내부 클래스
- 익명 내부 클래스

22.2 멤버 내부 클래스
다른 클래스와는 연관되어 사용되지 않고 해당 클래스에서만 특정 클래스를 사용할 때 하나의 소스파일로 묶어 관리를 편하게 할 수 있다. 외부 클래스는 내부 클래스를 멤버 변수처럼 사용할 수 있고, 내부 클래스는 외부 클래스의 자원을 직접 사용할 수 있는 장점이 있다. 멤버 내부 클래스는 외부 클래스 뒤에 .new를 붙이면 된다
외부클래스.new 내부 클래스 생성자();
22.3 지역 내부 클래스
지역 내부 클래스는 클래스의 정의 위치가 메서드, if문, while문 같은 중괄호 블록 안에 정의된다는 점에서 멤버 내부 클래스와 구분된다. 이러면 해당 메서드 안에서만 객체 생성이 가능해지므로 클래스의 정의를 깊이 숨기는 효과가 있다.
private int speed = 10;
public void getMarine() {
class Marine2 {
//외부 클래스의 자원 사용 가능
public void move() {
System.out.printf("dd" , spped);
}
}
Marine2 inner = new Marine2();
inner.move();외부 클래스의 메서드 안에 정의된 내부 클래스는 지역 변수와 유사한 특성을 가지므로 해당 메서드 안에서만 생성할 수 있다. 다른 곳에서는 생성할 수 없다. 즉, 객체의 생성을 제한할 수 있다. 내부 클래스이므로 역시 외부 클래스의 자원을 사용할 수 있다.
22.4 익명 내부 클래스
지역 내부 클래스는 해당 메서드에서만 클래스 생성이 가능하므로 클래스명이 상당히 제한적으로 사용된다. 그래서 클래스명을 생략해버리기도 한다. 이렇게 클래스명을 생략한 것이 익명 내부 클래스이다.

- 안드로이드 프로그래밍에서 위젯의 이벤트를 처리하는 핸들러를 구현할 때 이런 익명 내부 클래스를 사용하고 있다.
22.5 람다식
자바는 객체를 기반으로 프로그램을 구현한다. 만약 어떤 기능이 필요한데 간단한 기능이기 때문에 함수만 하나 만들어서 사용하고 싶어도, 자바는 클래스 기반의 객체지향 언어이기 때문에 간단한 클래스를 만들어줘야한다. 자바는 클래스가 없으면 메서드를 사용할 수 없다.
이런 불편함을 덜기 위해 자바 8부터는 함수형 프로그래밍 기법인 람다식을 지원한다. 자바는 익명 내부 클래스를 람다식으로 표현해 함수형 프로그래밍을 지원한다.
익명 내부 클래스 -> 람다식
- 익명 클래스를 나타내는 의미 없이 붙인 이름과 외부의 중괄호를 제거한다.
- 함수 이름, 반환형을 없애고 화살표(->)를 추가한다.
- 함수의 실행문 {} 블록을 남기고 문장의 끝을 알려주기 위해 세미콜론으로 마지막을 표시한다.
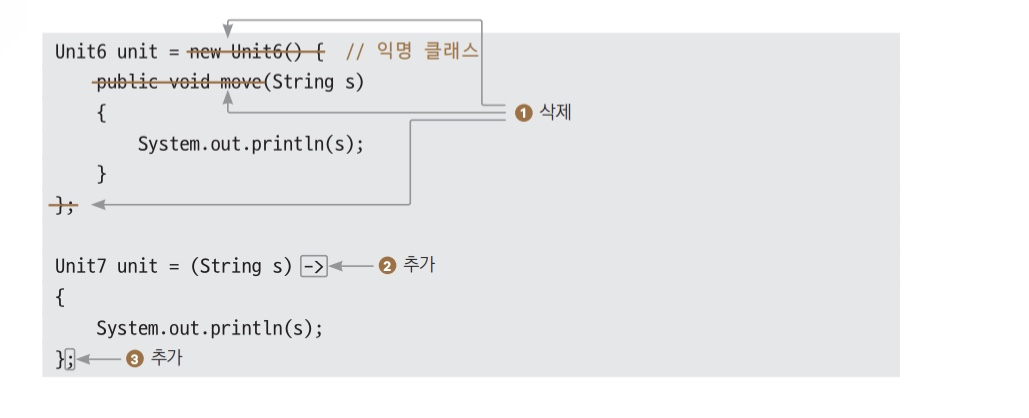
- 완성된 람다식
Unit7 unit = (String s) ->
{
System.out.println(s);
};람다식 문법
- 매개변수가 하나이면 자료형과 소괄호를 생략할 수 있다.
str -> { System.out.println(str); } - 중괄호 안의 구현부가 한 문장이면 중괄호를 생략할 수 있다.
str -> System.out.println(str); - 중괄호 안의 구현부가 한 문장이라도 return문이 있다면 중괄호를 생략할 수 없다.
str -> return str.length(); // 잘못된 형식 - 매개변수가 두 개 이상이면 소괄호를 생략할 수 없다.
x, y -> { System.out.println(x+y); } // 잘못된 형식 - 중괄호 안의 구현부가 반환문 하나라면 return 과 중괄호 모두 생략할 수 있다.
str -> str.length(); // 문자열의 길이를 반환
(x, y) -> x + y; // 두 값을 더하여 반환 - 매개변수가 없을 경우에는 소괄호를 생략할 수가 없다.
() -> System.out.println("hello~~");
22.6 함수형 인터페이스
함수형 인터페이스는 람다식을 선언하는 전용 인터페이스이다. 함수형 인터페이스는 익명 함수와 매개변수만으로 구현되므로 단 하나의 메서드만을 가져야한다. 인터페이스에 @FunctionalInterface 어노테이션을 붙여서 함수형 인터페이스임을 표시해놓는다. 이후에 혹시라도 실수로 메서드 등을 추가하면 에러가 발생하게 된다.
@FunctionalInterFace가 붙어있는 인터페이스에 만약 두 개 이상의 메서드가 있게 된다면 어떤 메서드에 익명 함수를 대입할지 모호해지기 때문에 에러가 발생하게 된다.
23. 스트림
23.1 스트림
데이터의 흐름을 가리켜 스트림이라고 한다. 데이터가 여러 개 있어야 흐름을 만들 수 있기 때문에 스트림 데이터 소스로는 컬렉션, 배열 등이 주로 사용된다. 스트림 데이터는 이렇게 데이터 소스에서 추출한 연속적인 데이터이다. 그리고 스트림은 이런 연속적인 데이터의 흐름을 반복적으로 처리하는 기능이다.
특징
- 스트림 연산은 기존 자료를 변경하지 않는다.
- 스트림 연산은 중간 연산과 최종 연산으로 구분된다.
- 한 번 생성하고 사용한 스트림은 재사용할 수 없다.
스트림은 java.util.stream 패키지의 멤버이며, BaseStream 인터페이스를 부모로 하여 Stream, intStream, LongStream, DoubleStream을 제공한다.
23.2 중간 연산, 최종 연산
스트림 연산은 중간 연산과 최종 연산으로 구분된다.
중간 연산
- filter() : 조건에 맞는 요소 추출
- map() : 조건에 맞는 요소 변환
- sorted() : 정렬
최종 연산
- 스트림의 자료를 소모하면서 연산을 수행
- 최종 연산 후에 스트림은 더 이상 다른 연산을 적용할 수 없음
- forEach() : 요소를 하나씩 꺼내옴
- count() : 요소 개수
- sum() : 요소의 합
23.3 파이프라인 구성
Stream 인터페이스가 제공하는 메서드는 대부분 반환 타입이 Stream 이므로 메서드를 연속해서 호출할 수 있다. 따라서 스트림 연산을 파이프라인으로 구성할 수 있다.
//Pipeline 구성
int sum = Arrays.stream(arr)
.filter(n -> n%2 ==1)
.sum();23.4 컬렉션 객체 vs 스트림
스트림을 사용하면 컬렉션만 사용한 것보다 코드가 간결하고, 쉽게 의미를 알 수 있다.
ex) 배열에서 홀수만 골라내서 정렬하여 출력하는 코드
//컬렉션 프레임워크를 이용한 방식
필터링
for(int i : arr) {
if(I%2 == 1) {
list.add(i);
}
}
Collections.sort(list); //정렬
// 요소 추출
for (int i : list) {
Sysytem.out.print(i+"\t");
}
// stream을 이용한 방식
Arrays.stream(arr)
.filter(n -> n%2 ==1) //필터링
.sorted() //정렬
.forEach(n -> System.out.print(n + "\t")); //요소추출
Sysytem.out.println();
}23.5 여러 가지 연산들
sorted()
스트림을 구성하는 데이터를 조건에 따라 정렬하는 연산을 한다.
//사전순 정렬
list.stream()
.sorted()
.forEach(n -> System.out.print(n + "\t"));
//글자 길이순 정렬
list.stream()
.sorted((s1, s2) -> s1.length() - s2.length())
.forEach(n -> System.out.print(n + "\t"));map()
스트림을 구성하는 데이터를 조건에 따라 변환하는 연산을 한다.
//대문자로 변환
list.stream()
.map(s -> s.toUpperCase())
.forEach(n -> System.out.print(n + "\t"));sum(), count(), average(), min(), max()
//합
int sum = IntStream.of(1,3,5,7,9)
.sum();
System.out.println("sum =" + sum);
//개수
int cnt = IntStream.of(1,3,5,7,9)
.count();
System.out.println("count =" + cnt);
//평균
IntStream.of(1,3,5,7,9)
.average();
.ifPresent(avg -> System.out.println("avg = " + avg));
//최소
IntStream.of(1,3,5,7,9)
.min();
.ifPresent(min -> System.out.println("min = " + min));
//최대
IntStream.of(1,3,5,7,9)
.maz();
.ifPresent(max -> System.out.println("max = " + max));reduce()
reduce() 최종 연산은 정의된 연산이 아닌 프로그래머가 직접 지정하는 연산을 적용한다.
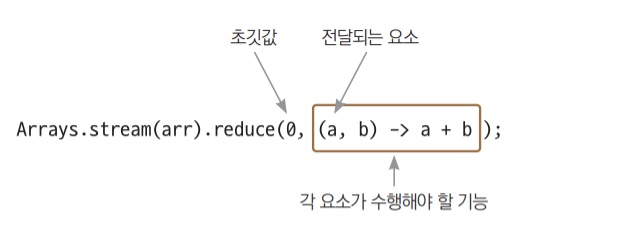
24. 입출력 스트림
24.1 자바의 입출력 스트림
자바에서 스트림이란 자료 흐름이 물의 흐름과 같다는 의미에서 사용된다. 자바 8에서 컬렉션 객체를 다루기 위한 스트림이 추가되면서, 기존의 입출력 모델에서 발생하는 스트림을 입출력(I/O)스트림이라고 구분하여 부르게 되었다.
다음과 같은 자바의 입출력 방식을 가리켜 자바 입출력 모델이라고 한다.
- 파일에서의 입출력
- 키보드와 모니터의 입출력
- 그래픽카드, 사운드카드의 입출력
- 프린터, 팩스와 같은 출력 장치의 입출력
- 인터넷으로 연결되어 있는 서버 또는 클라이언트의 입출력
이처럼 입출력 장치는 매우 다양하기 때문에 장치에 따라 입출력 부분을 일일이 다르게 구현하면 프로그램 호환성과 생산성이 떨어질 수 밖에 없다. 그래서 자바는 입출력 장치를 구분하지 않고 일관성 있게 프로그램을 구현할 수 있도록 위와 같은 자바 입출력 모델의 모든 입출력을 입출력 스트림을 통해 처리하는 기능을 제공한다.
- 대상 기준에 따라서는 입력 스트림, 출력 스트림으로 나눈다.
- 자료의 종류에 따라서 바이트 단위 스트림, 문자 단위 스트림으로 나눈다
- 기능에 따라서는 기반 스트림, 보조 스트림(필터 스트림)으로 나눈다.
24.2 입출력 스트림의 구분
입출력 스트림은 3가지 관점에서 입력 스트림, 출력 스트림, 바이트 단위 스트림과 문자 단위 스트림, 기반 스트림과 보조 스트림으로 구분할 수 있다.
입력 스트림과 출력 스트림
대상 기준에 따라 스트림을 구분할 때는 입력 스트림과 출력 스트림으로 나눈다.
- 입력 스트림 : 대상으로부터 자료를 읽어들이는 스트림
- 출력 스트림 : 대상으로 자료를 출력하는 스트림

- 스트림 종류
| 종류 | 예 |
|---|---|
| 입력 스트림 | FileInputStream, FileReader, BufferedInputStream 등 |
| 출력 스트림 | FileOutputStream, FileWriter, BufferedOutputStream 등 |
바이트 단위 스트림과 문자 단위 스트림
자료의 종류에 따라서 스트림을 구분할 때는 바이트 단위 스트림과 문자 다위 스트림으로 나눈다.
- 바이트 단위 스트림 : 동영상, 음악 파일 등을 읽고 쓸 때 사용
- 문자 단위 스트림 : 바이트 단위로 자료를 처리하면 문자는 깨짐. 2바이트 단위로 처리하도록 구현된 스트림
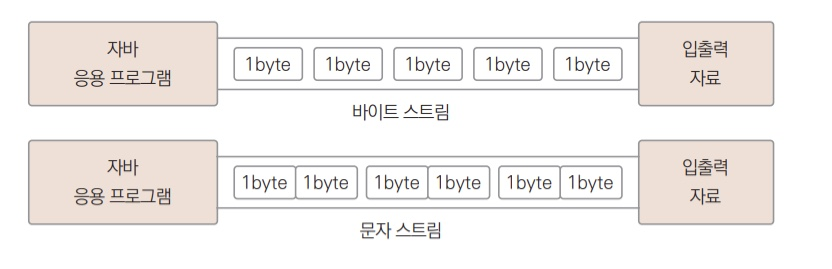
- 스트림 종류
| 종류 | 예 |
|---|---|
| 바이트 스트림 | FileInputStream, FileOutputStream, BufferedInputStream 등 |
| 문자 스트림 | FileReader, FileWriter, BufferedWriter 등 |
기반 스트림과 보조 스트림
기능에 따라서 스트림을 구분할 때는 기반 스트림, 보조 스트림(필터 스트림)으로 나눈다.
- 기반 스트림 : 대상에 직접 자료를 읽고 쓰는 기능의 스트림
- 보조 스트림 : 직접 읽고 쓰는 기능은 없이 추가적인 기능을 더해주는 스트림, 항상 기반 스트림이나 또 다른 보조 스트림을 생성자 매개변수로 포함함
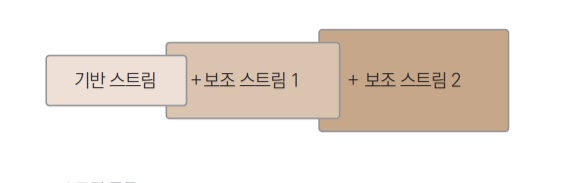
- 스트림 종류
| 종류 | 예 |
|---|---|
| 기반 스트림 | FileInputStream, FileOutputStream, FileReader 등 |
| 보조 스트림 | InputStreamReader, OutputStreamWriter, BufferedInputStream 등 |
24.3 파일 대상 입출력 스트림 생성
자바 입출력 모델의 가장 대표격인 '파일을 대상으로 하는 입출력 모델'에서 스트림을 생성하여 자바 입출력 스트림이다.
파일 대상 출려 ㄱ스트림 생성
OutputStream out = new FileOutputStream("만들 파일이름");
out.write(65); // ASCII 코드 65 ='A'
out.close();
파일을 생성하고 해당 파일에 스트림을 생성한다. 만들 때는 다양한 자바의 입출력모델에 맞춰서 구체적인 형태인 FileOutputStream을 사용해 만들게 도지만, 사용할 때는 일반적인 OutputStream 형태로 사용하면 된다.
write를 사용해 스트림을 통해 데이터를 보낸다. 이렇게 하면 파일에 데이터가 써진다.
close로 파일을 닫는다.
파일은 프로젝트의 루트 폴더에 생성된다.
입출력 스트림 예외 직접 처리
예외를 넘기지 않고 직접 처리하는 코드
OutputStream out = null;
try {
out = new FileOutputStream("파일명:);
out.write(65);
//out.close();
|
}
catch (IOException e) {
}
finally {
if(out != null) {
try {
out.close();
}
catch(IOException e2) {
}
}close를 확실히 호출하기 위해 finally 구문으로 옮기고 그러려면 범위가 달라져 out을 바깥에 선언해야한다. 또 finally 구문에서 out.close()를 부를 때 이 메서드 자체도 예외가 발생할 수 있기 때문에 또 try ~ catch로 묶어줘야한다.
입출력 스트림 예외 처리 개선
try~whit~resource를 적용하여 코드를 작성하면 된다.
try( OutputStream out = new FileOutputStream("파일명")){
out.write(65);
|
}
catch (IOException e) {
e.printStackTrace();
}파일 대상 입력 스트림 생성
try~with~resource를 적용한다.
try( InputStream in = new FileInputStream("파일명")){
int dat = in.read();
System.out.println(dat);
System.out.printf("%c \n", dat);
|
}
catch (IOException e) {
e.printStackTrace();
}바이트 단위 입력 및 출력 스트림 이용 파일 복사
try(InputStream in = new FileInputStream();
OutputStream out = new FileOutputStream();버퍼를 이용한 파일 복사
입출력 스트림의 데이터를 한 바이트씩 읽고 쓰는 방식은 입출력 I/O가 많이 발생하게 되어서 하드웨어적인 비용이 많이 발생해 시간이 오래걸린다. 그래서 메모리를 이용하여 버퍼에 저장해서 한 번 읽고 쓰는 방식으로 하드웨어적인 I/O의 횟수를 줄여주면 시간을 단축할 수 있다.
byte[] buf = new byte[1024];
int len;
Instant start = Instant.now()
while(true) {
len.inread(buf);
if(len == -1)
break;
out.write(buf, 0, len);
}24.4 보조 스트림
기반 스트림에 추가적인 기능을 더해주는 스트림이 보조 스트림이다. 항상 버퍼 기능을 구현하기는 어렵기 때문에 보조 스트림을 통해 기능을 제공하게 된다. 기반 스트림으로 사용해야할 때는 기반 스트림에 기능을 추가하지 않고, 필요하면 레고 블록처럼 보조 스트림을 붙여서 기능을 추가한다.
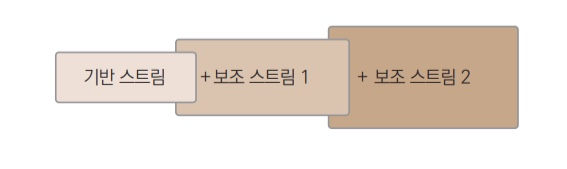
버퍼링 기능을 제공하는 필터 스트림
보조스트림은 단독으로 사용할 수 없고 기반 스트림에 더해서 같이 사용하게 된다.
BufferedInputStream in = new BufferedInputStream(new FileInputSteam();
BufferedOutputStream out = new BufferedOutputStream()))
24.5 문자 스트림
FileReader나 FileWriter 클래스를 사용하게 되면 입출력 스트림에서 두 바이트씩 데이터를 처리해준다.
FileWriter
try (Writer out = new FileWriter("파일명"))
FileReader
try (Reader in = new FileReader("저장된파일명"))
BufferedWriter
문자 스트림도 버퍼링 처리를 위하여 기반 스트림에 보조 스트림을 더할 수 있다.
try ( BufferedWriter bw = new BufferedWriter(new FileWriter("")))
기반 스트림이 FileWriter이고, 보조 스트림은 BufferedWriter가 된다. 문자열의 크기만큼 버퍼링하여 한 번에 출력 스트림으로 파일에 저장한다.
BufferedReader
문자 스트림으로 파일을 읽을 때도 보조 스트림을 적용하여 더 빠르게 읽어들일 수 있다.
try (BufferReader br = new BufferedReader(new FileReader("저장된 파일명")))
24.6 IO 스트림 기반의 인스턴스 저장
자바 가상 머신의 메모리에 있는 객체 데이터를 바이트 형태로 변환하는 기술인 직렬화 기능을 이용하면 객체 자체를 저장할 수도 있다.
직렬화
자바에서 직렬화는 객체의 상태를 그대로 저장하거나 다시 복원하는 것을 말한다. ObjectInputStream 과 ObjectOutputStream 을 사용하여 파일에 쓰거나 네트워크로 전송할 수 있다.
| 생성자 | 설명 |
|---|---|
| ObjectInputStream(InputStream in) | InputStream을 생성자의 매개변수로 받아 ObjectInputStream을 생성한다. |
| ObjectOutputStream(OutputStream in) | OutputStream을 생성자의 매개변수로 받아 ObjectOutputStream을 생성한다. |
직렬화는 객체의 내용 중 private이 선언된 부분이 있더라도 외부로 내용이 유출되는 것이므로 프로그래머가 직렬화 의도를 표시해야한다.
이때 사용하는 것이 java.io.Serializable 인터페이스이다. 이 인터페이스는 구현할 추상 메서드가 없다. 직렬화 의도를 밝히기 위해 인터페이스를 적용하는 것이기 때문에 마커 인터페이스라 부른다.
public class unit12 implements java.io.Serializable {
private static final long serialVersionUID = 1L;implements에 사용된 java.io.Serializable 인터페이스는 구현할 기능이 없는 마커 인터페이스이다. 이 클래스에 직렬화를 사용해도 된다는 표시이다.
serialVersionUID는 직렬화에 사용되는 고유 아이디인데, 선언하지 ㅇ낳으면 JVM에서 디폴트로 자동 생성한다. 하지만 사용하지 않으면 워닝이 보이기 되므로 선언하고 사용한다.
ObjectOutputStream
try (ObjectOutputStrem oos = new ObjectOutputStream("Object.bin")))
oos.writeObject();
로 사용한다 bin으로 저장한 것은 문자를 저장한 것이 아니고 객체를 저장한 것이기 때문에 에디터에서 일반적인 텍스트 문서처럼 열어볼 수 없다.
ObjectInputStream
ObjectOutputStream을 이용하여 객체를 저장한 경우 ObjectInputStream으로 읽어서 객체를 복원해야 정보를 읽을 수 있다.
try(ObjectInputStream ois = new ObjectInputStream(new FileInputStream("object.bin")))
25. 스레드
25.1 스레드의 이해
운영체제에서 실행 중인 프로그램을 프로세스라 부른다. 예전 DOS 운영체제 환경에서는 한 번에 한 프로그램만이 실행되었다.
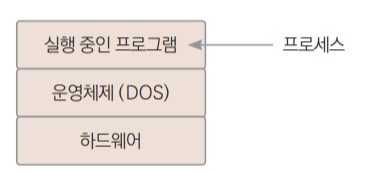
현대 운영체제인 윈도우, 맥OS, 리눅스 등에서는 동시에 여러 프로그램이 실행된다. 이렇게 두가지 이상의 작업을 동시에 처리하는 것을 멀티태스킹이라고 한다.
프로세스는 자신만의 자원을 가진다. 그래서 여러 프로세스가 동시에 실행되더라도 자신만의 메모리를 사용하기 때문에 서로 독립적이다.
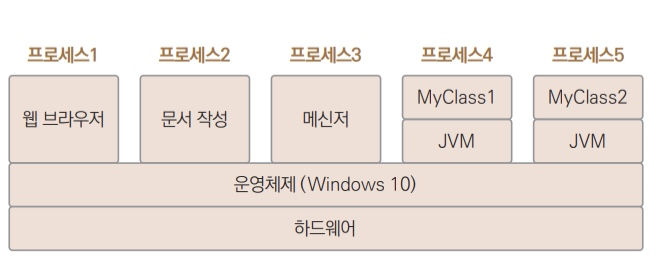
그리고 실행 중인 애플리케이션, 즉 프로세스에서도 동시에 수행할 수 있는 다수의 코드 블록이 있을 수 있다. 예를 들면 웹 브라우저는 다운로드가 진행 중일때 계속해서 검색을 할 수 있다. 이 작업들은 서로 독립적이어서 동시에 실행할 수 있다.
자바 애플리케이션은 JVM 위에서 동작하며, 하나의 JVM은 하나의 애플리케이션을 실행할 수 있다. 이 애플리케이션 안에서 앞에서 설명한 웹 브라우저처럼 여러 작업을 동시에 수행할 수 있는 데 이걸 스레드라고 한다.
스레드들은 각자의 자원을 가지고 독립적으로 실행된다.
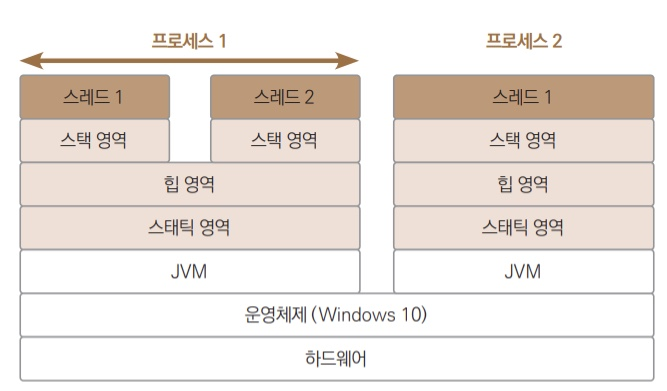
스레드는 하나의 실행 흐름으로 프로세스 내부에 존재한다. 그리고 프로세스는 하나 이상의 실행흐름을 포함하기 때문에 프로세스는 적어도 하나의 스레드를 가진다.
public static void main(String[] args) {
String name = Thread.currentThread().getName();
System.out.println("현재 스레드 이름 : " + name);
}
} 을 실행하면 현재 스레드 이름은 main이라고 뜬다.
25.2 스레드 생성과 실행
자바는 두가지 방법으로 스레드를 작성할 수 있다.
- Thread 클래스를 상속받아 run() 메서드 오버라이딩
- Runnable 인터페이스 구현
Thread 클래스와 Runnable 인터페이스는 java.lang 패키지에 포함되어 있기 때문에 따로 import할 필요는 없다.
Thread 클래스를 상속받아 만들기
우리가 여태 만들었던 것처럼 부모 클래스로 Thread를 상속받아 클래스를 만들 수 있다.
다만 스레드는 start() 메서드를 통해 동작시키게 된다.
스레드 실행은 메서드 호출과는 처리 방식이 다르다. 메서드 호출은 결과를 기다렸다 다음 라인이 실행되지만 스레드 실행은 시작하라는 명령만 내리고 바로 다음 라인으로 실행이 옮겨간다. 실행된 스레드는 메인 스레드와는 별도로 자기 자신만의 실행 순서로 main 스레드와 동시에 실행된다.
다만 메인 블록의 코드가 다 실행되었다고 해도 스레드가 실행되고 있다면 스레드 실행이 끝날 때까지 메인 블록 종료가 지연된다. 메인 블록이 끝나면 프로그램이 종료되기 때문이다.
Runnable 인터페이스 구현하기
자바는 다중 상속이 안 되기 때문에 Thread 클래스를 상속받아 스레드를 만들면 구현이 힘든 상황이 생긴다. 그럴 때는 Runnable 인터페이스를 구현하여 스레드를 만들면 된다.
class Mythead implements Runnable {
public void run() {
int sum = 0;
for(int i=0; i<10; i++)
sum = sum+i;
String name = Thread.currentThread().getName();
}
}
.
.
public static void main(String[] args) {
Thread t = new Thread(new MyThread());
t.start();
.
.Thread 클래스를 상속한 클래스와 Runnable 인터페이스를 구현한 클래스에서 달라지는 부분이다. run 메서드를 바로 호출하지 않고 start() 메서드를 호출하면 run()메서드가 실행된다.
람다식으로 Runnable 구현하기
public static void main(String[] args) {
Runnable task = () -> {
try {
Thread.sleep(3000);
}
catch(Exception e)여러 개의 스레드 동시 실행
하나의 프로세스에서 스레드는 여러 개가 동시에 실행될 수 있다. 여러 개의 스레드가 동시에 실행되면서 자기만의 동작을 하게 된다.
public static void main(String[] args) {
Runnable task1 = () -> {
try {
동작
}
catch(InterruptedException e) {}
};
Runnable task2 = () -> {
try {
동작
}
catch(InterruptedException e) {}
};25.3 스레드 동기화
변수의 값은 메모리에 있다. 이 변수의 값을 증감하는 연산을 하려면 CPU로 값을 옮겨와서 값을 증감시키는 연산을 수행하고 나서 다시 메모리에 저장시켜야 한다. 이런 과정이 있기 때문에 여러 스레드가 같은 변수의 값을 증감시키는 연산을 수행하면 문제가 발생한다.
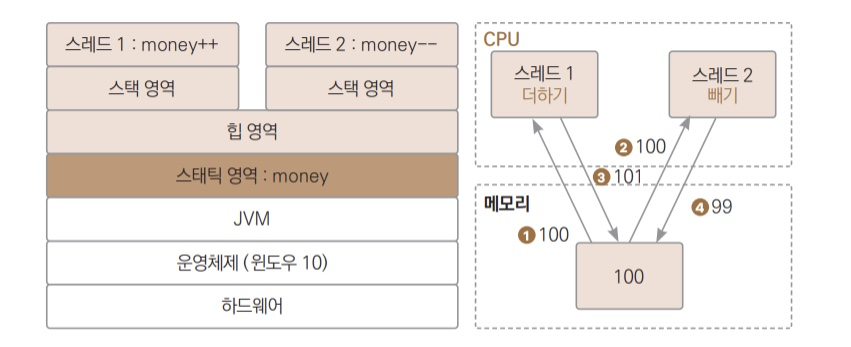
스레드에서의 문제점
위 그림 처럼 동작을 하면서, 스레드가 실행될 때의 CPU 진행 상황에 따라 진행 속도가 조금씩 달라지면서 매번 다른 결과가 나오게 된다.
스레드 동기화로 문제점 해결
자바에서는 스레드 동기화를 사용하여 이런 문제를 해결한다. 동기화 시키는 방법은 두 가지이다.
1. 메서드에 synchronized 키워드를 지정
2. 코드의 일부에 동기화 블록을 지정

이렇게 동기화가 메서드나 블록에 적용되면 동기화 영역이 실행되는 동안 다른 스레드의 접근을 제한하게 된다. 동기화 영역의 실행이 끝나면 이제 다른 스레드에서도 접근이 가능하게 된다. 그러므로 이 부분에 많은 스레드가 접근하게 된다면 병목 현상이 발생할 수 있다.
25.4 스레드 풀
스레드 개수가 많아지면 스레드 객체 생성과 소멸, 스케줄링 등에 CPU와 메모리에 많은 부하가 발생한다. 스레드의 생성과 소멸은 리소스 소모가 많은 작업이다. 웹 서버처럼 소규모의 많은 요청이 들어올 때마다 스레드를 생성 및 종료하면 오베헤드가 발생한다. 거기에 생성되느 ㄴ스레드 개수에 제한이 없다면 OutOfMemoryError가 발생할 수 있다.
따라서 생성과 종료를 반복해 사용하는 스레드라면 재활용하고 동시에 실행하는 스레드 개수도 제한하여 CPU와 메모리에 가해지는 부하를 줄일 필요가 있다. 이런 목적으로 자바5에 스레드 관한 java.util.concurrent 패키지ㅏㄱ 추가되었다.
스레드풀은 제한된 개수의 스레드를 JVM에 관리하도록 맡기는 방식이다. 실행할 작업을 스레드 풀로 전달하면 JVM이 스레드 풀의 유휴 스레드 중 하나를 선택해서 스레드로 실행시킨다
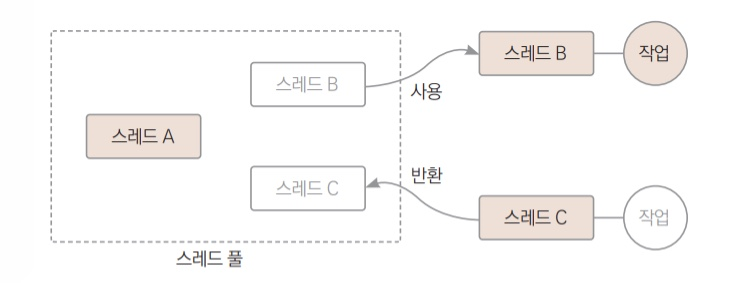
- newSingleThreadExecutor
풀 안에 하나의 스레드만 생성하고 유지한다. 스레드의 숫자가 하나이고 하나의 태스크가 완료된 이후에 다음 태스크가 실행한다. 즉, 여러 스레드가 동시에 실행되지 않으므로 동기화가 필요 없다.
ExecutorService pool = Executors.newSingleThreadExecutor();
pool.submit();
pool.shutdown();- newFixedThreadPool
풀 안에 인수로 전달된 수의 스레드를 생성하고 유지한다. 초기 스레드 개수는 0개, 코어 스레드 수와 최대 스레드 수는 매개변수 nThreads값으로 지정한다. 만약 생성된 스레드가 놀고있어도 스레드를 제거하지 않고 내버려둔다. 한 번에 최대 개수 이상으로 전달되면 최대 기수 이외의 개수는 다 수행되고 종료가 되면 그때부터 실행된다. - newCachedThreadPool
풀 안의 스레드의 수를 작업의 수에 맞게 유동적으로 관리한다. 초기 스레드와 코어 스레드 개수는 0개, 최대 스레드 수는 Integer 데이터형이 가질 수 있는 최댓값이다. 만약 스레드가 60초 동안 아무일도 하지 ㅇ낳으면 스레드를 종료시키고 스레드 풀에서 제거한다.
25.5 Callable & Future
스레드는 실행만 시켜줄 수 있고, 스레드로부터 결과를 반환받을 수 없다. 그런데 Executor 프레임워크를 사용하면 작업 대상의 Callable 객체를 만들고 ExecutorService에 등록한 다음 테스크 처리가 끝난 다음 작업 결과를 Future 객체를 통해서 반환받을 수 있다.
25.6 ReentranLock 클래스 : 명시적 동기화
기존의 synchronized는 메서드 전체나 구간을 묶어서 동기화시켰다. 그런데 ReenrantLock 클래스를 사용하면 시작점과 끝점을 명백히 명시할 수 있다. ReentrantLock을 이용해 명시적으로 동기화를 시켰을 뿐 synchornized를 사용해 동기화한 것과 같다.
25.7 컬렉션 객체 동기화
여러 스레드가 동시에 컬렉션 객체에 접근하여 요소를 변경하면 의도하지 않게 요소가 변경될 수 있다. 즉, 컬렉션 객체도 스레드에 안전하지 않다.
동기화되지 않은 컬렉션 객체의 사용
여러 스레드가 동시에 변수에 접근해 사용하면 데이터가 적을 때는 CPU가 빠르게 ㅅ처리하면 정상적으로 처리가 되지만, 여러 번 실행하면 스레드에 안전하지 않은 처리 결과가 나오게 된다.
synchronized를 이용한 동기화
컬렉션 프레임워크도 synchronized를 사용하여 동기화를 하면 정상적으로 처리할 수 있다.
Runnable task = () -> {
//list 객체를 사용할 때 객체에 동기화 Lock 설정
ListIterator<Integer> itr = list.listIterator();
.
.컬렉션 객체인 list 변수에 동기화 처리가 되어 있기 때문에 여러 스레드가 list 변수의 값을 변경할 때 이상한 결과를 보이지 않는다.
Collections 클래스의 메서드를 이용한 동기화
자바는 비동기화된 메서드를 동기화된 메서드를 래핑하는 Collections의 synchronizedXXX() 메서드를 제공한다.
| 반환형 | 메서드(매개변수) | 설명 |
|---|---|---|
| List | synchronizedList(List list) | List를 동기화된 List로 반환 |
| Set | synchronizedSet(Set s) | Set을 동기화된 Set 으로 반환 |
| Map<K,V> | synchronizedMap(Map<K,V>m) | Map을 동기화된 Map으로 반환 |
//thread-safe
List<T> list = Collections.synchronizedList(new ArrayList<T>()));
Set<E> set = Collections.synchronizedSet(new HashSet<E>());
Map<K,V> map = Collections.synchronizedMap(new HashMap<K,V>());하지만 컬렉션 객체의 동기화를 이렇게 했다고 하더라도 이 컬렉션 객체를 기반으로 생성하는 반복자는 별도로 동기화를 다시 해주어야한다.
ConcurrentHashMap 이용
스레드가 컬렉션 객체의 요소를 처리할 때 전체 잠금이 발생하여 컬렉션 객체에 접근하는 다른 스레드는 대기 상태가 된다. 이는 객체의 요소를 다루느 ㄴ것은 안전해졌지만, 처리 속도는 느려졌다는 이야기가 된다. 따라서 자바는 멀티스레드가 컬렉션의 요소를 병렬적으로 처리할 수 있도록 java.util.concurrent 패키지에서 ConcurrentHashMap, ConcurrentLinkedQueue를 제공한다.
이 클래스는 부분적으로 잠금을 사용하기 때문에 객체의 요소를 처리할 때 스레드에 안전하면서 빠르게 처리가 가능해진다.
Map<K,V> map = new ConcurrentHasMap<K,V>();
Queue<E> queue = new ConcurrentQueue<E>();--정리
스레드 풀은 제한된 개수의 스레드를 JVM에 관리하도록 맡기는 방식
- synchronized는 메서드 전체나 구간을 묶어서 동기화
- Executor 프레임워크를 사용하면 작업 대상의 Callable 객체를 만들고 ExecutorService에 등록한 다음 태스크 처리가 끝난 다음 작업 결과르 ㄹFuture 객체를 통해서 반환받을 수 있다.
- ReentrantLock 클래스를 사용하면 시작점과 끝점을 명백히 명시해 동기화할 수 있다.
- 컬렉션 객체도 스레드에 안전하지 않다. synchronized,Collections 클래스의 메서드, ConcurrentHashMap을 이용해 동기화 할 수 있다.
