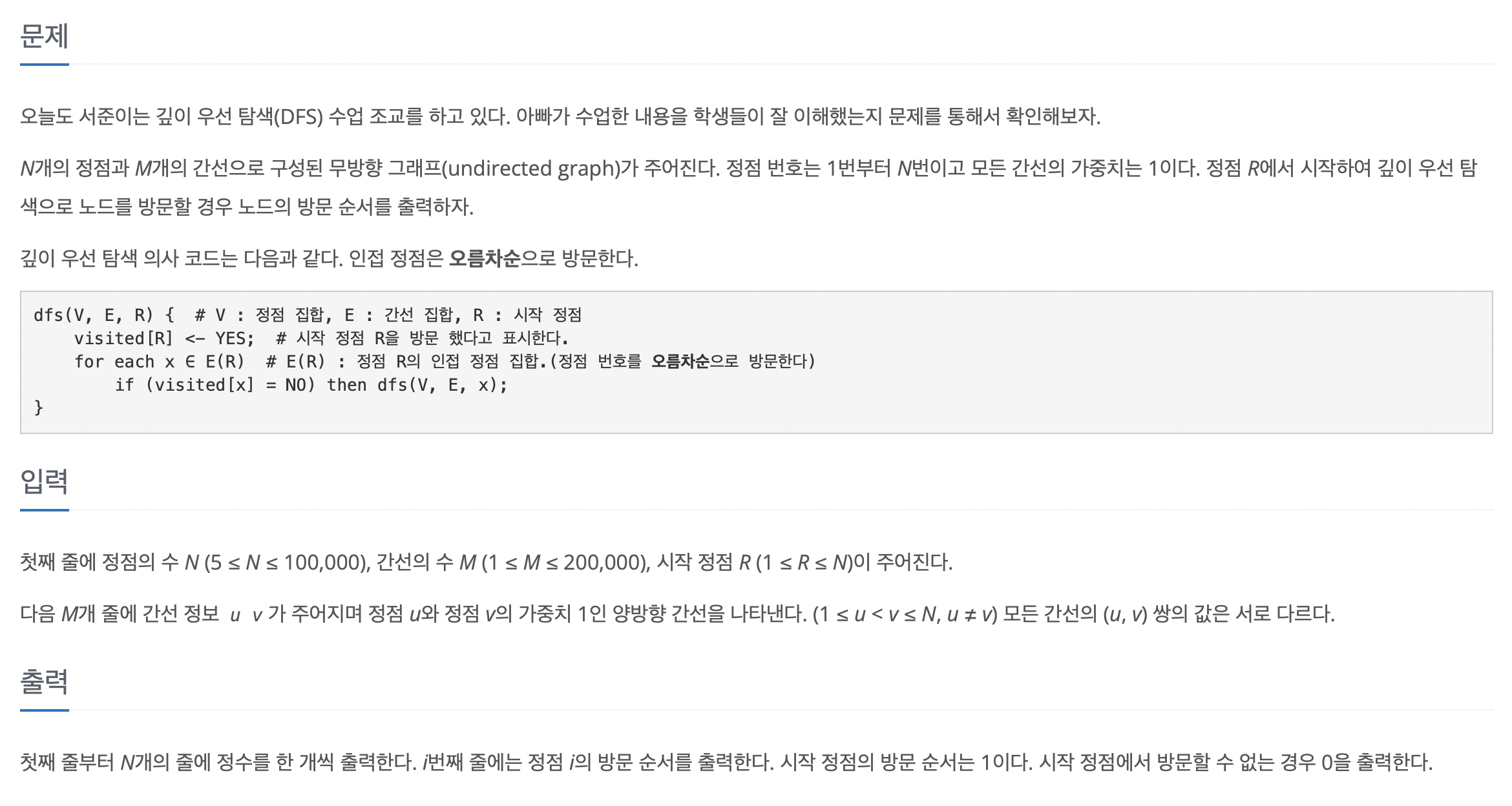
package baekjoon;
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStreamReader;
import java.util.*;
public class Main_24479 {
static ArrayList<Integer>[] graph;
static boolean[] visit;
static Map<Integer, Integer> map = new LinkedHashMap<>();
static int N, M, R, cnt;
public static void main(String[] args) throws IOException {
BufferedReader br = new BufferedReader(new InputStreamReader(System.in));
StringTokenizer st = new StringTokenizer(br.readLine(), " ");
N = Integer.parseInt(st.nextToken()); // 정점의 수
M = Integer.parseInt(st.nextToken()); // 간선의 수
R = Integer.parseInt(st.nextToken()); // 시작 정점
visit = new boolean[N + 1];
graph = new ArrayList[N + 1];
for (int i = 1; i <= N; i++) {
graph[i] = new ArrayList<>();
map.put(i, 0);
}
for (int j = 0; j < M; j++) {
StringTokenizer st2 = new StringTokenizer(br.readLine(), " ");
int u = Integer.parseInt(st2.nextToken());
int v = Integer.parseInt(st2.nextToken());
graph[u].add(v);
graph[v].add(u);
}
for (int i = 1; i <= N; i++) {
Collections.sort(graph[i]);
}
dfs(R);
for (int i : map.keySet()) {
System.out.println(i+" "+map.get(i));
}
}
public static void dfs(int start) {
if (!visit[start]) {
cnt++;
map.put(start, cnt);
visit[start] = true;
for (int i : graph[start]) {
dfs(i);
}
}
}
}
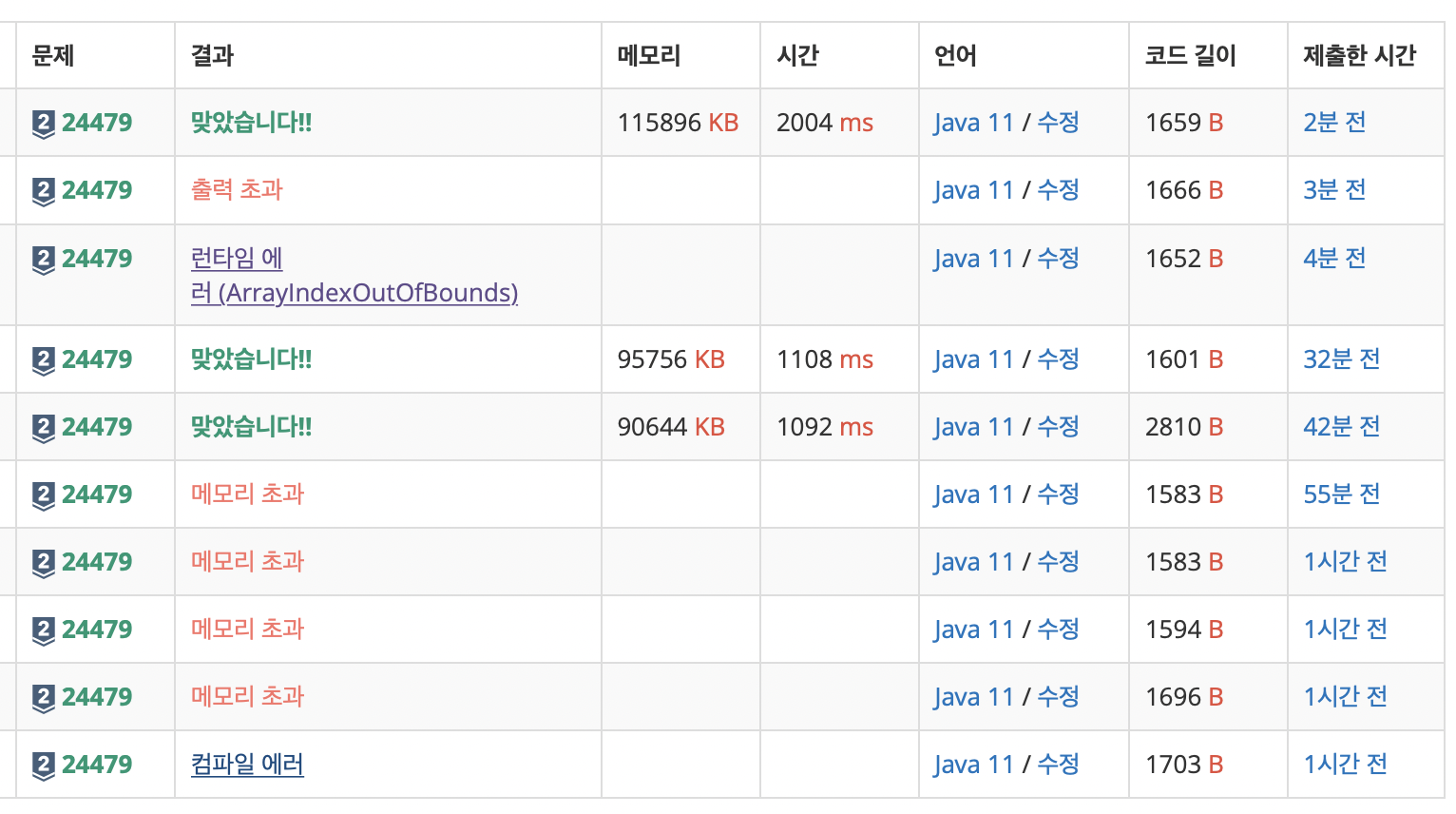
많은 시행착오가 있었다.
dfs는 항상 이차원 배열로 풀었는데 정점의 최댓값이 100,00이라 힙영역에 메모리 초과가 났다.
로직은 맞았어서 이차원 배열 > 리스트로 바꿔주니 문제 해결은 됐다.
나는 ArrayList 배열을 통해 풀었는데 다른 풀이를 보니 ArrayList<ArrayList> 이중 리스트로 푼 풀이가 많았다.
확실히 메모리나 시간쪽에서 차이가 많이 났다.ㅠ