
DB는
많은 데이터를 많은 사용자들이 동시에 사용할 때 필요함
(대용량의 데이터가 체계적으로 조직화되어있어야함)
규칙을 정해 놓고 데이터를 저장함
DB 시스템의 특성
-최초 적재 -> 이벤트에 따른 잦은 변경
쿼리를 이용해서 데이터베이스에 접근함
DBMS가 하는 일 사용자드이 sql문을 쓰면 그 문을 통해서 메타데이트를 통해서 디비의 구조 확인, 정보 빼서 유저에게 전달.
데이터베이스 - 데이터 및 데이터간 관계의 집합(관계까지 저장하고 있다!!)
DBMS - 사용자가 데이터베이스에 접근할 수 있도록 지원해주는 프로그램의 집합
질의(Query)
삽입, 삭제 , 갱신, 조회 쿼리
- 데이터베이스 인스턴스
-특정 시점에 데이터베이스에 실제로 저장되어있는 데이터
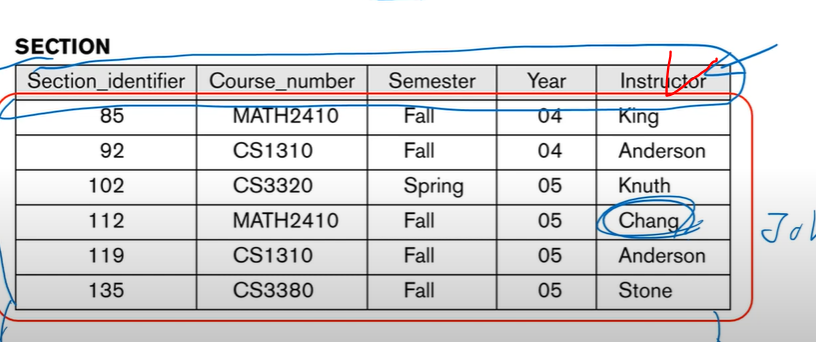
인스턴스 실제 값이 담기는 부분,
스키마는 껍데기.(행같은 느낌)
스키마를 만드는게 데이터베이스 모델링, 설계라고함
데이터베이스를 활용하기 위해 SQL 사용
DML 인스턴스에 대한 명령어 - 데이터의 조회, 삽입, 삭제 , 갱신 - 일반사용자가 사용.
DDL
: 스키마를 기술하기 위해 사용됨 - 테이블을 만든다던지, 칼럽을 만든다던지, 관계를 맺어준다던디.
DCL
TCL
데이터베이스의 설계 4단계
- 요구사항 분석
- 업무기술서 작성. 학생은 학번을 갖고, 성별을 명시한다~ 등등
- 개념적 설계(conceptual design)
-업무기술서의 내용을 서로 이해하기 좋겟끔 하는거 - 도식화로 표현가능
- 개체관계모형이 많이 쓰임 Entity = Relationship Model = ERM
- 개체관걔 모형의 결과로 나타나는 다이어그램을 ERD라고 한다.
- 이 다이어그램을 컴퓨터가 알아듣게 만드는걸 논리적 설계라고 함
- 논리적(Lofical design)
- 테이블 형태로 나타나는 모델 Relation Model 을 많이 씀
- 물리적 (PHYsical design)
- 실제로 구현하는 과정 (?)
-실제 디비안에 넣을때 고려해야되는 것들
*실무와 학교의 구분이 약간 다름
Relationship - □-△-□ 이것처럼 도식화(?)할때 △를 릴레이션쉽이라고 Relational - 표의 한행 한행 한행을 말함. 한글로 릴레이션 = 테이블
관계가 있다고 안함!!!
dm에서 관계라고 하면 Relationship 나타내는거임
ER Model Concepts
DB를 만들 때 제일 먼저 생각해야되는거 2가지, 중요한 것 2가지
-개체(Entity)
: 실세계에 존재하는 의미있는 하나의 정보 단위
: 물리적 객체 뿐 아니라 개념적 객체도 포함(학생자동차 강의실 프로젝트 직업 교과목)
-관계(Relationship)
: 개체들 사이의 연관성
- 학생과 교과목 사이의 수강 관계

학생이 동아리에 가입한다. 건물에 강의실을 포함한다.
ER에서는 개체인지 관계인지 애매한 것들이 있지만
Rleation으로 가면 고민할 필요가 없어짐 어처피 똑같아짐
-속성 (Attribute)
-개체 또는 관계의 본질적 성질
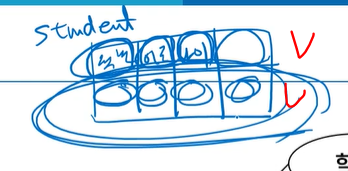
첫번째줄 - 속성
두번째줄 - 속성의 값 = 객체(인스턴스=속성값들의모임)
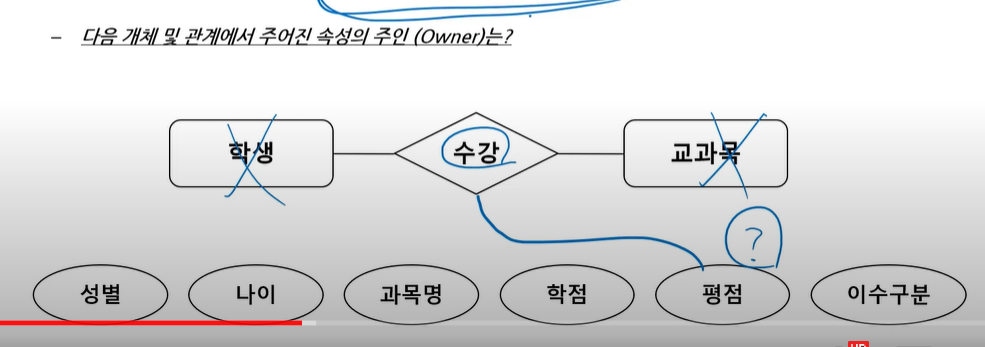
평점은 교과목의 속성인가 ? 애매하다. 어느 과목의 평점인지 알 수 없기 때문이다. 관계의 속성으로 가능하다. 수강이라는 것 자체가 홍길동이라는 학생이 자바를 수강한다는 이벤트 하나를 모델링하고 있음.
따라서 평점의 속상은 학생도 아니고 교과목도 아니고 수강이다 !
업무기술서를 토대로 ER모델만듬
Types of Attributes
- single-valued vs. Multivalued
하나의 값만 가지는 것을 싱글벨류라고 함
취미 같이 여러개 값을 가질 수 있는 것을 Multivalued라고 한다
-simple vs. composite
simple : 더 이상 쪼개지지 않는 원자값을 갖는 속성 나이학번등
composite attribute : 몇 개의 요소로 분해될 수 있는 속성
주소같은거. 시, 군, 구, 번지
둘 이상으로 나뉘어져도 의미를 갖는 것을 말함
주소를 composite attribute
주소 쪼갠거 하나하나를 simple attriute라고함
이래도 되고 저래도 되서 혼란스러움
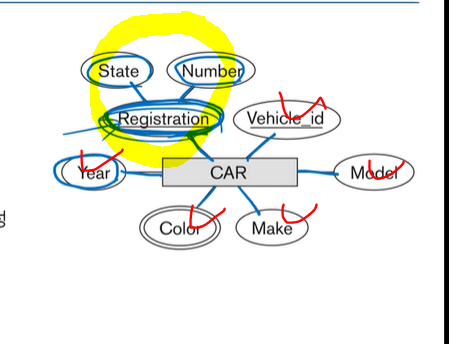
파란색 체크 - 심플
노란색 - 컴포짓, 심플
동그라미 두개 갖힌거 - 멀티면서 심플임
Stored vs . Derivde
-Derived Attribute - 저장된 다른 데이터로부터 유도 가능한 속성
국영수점수를 알면 총점과 평균을 알 수 있음
주민번호 앞자리 - 출생년도를 통해서 나이를 알 수 있음. - 나이 뽑기 가능
Derived Attribute 는 설계자가 판단해서 지정해야함
유도 안하고 물어보고 저장하면 Stored
유도하면 Derived
유도가 불가능해서 저장해야되는 얘임? Stored
유도 가능해서 저장 안해도 되는거임?? Derived

키는 3가지 조합으로 만들어짐.
키 속성
- 자동차 엔터티의 속성은 차량번호.
- 어떤 개체에 대해서 항상 유일한 값을 갖는 속성(또는 속성들의 집합)
유일하다라는 뜻 : 그 집단에서 겹치는 값을 가질 수 없는 속성
-주민번호 키속성가능, 이름과혈액형은 같은 사람이 있을 수 있으니까 키속성이 아님.

이때 키속성은 팀명+등번호임
단일키로 키속성이 어려운 경우 키 조합으로 속성이 가능함
Composite Attributes - 복합키
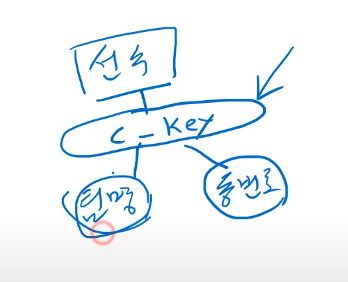
컴포짓키 자체로 의미를 갖지 않음 나중에 결국 저장되는건 팀명과 등번호임
복합키는 최소성을 가져야한다.
팀명+선수명+등번호 로 조합하면 더 안전하지 않을까?
유일성은 만족하나 최소성은 만족하지 않는 조합임
선수명안들어가도 되니까
복합키는 최소성을 가져야함
*conceptual에서 idenfy에서 의 특징임. 로지컬가면 달ㄹㅏ짐.
각 가체는 하나 이상의 키를 가질 수 있다.
어떤 개체는 키를 갖지 않을 수도 있음 : 약성개체(Weak Entity)
개체 = 엔티티
pk는 테이블 당 딱 하나씩 있어야함
conceptual에서 idenfy에서 의 특징임
데이터베이스를 설계하는 과정 - 요구사항 분석
엔터티 -> 관계 -> 속성
순으로 분석하기
1시간 46분부터보기
정규화 ★
목적 : 삽입/삭제/갱신 이상현상 방지
함수적 종속성에 기반하게됨
종류
1. 제 1 정규형 - 모든 값이 원자값을 가짐 - 원자값 : 더 이상 분해될 수 없는 값
2. 제 2 정규형 - 부분함수종속 제거
형액형 함수에 대해서 학번이 여러개 존재할 수 있음.
혈액형은 학번을 함수적으로 결정하지 못한다
학번은 혈액형에 함수적으로 종속되지 않는다.
학번이 1234학생한테 혈액형을 물어봄, 학생 한 명만 결정된 상태
학번은 혈액형을 함수적으로 결정한다.
혈액형은 학번의 함수적으로 종속된다. funtionally dependency FD 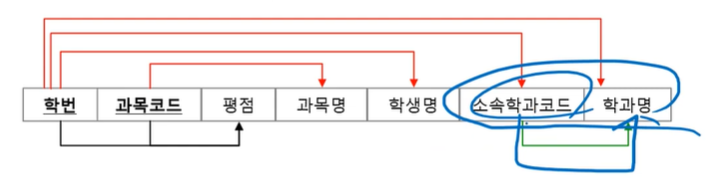
빨간색선 - 부분함수종속 (기본키에서 나가는 선임)
초록색선 - 이행함수종속 (기본키에서 나가는 선이 아님)
이행 : 간접적인 느낌. 소속학과코드는 학번과 학과명으로 연결되고 있음.
3정규형까지 끝나면 검정색선들만 남게됨. 제 3정규형 획득- 제 3 정규형 - 이행함수종속제거
→→→식별자가 아닌 속성(주식별자의 일부 또는 일반속성)이 결정자 역할을 하는 종속 제거 ->3NF
주식별자의 일부 : 부분함수
일반속성 : 이행함수
1차정규화를 하고 나면 제 1정규화가 된다.(1NF 라고함)
화살표의 출발지 : 결정자
도착지 : 종속자
1시간 15분 43초
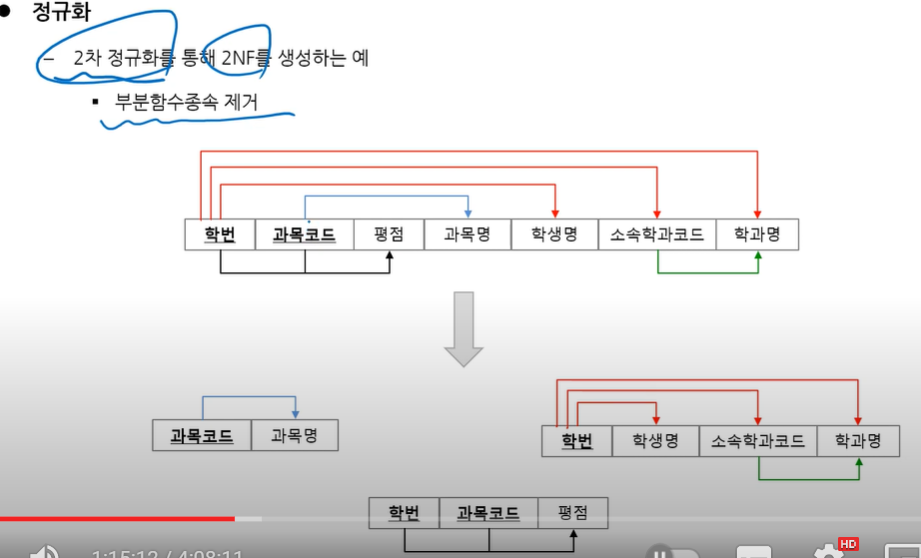
함수종속을 제거하는 큰 흐름은 자기네들끼리 다른 테이블을 만들면됨.
근데 우두머리(결정자)는 남아야함
부분함수 종속은 PK가 하나면 있을 수가 없다.
밑에 3개중 맨 아랫것은 부분함수종속이 있는데 평점을 결정한ㄴ 거 말고 다른 관계가 없어서
이 3개를 포함하는 전체 스키마는 제 2정규형을 만족한다 라고 할 수 있다.
3번째중 맨 왼쪽꺼는 제 1,2,3 정규형을 만족한다.
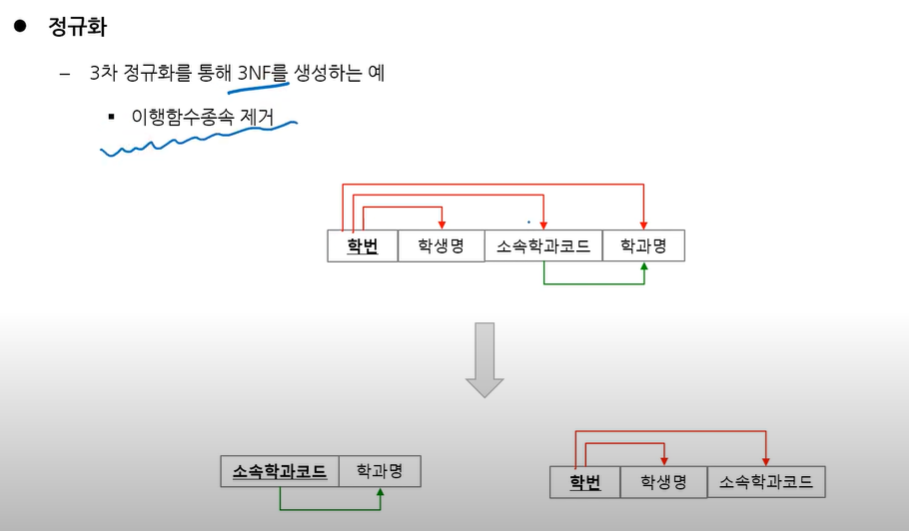
얘는 2정규형이지만 3정규형이 못 된다.
3정규형은 pk가 아닌 애가 화살표를 쏘면 안됨.
이 화살표를 없애서 테이블을 따로 만들어주면 이것들은 3정규형이된다.
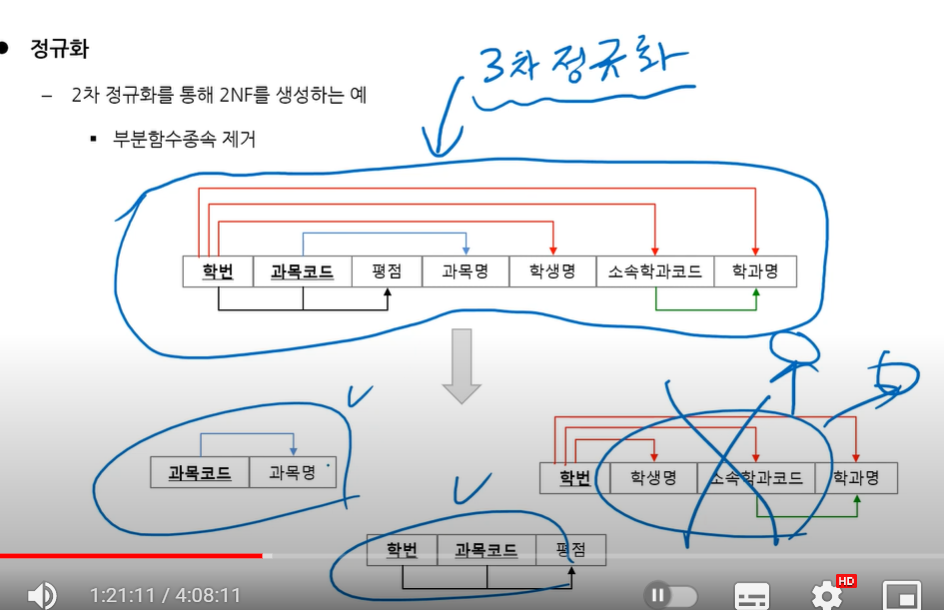
맨 처음 테이블을 3차 정규화까지 수행하고 나면 총 나오는 테이블 갯수는 4개이다!!
정규화의 효과
데이터 중속 감소 -> 성능 향상
데이터가 관심사별로 묶음 -> 성능 향상
조회 질의에서 조인이 많이 발생 -> 성능 저하
테이블을 건너 건너에서 정보를 빼내는거 그래서 성능 저하됨1시간 35분 45초 부터 반정규화
반정규화
●반정규화(역정규화=Denormalization)
-정규화를 했는데 성능상 문제로 다시 거꾸로 돌아오는 것
-정규화된 엔터티, 속성,관계에 대해 성능 향상 목적으로 중복, 통합, 분리를 수행하는 데이터 모델링 기법
(*참고 : 비정규화 - 정규화를 아예 수행하지 않음)
●특징
- 테이블, 칼럼, 관계의 반정규를 종합적으로 고려해야함
-일반적으로 속성(칼럼)중복을 시도
-과도한 반정규화 -> 데이터 무결성을 침해하게됨
반정규화의 사전 절차
-
반경규화 대상조사
-범위처리 빈도수 조사a=3 연산속도 빠름 1<a<5 (범위처리) 위에보다 시간이 걸림
-대량의 범위 처리 조사
범위에 걸리는 후보의 값이 많은가 적은가 -통계성 프로세스 조사
-테이블 조인 개수
이런것들을 조사해서 이 지점에 문제가 잇음 개선해도 되는거 아니야? 하는 부분임
- 다른 방법 유도 검토
-뷰(view) 테이블 - 신중하게 설계된 뷰를 재사용할 때 성능 향상
(뷰가 잘 만들어져야 성능향상이 됨. 뷰를 쓰면 무조건 성능 향상XX)
-클러스터링 : 자주 사용되는 테이블의 데이터를 디스크의 같은 블록에 저장
-인덱스의 조정 : 인덱스 추가, 삭제, 및 순서 조정
-응용 애플리케이션 : 데이터 처리를 위한 로직 변경
쿼리를 3번 물어볼거를 1번 물어본다던지
데이터 처리를 하기 위한 로직을 DB 가 아니라 프로그램 레벨에서 조절하면 성능이 향상 될 수 있지 않을까? 하는 아이디어에서 나옴
- 반정규화 적용
-테이블, 속성, 관걔의 반정규화
반정규화 기법
- 칼럼 반정규화가 대부분임
-중복칼럼, 파생칼럼, 이력테이블칼럼, PK의 의미적 분리를 위한 칼럼 추가, 데이터 복구를 위한 칼럼 추가(과거데이터 복구가 필ㅇ해서 부득이하게 ) - 테이블 반정규화
-테이블 병합, 분할, 추가 -중복 통계 이력 부분 테이블 추가
-없어도 되는데 성능상으로 추가함. - 관계 반정규화 -- 관계를 중복으로 추가한다.
반정규화 기법

마지막 - 성능보다 회복에 중점을 맞춘 기법-중복칼럼 추가 : 해당 테이블에서 자주 사용하는 칼럼을 중복시킴
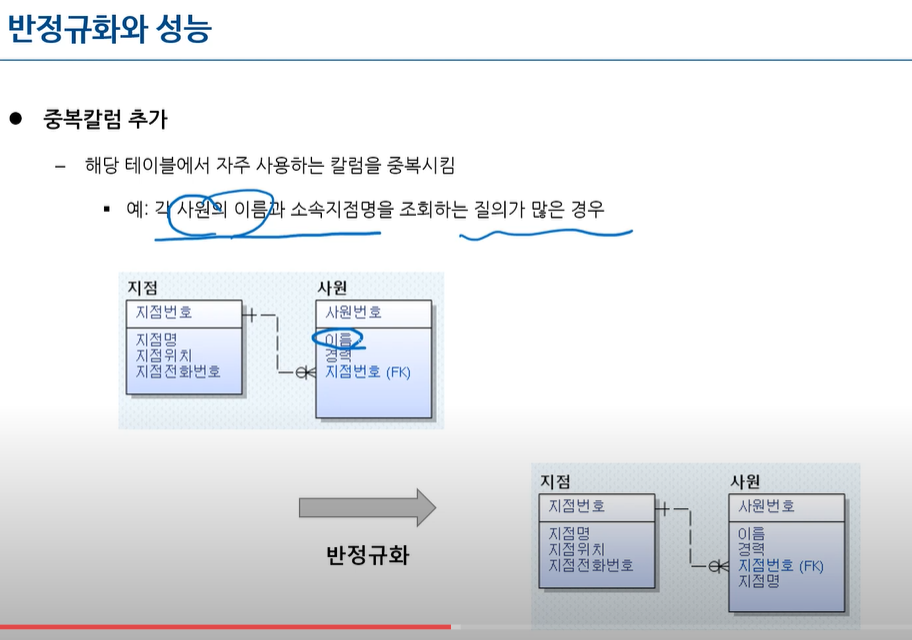
이름, 사번을 주고 어느 대리점에서 일하는지
첫번째 그림 : JOIN이 있는 상태 질의가 많으면 JOIN도 늘어남
양쪽 둘다 2정규화 테이블임
둘 다 부분함수 종속이 있을 수 없음
PK가 복합키가 아니고 단일키 이기 때문이다.
질의중에 조회하는 질의를 할 때 옆테이블과 조인이 많으면 중복칼럼 추가한다
-파생칼럼 추가 : 질의가 예상되는 값을 미리 계산하여 저장함
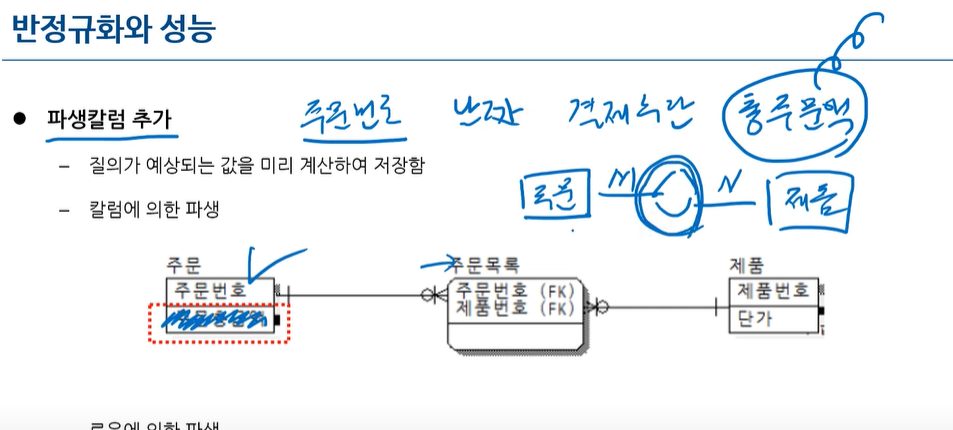
주문과 제품은 다대다 관계여서
주문목록이라는 관계 만듬
주문목록은 연관엔터티임
-속성을 저장하는게 목적이 아니고 연결관계를 나타내는것에 목적이 잇음
총금액을 알 고 싶은게 많을 테니까 계산해둬!!
DERIVED ATTRIBUTE (점선으로 있음)
■칼럼에 의한 파생!!
ROW에 의한 파생은 없음
-이력테이블칼럼 추가
: 이력테이블에 최근값, 종료여부 등의 칼럼을 중복으로 추가
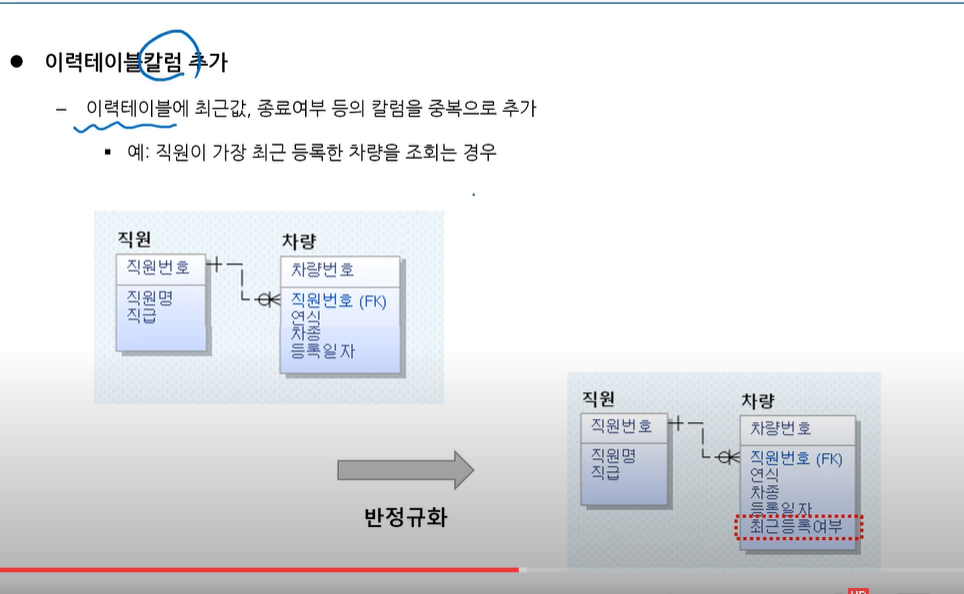
만약 차를 1년마다 한번씩 바꿀경우.
가장 최근에 등록한 차량 찾기
건물에 1대씩밖에 입장못함
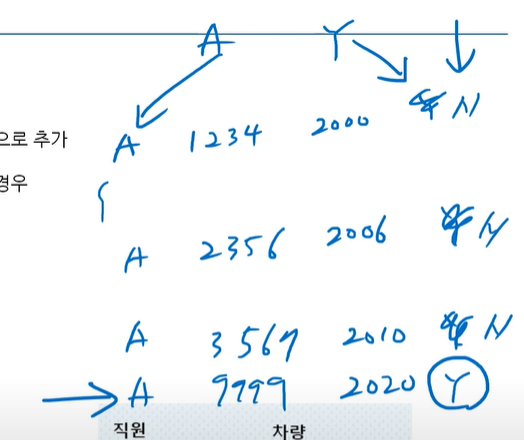
여러개의 레코드의 이력을 관리할 때 사용함. 최근 등록한 데이터를 조회할 때 사용함
등록할 때 마다 N->Y로 변경
-PK의 의미적 분리를 위한 칼럼 추가
: PK룰 활용할 슈 없음 -> 일반속성추가
-데이터 복구를 위한 칼럼 추가
: 사용자 의 실수 또는 응용프로개램 오류로 인한 데이터 손실 대비
-고객 정보 중 이전 주소 추가
A라는 사람이 이사를 걔속 할때 주소관리하는거를 이력테이블
있던 데이터를 지우고 새 주소 덮어 씌우는게 실수엿다면. 옛날 값을 복원하고 싶다면
바로 직접값을 보관함
이전값 복원 가능
반정규화 기법 - 테이블 반정규화
- 테이블 병합
- 관계 병합 : 1:1 1:M 병합
- 슈퍼/서브타입 병합
- 테이블 분할
- 수직 분할
- 수평 분할
- 테이블 추가
- 중복 테이블 추가
- 통계 테이블 추가 CLUOM SUM
- 이력 테이블 추가
- 부분 테이블 추가

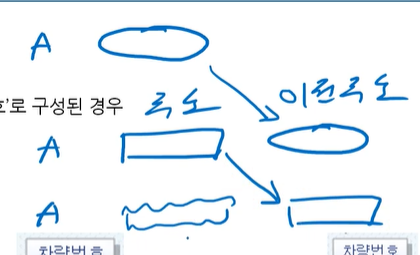
*수직분할 VS 부분 테이블 추가
수직분할은 테이블 2개가 되고
부부 테이블 추가는 원래 테이블, 추가된 테이블 생겨남(원본유지)
관계병합
- 두 테이블의 동시 조회가 많은 경우
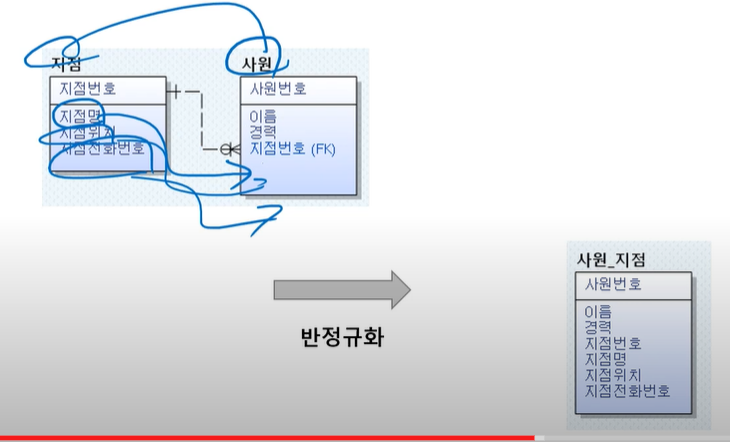
3->2 정규형으로 다운, 반정규화임
슈퍼/서브타입 모델의 변환
- 일반화 관계를 표현함
- 여러 엔터티의 공통 속성을 SUPER TYPE, 개별 속성을 SUB TYPE로 구성함
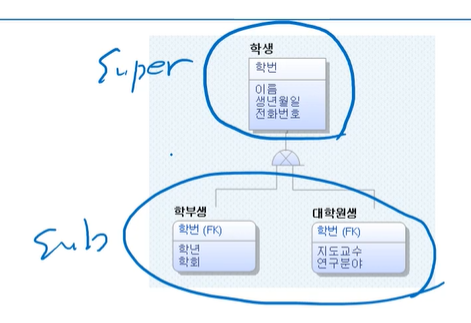
만약 학부생, 대학원생 둘다 학년이 중요하면 SUPER에 추가함
1:1
공통속성을 위로, 자식에서 공통속성이지 않은 속성을 일반속성으로 넣음
학부생 대학원
슈퍼 서브 타입은
학생+학부생 / 학생 대학원생 으로 테이블 만든거
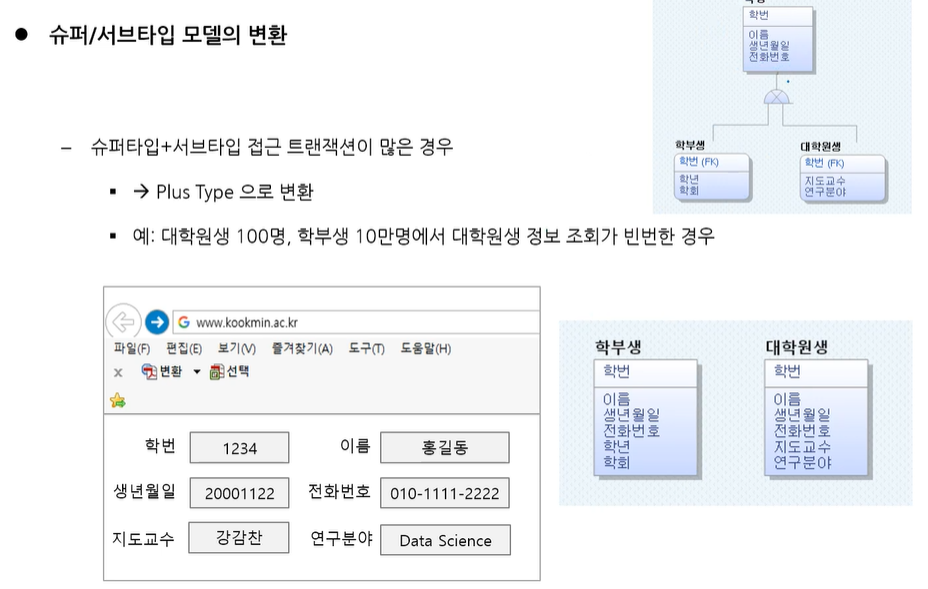
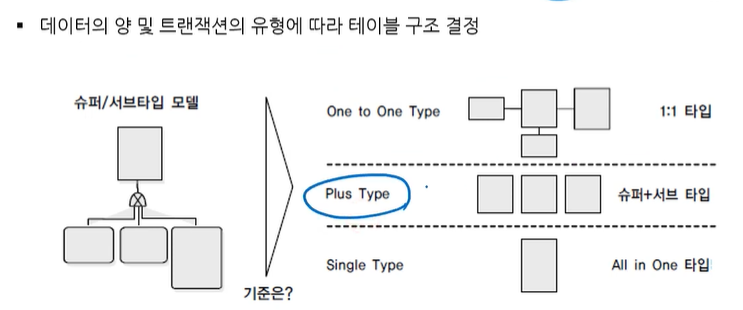
슈퍼+서브 합쳐서 조회하는 경우가 많은 경우 PULS TYPE
대학원생 100명 학부생 10만명에서 대학원생 트랜잭션(조회)가 많은 경우 슈퍼서브타입 만듬. 학부생 10만명까지 조회하게 냅둘 수 없으니까
근데 만약 학부생 조회가 많은 경우 그냥 냅둠 100명 양이 적으니까(?)
- 올인원 타입은 3개 다 합친거
1:1타입에서 슈퍼서브타입 올인원으로 바꾼게 비정규화임
-개별 접근 트랜잭션이 많은 경우 -> ONE TO ONE TYPE으로 변환
-여러 서브타입에 대한 동시 접근이 많을 때 -> ALL IN ONE TYPE으로 변환 ▼
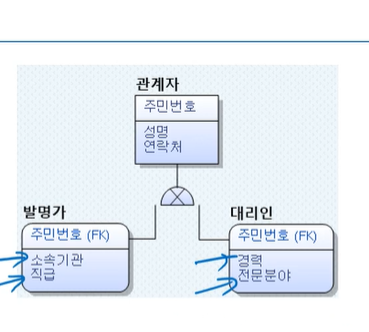
▷ 발명가+대리인 조회하는 트랜잭션이 많은 경우 올인원타입으로
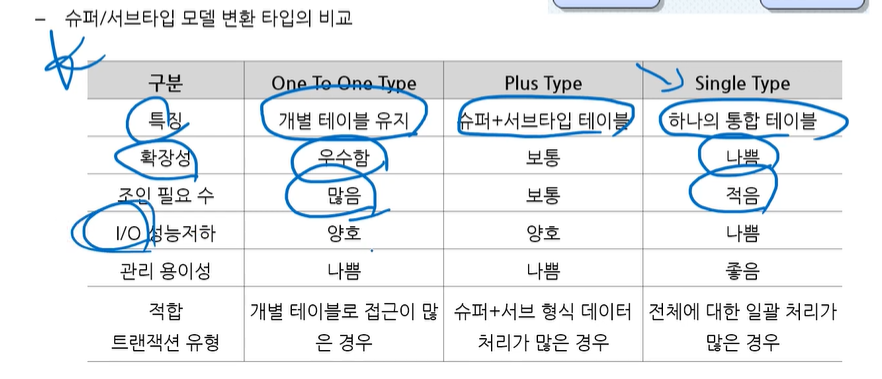
관리용이성 : 어떤 테이블이 관리하기 편한가?
(★싱글테이블의 장단점)
2:44:05
테이블 분할 절차
- 데이터 모델링 수행
- 데이터베이스 용량 산정
- 대량 데이터가 처리되는 테이블에 대해 트랜잭션 처리 패턴 분서
- 트랜잭션이 칼럼 단위로 집중되는 경우 수직 분할, 로두 단위로 집중되는 경우 수평 분할 수행
3:21:10
인덱스
SELECT 학번, 이름, 학년
FROM 학생
WHWER 학번>3000 AND 학번<5000
세로 가로 필터링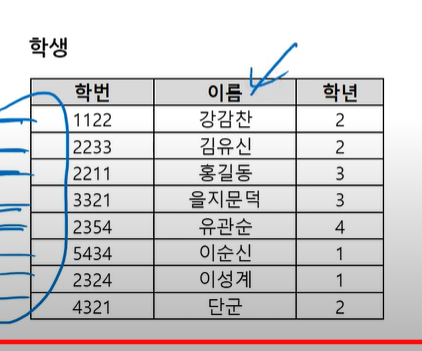
인덱스 테이블은 정렬이 안되어 있음. 무작위로 있다고 보면 됨
그래서 테이블을 전체 조회해서 찾고자 하는 정보 뽑아냄
위의 쿼리문 실행 >> 조건에 맞는 정보(2개)를 찾기 위해 전체 조회
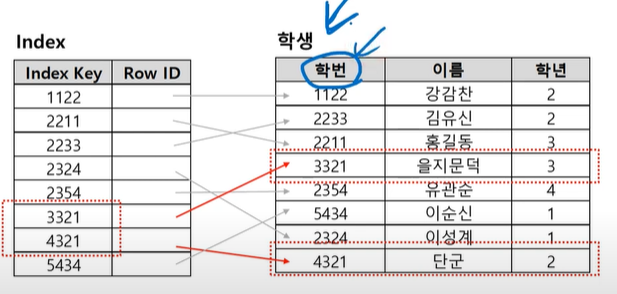
학번을 인덱스로 만들어서 정렬함
인덱스에서 학생 테이블로 이동.
컴퓨터가 정렬이 된 얘(인덱스)를 찾아감
검색의 조건으로 자주 사용되는 필드, 속성, 칼럼에 대해서는 인덱스를 생성한다
인덱스 생성 : 위와 같은 테이블을 만든다는 뜻
풀스캔을 하지 않고 해당 자료에 찾아가게 하는 것
그 칼럼에 대해 인덱스를 만듬
검색 속도의 향상을 위한 기술 -> 실제 테이블을 FULL SCAN하지 않고 테이블을 검색
지나치게 많은 인덱스 생성시 시간 및 공간 낭비
인덱스된 필드의 업데이트시 시간 증가
자동 생성(PK또는 UNIQUE 조건) / 수동 생성(CREATE INDEX 구문)
-PK를 만들면 자동으로 인덱스 생성됨
-유니크도 아니고 PK도 아니면 수동생성
시간낭비 공간낭비를 감수하더라도 검색속도 향상을 위해서 그 칼럼에 대한 인덱스를 만듦
인덱스의 구조 이해 - PK의 속성 순서대로 인덱스가 정렬됨
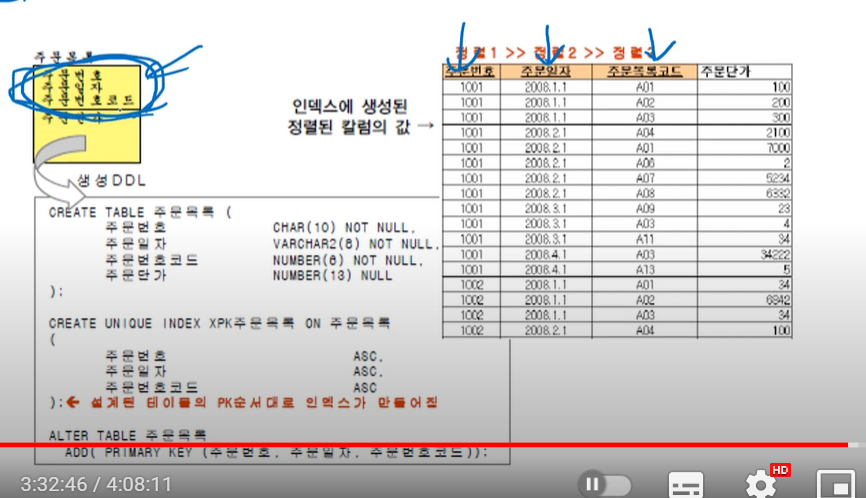
주문번호의 PK 순서대로 인덱스가 정렬 됨.
그래서 PK의 순서가 중요함
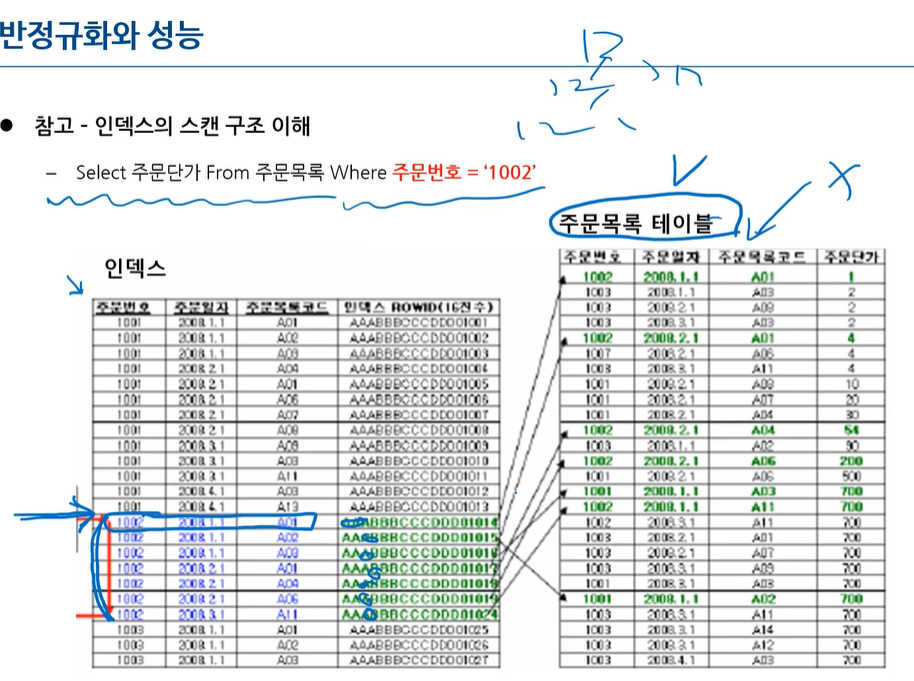
주문번호 1002번 찾아야될 때 인덱스에서 1002번만 읽고 그 주소에 맞는 자료 찾아감
만약 주문일자를 찾는거면 인덱스 테이블을 풀스캔해야함
자주 조회되는 트랜재션을 고려해서 PK순서를 고려해야함
FK 인덱스 설정을 통한 성능 향상
FK는 인덱스가 자동으로 걸리지 않음
~~ PK가 아닌 곳에 인덱스를 걸어서 성능향상 시키는 예시.
~~ 대부분의 이런 경우는 FK일 경우가 많다
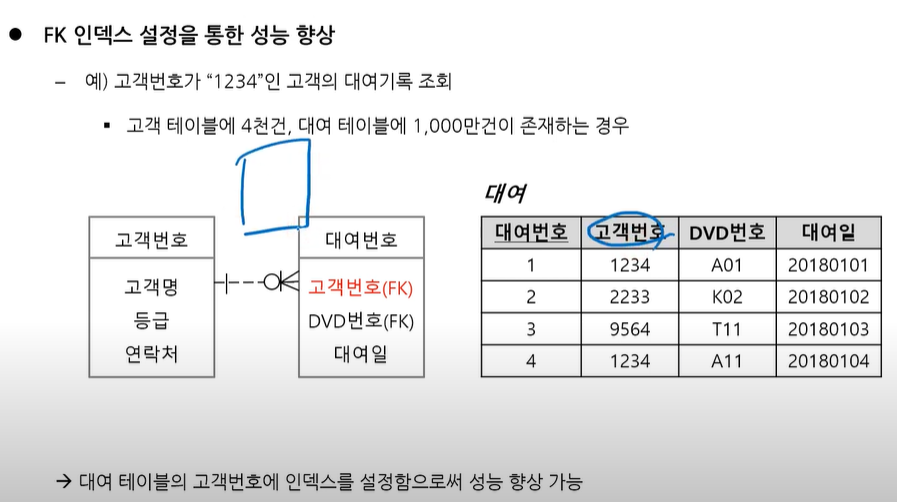
대여번호는 PK라 인덱스가 걸려있다
해당자료에서 고객번호가 1234인 고객의 대여기록을 조회하고자 하면
대여테이블을 풀스캔하게된다.
고객번호는 PK도 아니고 유니크도 아니지만 고객번호 순으로 인덱스를 만들자!
분산 데이터베이스의 개념
- 물리적으로 분산된 데이터베이스를 하나의 논리적 시스템으로 사용 3:48:40
