컴퓨터비전 PPT 요약
1. 목적
rtdetr의 모델 이해 + 코드를 분석하고 개선 + 하이퍼 파라미터 튜닝 + 커스텀 데이터 셋 적용
2. rtdetr의 모델 이해
1. 전체적인 구조
backbone : feature map 추출
encoder : 참조점, 모델 예측
decoder : pred_bbox, pred_label
postprocess : top_query 중에서 matching 알고리즘을 통해 예측 점 생성
loss : loss_vfl(uncertainly query selection과 밀접한 연관), loss_bbox, loss_giou
2. backbone
presnet feature s3,s4,s5 추출 크기가 서로 다름. 위로 갈수록 더 다양한 feature를 추출
1x1 convolution을 통해 demension을 동일하게 설정
3. encoder
AIFI
s5 를 AIFI 를 통해 F5를 추출 (s5만 AIFI를 통과시키는 이유 : 모든 특징들을 통과시킬 경우 feature들이 중복되는 computation 중복성이 발생한다. 이를 5가지의 연구 결과를 보여주면서 설명)
CCFF
그렇게 추출된 s3,s4,f5를 가지고 CCFF를 통과시킨다. cross-scal fusion module을 기반으로 optimized한 모델. (피라미드 형태의 feature맵을 fusion하는 module)
scale이 큰 feature 맵은 conv 1x1, batch normalize, SiLU활성화함수를 통과시켜서 스케일을 맞춰주고,
scale이 큰 feature맵은 conv 3x3, batch normalize, SiLU를 통과시켜서 스케일을 맞춰줌.
그렇게 완성된 feature들에 대한 정보들을 sequencial하게 만들어서 출력함.
4. decoder
1. enc_topk_bboxes
input :
enc_topk_bboxes = F.sigmoid(reference_points_unact)
reference_points_unact (encoder에서 추출한 참조점들을 이용해서 enc_topk_bboxes를 생성
Shape: [4, 300, 4]
배치 크기 4 (batch_size=4)
각 배치에 대해 300개의 상위 예측 박스 (num_queries=300)
각 박스는 4개의 좌표값을 가짐 (일반적으로 중심 좌표 cx, cy와 너비 w, 높이 h)
Values:
좌표값이 sigmoid 함수를 거친 결과로, 0~1 사이의 값.
예시:
첫 번째 박스: [0.0461, 0.7061, 0.0505, 0.0507]
중심 좌표 (cx=0.0461, cy=0.7061)
너비 및 높이 (w=0.0505, h=0.0507)
2. enc_topk_logits
input :
enc_topk_logits = enc_outputs_class.gather(dim=1, \
index=topk_ind.unsqueeze(-1).repeat(1, 1, enc_outputs_class.shape[-1]))
enc_outputs_class에서 상위 enc_topk_logits를 선택.
Shape: [4, 300, 80]
배치 크기 4
각 배치의 300개의 쿼리에 대해 80개의 클래스 점수를 포함 (80은 클래스 개수).
Values:
점수는 클래스별로 logits 형태로 표현되며, 값의 범위는 음수로 되어 있음.
예: [-4.1671, -3.5944, -3.9530, ..., -4.2104, -4.4524, -5.1099]
logits는 softmax를 거치지 않은 값으로, 상대적으로 큰 값이 높은 확률을 나타냄.
각 박스에 대해 80개의 클래스 점수 중 최댓값이 높은 것이 상위 클래스로 예측됨.
outputs :
if self.training and self.aux_loss:
out['aux_outputs'] = self._set_aux_loss(out_logits[:-1], out_bboxes[:-1])
out['aux_outputs'].extend(self._set_aux_loss([enc_topk_logits], [enc_topk_bboxes]))out['aux_outputs']를 생성.
3.outs
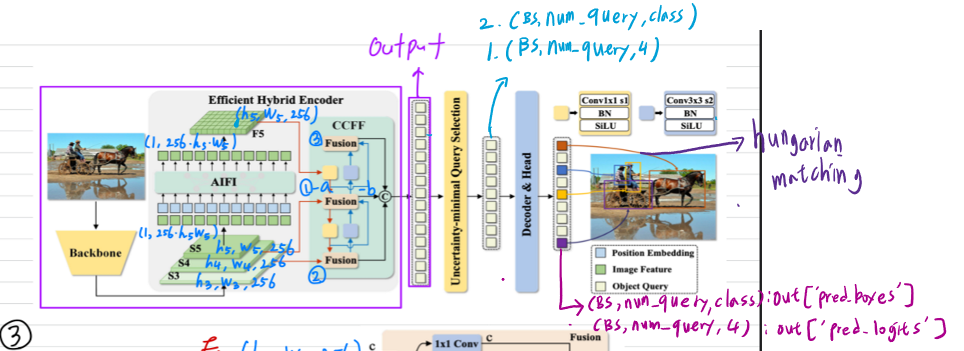
5. postprocess
헝가리안 알고리즘
3. 가설 설정
-
uncertainly query selection을 줄이기 위한 방식이 과연 optimal한가? 단순히 class, bbox사이의 거리로 판단하는게 옳은가?
-
현재 SOTA 모델인 D-fine모델을 보면서, 각 좌표에 대한 bin을 10으로 나눠서, 적분을 통해 더 정확한 좌표값을 선택할 수 있음.
-
이를 rtdetr 모델에 정의 (enc_topk_bboxes를 10개의 bin으로 나눠, batch, num_query * 10 , 4) 로 만들고, 이를 기댓값(0~1)이랑 좌표를 곱해서 좌표를 더 정확히 설정
4. 실패
- 단순히 enc_topk_bboxes, enc_topk_logits로 pred_bbox가 생성되는게 아님. 이를 통해 aux_bbox가 생성.
- 또한 decoder를 통해 생성되므로, 이를 바꾸게 되면 다른 모든 decoder에 생성되는 설정들을 변경해야함
- 따라서 decoder를 d-fine 모델로 변경해봄
- 성능이 낮아짐. 그 이유로 loss_fgl, loff_ddf를 고려해서 학습이 이뤄지는데, 이에 대한 back propagation이 이뤄지지 않으니까 오히려 성능이 더 감소함
5. 하이퍼 파라미터 튜닝
rtdetr의 기본 모델의 하이퍼 파라미터를 튜닝하는 방식을 함
