
해당 글은 AWS Korea의 Webinar for Data 시리즈 중 ‘키 디자인 패턴’ 영상을 정리한 글입니다.
Amazon DynamoDB 키 디자인 패턴 - 이혁, DynamoDB Specialist Solutions Architect, AWS
DynamoDB의 중요 컨셉
DynamoDB 테이블 구조
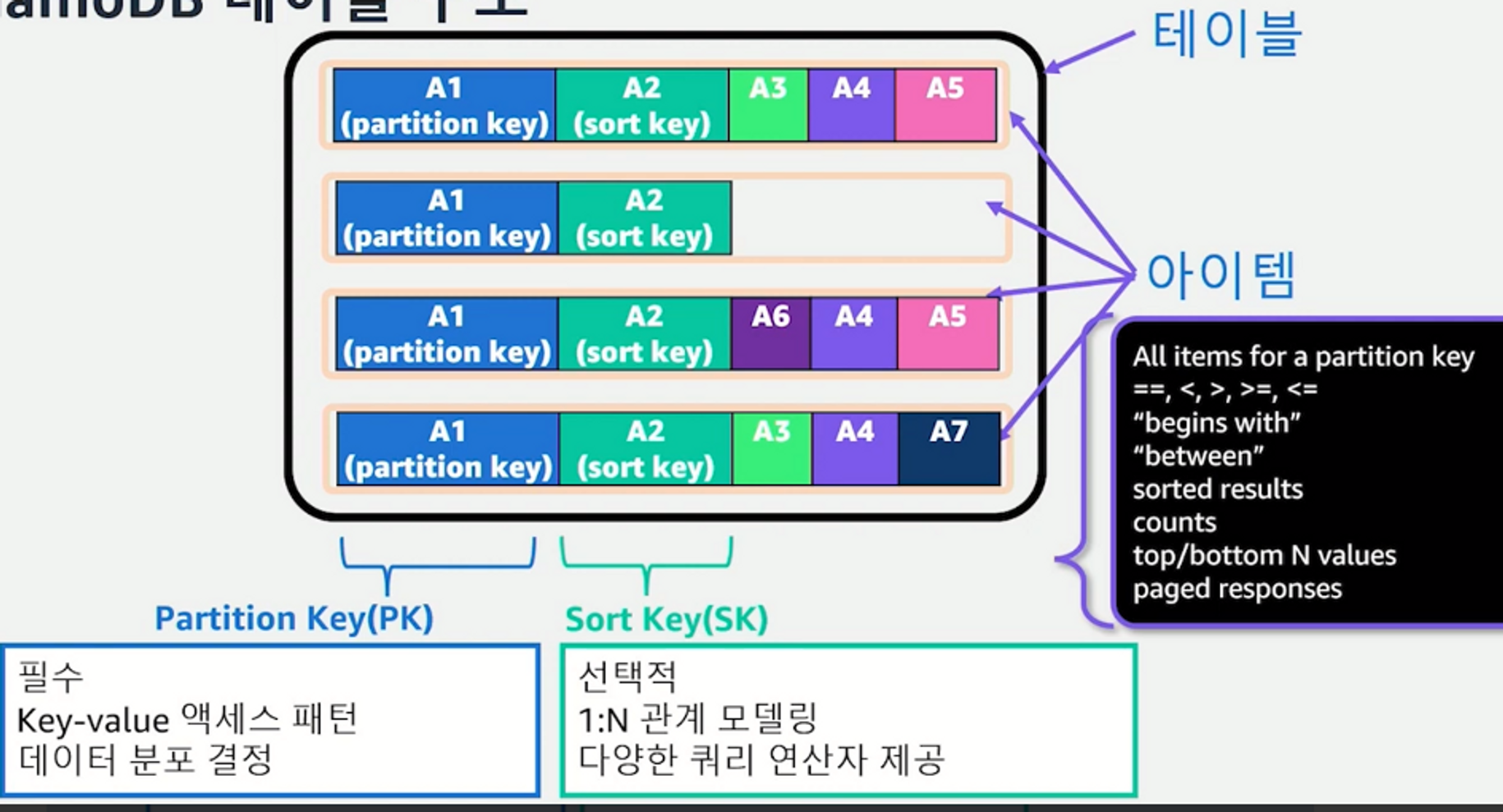
-
가장 큰 단위는 ‘테이블’.
- 논리적으로 생각할 수 있는 모든 데이터를 담을 수 있는 그릇 같은 개념.
- 하나의 테이블에는 무한대 가까운 아이템을 입력할 수 있다.
-
Item은 여러 개의 attribute로 구성 되어 있다.
- Item은 보통 RDBMS에서는 ROW라고 부르는 것과 비슷한 개념.
- attribute는 RDBMS에서 COLUMN이라 부르는 것과 비슷한 개념.
-
PK (partition Key)
- 테이블 생성 시 PK는 필수적
PK는 실제 데이터가 들어가는 위치를 결정하며, 데이터를 찾을 때 PK를 이용한다.- 테이블을 만들 때 파티션 키를 설정하면 데이터가 들어올 때 파티션 키 내부의 해시 함수를 돌려서 데이터가 어디로 저장될 지에 대한 해시값(주소값)을 반환한다. 그리고 데이터 조회할 시 이 주소값으로 데이터를 찾는다.
- 즉 무한하게 많은 파티션 중에서 내가 찾고자 하는 데이터가 어느 파티션에 있는지 찾아갈 수 있도록 도와주는 역할을 하며,
- PK가 있기 때문에 테이블에 크기가 백 테라바이트 혹은 백 페타바이트가 되어도 동일한 시간에 특정아이템을 검색할 수 있게 된다.
- ‘해시 속성 혹은 해시키’라고도 불리며
- 파티션 키 사용시 동일한 두 개의 데이터가 같은 위치에 저장될 수 없다. (같은 위치에서는 파티션 키 중복 불가)
- 항상 equal 연산자만 사용 가능
-
SK (sort Key)
- 테이블 생성 시 SK는 선택적
- SK를 이용해 동일한 PK 안에서 1 대 N 관계 모델링을 할 수도 있고, SK 값은 오름차순 혹은 내림차순 정렬 순서로 데이터를 조회할 수 있다.
- 특정 값으로 시작되는 데이터를 찾을 때 begins with, 범위 검색을 할 때 between, 그리고 등호 연산자 사용 가능
Primary Key의 중요성
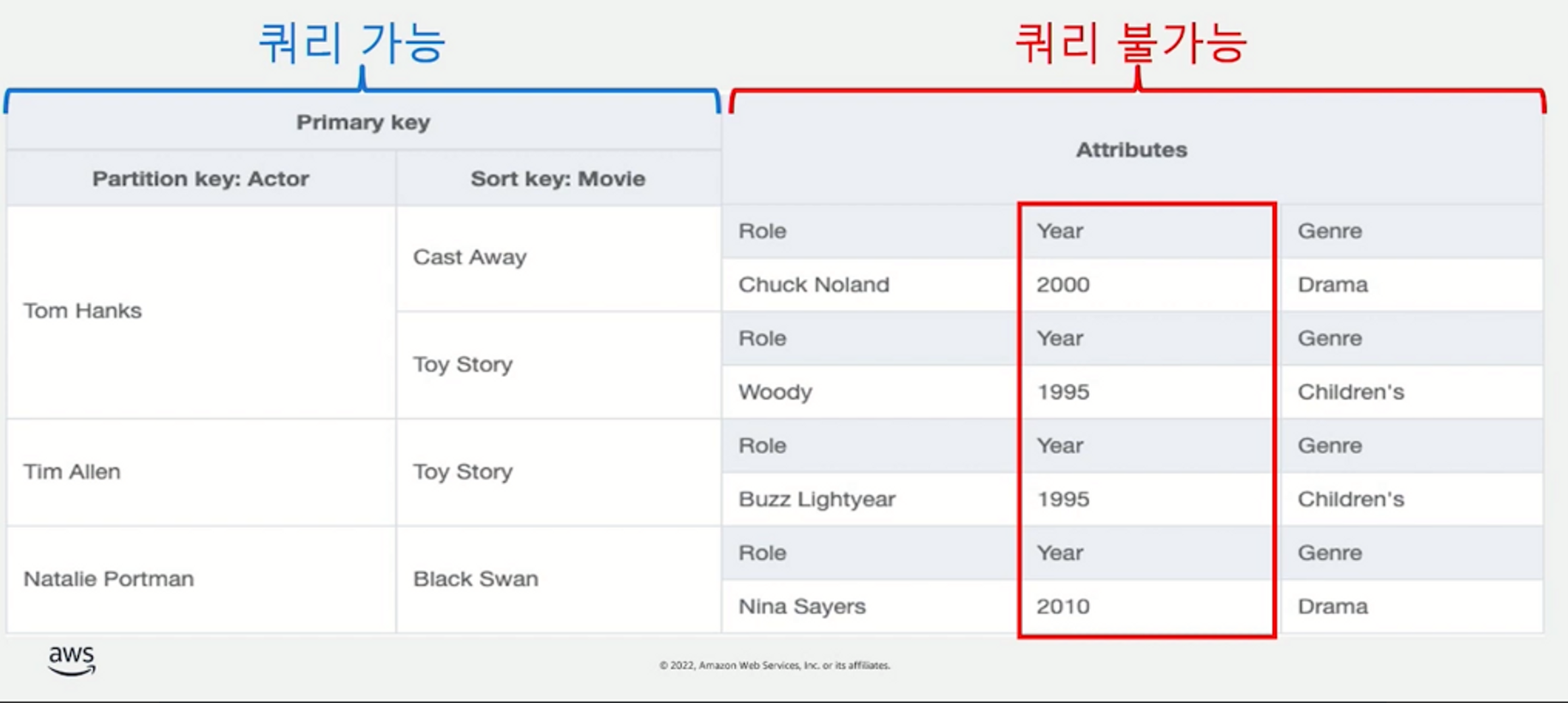
- Primary Key = PK + SK
- DynamoDB에서는 PK와 SK를 합쳐 Primary key란 용어로 부른다.
- DynamoDB에서 이 프라이머리 키가 중요한 이유는 오직 Primary key를 통해서 데이터 검색이 가능하기 때문
( 물론 Scan API는 예외지만 일반적으로 우리가 프로덕션 환경에서 OLTP 용도로 사용할 수 있는 API에서는 프라이머리 키가 없으면 데이터 조회가 안된다고 생각해야 한다고 함 ) - 그렇기 때문에 어플리케이션이 어떻게 데이터를 CRUD하는지에 대한 액세스 패턴에 대한 이해가 RDBMS보다 매우 중요할 수밖에 없다.
++ 참고 : OLTP / OLAP란?
https://code-lab1.tistory.com/267
데이터베이스 스케일링
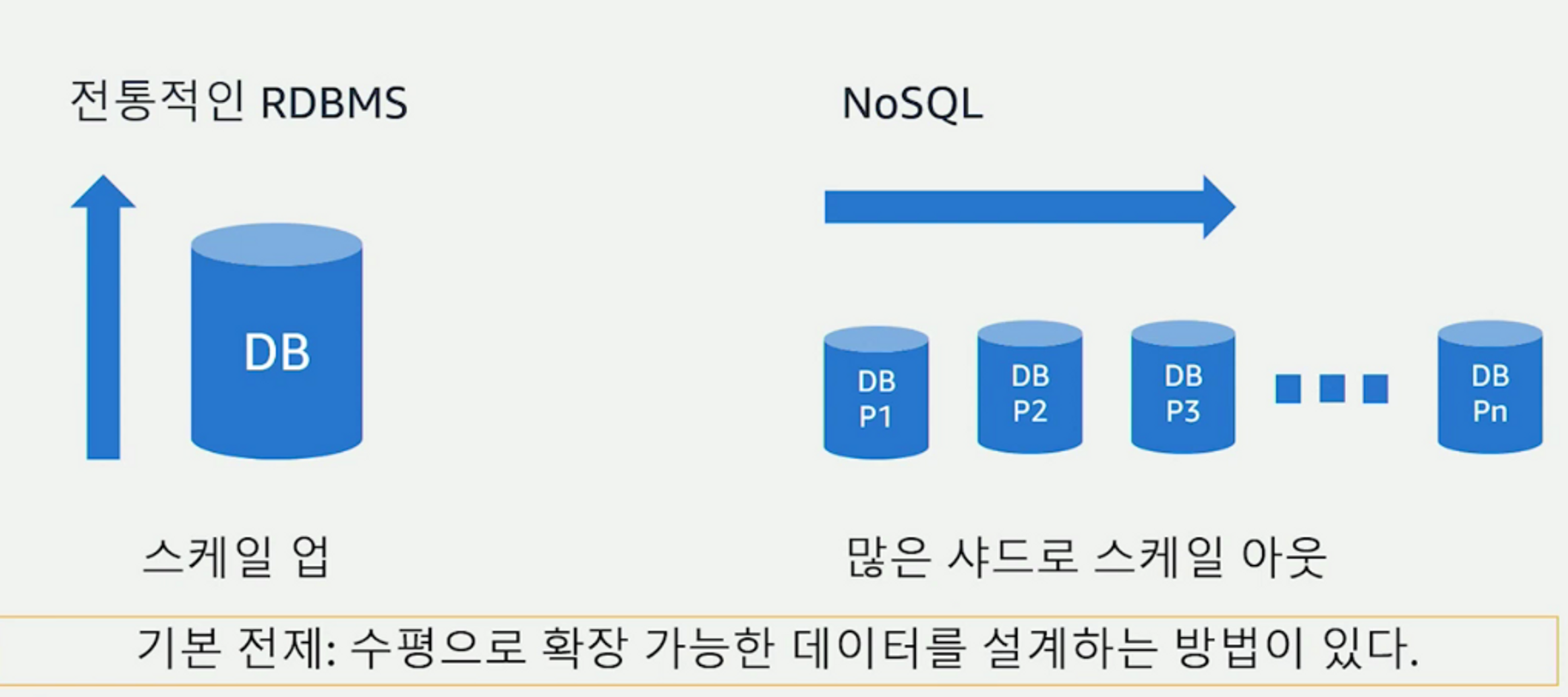
-
트래픽이 증가했을 때 우리는 스케일링을 생각하게 된다. 그런데 RDBMS와 NoSQL은 시작된 시점과 시대적 배경이 다르기 때문에 스케일링에 대한 서로의 목표가 다를 수밖에 없다.
-
많은 곳에서 사용하고 있는 RDBMS는 높은 성능이 필요한 경우 스케일업(Scale-up)을 선택할 수밖에 없다. 특히 오픈소스 RDBMS에서는 피할 수 없는 제약이다. 왜냐하면 단일 머신의 스케일업은 한계가 있기 때문.
-
하지만 NoSQL은 처음부터 대규모 트래픽을 목적으로 만들어졌기 때문에 더 많은 성능이 필요한 경우 스케일아웃(Scale-out) 전략을 사용한다. 이론적으로 무한대 머신까지 스케일아웃 할 수 있는 구조를 갖도록 설계 되어있다.
⇒ 그렇다면 여기서 우리가 고민할 부분은 ‘수평으로 무한대 가깝게 확장 가능한 데이터를 어떻게 설계할 것인가?’ 이다.
오른쪽 그림처럼 noSQL은 성능이 작은 머신을 스케일 아웃해 나가며 각 머신들을 동시에 골고루 잘 사용할 수 있도록 해야 된다. 트래픽이 특정 머신에 몰리거나 하면 안된다.
이것이 RDBMS와 키 디자인에 있어서 다른 특징 중 하나이다.

- DynamoDB에서 테이블 단위로 데이터를 읽고 쓰는 작업을 하면, 논리적인 테이블 아래에는 실제 물리적인 서버 위에 파티션이라는 단위로 컴퓨팅 작업이 수행된다. 이러한 파티션 관리는 DynamoDB가 알아서 처리하고, 다른 테이블이 만들어져도 이는 동일하게 처리된다.
- 여기서 중요한 점은, 각 파티션의 단위는 초당 천 개의 쓰기(1K WCU), 3,000개의 읽기(3K RCU), 10GB 데이터를 저장할 수 있는 제약조건이 있다는 것이다. 이는 키 디자인 시 항상 기억해야할 매우 중요한 제약 조건 중 하나다.
DynamoDB 수평적 스케일링
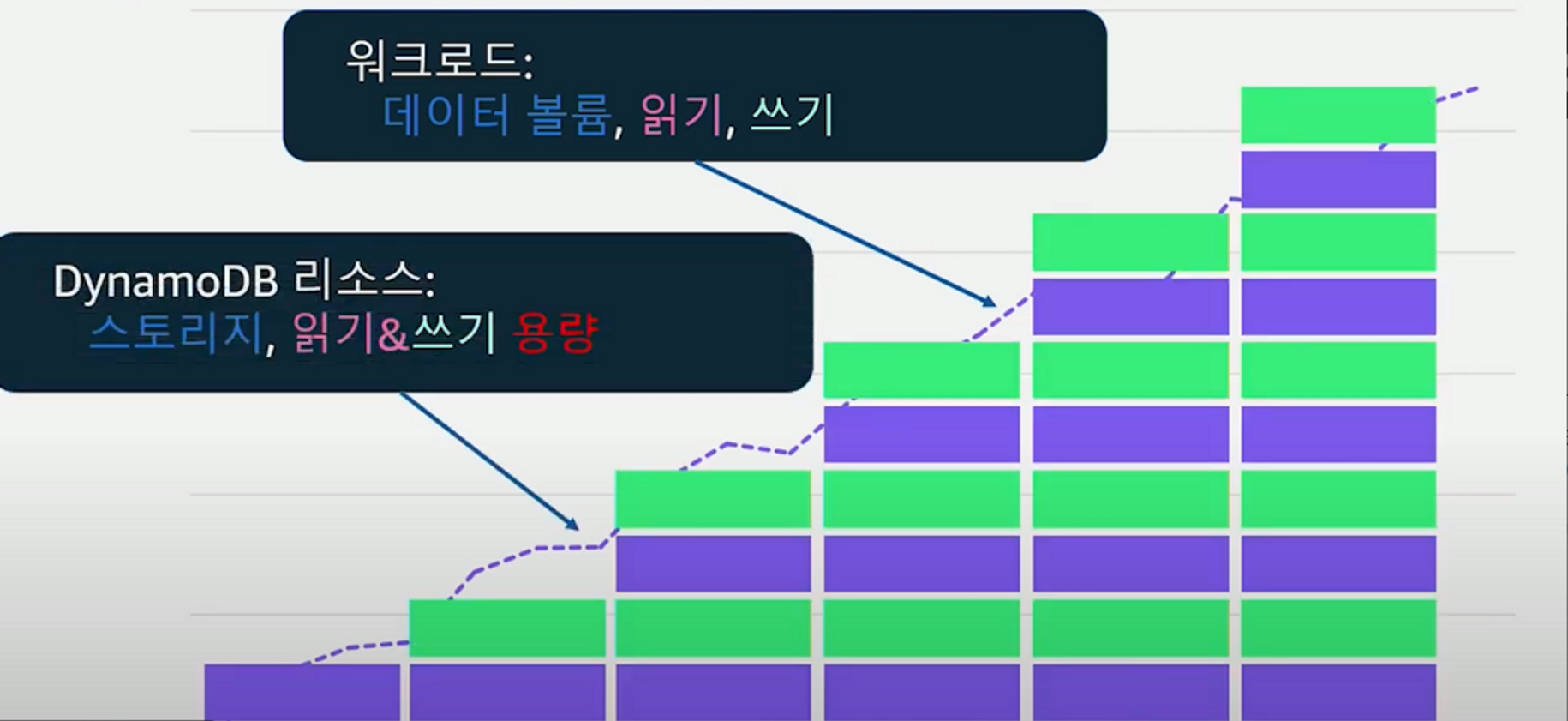
- DynamoDB 테이블은 트래픽이 늘어나면 그림과 같이 테이블에 저장되는 총 데이터양, 총 읽기 및 쓰기 처리양에 따라서 테이블 안에 존재하는 파티션의 개수가 늘어난다. 그러나, 파티션에 개수가 들어간다는 것은 해당 테이블이 제공하는 최대 처리량이 늘어난다는 것이지 앞서 살펴본 하나의 파티션에서 제공되는 처리량은 절대로 변하지 않는다.
⇒ 그래서 여러 개의 파티션이 골고루 동시에 사용될 수 있도록 키디자인 하는 것이 중요하다.
이상적인 아이템 분포란?

만약 위의 그림처럼 OrderId가 PK(partition key)라고 해보겠다.
만약 이 PK값을 테이블에 그대로 입력한다면 파티션 A로 모든 데이터가 몰리게 될 것이고, 운영 환경에서 파티션 B와 C는 아무런 역할도 하지 않고 놀게 될 것이다.
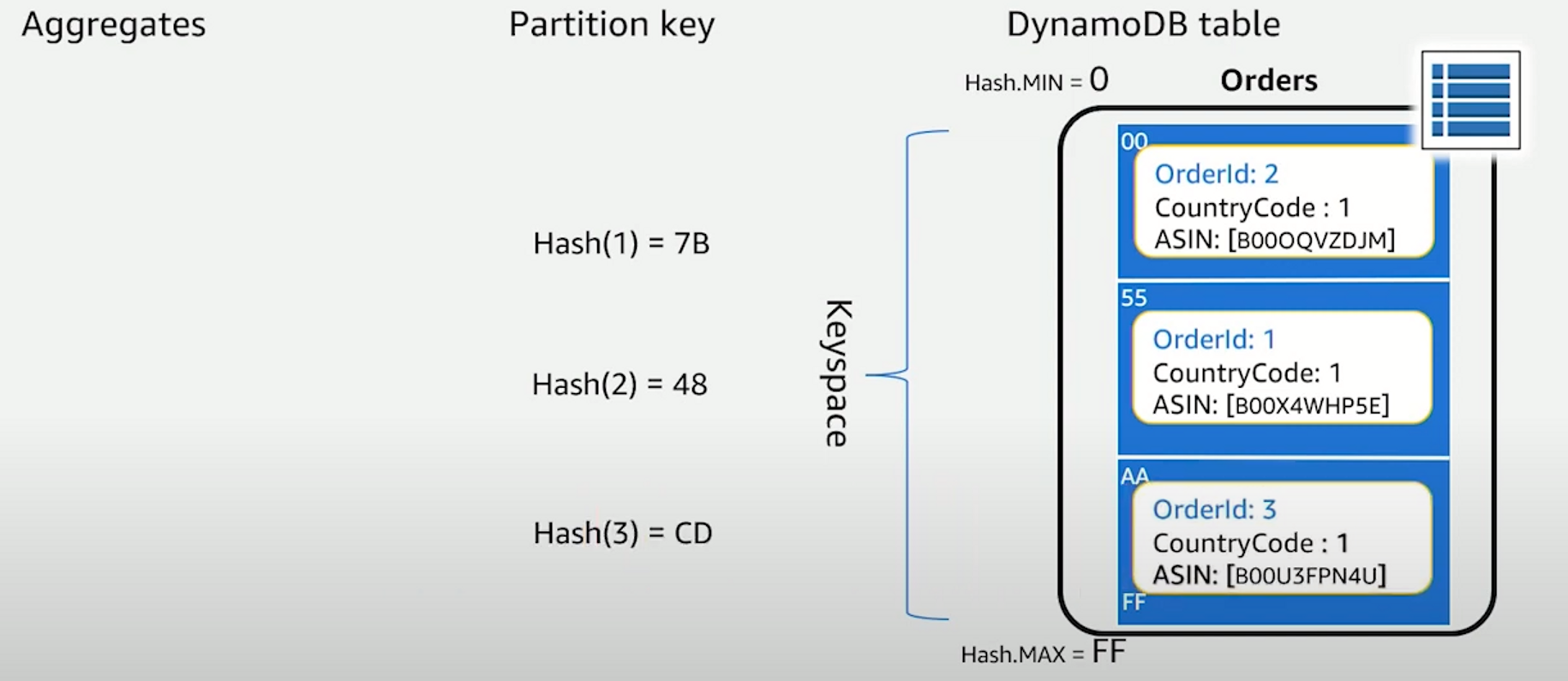
따라서 DynamoDB는 파티션에 데이터를 입력하기 전에 PK 값으로 해시 함수를 실행하고 나온 해시값을 기준으로 파티션에 위치시킨다.
최대한 사용자의 데이터를 여러 개 파티션에 나누어 저장하려고 노력하는 것. 따라서 우리는 여러 개 파티션을 골고루 잘 사용할 수 있도록 키 디자인을 해야한다.
데이터 복제
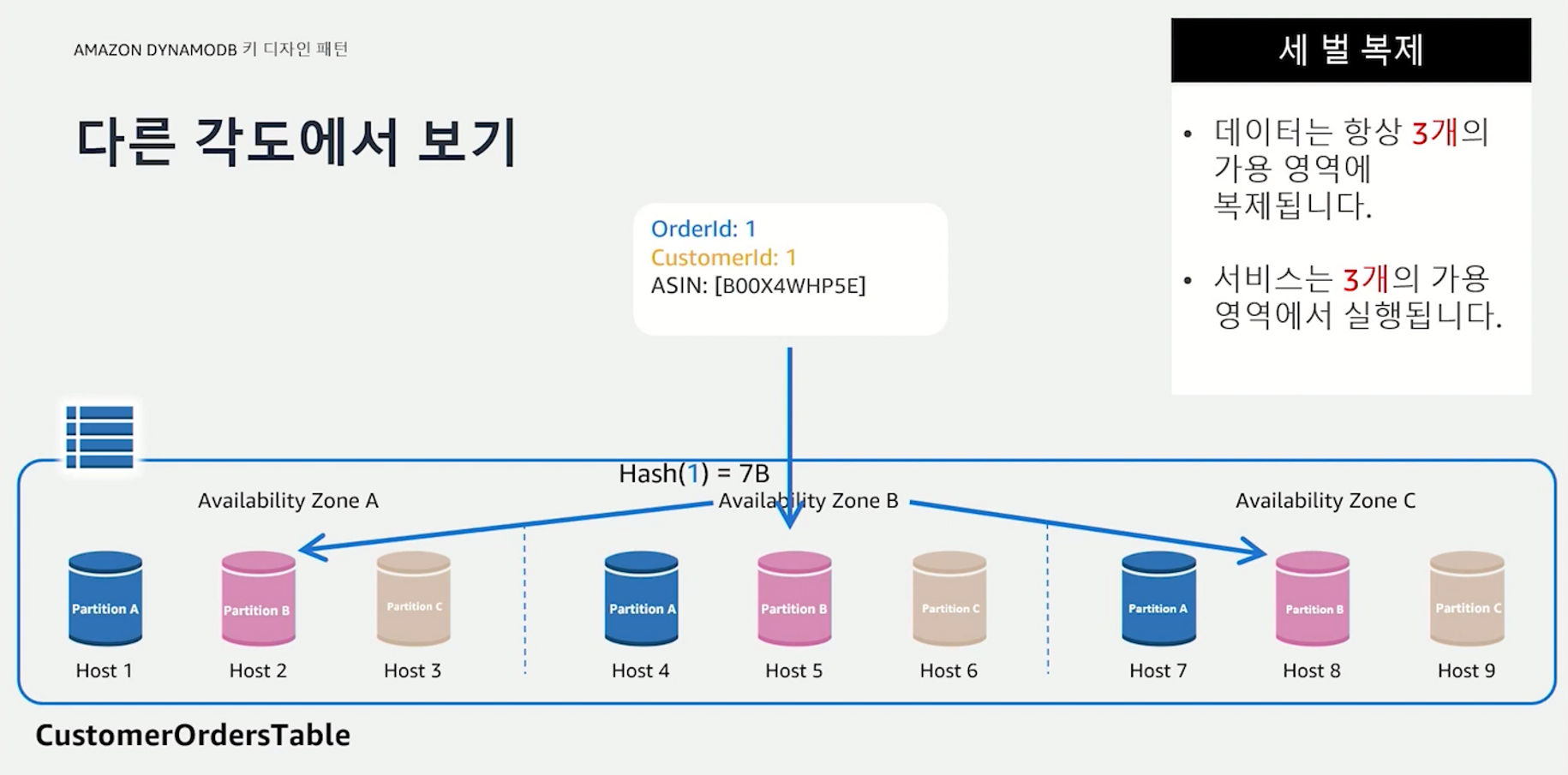
OrderId 1이 해시함수의 결과로 7B라는 해시값으로 변경되었고, 그 결과 파티션 B에 저장되고 있는 예제이다.
사용자가 아이템 API를 이용해 데이터를 입력하면 해당 데이터는 3개의 가용역역에 복제되어 저장된다. 따라서 리전 내에 한 개의 Availabilty Zone이 무너져도 데이터 쓰기 및 읽기 작업은 영향없이 지속될 수 있다.
DynamoDB의 제약 조건
스케일링
처리량
- 테이블에 원하는 양의 처리량 설정
- RCU(Read Capacity Unit) : 4KB per second(프로비전드) or request(온디맨드)
- RCU는 데이터를 읽을 때 소비하는 컴퓨팅 단위로, 1RCU에 4KB까지의 데이터를 읽을 수 있다.
- WCU(Write Capacity Unit) : 1KB per second(프로비전드) or request(온디맨드)
- WCU는 데이터를 쓰거나 수정하거나 수정할 때 소비하는 컴퓨팅 단위로, 1WCU에 1KB까지 데이터 조작이 가능하다.
- RCU와 WCU는 독립적으로 동작
- RDBMS와 다르게 쓰기, 읽기 처리량은 독립적으로 사용할 수 있다. 예) 30000 RCU, 100 WCU를 동시에 사용할 수 있으며 사용한만큼 비용 청구됨
- RDBMS와 다르게 쓰기, 읽기 처리량은 독립적으로 사용할 수 있다. 예) 30000 RCU, 100 WCU를 동시에 사용할 수 있으며 사용한만큼 비용 청구됨
- Consistent 설정 (읽기 일관성)
-
Eventually Consistent 읽기는 Strongly Consistent 읽기에 비해 RCU를 절반만 사용 : 8KB per second(프로비전드) or request(온디맨드)
-
Eventually Consistent
- 기본 설정이며, 방금 쓴 데이터가 조회되거나 혹은 이전 데이터가 조회될 수도 있다.
- 1RCU로 8KB까지의 데이터를 읽을 수 있다.
-
Strongly Consistent
- 1RCU로 4KB까지의 데이터를 읽을 수 있다.⇒ 내 애플리케이션 요구 조건에 따라 읽기 일관성을 충분히 고려해야 한다.
-
사이즈
-
테이블에 아이템을 원하는 수만큼 추가 가능
- 아이템 하나의 최대 크기는 400KB
- 하지만 400KB 모두 사용하는 것은 비권장
- DynamoDB는 하나의 아이템에서 한 글자만 바뀌어도 전체 아이템을 다시 쓰는 특성을 갖기 때문에 400KB를 모두 사용하는 것은 권장하지 않음.
- 가능하면 아이템 사이즈를 작게 유지하며 아이템의 개수를 많이 가져가는 것이 좋다.
-
스케일링은 파티셔닝을 통해 이루어짐
- 각 파티션은 1000WCU/초 혹은 3000RCU/초를 제공하며 둘 중 하나가 초과되면 파티션이 늘어나는 구조
- 예) 1만 RCU일 경우 파티션이 10개 /
10만 RCU일 경우 파티션의 개수가 100개로 늘어나는 구조
- 예) 1만 RCU일 경우 파티션이 10개 /
- 또는 테이터 용량이 10GB 초과 시 파티션이 늘어나는 구조
- 각 파티션은 1000WCU/초 혹은 3000RCU/초를 제공하며 둘 중 하나가 초과되면 파티션이 늘어나는 구조
DynamoDB에서 데이터를 읽는 방법 (REST API)
RDBMS는 SQL 쿼리라는 언어를 사용해 데이터를 조회하지만,
DynamoDB에서는 REST API를 이용해 데이터를 읽거나 조회한다.
(다소 생소한 방식이지만 최근 RDBMS를 사용해도 직접 쿼리를 짜는 것보다 ORM을 사용하는 것과 같이 생각해보면 좀더 친숙하게 느껴질 수도 있다…)
GetItem
- Partition key의 정확한 값 지정
- 정확히 0 또는 1개의 아이템을 반환하는 API
- 조건이 맞는 아이템이 없을 때 0개의 결과 반환)
- 아이템의 크기에 따라 RCU를 사용
- 예) 10KB의 한 개 아이템을 GetItem API로 eventually consistence 읽기를 이용해 조회할 경우 2RCU가 사용된다.
Query
- Partition Key의 정확한 값 지정
- 선택적으로 non-key attribute에 필터링 조건 추가 가능
- 프라이머리 키가 아닌 attribute에 필터링 조건을 걸어 서버사이트 필터링을 할 수도 있다.
- 일치하는 아이템 반환(여러 개 가능)
- Key 조건과 일치하는 아이템의 크기에 따라 RCU를 소비하여 단일 결과를 반환
Scan
- RDBMS의 풀스캔이라고 생각해도 됨
- 다만 RDBMS의 풀스캔은 테이블 끝까지 스캔을 완료한 후 결과가 반환되지만,
DynamoDB에서는 1MB 단위의 스캔이 가능하므로 리턴 메시지에 토큰값을 이용해 다음 1MB 시 API 호출을 반복해야 하는 차이점이 있다. - 그래서 만약 테이블이 1페타 정도 크기라면 당연히 오래 걸릴 수밖에 없고, OLTP 운영 환경에선 사실 거의 사용할 일이 거의 없다.
- 보통 온라인 마이그레이션을 한다고 할 때 고민하게 될 API가 될 것
- 다만 RDBMS의 풀스캔은 테이블 끝까지 스캔을 완료한 후 결과가 반환되지만,
- 키를 지정하지 마세요! 선택적으로 키가 아닌 attribute에 대한 필터 조건 지정
- 필터 표현식과 일치하는 테이블의 모든 아이템을 반환
- 테이블의 모든 아이템을 읽기 위해 RCU를 소비한다. 운영 환경에서 사용할 때 주의 깊게 생각할 것.
대표적인 API 제약 조건
Query & Scan
- 단일 호출로 최대 1MB를 반환하며, 응답 메시지가 1MB 이상 넘어갈 시 리턴 메시지에 LastsEvaluatedKey를 이용해 pagination 가능
BatchGetItem
- API Server와 DynamoDB 사이에 라운드 트립을 줄여 한 번에 여러 개의 getItem을 묶어 실행할 수 있는 API
- 단일 호출로 최대 100개 아이템 혹은 최대 16MB 데이터를 반환
BatchWriteItem
- 단일 호출로 putItem과 deleteItem API를 최대 25개까지 묶어 한 번에 실행하며, 최대 16MB까지 쓸 수 있다.
- 하지만 가능하다면 종료 시점에 벌크 작업을 하기보다 여러 시점에 나누어서 작업이 일어날 수 있다면 더 좋다
데이터 타입과 데이터 조작

- TransactGetItems와 TransactWriteItems
- 두 개의 API는 RDBMS와 사용하는 것과 같은 ACID가 지원되는 트랜잭션이다.
- 단일 리전 안에서 여러 개 테이블이나 단일 테이블에서 여러 개 아이템을 동시에 트랜잭션으로 묶어서 읽거나 쓸 수 있다.
- 다만 WCU, RCU가 기존 API보다 2배가 소모되기 때문에 필요한 곳에만 최소화해서 사용하길 권장한다.
세컨더리 인덱스
DynamoDB엔 2가지 종류의 세컨더리 인덱스가 제공된다. → GSI / LSI
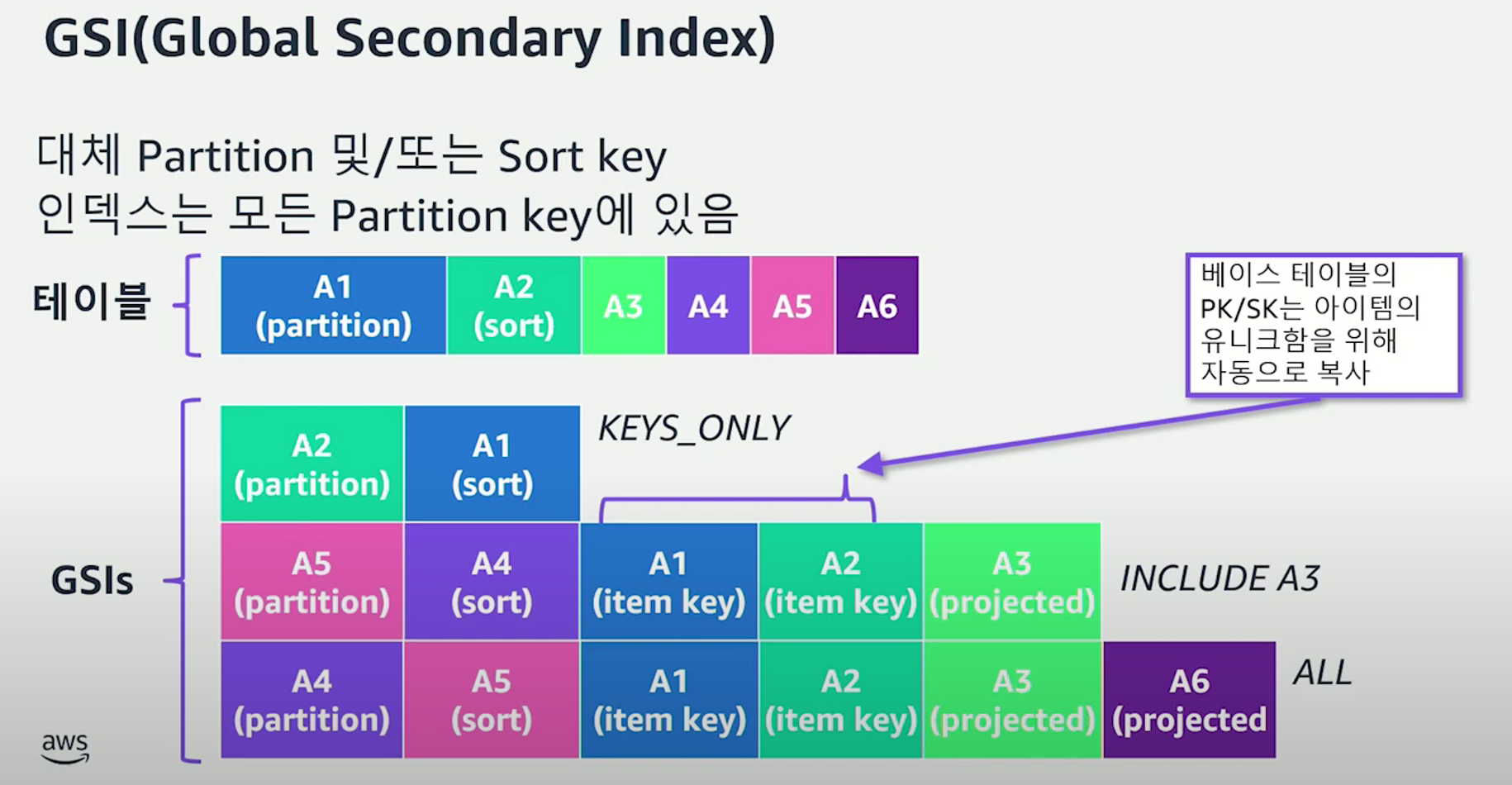
- GSI
- 베이스 테이블에 프라이머리 키 의외의 다른 검색 조건이 필요한 경우 언제든 추가나 삭제가 자유롭다.
- 서비스 오픈 후 지속적으로 진화하는 스키마와 검색 조건을 기존 테이블을 마이그레이션하지 않고 GSI를 이용해 대행해 나갈 수 있다. (이는 RDBMS와 동일하다. 새로운 검색 요구조건이 들어오면 create index하는 것과 같은 개념)
- 베이스 테이블의 모든, 혹은 일부 attribute를 포함하거나 key만 포함할 수도 있다.
(애플리케이션의 읽기 패턴에 따라 선택)
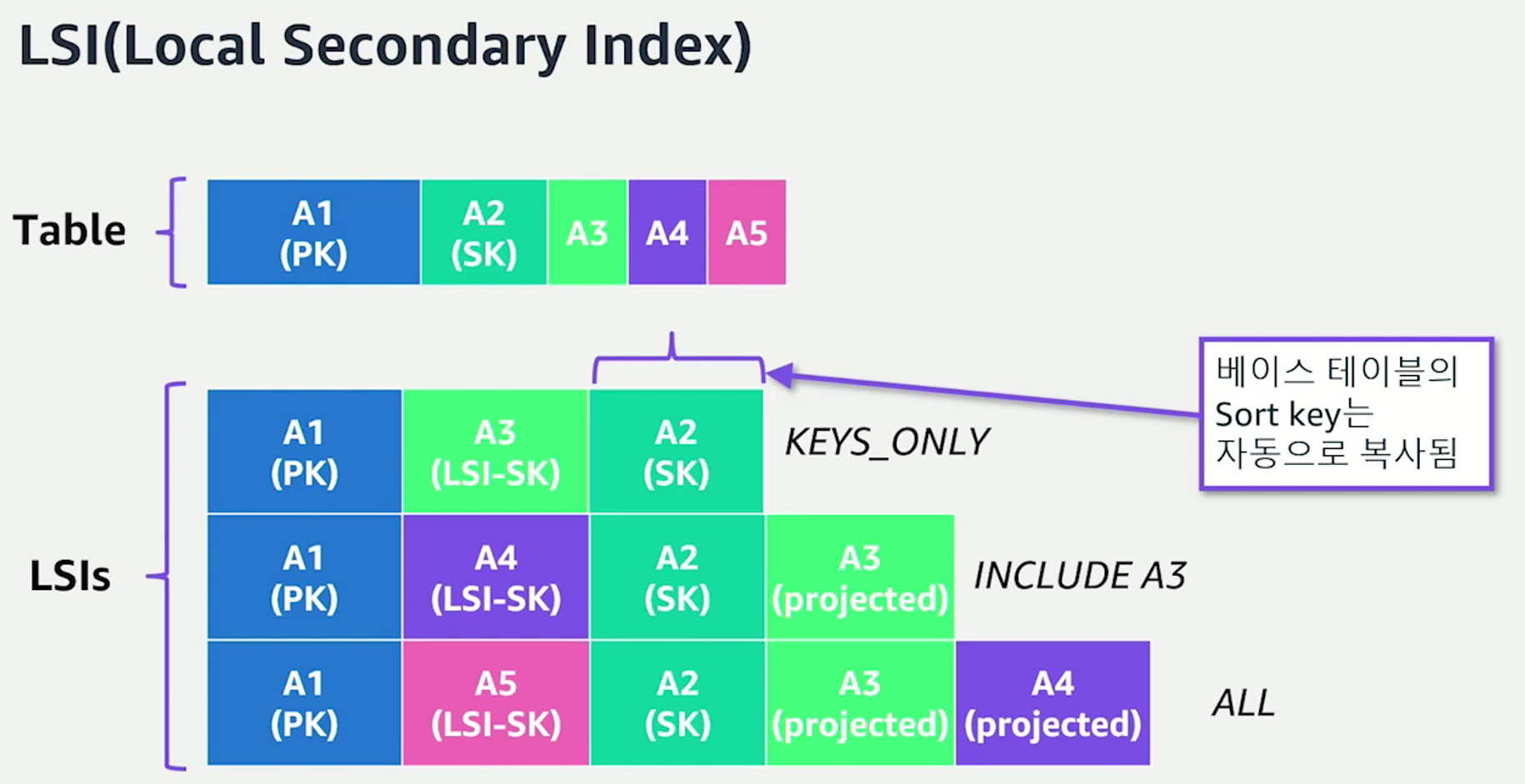
- LSI
- 베이스 테이블 안에서 동일한 PK를 사용하며 다른 SK를 사용하고 싶을 때 사용할 수 있는 세컨더리 인덱스
- GSI와 달리 테이블 생성할 때만 생성이 가능하고 도중에 삭제가 불가능하기 때문에 쿼리 유연성이 떨어져 일반적으로 사용을 권장하지 않음
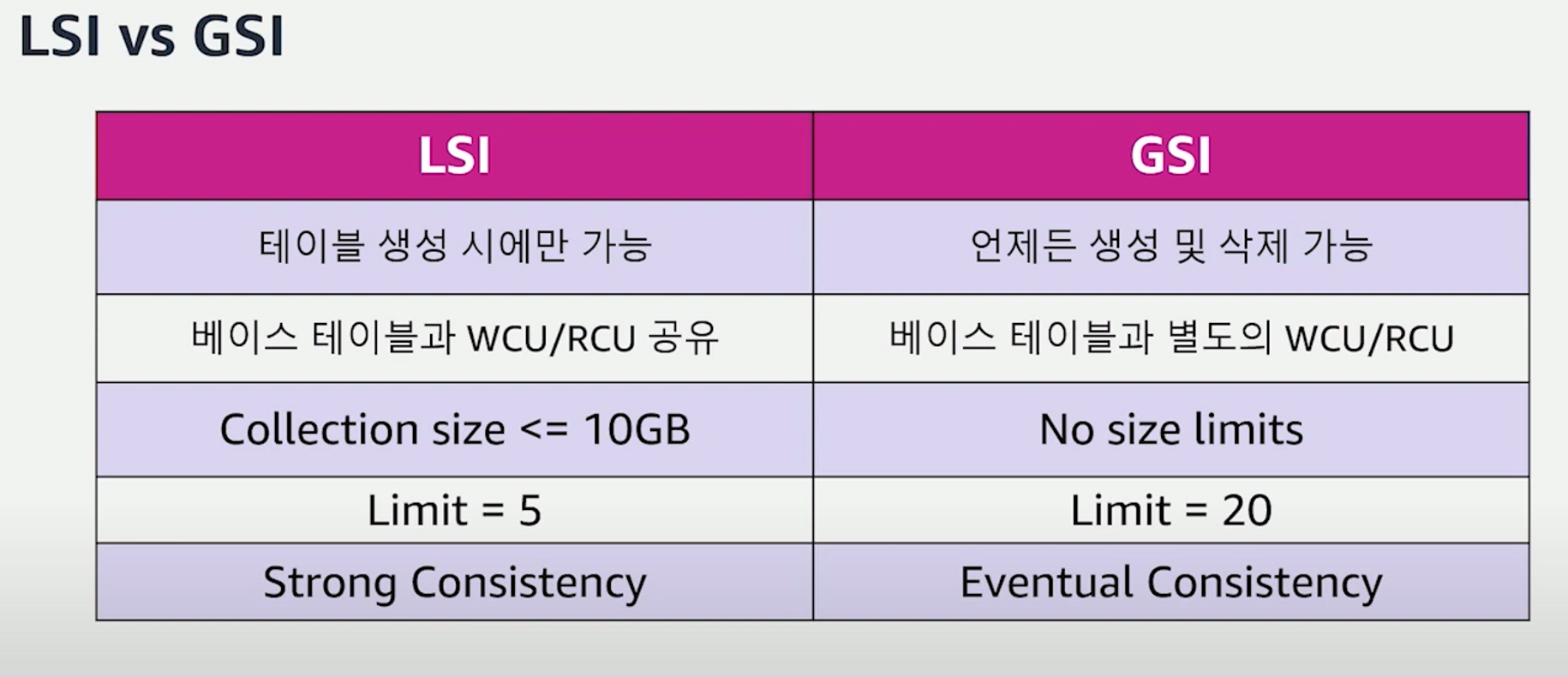
- LSI는 strong consistency가 필요한 경우 사용을 고려할 수 있다.
- 하지만 서비스 오픈 후 매번 엑세스 패턴이 추가될 때마다 테이블을 마이그레이션할 수는 없기 때문에 세컨더리 인덱스를 추가하는 것이 자연스러울 것
- 가능하다면 세컨더리 인덱스를 안 쓸 수 있도록 엑세스 패턴을 단순화하여 사용하는 것이 베스트이며 차선은 최소화하여 사용하는 것이다. → 세컨더리 인덱스는 비용과 직결되기 때문
Tenet

예를 들어 프로덕트 데이터베이스를 디자인한다고 가정해보자.
그림의 왼쪽은 RDBMS에서 데이터 중복을 최소화하며 엔티티 별로 테이블 만드는 정규화 방법이다. 하지만 NoSQL에서도 RDBMS처럼 엔티티 별로 테이블을 만들어서는 안된다.
즉, 그림의 오른쪽처럼 애플리케이션의 화면을 기준으로 최대한 빠르게 데이터가 조회될 수 있도록 키를 디자인 하자는 것이다.
DynamoDB 데이터 모델링 TENET
모델링 tenet은 비단 DynamoDB뿐만 아니라 key-value noSQL 데이터베이스라면 동일하게 적용 할 수 있는 개념이다.

1. UseCase 정의
첫 번째로 애플리케이션 UseCase가 DynamoDB가 잘하는 것과 맞는지 생각해봐야 한다.
DynamoDB가 가장 잘하는 것은 무한하게 많은 아이템 개수 중 pk와 sk 조합으로 유니크한 한 개 혹은 몇 개 아이템을 빠르게 찾아서 리턴하는 것이다.
반면 대량의 레인지 쿼리, 풀텍스 서치, 집계 쿼리와 같은 것은 잘 하지 못한다.
2. 액세스 패턴을 식별
애플리케이션의 읽기/쓰기 워크로드 패턴을 정확히 이해해야 한다.
3. 데이터 모델링
RDBMS와 같이 엔티티 별로 테이블을 생성하는 것이 아닌 하나의 테이블로 시작하는 것을 말함
DynamoDB는 풀 서버리스 형태의 완전 관리형 데이터베이스 서비스이다. 그런데 운영 환경에 테이블이 300개 정도 있다고 가정하면 실제로 관리할 테이블 개수가 300개라는 의미가 된다. 완전관리형으로 운영 부담을 줄이기 위해 사용되는데 또 다른 운영 부담을 만들어내는 꼴이 된다. 테이블 한 개에서 발생한 알람과 300개 테이블에서 발생하는 알람의 개수는 다를 수밖에 없을텐데 이 알람이 많아지면 점점 그 알람에 무감각해지고 결국엔 장애로 이어질 확률이 높다.
또한 테이블 안에 파티션의 개수가 많을수록 애플리케이션의 데이터 엑세스가 여러 개 파티션에서 동시에 일어날 확률이 높아진다. 이는 테이블의 전체 성능이 높아지고 결국엔 핫파티션의 확률도 줄어든다.
따라서 DynamoDB는 사이즈가 작은 여러 개 테이블 보단 하나의 큰 테이블을 사용하는 것이 이점이 더 많다.
- 애플리케이션 종류 : OLTP vs OLAP
애플리케이션 종류는 OLTP여야 하고, OLAP 분석이 필요하다면 DynamoDB 웹으로 분석 파이프라인을 만들어서 그곳에서 분석 워크로드를 수행해야 한다.
- 데이터 라이프 사이클
데이터 라이프 사이클은 데이터의 특성에 따라 TTL의 필요 여부를 고민하고, 백업 정책도 반드시 고민해야 한다.
- Primary Key 식별
하지만 보관할 수 없는 백업은 사실상 의미가 없다. 프라이머리 키로만 데이터를 조회할 수 있기 때문에 내 어플리케이션이 어떻게 데이터를 읽고 쓰는 가에 따라 프라이머리 키를 식별하는 것이 중요하다.
- Repeat Review
여러 명이 함께 모델링하고 함께 리뷰하는 과정을 반복해서 서로의 생각을 하나의 디자인으로 만드는 과정을 반복해야 한다.
RDBMS 정규화는 공식이 있기 때문에 대부분 개발자들이 공식을 알려주면 비슷한 결과물을 만들어낼 수 있지만 NoSQL의 키 디자인은 10명이 함께 하면 10개의 디자인이 나오는 열린 결말과 같다.
따라서 리뷰 반복 단계가 프레세스화되어야 한다.
비정규화
-
비정규화는 데이터 중복을 최소화하는 정규화와 반대되는 개념
-
DynamoDB가 잘 하는 것 - 무한하게 많은 아이템 중 하나 혹은 몇 개를 일정한 시간에 찾아낸다.
⇒ 그렇게 하기 위해선 RDBMS와 다르게 생각하는 것이 필요하다.
- 데이터 모델을 정규화하는 것에 중점을 두는 RDBMS와 다르게, DynamoDB와 같은 key-value nosql은 애플리케이션이 사용하는 모든 데이터 액세스 패턴을 알고 시작하는 것이 중요
- 또한 조인 같은 복잡한 연산이 불가능하기 때문에 데이터를 조회할 결과셋 형태로 미리 연산해서 입력해 두는 것이 필요
-
참고 - 왜 RDBMS는 정규화에 중점을 두었을까?
- 데이터 중복을 최소화하여 정규화된 테이블 간의 조인을 이용해 Ad-hoc하게 런타임에 디스크의 데이터를 읽어 CPU 리소스를 사용해 조인 연산을 실행한다.
- 여러 이유가 있지만 시대적 배경의 영향도 있다. RDBMS가 시작되던 1970, 80년대는 컴퓨터의 3대 구성요소인 CPU, 메모리, 디스크 중 CPU 보다 디스크가 비쌌고, 이에 따라 정규화를 통해 데이터 중복을 줄여 최소의 데이터를 디스크에 저장하고 런타임에 CPU 리소스를 많이 사용하는 측면으로 만들어짐
- 그러나 Key-value NoSQL이 시작되었던 2000년대 중반은 디스크 가격 GB 당 1달러 아래로 떨어지며 상황이 역전 되었고 디스크를 많이 사용하고 런타임에 CPU 연산을 줄이는 방향으로 발전했다.
디자인 패턴 1 - 간단한 PK 유일키
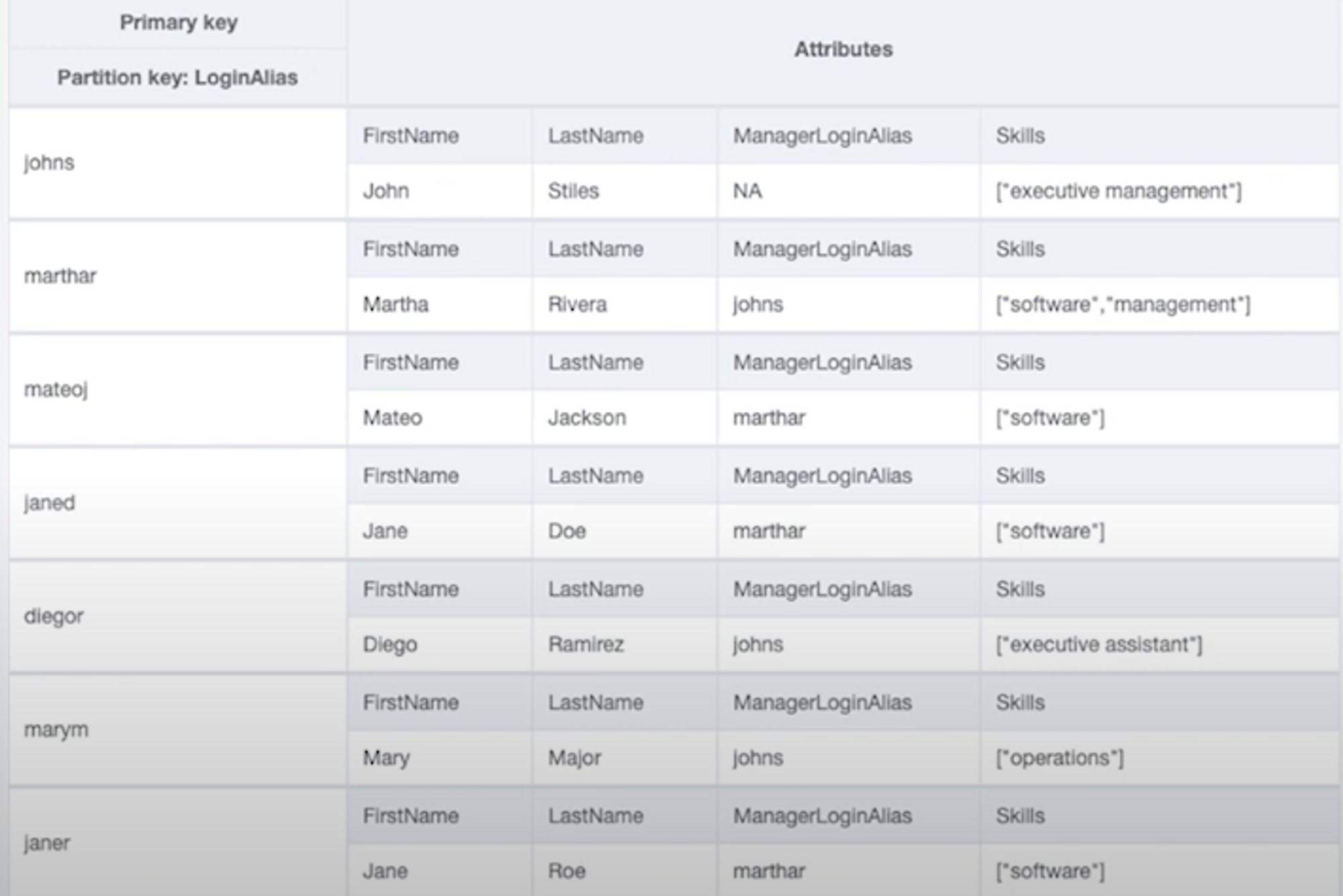
- 한 개의 pk에 한 개의 아이템만 존재하는 간단한 구조.
- 대표적으로 사용자 프로파일, 세션 스토어, 이커머스의 상품 정보 등이 이런 디자인 패턴을 사용.
- loginAlias라는 pk에 각 사용자의 alias가 입력되어있고, attribute에는 사용자의 세부 정보를 볼 수 있음
- 일반적으로 조직 내부에서 쓰는 이메일 주소 앞에 아이디는 조직 내에서 유일하다. → 이러한 케이스이 경우 DynamoDB 테이블생성 시 PK만 있는 형태로 생성하면 된다.
디자인 패턴 2 - PK+SK 복합키
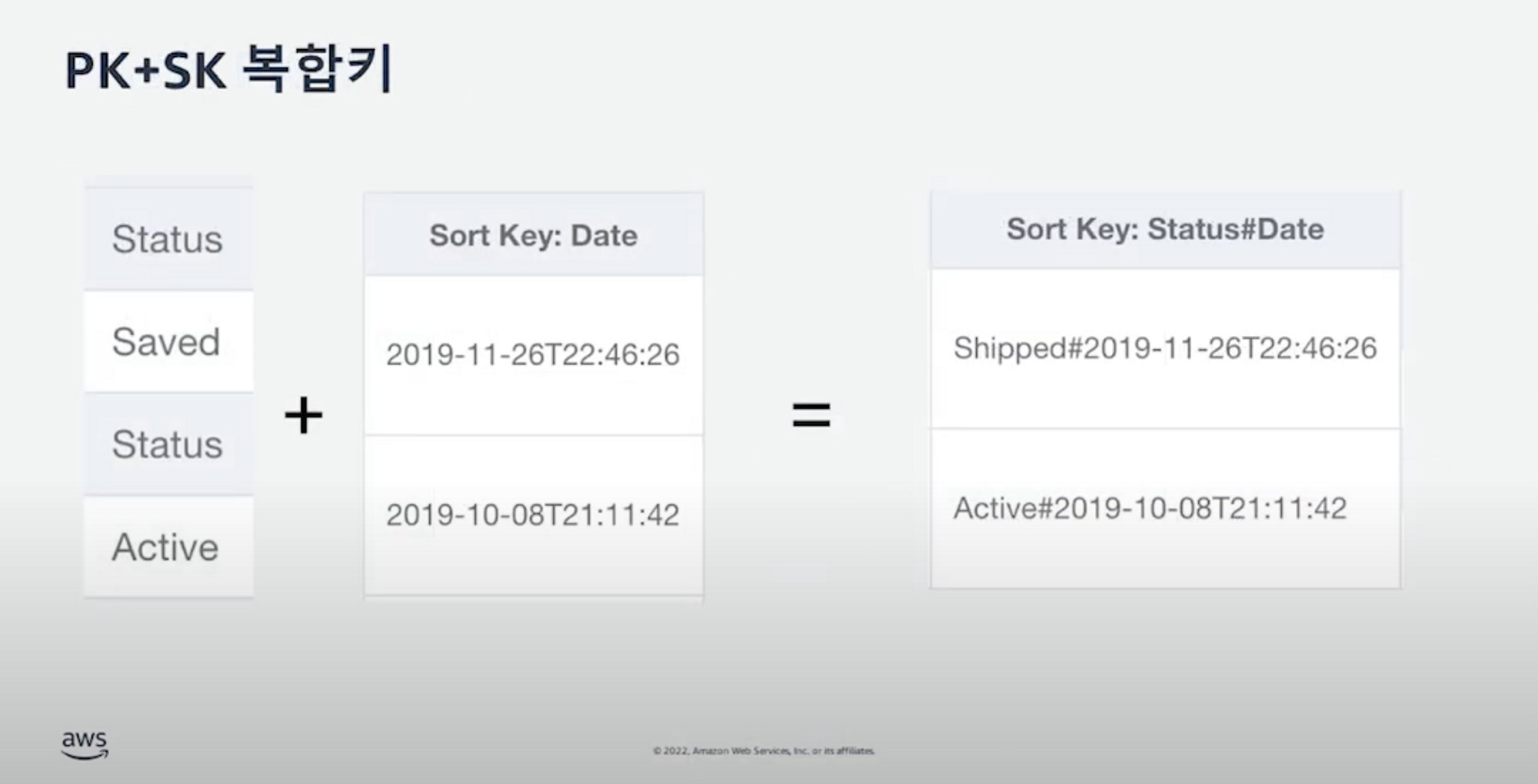
-
만약에 위 예제와 같이 status와 date attribute를 하나의 복합키로 만들어 검색조건으로 사용해야 한다면 오른쪽과 같이 중간에 샵 구분자를 이용해 두 개 이상의 어트리뷰트를 하나의 논리적인 복합키로 만들 수 있다.
-
Redis에서 일반적으로 복합키의 구분자로
,콜럼을 사용하는 것처럼 DynamoDB에서는#을 많이 사용하지만 원하신다면$달러와 같은 다른 특수기호도 사용할 수 있다. -
어트리뷰트 왼쪽에 가장 일반적인 어트리뷰트를 사용하고 오른쪽에 더 고유한 어트리뷰트를 연결한다. 이렇게 하면 SK의 값에 begins with, 혹은 between 같은 연산자를 가능하게 한다.
-
이 예제에서는 상태 및 날짜를 기반으로 데이터 액세스하는 패턴으로 보입니다. 상태가
Active혹은Shipped로 시작하는 값이며, 2019년 11월 26일 22시까지의 값 같은 검색이 가능하다 -
SK(Sort Key)
- 일반적으로 많이 사용되는 SK 값은
알파벳, 문자열, 숫자, 타임스탬프, ULID/KSUID와 같은 아이디 등이 있다. SK의 기본 어트리뷰트 값을 기준으로 오름차순 및 내림차순이 가능하다. - 아래 데이터들이 pk, sk를 함께 사용하여 만들어낼 수 있는 디자인 패턴이 된다.
- 특정 IoT 디바이스의 시간 별로 유입되는 로그 데이터
- 소셜 네트워크에서 각 사용자의 포스트 리스트,
- 이커머스에서 각 주문 상세정보 혹은 이력
- 일반적으로 많이 사용되는 SK 값은
- 예제 1

firstname + lastname 조합으로 이루어진 프라이머리키라고 가정해보자.
앞서 PK 유일키는 pk의 attribute의 값으로 단일의 유일한 아이템이 가능했다면
pk,sk를 모두 사용할 때는 pk, sk의 attribute 조합으로 유일한 아이템을 만들어 낼 수 있다.
대표적으로 jane doe와 jane roe는 동일한 pk이지만 다른 sk를 가지기 때문에 동일한 pk에 2개의 아이템이 사용될 수 있다.
- 예제 2
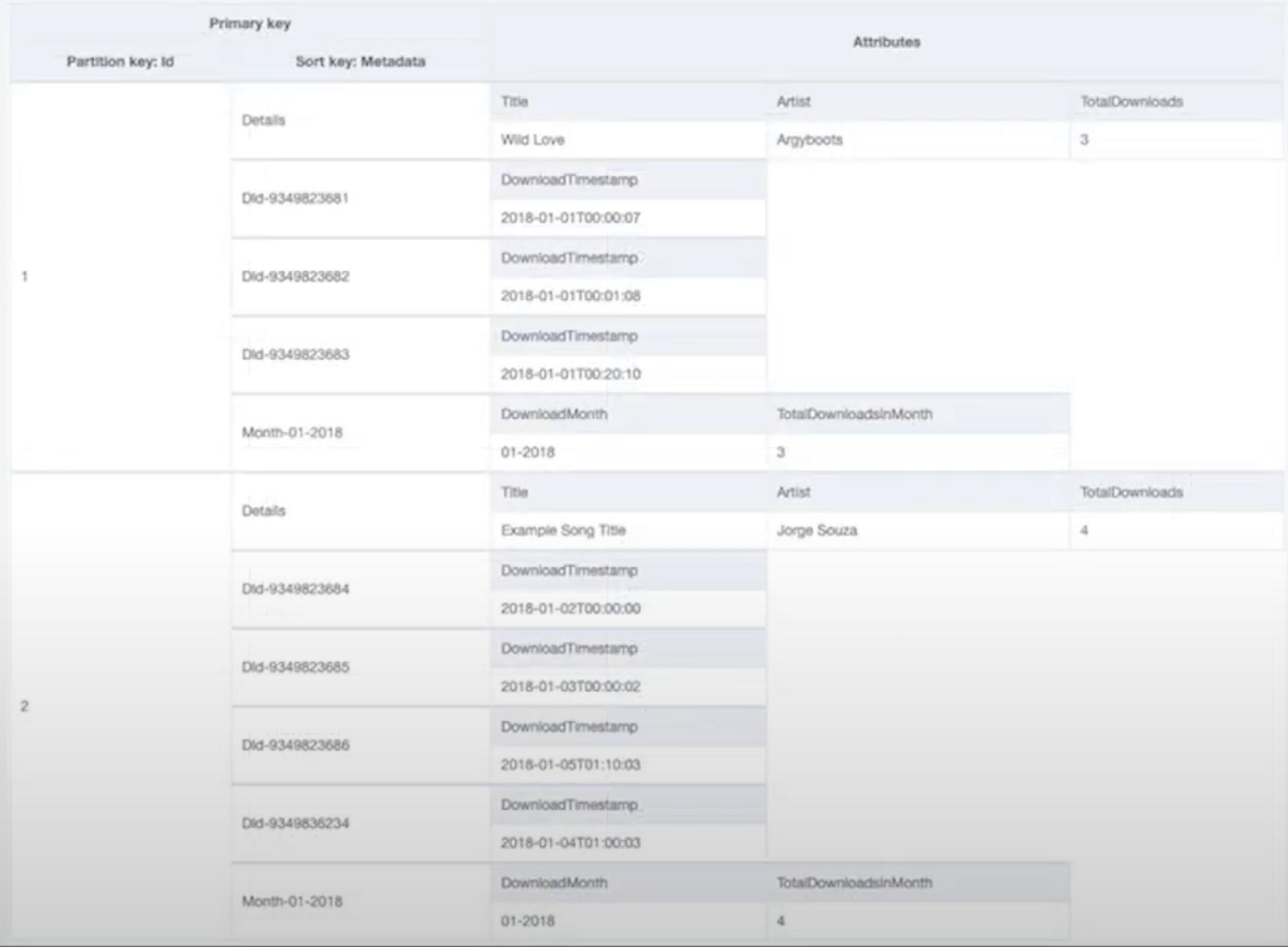
또 다른 예제는 각 노래별 월간 다운로드 수, 각 다운로드 시간, 노래 상세정보를 pk sk 조합으로 디자인한 예다.
PK ID 1은 Details라는 SK를 통해 노래 상세정보를 저장하며,
Did로 시작하는 아이템을 통해 노래의 다운로드 이력을 저장하고,
month 01, 2018 아이템을 이용해 2018년 1월에 이 노래가 다운로드된 총합을 저장하고 있다.
이 경우에 우리는 노래 상세 정보만 조회할 수도 있고,
begins with 연산자를 이용해 did로 시작하는 다운로드 이력만 조회할 수 있고,
쿼리 API를 이용해 PK ID 1에 모든 아이템을 한번에 조회할 수 있다.
⇒ 키 디자인 시 지속적으로 생각해야 될 포인트는 ‘UI에 있는 데이터를 그대로 저장 하는 것’.
UI에 따라 데이터 액세스 패턴이 결정될 것이고 이를 어떻게 key-value NoSQL 데이터베이스의 특성에 맞게 단순화 할 수 있을지 고민해야 한다는 의미이다.
디자인 패턴 3. 싱글 테이블 디자인
해당 영상에선 DynamoDB를 어떻게 하면 더 잘 사용할지에 대한 내용을 다루고 있는데, 그 핵심 중 하나는 싱글테이블 디자인이다.
-
정의
- 애플리케이션의 모든 엔티티를 하나의 테이블로 엑세스할 수 있도록 설계하는 방법
-
장점
- 일반적으로 다수의 테이블에 비해 적은 운영 부담
- 높은 테이블 최대 성능 및 쓰로틀링 경감
-
단점
- noSQL을 처음 접하는 단계에선 높은 러닝 커브
- ‘시계열 데이터, 또는 엔티티 별 다른 액세스 패턴’ 등의 예외 케이스에서는 적합하지 않음
-
안티 패턴
-
PK를 UserID로 고정하고 시작하는 습관
- 일반 사용자와 VIP를 같은 키 디자인으로 해결하려는 습관
- 대량 트래픽을 유발하는 heavy user를 항상 고민해야 함
(보통 어떤 서비스를 만든다고 가정했을 때 PK를 유저 아이디로 고정하고 디자인을 하는 경우가 많다. 작은 규모 서비스라면 별 문제가 안되지만, 우리가 DynamoDB를 도입하기로 결정한 것은 RDBMS의 스케일로는 어려운 대규모 서비스를 타겟팅하며, 글로벌로 언제든 나갈 수 있고, 언제 대규모 트래픽이 들어오던 탄력적으로 대응 가능한 데이터 베이스 레이어를 사용하겠다는 의미이다.
그러나 PK를 유저 아이디로 고정 하게 되면 한 사용자의 모든 데이터가 한 개의 pk에서 벗어날 수 없게 된다. 일반적인 사용자라면 괜찮지만, 대부분의 서비스에서 갖는 대량 트래픽을 유발하는 헤비유저를 처음부터 염두에 두고 키 디자인을 할 필요성이 있다.)
-
엔티티 별로 테이블을 만드려는 습관
또 다른 좋지 않은 패턴은 ‘엔티티 별로 테이블을 만드려는 습관’이다. 테이블에 개수가 많아지면 결국 손이 많이 가게 된다. 운영 부담을 줄이고 더 가치 있는 곳에 시간을 사용하기 위해 완전관리형 데이터베이스 서비스를 사용하는데 테이블 개수가 많아지는 것은 이런 관점에서 매우 아이러니하다.
-
GSI를 많이 사용하려는 습관
앞서 언급한 것처럼 세컨더리 인덱스은 즉시 눈에 보이는 비용으로, 사용을 최소화 해야 한다.
-
싱글 테이블 디자인 예제 - 이커머스 애플리케이션 디자인
실제 조직에서 사용하길 권장하는 키디자인 풀사이클 프로세스를 예제와 함께 살펴보자.
키 디자인 풀사이클
- 비즈니스 유즈 케이스 이해하기
- 서비스 유즈 케이스를 정확하게 이해하고 key-value NoSQL 데이터베이스가 잘하는 부분과 일치하는지 생각해보기.
- 아니라고 판단되면 빠르게 유즈 케이스에 맞는 다른 데이터베이스를 고민해 봐야 된다.
- ER 다이어그램 그리기
- 서비스 유즈 케이스와 DynamoDB가 맞다고 판단되면 다음은 ER 다이어그램을 그린다.
- ER다이어그램은 RDBMS만 그리는 거 아닌가?라는 의문이 들 수 있지만, NoSQL이어도 각 엔티티 간의 관계에 따라 일대일, 일대N, N대N 관계가 될 수 있고, 이에 따라 키 디자인 패턴이 달라지기 때문에 ER 다이어그램을 그리는 것을 권장한다.
- 대신 엔티티 안에 모든 attribute까지 명세해서 자세히 그리기보단 단순하게 엔티티 간의 관계만 표현할 정도면 된다.
- 모든 데이터 엑세스 패턴 정리하기
- 애플리케이션이 DynamoDB를 사용하기 위한 모든 데이터 액세스 패턴을 정리한다.
- 만약 스타트업의 매우 초기 단계와 같이, 거의 매일 액세스 패턴이 바뀌는 상황일 때는 그때마다 키 디자인을 다시 하는 것은 생산성 문제로 이어질 수 있기 때문에 key-value NoSQL 보다는 RDBMS로 시작하는 것을 권장한다. (+ 그래서 대부분 스타트업들이 초기에 RDBMS로 서비스를 시작하고, 서비스가 트래픽이 늘어났을 때 Scale-up으로 대응하다, 이후 Scale-up으로 대응할 수 없는 단계가 왔을 때 ‘샤딩이냐 또는 NoSQL이냐’ 기로에 한번 서게 된다.)
- 키 디자인 시작하기
비즈니스 유즈 케이스 이해하기

이 예제는 사진 하단의 aws-samples 깃허브 레포지토리 안에 있는 DynamoDB 키 디자인 패턴 3개 예제 중 하나이다.
간략히 보자면, 고객이 온라인샵에 방문하고 여러 개 상품들을 둘러보다 여러 개 상품을 주문한다는 내용이다.
즉, 구매대행 상품들은 하나 혹은 여러 곳에 물류창고에서 픽업되어 고객의 주소로 배송 된다는 내용이고, 파란색으로 표기된 것들이 이 예제에서 엔티티들이 된다.
(주문과 연결된 인보이스를 기반해 여러 개 결제 수단을 결합해 지불 할 수 있지만 복잡해질 수 있기 때문에 해당 예제에서는 결제 관련된 엔티티는 다루지 않는다.)
ER 다이어그램 그리기
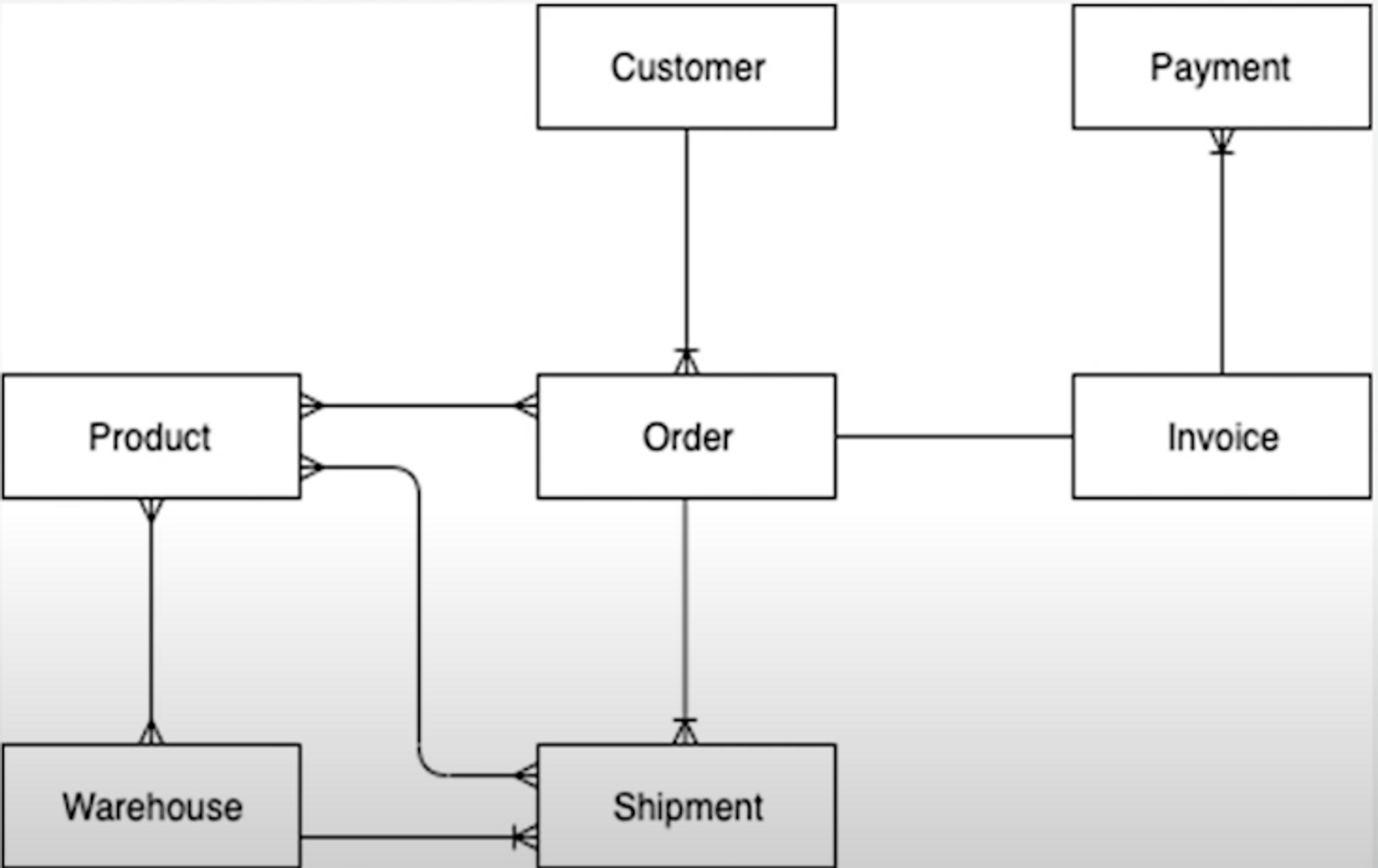
비즈니스 유즈 케이스로부터 엔티티를 추출하고 각 엔티티의 관계를 그린 ERD이다.
고객은 여러 개 주문을 할 수 있고,
주문은 인보이스를 만들어 내고,
주문하면 여러 개의 상품이 담길 수 있고,
상품은 다시 여러 개 주문에 속할 수 있는 그런 관계다.
DynamoDB의 키 디자인을 위한 다이어그램은 더 복잡할 필요 없이 이정도로 충분하다.
모든 데이터 액세스 패턴 정리하기

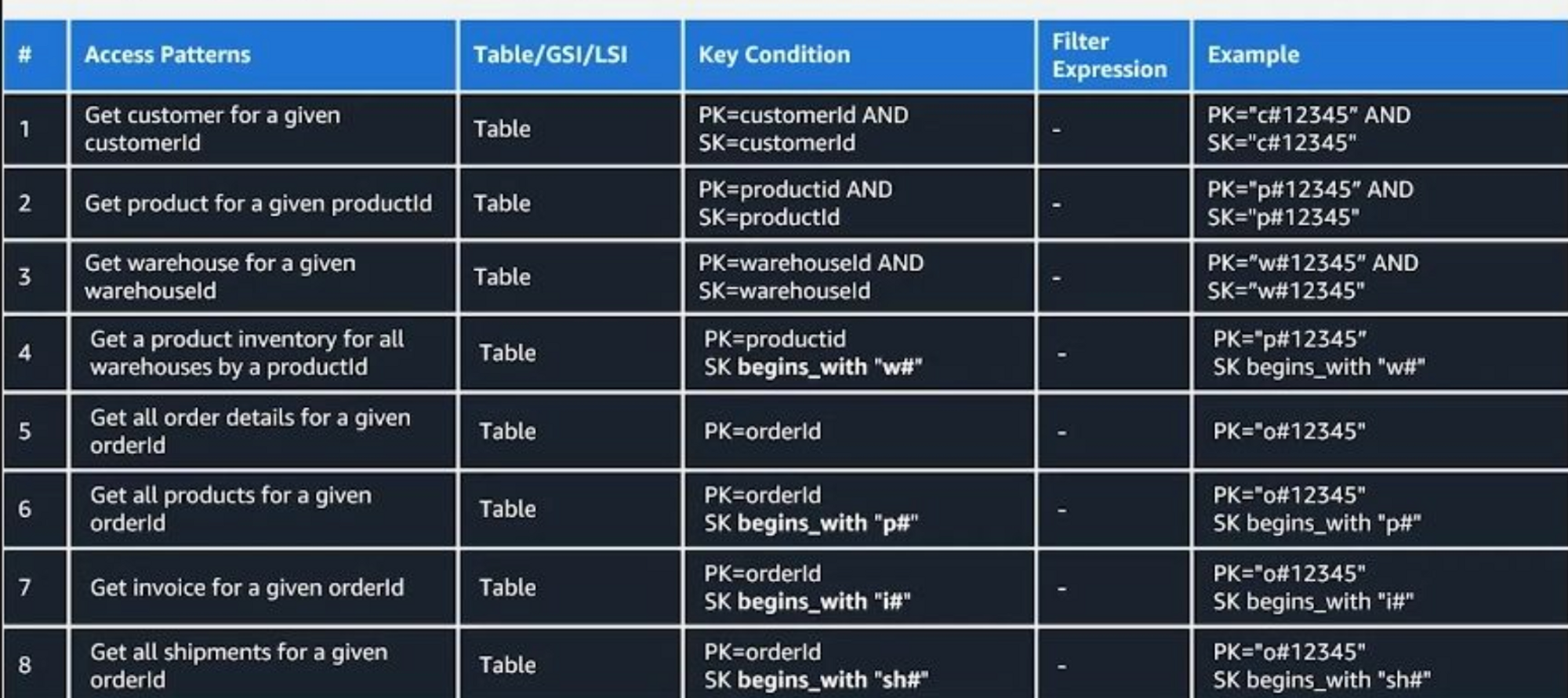
- ‘어떤 값으로 어떤 데이터를 줘야겠다’를 정리한 것이 엑세스 패턴이라고 보면 된다. 예를 들면 1번 엑세스 패턴은 customerId로 고객 정보를 줘야 한다. 5번 엑세스 패턴은 orderId에 상세 주문정보를 조회한다. 로 볼 수 있다.
- 예제에서는 조회 엑세스 패턴만 있지만 실제 워크로드에서는 쓰기와 읽기 엑세스 패턴이 모두 정리되어야 한다. (정해진 룰은 없지만 6개월 후에 나를 위해 그리고 내가 떠나고 누군가 될지 모르는 다음 사람을 위해서라도 화면과 같은 형식으로 엑세스 패턴이 정리되어 있다면 정말 좋을 것.)
- 만약 RDBMS 였다면 엔티티 별로 각각의 테이블을 만들고, 엑세스 패턴에 따라 여러 개 테이블을 조인 하거나 하나의 테이블에서 데이터를 조회할 것이다. 하지만 DynamoDB에서는 이 엑세스 패턴을 하나의 테이블에 담아 볼 것이다.
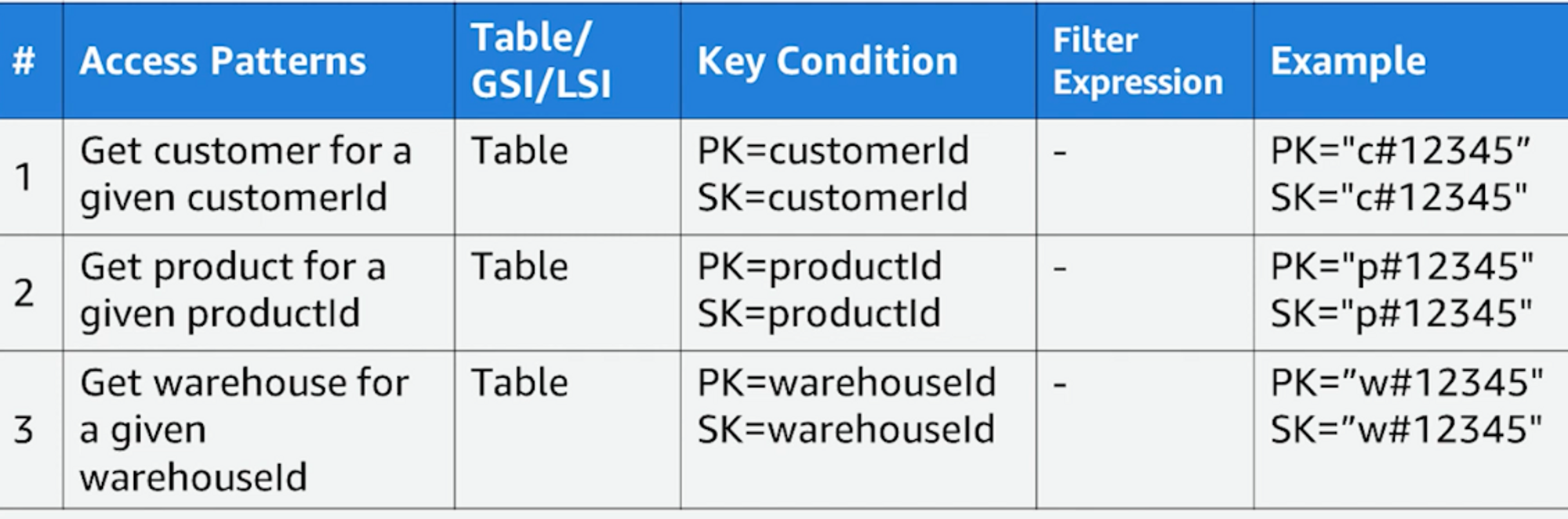
- 엑세스 패턴 작성은 이와 같다 1) 엑세스 패턴의 번호, 엑세스 패턴 내용, 그리고 액세스가 테이블, GSI, LSI 중 어디에서 발생하는 것인지 명시하고, 2) 그 다음 PK, SK든, 어떤 연산자를 사용할지에 대한 Key Condition 3) 필요에 따라 서버사이드 필터링을 표시하고 4) 마지막으로 키 컨디션의 예제 값을 대입해 표기하면 된다.
- 위의 1,2,3번 엑세스 패턴은 사실 패턴이 같다.
customId로 고객정보를 조회하고 / productId로 상품정보를 조회하고 / warehouseId로 물류창고 정보를 조회하는 간단한 패턴이며,
이 패턴들은 베이스 테이블에서 일어난다.
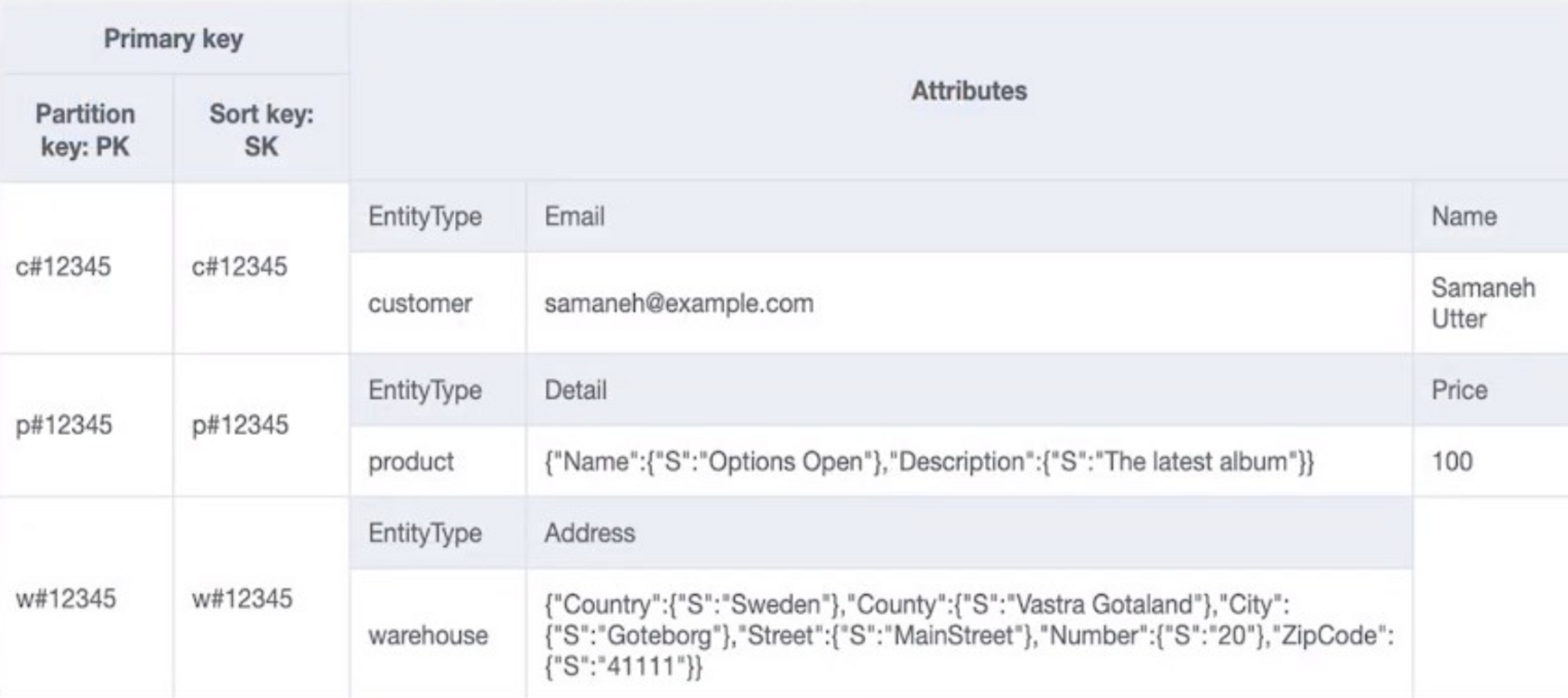
- DynamoDB document 웹페이지에서 noSQL Workbench라는 툴을 다운로드 받으면 위 화면처럼 만들어 낼 수 있다.
- 그런데 위 화면에서 몇 가지 이상한 점이 보일 것이다.
- 첫 번째로, pk와 sk 이름이다. → 일반적으로 엔티티별로 테이블을 따로 생성한다면 지금처럼 PK 이름을 PK로, SK 이름을 SK로 하시지 않을 것이다. 하지만 싱글테이블 디자인에서는 하나의 테이블에 여러 개 엔티티가 들어가니 사실상 pk, sk의 이름은 어떤 의미를 같이 못 하기 때문에 일반적으로 pk, sk를 이름으로 사용한다.
- 두 번째, 그렇다면 PK와 SK는 어떤 데이터 타입을 사용할까? 바로 ‘스트링’이다. (여러 개 엔티티가 하나의 테이블에 들어간다는 사실을 잘 생각해 보면 당연한 이야기다)
- 세 번째, 엔티티 타입이라는 attribute를 보자. 이런 attribute를 가지고 있는 케이스는 매우 드물 것이다. 하지만 이 attribute는 각 아이템이 어떤 엔티티에 속하는지를 표기하며 향후 분석 시 특정 엔티티에 데이터만 필요할 때 매우 큰 효과를 발휘한다.
- 마지막으로, pk와 sk엔 왜 동일한 값이 입력되어 있을까? 현재 우리는 모든 엔티티를 하나의 테이블에 넣는다고 했다. 즉, 어떤 엔티티는 pk만 필요하기도 하고, 어떤 엔티티는 PK+SK가 모두 필요하게 되는데, 모두를 포함할 수 있는 테이블 형식은 PK+SK 모두 있는 것이다. 그래서 SK 값을 입력 하지 않으면 아이템이 입력 되지 않기 때문에 임의로 값을 입력한 것인데, 원하신다면 디테일스 같은 상수값을 입력하셔도 무방하다.
- 첫 번째로, pk와 sk 이름이다. → 일반적으로 엔티티별로 테이블을 따로 생성한다면 지금처럼 PK 이름을 PK로, SK 이름을 SK로 하시지 않을 것이다. 하지만 싱글테이블 디자인에서는 하나의 테이블에 여러 개 엔티티가 들어가니 사실상 pk, sk의 이름은 어떤 의미를 같이 못 하기 때문에 일반적으로 pk, sk를 이름으로 사용한다.

다음 액세스 패턴은 특정 상품이 어떤 물류창고에 있는지 검색하는 엑세스 패턴이다.
베이스 테이블에서 발생하고, SK에서 W#으로 시작하는 값을 검색하는 비긴스 위드 연산자를 함께 사용한다.
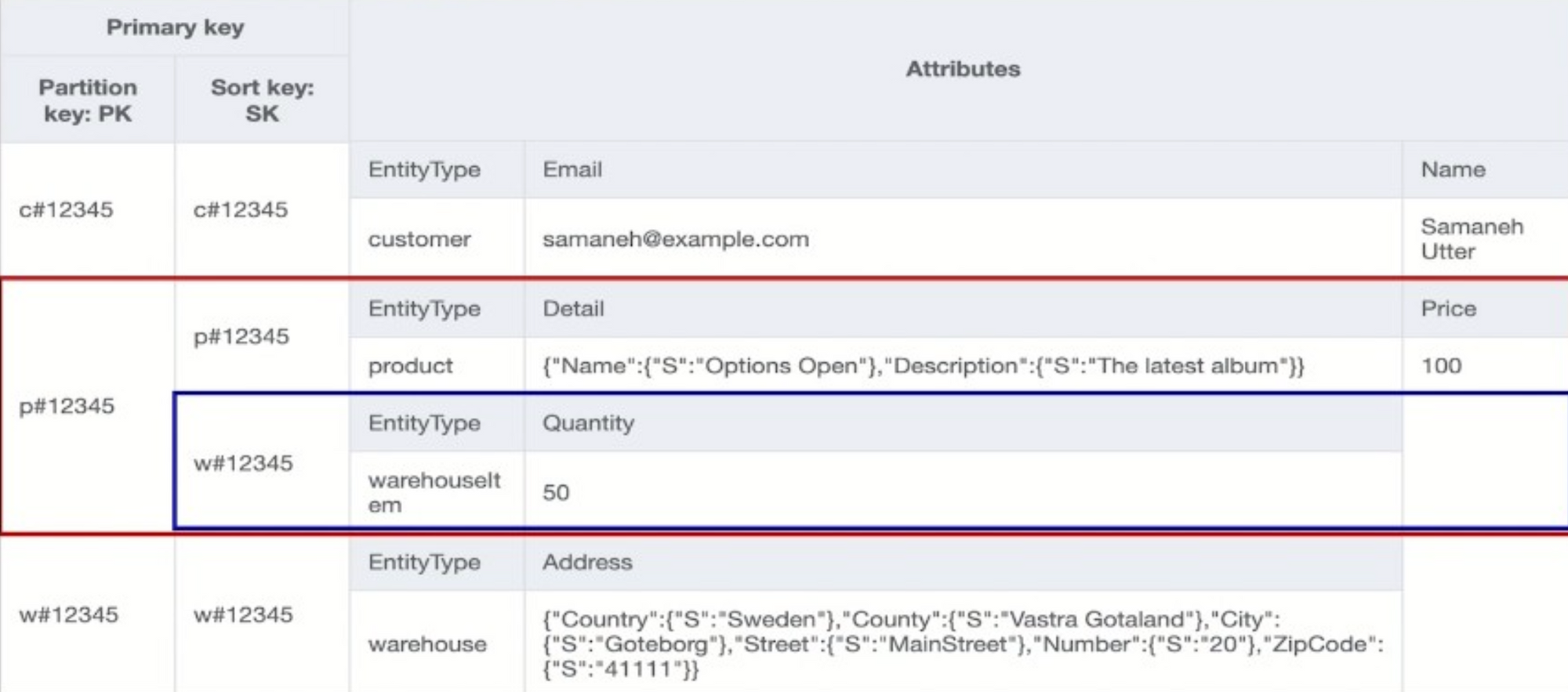
앞에서 봤던 데이터에서 파란색 아이템이 하나 추가되었다.
3번 엑세스 패턴을 다시 생각해 보면 우린 p#12345를 pk로 갖는 상품이 w#12345라는 물류창고에 50개 있다는 사실을 알 수 있다.
하지만 만약 우리가 p#12345라고 하는 상품의 상세정보와 물류창고별 개수를 한 번에 조회해야 된다고 하면 어떻게 하면 될까?
RDBMS 였다면 product 테이블과 warehouse 테이블을 런타임에 productId인 p#12345로 조인해서 결과를 리턴받을 것이다.
하지만 DynamoDB엔 조인이 없다. 그래서 내 애플리케이션에서 조인과 동일한 결과가 필요하다면 미리 이렇게 두 개 아이템으로 프리 컴퓨팅해서 입력해주고, 런타임은 추가 연산 없이 빠르게 읽기만 하면 되도록 한다. (앞서 말한 것처럼 지금은 디스크보다 CPU가 비싸기에...)
경우에 따라 product 엔티티인 아이템만, 혹은 warehouse 엔티티의 데이터만 조회 할 수도 있고, 쿼리 API로 두 개 아이템을 한 번에 조회해야 할 수도 있다. 이것을 정확히 이해하는 것이 중요하다.
다이나모디비엔 실시간으로 사용할 수 있는 조인 연산이 없기 때문에 키 디자인 어떻게 하는지에 따라 설명드린 방법처럼 충분히 조인과 같은 결과를 만들어 낼 수 있다.

다음은 주문에 관련된 액세스 패턴이고, 여전히 앞에서부터 보고 있던 것과 동일한 하나의 테이블에서 키 디자인 하고 있다는 것을 명심하자.
5번 엑세스 패턴은 orderId로 특정 주문에 대한 모든 정보를 조회한다.
그래서 키 컨디션은 SK가 없는 것이고, 쿼리 API를 사용한다면 해당 pk에 모든값을 단일 응답으로 리턴받는다.
6번은 특정 orderId 안에 있는 모든 상품 정보를 조회해야 하는 것이니 특정 주문에서 구매한 모든 상품 리스트가 되겠다. 이 경우엔 SK가 begins_with 연산자를 사용한다.
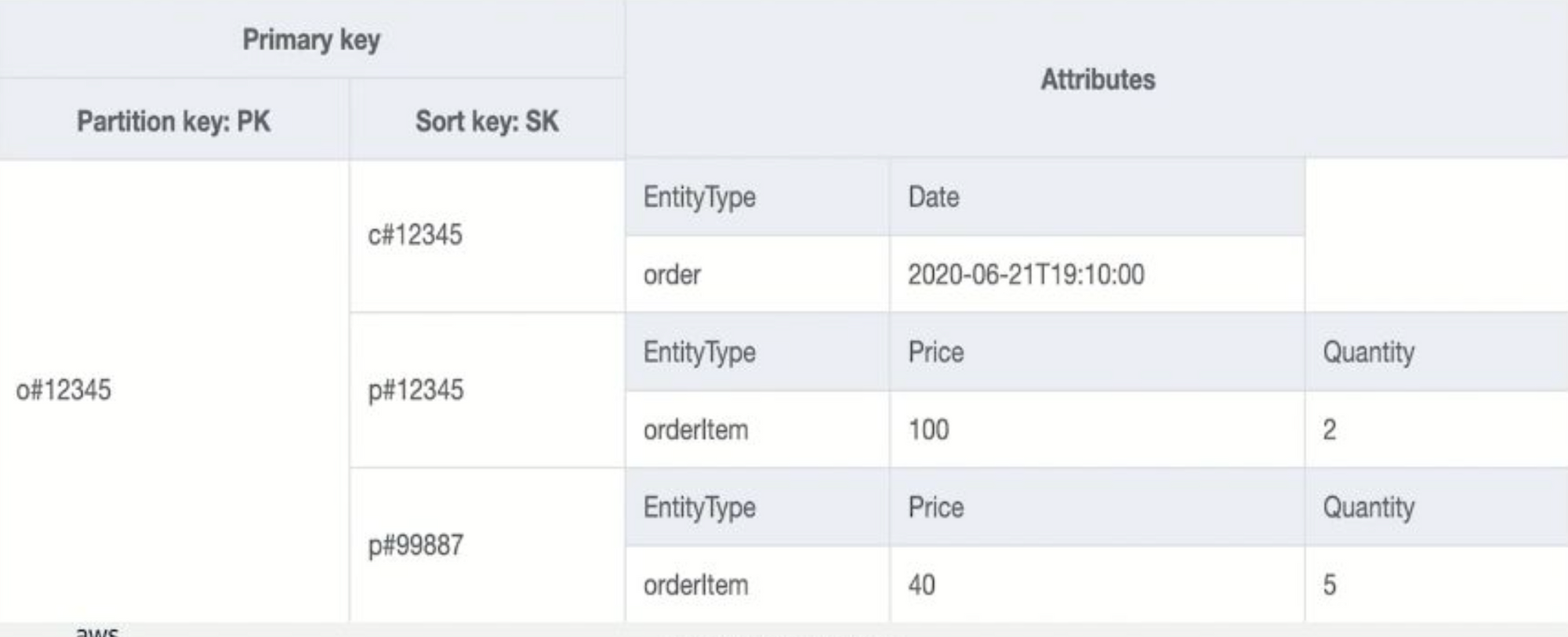
다시 한번 강조하자면 앞에서 봤던 것과 계속 같은 테이블이다.
쿼리 API로 PK만을 이용해 조회하면 현재 화면에 보시는 세 개 아이템이 한 번에 리턴된다.
이는 소비자가 이커머스에서 구매하고 구매이력을 조회하면 나오는 화면이다.
만약 rdbms 였다면 order 테이블과 order Items 테이블로 나눠서 관리되고 orderId로 조인되어 나와야할 3개의 로우들이 될 것.
보는 것처럼 DynamoDB에서도 RDBMS 조인과 같은 결과를 만들어 낼 수 있고, 다만 런타임에 조인 연산을 사용하느냐 미리 내가 나중에 조회 형태대로 만들어서 입력해 두느냐의 차이 밖에 없다.

다음은 오더의 연동된 인보이스 정보를 줘야 하는 액세스 패턴이다.
PK는 orderId고 SK는 인보이스를 나타내는 i#으로 시작되는 것을 검색하는, 즉 비긴스위드 연산자가 사용되는 것을 볼 수 있다.

화면의 파란색은 하나의 아이템이 추가된 것이고, 이제 우리는 하나의 pk에서 3개의 엔티티를 볼 수 있다.
RDBMS 였다면 3개 테이블 조인한 형태일 것.


마지막은 특정 orderId에 속한 모든 배송정보를 줘야 하는 패턴으로,
SK가 배송을 나타내는 sh#으로 시작하는 모든 아이템을 조회한다는 내용.
화면에 파란색으로 보이는 2개의 배송 정보 관련된 아이템이 추가되었고,
화면에 여섯 개 아이템 중에 내가 원하는 엔티티의 데이터만 조회할 수도 있고,
빨간색 박스처럼 4개 엔티티 데이터를 쿼리api를 이용해 단일 호출로도 조회할 수 있는 것.
마지막으로 지금까지 여덟 개 엑세스 패턴을 하나의 테이블로 디자인한 내용을 정리하면 이런 결과가 도출된다.
이것이 바로 DynamoDB 키 디자인.
여기서 필요하다면 선택적으로 GSI가 추가된 것을 제외하면 특이사항이 없다.
이제 위 예제가 정확하게 이해가 된다면 충분히 싱글 테이블 디자인에 도전할 수 있다. PK SK를 이렇게 다양한 패턴으로 디자인할 수 있다는 것을 이해했다면 기술 부채를 하나 줄였고 충분히 가치 있는 시간이 되었다고 생각된다.
정리하면 내가 사용하려는 DynamoDB 특성과 제약사항을 정확하게 이해하고, 디자인 패턴과 Tenet을 익힌후 도전하는 것. 그리고 함께 리뷰하고 이 과정을 서비스 오픈 전까지 반복하는 것이 중요하다.
