이 문제는 다음과 같은 경우 확인해 봐야한다.
- terraform을 이용해 EKS를 구축하였다.
- VPC-CNI 에드온을 사용 중이다.
Retrying waiting for IPAM-D가 무한반복된다.- 새로 추가된 노드에
kube-proxy는 올라갔는데aws-node는running단계에서 진행되지 않는다.
우선 제일 먼저 확실하게 해당 문제가 원인인지 파악하려면 다음 단계를 거치면 된다.
kubectl -n kube-system get all -o wide를 이용해 kube-system내의 구조를 확인한다.
PS C:\...> kubectl -n kube-system get all -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
pod/aws-node-2n7dp 0/1 Running 3 (96s ago) 6m41s xxx.xxx.xxx.xxx ip-xxxxxxxxxxxx.ap-northeast-2.compute.internal <none> <none>
pod/aws-node-7x7z9 0/1 Running 3 (96s ago) 6m42s xxx.xxx.xxx.xxx ip-xxxxxxxxxxxx.ap-northeast-2.compute.internal <none> <none>
pod/aws-node-d24k4 1/1 Running 0 6m41s xxx.xxx.xxx.xxx ip-xxxxxxxxxxxx.ap-northeast-2.compute.internal <none> <none>
pod/aws-node-nbm2t 0/1 Running 3 (97s ago) 6m43s xxx.xxx.xxx.xxx ip-xxxxxxxxxxxx.ap-northeast-2.compute.internal <none> <none>
pod/coredns-556f6dffc4-2xcpw 1/1 Running 0 16h xxx.xxx.xxx.xxx ip-xxxxxxxxxxxx.ap-northeast-2.compute.internal <none> <none>
pod/coredns-556f6dffc4-7c7gc 1/1 Running 0 16h xxx.xxx.xxx.xxx ip-xxxxxxxxxxxx.ap-northeast-2.compute.internal <none> <none>
pod/kube-proxy-djk6s 1/1 Running 0 61m xxx.xxx.xxx.xxx ip-xxxxxxxxxxxx.ap-northeast-2.compute.internal <none> <none>
pod/kube-proxy-ptfpk 1/1 Running 0 61m xxx.xxx.xxx.xxx ip-xxxxxxxxxxxx.ap-northeast-2.compute.internal <none> <none>
pod/kube-proxy-z6pfp 1/1 Running 0 61m xxx.xxx.xxx.xxx ip-xxxxxxxxxxxx.ap-northeast-2.compute.internal <none> <none>
pod/kube-proxy-z7xs5 1/1 Running 0 16h xxx.xxx.xxx.xxx ip-xxxxxxxxxxxx.ap-northeast-2.compute.internal <none> <none>위와 같이 초기에 시작한 노드그룹의 포드 외에는 ready가 켜지지를 않는다.
이 이유를 알기 위해서 포드의 로그를 살펴보면 아래와 같이 포드가 보인다.
kubectl -n kube-system logs pod/aws-node-2n7dp < 여기서 포드 이름은 사람마다 다르니 위의 명령어에서 찾은 켜지지 않은 포드를 입력해라
이때 로그는 이런식으로 뜰 것이다.
PS C:\...> kubectl -n kube-system logs pod/aws-node-2n7dp
Defaulted container "aws-node" out of: aws-node, aws-vpc-cni-init (init)
{"level":"info","ts":"2022-09-02T00:21:46.277Z","caller":"entrypoint.sh","msg":"Validating env variables ..."}
{"level":"info","ts":"2022-09-02T00:21:46.278Z","caller":"entrypoint.sh","msg":"Install CNI binaries.."}
{"level":"info","ts":"2022-09-02T00:21:46.303Z","caller":"entrypoint.sh","msg":"Starting IPAM daemon in the background ... "}
{"level":"info","ts":"2022-09-02T00:21:46.304Z","caller":"entrypoint.sh","msg":"Checking for IPAM connectivity ... "}
{"level":"info","ts":"2022-09-02T00:21:48.321Z","caller":"entrypoint.sh","msg":"Retrying waiting for IPAM-D"}
{"level":"info","ts":"2022-09-02T00:21:50.331Z","caller":"entrypoint.sh","msg":"Retrying waiting for IPAM-D"}
{"level":"info","ts":"2022-09-02T00:21:52.331Z","caller":"entrypoint.sh","msg":"Retrying waiting for IPAM-D"}
{"level":"info","ts":"2022-09-02T00:21:54.331Z","caller":"entrypoint.sh","msg":"Retrying waiting for IPAM-D"}
{"level":"info","ts":"2022-09-02T00:21:56.331Z","caller":"entrypoint.sh","msg":"Retrying waiting for IPAM-D"}
{"level":"info","ts":"2022-09-02T00:21:58.331Z","caller":"entrypoint.sh","msg":"Retrying waiting for IPAM-D"}
{"level":"info","ts":"2022-09-02T00:21:60.331Z","caller":"entrypoint.sh","msg":"Retrying waiting for IPAM-D"}
{"level":"info","ts":"2022-09-02T00:21:62.331Z","caller":"entrypoint.sh","msg":"Retrying waiting for IPAM-D"}이 일이 일어나는 원인은 아래와 같다.
VPC-CNI 애드온을 사용하는 경우 각 aws의 관리형 노드들은 kube-system:aws-node 서비스 어카운트를 통해 aws에 접속해 VPC와 서브넷에 할당 가능한 IP를 검색하게 된다.
아마도 공식 문서나 이런저런 방법을 통해 규칙을 생성했다면 aws iam에 접속해서 규칙을 확인해 보자.
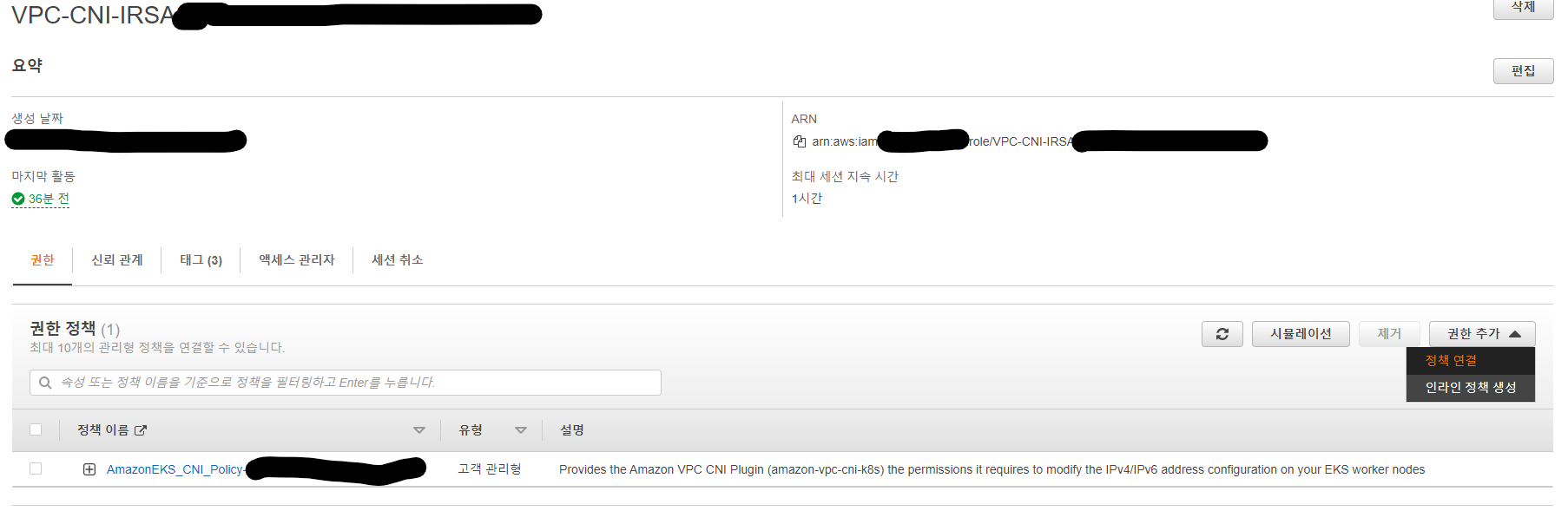
나같은 경우 terraform의 terraform-aws-modules/iam 모듈을 이용해서 자동생성한 규칙이 있었는데 이 규칙은 다음과 같았다.
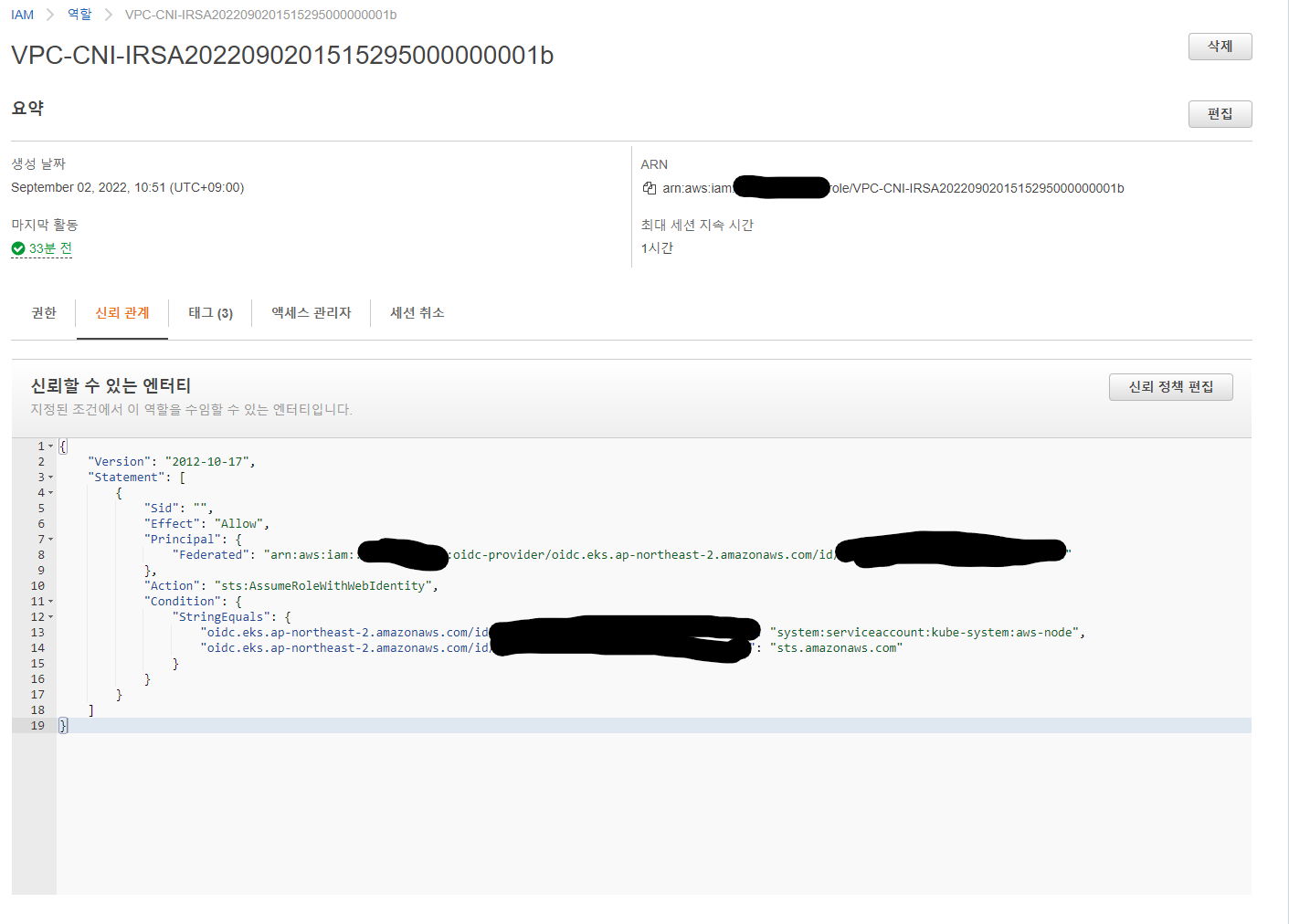
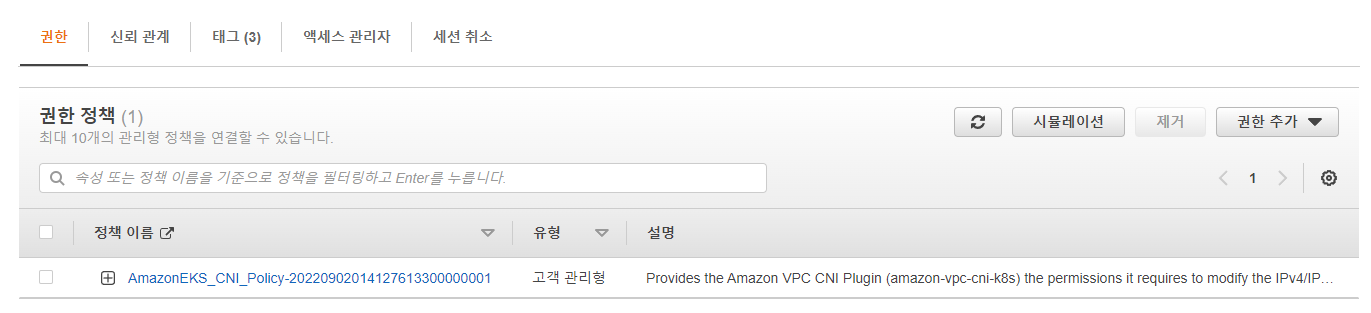
이 역활 VPC-CNI-IRSA2022090201515295000000001b에는 추가로 아래와 같은 고객 관리형 권한이 있었다.
해당 정책의 내부 내용은 다음과 같았다.
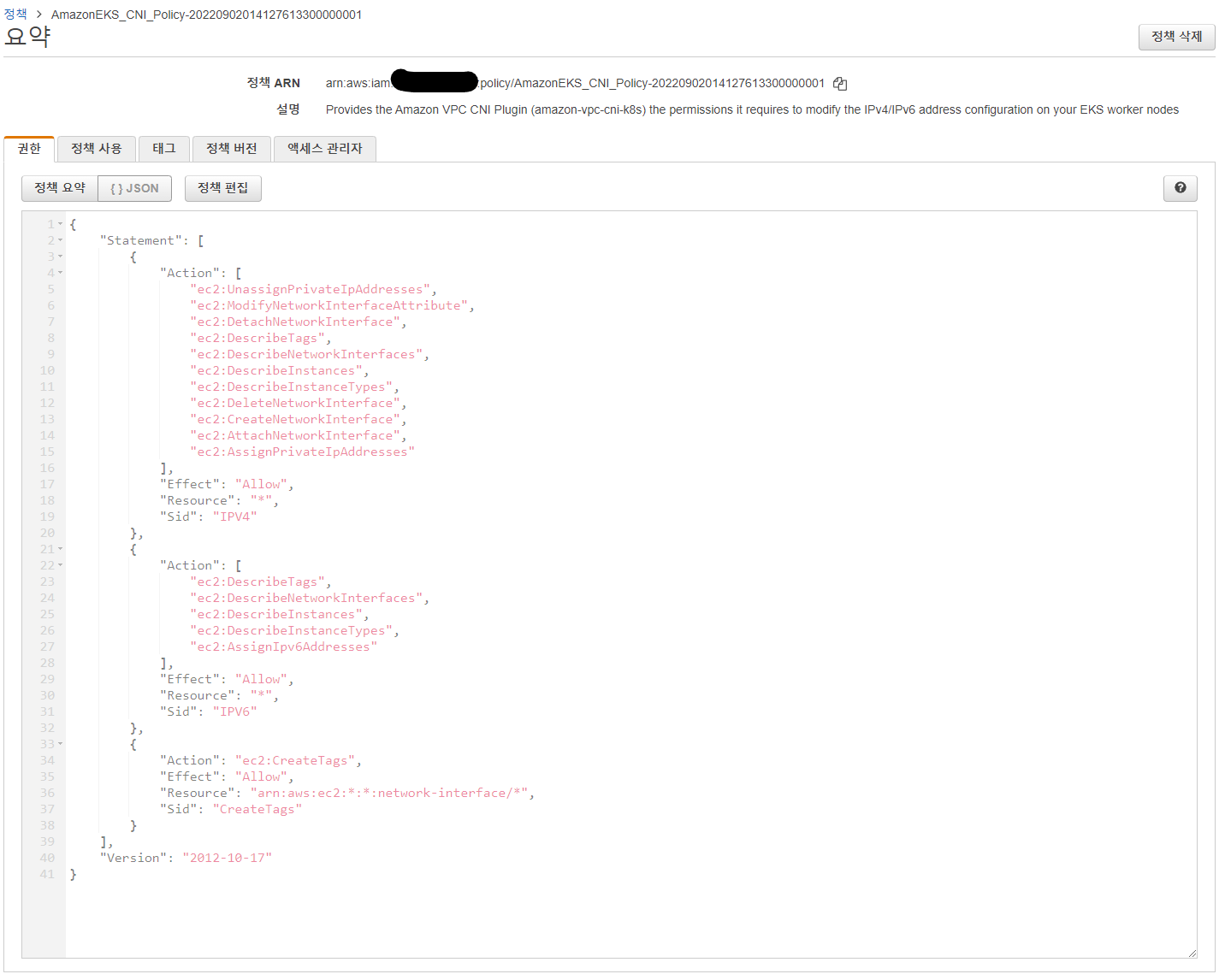
사실 위의 iam 역활은 이미 고쳐진 이후의 내용이라 위와 같은 iam 규칙이 이미 존재한다면 문제가 발생하지 않는다.
나같은 경우 위의 규칙에서 아래 json과 같이 IPv6인 서브넷에서만 정상 동작하는 규칙을 만들었었다.
{
"Statement": [
{
"Action": [
"ec2:DescribeTags",
"ec2:DescribeNetworkInterfaces",
"ec2:DescribeInstances",
"ec2:DescribeInstanceTypes",
"ec2:AssignIpv6Addresses"
],
"Effect": "Allow",
"Resource": "*",
"Sid": "IPV6"
},
{
"Action": "ec2:CreateTags",
"Effect": "Allow",
"Resource": "arn:aws:ec2:*:*:network-interface/*",
"Sid": "CreateTags"
}
],
"Version": "2012-10-17"
}만약 AWS iam role을 어떻게 만들었는지는 사람마다 다르겠지만 직접 만들었다면 AWS 콘솔을 이용해 위와 같은 규칙을 만들어 역활에 부여하면 될 테고,
만약 iam role이 존재하지 않는다면... 일단 OIDC부터 확인해야 해서 골치가 아프고 너무 길어지니 그 경우에는 OIDC가 존재하는지 부터 확인해 봐야 할거다.
만약 iam role을 수정했고 다른 문제가 없다면,
kubectl -n kube-system rollout restart daemonset.apps/aws-node
위의 명령어를 실행해 모든 aws-node(vpc-cni지원을 위한 포드들)을 재실행시켜 문제를 해결할 수 있다.
만약 그렇다면 아래같이 콘솔에 창이 뜰 것이다.
PS C:\...> kubectl -n kube-system get all -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
pod/aws-node-76666 1/1 Running 0 46m xxx.xxx.xxx.xxx ip-xxxxxxxxxxxx.ap-northeast-2.compute.internal <none> <none>
pod/aws-node-bz8bq 1/1 Running 0 46m xxx.xxx.xxx.xxx ip-xxxxxxxxxxxx.ap-northeast-2.compute.internal <none> <none>
pod/aws-node-ghdf9 1/1 Running 0 46m xxx.xxx.xxx.xxx ip-xxxxxxxxxxxx.ap-northeast-2.compute.internal <none> <none>
pod/aws-node-j5wgs 1/1 Running 0 46m xxx.xxx.xxx.xxx ip-xxxxxxxxxxxx.ap-northeast-2.compute.internal <none> <none>
pod/coredns-556f6dffc4-2xcpw 1/1 Running 0 17h xxx.xxx.xxx.xxx ip-xxxxxxxxxxxx.ap-northeast-2.compute.internal <none> <none>
pod/coredns-556f6dffc4-7c7gc 1/1 Running 0 17h xxx.xxx.xxx.xxx ip-xxxxxxxxxxxx.ap-northeast-2.compute.internal <none> <none>
pod/kube-proxy-djk6s 1/1 Running 0 108m xxx.xxx.xxx.xxx ip-xxxxxxxxxxxx.ap-northeast-2.compute.internal <none> <none>
pod/kube-proxy-ptfpk 1/1 Running 0 107m xxx.xxx.xxx.xxx ip-xxxxxxxxxxxx.ap-northeast-2.compute.internal <none> <none>
pod/kube-proxy-z6pfp 1/1 Running 0 107m xxx.xxx.xxx.xxx ip-xxxxxxxxxxxx.ap-northeast-2.compute.internal <none> <none>
pod/kube-proxy-z7xs5 1/1 Running 0 17h xxx.xxx.xxx.xxx ip-xxxxxxxxxxxx.ap-northeast-2.compute.internal <none> <none>참고로 나같은 경우는 terraform을 이용했는데 해당 역활을 생성한 코드는 다음과 같았다.
module "vpc_cni_irsa" { source = "terraform-aws-modules/iam/aws//modules/iam-role-for-service-accounts-eks" version = "~> 4.12" role_name_prefix = "VPC-CNI-IRSA" create_role = true attach_vpc_cni_policy = true vpc_cni_enable_ipv4 = true vpc_cni_enable_ipv6 = true oidc_providers = { main = { provider_arn = module.eks.oidc_provider_arn namespace_service_accounts = ["kube-system:aws-node"] } } }여기서 중요한 부분은 vpc_cni_enable_ipv6와 vpc_cni_enable_ipv4로
둘다 켜져 있어야 ipv4든 ipv6 대역에서든 동작하게 된다.
나같은 경우에는 vpc_cni_enable_ipv6만 켜져있어서 문제가 생겼었다.
원인은?
이 문제는 쿠버네티스의 aws-node의 권한 부족으로 일어난다.
vpc-cni 애드온이 활성화된 경우, aws-node 파드는 aws-node 데몬셋을 통해 모든 노드에 분배되게 되고 각 노드에 분배된 aws-node 파드는 쿠버네티스의 kube-system:aws-node 서비스 어카운트를 통해 AWS 자원에 접근하게 된다.
kube-system:aws-node은 eks에서 자동으로 생성한다.
이때 OIDC를 통해 쿠버네티스 클러스터에서 kube-system:aws-node 서비스 어카운트로 접근한 aws-node 파드 위의 iam role의 아래 코드 중 표시된 부분을 통해 식별되어 AWS 리소스에 접근하게 된다.
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "",
"Effect": "Allow",
"Principal": {
"Federated": "arn:aws:iam::<aws 계정 id>:oidc-provider/oidc.eks.ap-northeast-2.amazonaws.com/id/<oidc id>"
},
"Action": "sts:AssumeRoleWithWebIdentity",
"Condition": {
"StringEquals": {
"oidc.eks.ap-northeast-2.amazonaws.com/id/<oidc id>:sub": "system:serviceaccount:kube-system:aws-node", <<- 이 부분이 중요
"oidc.eks.ap-northeast-2.amazonaws.com/id/<oidc id>:aud": "sts.amazonaws.com"
}
}
}
]
}즉 쿠버네티스 서비스 어카운트를 마치 iam 역활처럼 이뤄지게 하는 동작이 위의 iam role으로 이뤄지게 되는 것이다.
그놈의 aws iam은 정말 사람 속을 불태워 버리네요...
제가 물론 온라인에서 복붙한 코드를 썼으니 제 탓이긴 합니다만...
이래서 이해하지 못하는 코드는 쓰면 안됩니다...
