8편 : 아... 제일 힘든 시간... 디버깅과 단위테스팅, 그 1부
6편부터 사실 라이브러리는 이미 만들었다고 말 했었다.
그런데 사실 다만 일단 코드만 다 짜고, 제대로 돌아가는지 그때는 확인이 안 된 상황이였다.
물론 대략적인 기능들은 잘 돌아가는지 확인했고, 내가 본 JWK 중에서 가장 대표적이라고 생각되는 Google API 에서 쓰는 https://www.googleapis.com/oauth2/v3/certs에서는 잘 돌아가는 걸 확인했었다.
하지만 단순히 몇몇 사례에서 정상적으로 돌아간다는 것 만으로 해당 라이브러리에 문제가 없는지 확신할 수 있는가는 그 누구도 이야기 할 수 없다.
그렇기에 똑똑한 개발자분들은 이런 생각을 했다.
만약 라이브러리를 작은 단위들로 나누어 각 단위들을 모두 테스팅 한다면, 아마 대다수의 에러들은 걸러 낼 수 있지 않을까?
역시 똑똑해. 그러니 나도 똑똑한 분들이 고안한 단위 테스팅을 도입해 내 라이브러리를 검증해 보자.
다만 엄격하게 단위 테스트를 해내려면 목 객체도 만들고 해야 하는데 나는 그렇게까지는 하지 않을 것이고 이전 단위 테스트에서 통과한 부분은 100% 신뢰한다고 가정하고 단위 테스팅 코드를 짤 것이다.
Go 언어의 단위 테스팅과, Code Coverage

혹시 오픈소스 라이브러리에서 위와 같은 태그들을 본 적이 있는가?
여기서 나오는 항목들은 이 프로젝트가 어떤 부분을 얼만큼 충족했다. 같은 일종의 게임으로 치자면 도전과제 같은 것들이다.
여기서 내가 이야기하고 싶은 내용은 codecov이다.
코드 커버리지(Code coverage)란 테스팅의 결과가 코드들을 얼마나 잘 확인하고 있는가?를 나타내는 지표 중 하나다.
테스팅을 수행할 때 테스트를 진행하는 도구가 소스코드와 테스트 코드들을 분석하면서 테스팅 도중 거쳐가는 소스코드의 라인들을 측정한다.
그러면서 최종적으로 코드 커버리지 = 테스팅 중 거쳐간 코드 라인 / 전체 코드 라인의 계산식을 통해 코드 커버리지를 계산한다.
이렇게 커버리지를 측정하면 테스팅 코드를 작성할 때 혹시 확인하지 못한 부분이 있는지 시각적으로 확인이 가능해진다.
위와 같은 형태로 코드 커버리지의 결과가 나온다.
이 결과에 대해 이야기하자면 테스팅 중 한번도 확인 못한 부분은 붉은색으로, 테스팅 중 확인하고 지나간 부분은 푸른 색으로 표시해준다.
즉 커버리지는 푸른색으로 표시된 줄 / (푸른색 줄 + 붉은색 줄)이다.
사실 codecov는 코드 커버리지를 측정할 때 쓰는 도구 이름이다.
코드 커버리지는 라인 커버리지, 분기 커버리지 등, 여러 방법으로 측정 가능하지만 가장 대표적으로 사용되는 커버리지는 소스코드를 줄 단위로 분석하는 라인 커버리지이다. 위에서 설명한 부분은 라인 커버리지이다.
단위 테스팅의 작성
사실 포스트를 올리는 지금은 테스팅을 모두 작성하지 못했다. 그래서 글의 제목이 테스팅 1편이다.
만약 테스팅을 모두 완료했다면 바로 하나로 묶어 한편으로 했을 것이다.
그러면 어떤 식으로 테스팅을 진행할 지 이야기하자면, 일단 코드 커버리지를 측정하기 위한 방법으로는 Go test를 이용할 것이다.
해당 도구는 go 언어에서 자체적으로 제공하는 테스트 및 코드 커버리지 측정용 도구인데 해당 도구를 사용하면 별다른 외부 도구의 사용 없이도 바로 코드 커버리지를 측정 가능해진다.
go test는
go test <테스트할 대상>형식으로 실행이 가능하다.
go 언어에서 새로운 라이브러리를 다운로드할 때go get <라이브러리 주소>형식으로 다운로드하는 것과 동일하다.
모든 코드에 대해 일관적으로 커버리지를 작성하려면 시간이 좀 걸리므로 일단 이 블로그에는 sortkey.go라는 내부적으로 Key들을 정렬하기 위해 사용되는 간단한 파일 한개만 테스팅을 작성할 것이다.
우선 테스팅 전체 코드는 아래와 같다.
func TestSortkey(t *testing.T) {
t.Run("name is different", func(t *testing.T) {
data := []jwk.Key{
&jwk.UnknownKey{BaseKey: jwk.BaseKey{KeyID: "D"}, KeyType: jwk.KeyTypeOctet},
&jwk.UnknownKey{BaseKey: jwk.BaseKey{KeyID: "A"}, KeyType: jwk.KeyTypeOctet},
&jwk.UnknownKey{BaseKey: jwk.BaseKey{KeyID: "B"}, KeyType: jwk.KeyTypeOctet},
&jwk.UnknownKey{BaseKey: jwk.BaseKey{KeyID: "C"}, KeyType: jwk.KeyTypeOctet},
}
ids := make([]string, len(data))
for i, k := range data {
ids[i] = k.Kid()
}
sort.Strings(ids)
jwk.SortKey(data)
for i, v := range ids {
if data[i].Kid() != v {
t.Fatalf("must be data[%d] == '%s'", i, v)
}
}
})
t.Run("name is same, but different type", func(t *testing.T) {
data := []jwk.Key{
&jwk.UnknownKey{BaseKey: jwk.BaseKey{KeyID: "A"}, KeyType: jwk.KeyTypeOctet},
&jwk.UnknownKey{BaseKey: jwk.BaseKey{KeyID: "A"}, KeyType: jwk.KeyTypeRSA},
&jwk.UnknownKey{BaseKey: jwk.BaseKey{KeyID: "A"}, KeyType: jwk.KeyTypeEC},
}
jwk.SortKey(data)
if data[0].Kty() != jwk.KeyTypeEC {
t.Fatalf("must be data[%d].Kty() == '%s'", 0, jwk.KeyTypeEC)
}
if data[1].Kty() != jwk.KeyTypeRSA {
t.Fatalf("must be data[%d].Kty() == '%s'", 1, jwk.KeyTypeRSA)
}
if data[2].Kty() != jwk.KeyTypeOctet {
t.Fatalf("must be data[%d].Kty() == '%s'", 2, jwk.KeyTypeOctet)
}
})
t.Run("name and type mixed", func(t *testing.T) {
// A(oct), B(oct), C(EC), C(oct), D(oct), E(EC), E(RSA), E(oct)
data := []jwk.Key{
&jwk.UnknownKey{BaseKey: jwk.BaseKey{KeyID: "E"}, KeyType: jwk.KeyTypeEC},
&jwk.UnknownKey{BaseKey: jwk.BaseKey{KeyID: "C"}, KeyType: jwk.KeyTypeOctet},
&jwk.UnknownKey{BaseKey: jwk.BaseKey{KeyID: "E"}, KeyType: jwk.KeyTypeRSA},
&jwk.UnknownKey{BaseKey: jwk.BaseKey{KeyID: "D"}, KeyType: jwk.KeyTypeOctet},
&jwk.UnknownKey{BaseKey: jwk.BaseKey{KeyID: "B"}, KeyType: jwk.KeyTypeOctet},
&jwk.UnknownKey{BaseKey: jwk.BaseKey{KeyID: "C"}, KeyType: jwk.KeyTypeEC},
&jwk.UnknownKey{BaseKey: jwk.BaseKey{KeyID: "A"}, KeyType: jwk.KeyTypeOctet},
&jwk.UnknownKey{BaseKey: jwk.BaseKey{KeyID: "E"}, KeyType: jwk.KeyTypeOctet},
}
expected := []jwk.Key{
&jwk.UnknownKey{BaseKey: jwk.BaseKey{KeyID: "A"}, KeyType: jwk.KeyTypeOctet},
&jwk.UnknownKey{BaseKey: jwk.BaseKey{KeyID: "B"}, KeyType: jwk.KeyTypeOctet},
&jwk.UnknownKey{BaseKey: jwk.BaseKey{KeyID: "C"}, KeyType: jwk.KeyTypeEC},
&jwk.UnknownKey{BaseKey: jwk.BaseKey{KeyID: "C"}, KeyType: jwk.KeyTypeOctet},
&jwk.UnknownKey{BaseKey: jwk.BaseKey{KeyID: "D"}, KeyType: jwk.KeyTypeOctet},
&jwk.UnknownKey{BaseKey: jwk.BaseKey{KeyID: "E"}, KeyType: jwk.KeyTypeEC},
&jwk.UnknownKey{BaseKey: jwk.BaseKey{KeyID: "E"}, KeyType: jwk.KeyTypeRSA},
&jwk.UnknownKey{BaseKey: jwk.BaseKey{KeyID: "E"}, KeyType: jwk.KeyTypeOctet},
}
jwk.SortKey(data)
for i, k := range expected {
if data[i].Kid() != k.Kid() {
t.Fatalf("data[%d] must be kid = '%s'", i, k.Kid())
}
if data[i].Kty() != k.Kty() {
t.Fatalf("data[%d] must be kty = '%s'", i, k.Kty())
}
}
})
t.Run("random generated 1.5M, mixed test", func(t *testing.T) {
const GENERATED_LENGTH = 1_500_000
const ID_MINLEN = 2
const ID_MAXLEN = 4
var TYPE_ONEOF = []jwk.KeyType{jwk.KeyTypeOctet, jwk.KeyTypeEC, jwk.KeyTypeRSA}
var KTY_TO_INT_TABLE = map[jwk.KeyType]int{
jwk.KeyTypeEC: -3,
jwk.KeyTypeRSA: -2,
jwk.KeyTypeOctet: -1,
}
var CHARSET = []rune("abcdefghijklmnopqrstuvwxyz")
gen_id := func(length int) string {
result := make([]rune, 0, length)
for i := 0; i < length; i++ {
result = append(result, CHARSET[rand.Intn(len(CHARSET))])
}
return string(result)
}
keys := make([]jwk.Key, 0, GENERATED_LENGTH)
ids := make([]string, 0, GENERATED_LENGTH)
for i := 0; i < GENERATED_LENGTH; i++ {
kid := gen_id(ID_MINLEN + rand.Intn((ID_MAXLEN-ID_MINLEN)+1))
kty := TYPE_ONEOF[rand.Intn(len(TYPE_ONEOF))]
keys = append(keys, &jwk.UnknownKey{BaseKey: jwk.BaseKey{KeyID: kid}, KeyType: kty})
ids = append(ids, kid)
}
sort.Strings(ids)
jwk.SortKey(keys)
for i := 0; i < GENERATED_LENGTH; i++ {
if ids[i] != keys[i].Kid() {
t.Fatalf("expected data[%d].Kid() is '%s', but got '%s'", i, ids[i], keys[i].Kty())
}
currID := keys[i].Kid()
currTYP := KTY_TO_INT_TABLE[keys[i].Kty()]
for j := i; j < GENERATED_LENGTH && keys[j].Kid() == currID; j++ {
jTYP := KTY_TO_INT_TABLE[keys[j].Kty()]
if currTYP > jTYP {
t.Fatalf("from data[%d] to data[%d], data[%d].Kty() is '%s', but data[%d].Kty() is '%s'", i, j, i, keys[i].Kty(), j, keys[j].Kty())
}
if jTYP > currTYP {
currTYP = jTYP
}
}
}
})
}여기서 TestSortKey 아래에 name is different, name is same, but different type, name and type mixed, random generated 1.5M, mixed test이렇게 4개의 테스트 케이스들이 작성되어 있다.
각 요소는 SortKey를 테스트하기 위한 여러가지 방법에 대한 부분인데 우선 이 테스팅 코드가 왜 이러한가? 를 이야기하기 위해서는 우선 SortKey부터 먼저 이야기해야 할 것 같다.
SortKey는 입력으로 []Key, 즉 키의 배열을 받아 해당 배열을 정렬해 주는 함수이다.
이게 있는 이유는 Go에서는 제네릭을 지원하지 않아 정렬을 위해서는 sort.Interface를 구현하는 타입을 반드시 직접 선언해 줘야 하는데 해당 타입은 별로 대단한 부분이 없기 때문에 라이브러리에서 해당 하입은 숨기되 해당 기능은 사용할 수 있게 만들기 위해서 해당 함수를 정의했다.
이를 정의한 이유는 키를 정렬할 때는 2가지 요소가 필요하기 때문이다.
우선 키는 kid라고 불리는 키의 아이디를 통해 사전형식으로 정렬된다.(대소문자 구분) 이후 키의 kid가 같다면 추가적으로 kty이라고 불리는 부분을 통해 추가적인 정렬을 필요로 한다.
이때 kty은 string 타입이지만 사전순 정렬이 아닌 "EC", "RSA", "oct"순서로 정렬해줘야 한다.
이제 각각의 테스트 케이스에 대해 설명하자 이는 다음과 같다.
키들이 이름이 다른 경우를 확인하는 name is different
해당 테스트에서는 이름이 다른 경우를 확인한다.
위의 테스트에서는 키가 모두 타입은 oct으로 동일하고 kid가 각각 A, B, C, D인 사례에서 정렬이 제대로 수행된는지를 확인한다.
테스트의 확인은 키들만 모은 string배열의 결과와의 비교를 통해 확인한다.
키들이 이름은 같지만, 타입이 다른 경우를 확인하는 name is same, but different type
해당 테스트는 키의 이름은 같지만 타입이 다른 경우 제대로 정렬이 됬는지를 확인한다.
즉 위의 경우는 {kid:"A", kty : "oct"}, {kid:"A", kty : "RSA"} {kid:"A", kty : "EC"}가 EC, RSA, oct 순서로 제대로 배열되었는지를 확인한다.
키들이 이름도, 타입도 다른 경우를 확인하는 name and type mixed
해당 테스트에서는 이름과 타입이 모두 다른 경우를 확인한다.
위의 두 테스트 케이스가 공존하는 경우 제대로 된 출력이 나오는지를 확인한다.
백만개의 테스트 케이스를 동적으로 만들어 확인하는 random generated 1.5M, mixed test
해당 테스트에서는 1백만개의 테스트 케이스를 만들어 해당 항목이 원하는 대로 정렬되었는지 확인한다.
여기서 왜 백만개의 테스트 케이스를 만들었냐면 이 테스트에서 ID는 정규식으로 표현하면 [A-Z]{2,4}형태를 가진다.
이 때 모든 가능한 경우의 수는 26^2 + 26^3 + 26^4이다.
이를 계산하면 475228이 된다.
따라서 랜덤으로 키를 생성하더라도 키 타입은 3개이므로 475228 * 3 = 1425684개 이므로 1.5백만개면 내가 별도의 테스트케이스를 작성하지 않더라도 아마 가능한 모든 경우의 수가 나타날 것이다.
테스팅 코드의 확인
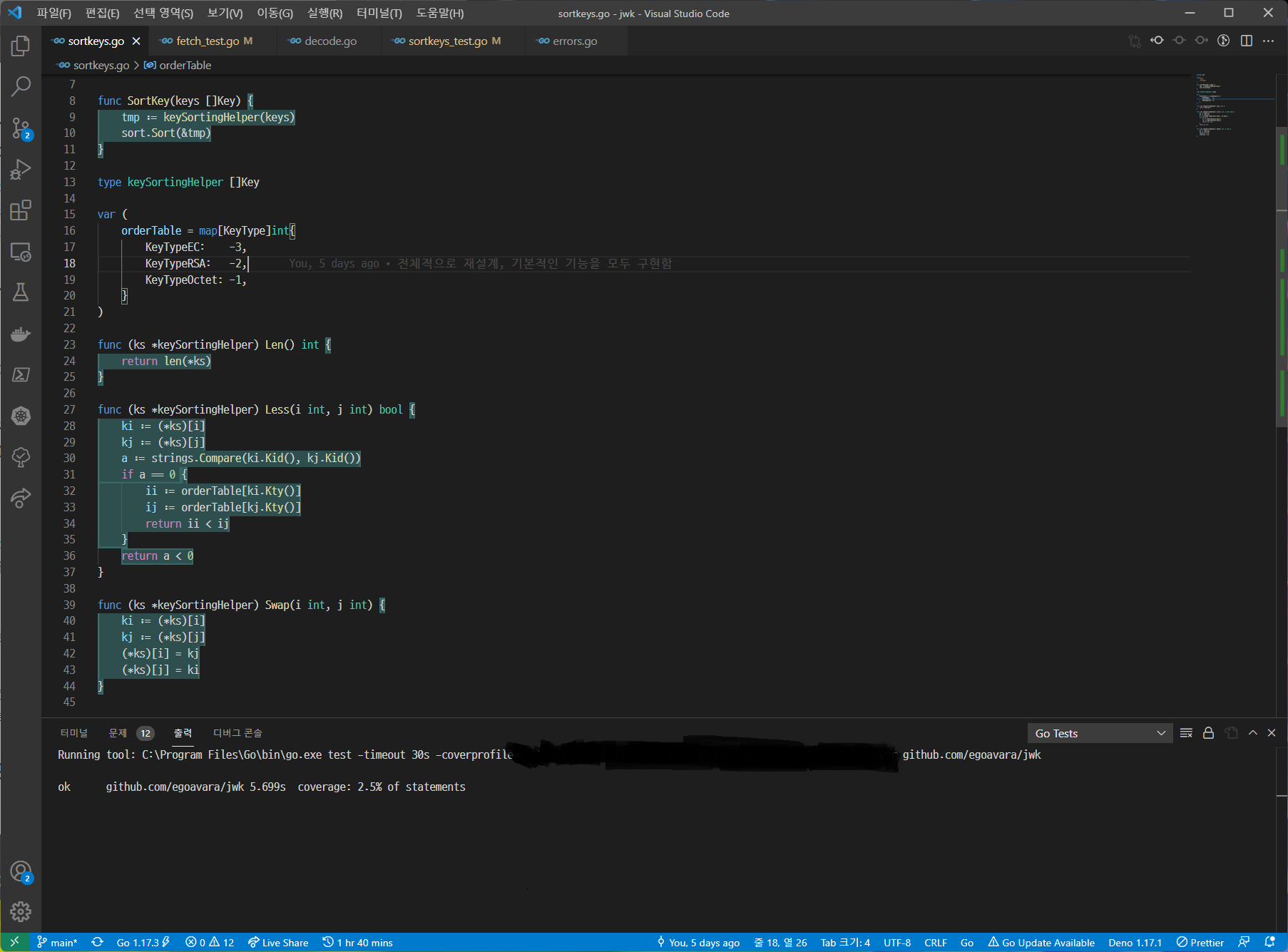
이 코드를 최종적으로 실행하면 다음과 같이 되는 것을 확인할 수 있다.
참고로 2.5% 코드 커버리지라 나오는데 사실 이거보다 더 많은 테스팅 코드가 이미 있기 때문에 2.5% 씩이나 나오는 것이다. 이제 이걸 못해도 95%까지 올리는 것이 내가 해야할 일이다.
코드 커버리지와 단위 테스팅은 오픈소스 라이브러리들을 볼 때마다 *_test.go 형식의 파일이 자주 눈에 띄어서 이게 뭐하는 파일인가?를 조사하며 알게 되었다.
이후 대학교 소프트웨어 공학개론 수업에서 이게 뭔지 자세히 알게 되었다.
개인적으로 코드 커버리지와 단위 테스팅을 모를 때에는 과연 내가 제대로 만들고 있는건가? 하는 의문이 자주 들 때가 많았다.
하지만 코드 커버리지와 단위 테스팅을 배우면서 적어도 내가 신경쓰지 못하고 대충 넘긴 코드 부분은 없구나! 라는 것을 확신하게 만들어주는 점이 매우 좋았다.
이제 단위 테스트 코드를 어느정도 완성하고 나면 해당 글을 정리하는 편과 사용법을 정리하는 글, 그리고 CI/CD를 위한 Github Action을 적용하는 글을 올리고 싶다.
물론 전에 이런 식으로 쓰고 싶다라고 올린 적이 있는데 단 하나도 제대로 생각대로 쓴 글이 없어서... 그냥 대충 그럴 것 같다는 의미이다.
