우선 시작하기 앞서, postgres는 RDBMS가 아닌 스스로를 ORDBMS라고 한다.
여기서 O는 객체지향에서 말하는 그 Objective 를 의미하는데 postgres는 스스로를 그렇게 설명하는 만큼 직접 사용하다 보면 "이런 기능이 DBMS에 있다고???? 싶은 기능이 자주 보인다."
그중 하나가 array 기능인데 데이터베이스 정규형을 배워봤다면 원자성에 대한 이야기를 들어봤을 것이다.
근데 pg는 무려 배열 타입을 자체 지원하는 데이터베이스이다.
다만 이 기능은 이야기하기에는 길어지고 논쟁이 좀 있을 수도 있으니 생략하고,
이번에 이야기하고자 하는 것은 집계로서의 array 이다.
문제 상황
한 쿼리가 존재하는데 해당 테이블은 4개의 테이블을 조인해서 만들어진다.
이때 조인 중 하나는 left outer joing으로 1:N의 관계를 가진다.
즉 개념적으로 아래와 같은 구조이다.
select
*
from
학생
inner join 교실
inner join 사물함
left join 수강과목이런 식으로 1명의 학생에 여러 수강과목이 달려있는 형태로 되어 있었다.
여기서 내가 문제삼고 싶었던 부분은 이 부분을 가져오는 해당 mybatis resultmap이였다.
<resultMap id="학생" type="com.example.학생">
<result property="학번" column="학번"/>
<result property="교실명" column="교실명"/>
<result property="사물함번호" column="사물함번호"/>
<collection property="수강과목목록" column="수강과목명" javaType="list" ofType="String">
<result property="수강과목명" column="수강과목명"/>
</collection>
</resultMap>여기서 collection은 1:N문제에서 서브쿼리를 수도 없이 많이 보내는 DB 테러 문제를 해결하기 위해 생겨난 기능으로 한 마디로 정의하면 서버에서 수행하는 groupby 정도에 해당한다.
그런데 이 과정에서 나는 생각을 해 봤다.
여기서 학생은 내 케이스에서는 16만개 이상이 존재했다. 그런데 left join 된 수강과목에 의해 총 열은 18만개가 나온다.(대다수 학생은 1과목만 수강한다)
더 자세히 확인해 보니 1과목 이상을 수강하는 학생은 8000명 정도인데 이놈들 땜에 무러 2만줄이 더 추가된 것이다.
이는 행 2만개지만 그 2만개의 대다수 열은 중복된 부분이 많다 예를 들어 아래 경우를 살펴보자.
학번 교실명 사물함 번호 수강과목
20230000 컴공반 A000 C언어
20230000 컴공반 A000 JAVA
20230000 컴공반 A000 Python
20230001 컴공반 A001 C언어
20230002 컴공반 A002 C언어
...이런 식이면 2023000, 컴공반, A000 라는 데이터는 불필요하게 2번 중복되어 나타난다.
따라서 내 계산에 의하면 예시 위의 실제 사례에서는 2만행 * (행당 데이터 크기 - 고유한 값)개의 중복값이 나타날 것으로 예상하였다.
이는 단순 계산으로도 좀 차이가 있었고 성능 하락도 예견되는 상황이였다.
문제 해결법
postgres에는 array 가 있다.
이는 사실 데이터 저장보다는 집계와 서버로 가져오는 과정에서 더 유용하다.
위 코드를 아래처럼 바꿔 보자.
select
*
from
학생
inner join 교실
inner join 사물함
left join 수강과목 <resultMap id="학생" type="com.example.학생">
<result property="학번" column="학번"/>
<result property="교실명" column="교실명"/>
<result property="사물함번호" column="사물함번호"/>
<collection property="수강과목목록" column="수강과목명" javaType="list" ofType="String">
<result property="수강과목명" column="수강과목명"/>
</collection>
</resultMap>select
*,
array(select * from 수강과목 where 수강생학번 = 학번)
from
학생
inner join 교실
inner join 사물함 <resultMap id="학생" type="com.example.학생">
<result property="학번" column="학번"/>
<result property="교실명" column="교실명"/>
<result property="사물함번호" column="사물함번호"/>
<result property="수강과목목록" column="수강과목목록" typeHandler="com.example.PgArrayTypeHandler"/>
</resultMap>typeHandler는 sql에서 준 배열을 파싱하기 위한 커스텀 타입 핸들러인데, postgres array를 List 타입으로 변환하는 과정이 필요해서 이렇게 해 봤다.
이렇게 하면 postgres는 위의 예시가 이렇게 변하게 전송할 수 있다.
학번 교실명 사물함 번호 수강과목
20230000 컴공반 A000 C언어
20230000 컴공반 A000 JAVA
20230000 컴공반 A000 Python
20230001 컴공반 A001 C언어
20230002 컴공반 A002 C언어
...학번 교실명 사물함 번호 수강과목
20230000 컴공반 A000 {C언어,JAVA,Python}
20230001 컴공반 A001 {C언어}
20230002 컴공반 A002 {C언어}
...이러면 중복값을 많이 줄이고 서버에서 집계를 위한 메모리와 런타임을 아낄 수 있다고 생각했고 이를 실제로 코드에 적용해서 실험해 봤다.
실험 결과
개선 이전

개선 후
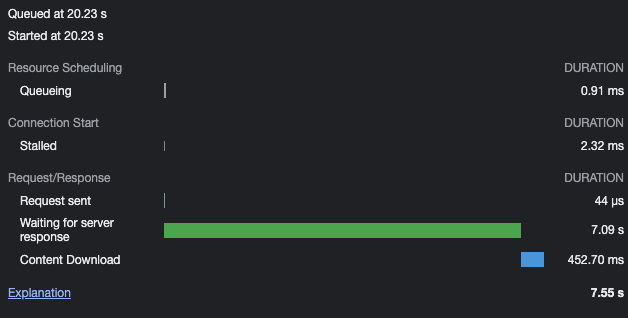
개선 이후 약 10회정도의 작업을 수행하였고 swagger를 통해 API 호출로 테스트 해 봤다.
모든 결과를 가져올 순 없으니 대략적인 중위값을 표시해 봤다.
일단 내 사례에서는 위의 Waiting for server response 결과가 약 8.2s 정도에서 7s 정도로 1.2s 정도 개선되었다.
Content Download는 무시해도 된다, 서버 응답성능하고는 전혀 관계없다.
이 개선은 184466개의 학생에 대한 쿼리 중 8013개의 1개 초과의 수강과목을 듣는 학생에 의해 192956개의 행이 생기는 경우에 대한 개선 결과이며 이는 테스트용 데이터라 실제 데이터에서는 더 개선이 존재할 수도 있을 것이라 생각된다.
특히 이 배열에 관한 쿼리는 여기저기서 많이 사용되고 있었기에 개선 효과가 더 클 수 있을 것이라 생각되니만큼 가치가 더 클 수 있다고 기대된다.
한계점
이 개선점은 잠재적으로 데이터베이스 성능을 더 요구한다.
실제로 해당 집계는 스칼라 서브쿼리에 해당하므로 데이터베이스 부담은 매우 높다.
실제로 내가 분석한 바에 의하면 개선 전 join 기반 쿼리는 0.7s 정도에 처리되었지만 서브쿼리 기반 솔루션은 1.4s로 거의 2배가량 쿼리 성능이 하락하였다.
다만 내가 이 방법을 생각해 본 이유는 원래 상황이 8s 정도의 실행시간 중 쿼리에 걸리는 시간이 0.7s밖에 안되기에 한번 생각해 본 것이다.
즉 실제 응답시간에서 원래 집계에 이용되던 mybatis collection의 오버헤드는 2s 미만 정도라고 대략 추측해 볼 수 있다.
하지만 만약, api 서버에서 늘어난 db 부하를 버틸 만큼의 db 자원이 없다면? 이때는 한번 생각해 봐야될 솔루션이다.
