
내가 처음으로 배운 프로그래밍 언어는 C 이다.
그렇기에 문자열은 char의 포인터라고 배웠다.
틀린 말은 아니고, 처음 프로그래밍을 배우는 사람에게 말하기에는 적절하지만, 이제는 이것만으로는 설명이 모자르다라고 여겨진다.
따라서 문자열에 대해 더 자세하게 알아보고자 한다.
실제로 직접 알아본 결과 문자열은 내 생각 이상으로 복잡하고 어려웠다.
따라서 이번 시리즈에서는 내가 인터넷에서 프로그래밍 언어별 소스코드 기반으로 문자열을 구현하는 방법과 그에 따라 어떻게 문자열이 구성되었는가를 분석할 것이다.
이 글은 64비트, amd64 아키텍쳐에서 실험되었다.
C++, "libstdc++"
C++ 구현 중 하나인 g++의 표준 라이브러리이다.(GNU GCC)
우리가 gcc를 사용할 때 사용되는 구현이다.
실험에 사용된 버전은 9.3.0이다.
다만, 온라인 도큐먼트는 9.4.0으로 링크가 걸려 있는데 소스코드는 동일한지 확인하고 링크를 걸었다. 9.3.0은 온라인 도큐먼트를 못 찾아서 어쩔수 없었다.
실제 구현체
실제 소스코드에서 데이터 구조에 대한 필수적인 부분만 정의하면 아래와 같다.
template<typename _CharT, typename _Traits, typename _Alloc>
class basic_string {
// 154번째 줄부터
struct _Alloc_hider : allocator_type {
pointer _M_p; // 실제 데이터가 저장되는 포인터
};
_Alloc_hider _M_dataplus;
size_type _M_string_length;
enum { _S_local_capacity = 15 / sizeof(_CharT) };
union {
_CharT _M_local_buf[_S_local_capacity + 1];
size_type _M_allocated_capacity;
};
// 179번째 줄까지
};여기서 사용된 소스코드는 아래 주소의 111번째 줄부터 나온다.
https://gcc.gnu.org/onlinedocs/gcc-9.4.0/libstdc++/api/a00290_source.html
여기서 우리가 주로 사용하는 string은 basic_string을 이용해 이렇게 정의되어 있다.
/// A string of @c char
typedef basic_string<char> string; 여기서 사용된 소스코드는 아래 주소의 79번째 줄부터 나온다.
https://gcc.gnu.org/onlinedocs/gcc-9.4.0/libstdc++/api/a00617_source.html
즉 string을 쓸 때 basic_string에서 사용되는 type들은 다음과 같다.
template<typename _CharT, typename _Traits, typename _Alloc>
class basic_string {
// 154번째 줄부터
struct _Alloc_hider : allocator_type {
char* _M_p; // 실제 데이터가 저장되는 포인터
};
_Alloc_hider _M_dataplus;
size_t _M_string_length;
enum { _S_local_capacity = 15 / sizeof(char) };
union {
char _M_local_buf[_S_local_capacity + 1];
size_t _M_allocated_capacity;
};
// 179번째 줄까지
};위의 클래스에는 수많은 메서드와 여러 타입 정의들이 있지만 실제 저장되는 데이터는 다음과 같은 부분이 전부이다.
위의 내용에 따르면 해당 클래스의 크기는 다음과 같다.
_M_dataplus실제 데이터가 저장되는 위치, 64비트 PC 이므로 크기는 8바이트_M_string_length데이터가 총 몇 바이트 크기를 가졌는지에 대한 정보이다. 크기는 8바이트이고 위의 데이터가 저장되는 위치에 데이터가 총 몇 바이트인지를 의미한다.- 유니언 필드 : 두 개중 더 큰 것은
_M_local_buf로 크기는 16바이트이다._M_local_bufSSO 라고 불리우는 기능을 지원하기 위한 필드이다. 크기는 16바이트._M_allocated_capacity는size_t타입으로 64비트에서는 대개 8바이트이다.
libstdc++에서 string은 이렇게 3개의 필드로 구성된다.(하나는 유니언)
즉 여기서 SSO 가 아닌 경우라면
_M_dataplus가 의미하는 문자열 배열의 포인터
_M_string_length가 의미하는 스트링 크기
_M_allocated_capacity가 의미하는 용량이 있다.
각 필드는 8, 8, 16 바이트로 capacity의 경우 SSO를 위한 _M_local_buf와 유니언으로 결합되어 16바이트 크기를 차지하게 된다.
일반 스트링과 SSO
우선 SSO란 Small String Optimization의 약자로 문자열의 동적할당을 최대한 줄이기 위해 나왔다.
이는 말로 하면 좀 복잡할 수도 있는데 직관적으로 이야기하면
작은 문자열을 힙이 아니라 스택에 저장하자
라는 이야기이다.
여기서 libstdc++는 32바이트이고 _M_local_buf가 SSO라고 했는데 즉 _M_local_buf 는 크기가 16이고 c++에서는 C 의 null terminator 호환을 위해 마지막 바이트는 항상 0으로 고정하므로 libstdc++에서 SSO는 15 바이트 이하의 문자열을 사용할 때 적용된다.
사실 말로는 아무리 열심히 말해보려 해도 도저히 잘 말할 자신이 없으니 직관적인 그림을 그려보도록 하자.

문자열 "HelloWorld"는 총 10자이므로 small string으로 전환되어 포인터는 다른 위치가 아닌 자기 자신의 16번째 바이트의 주소를 가르키게 된다.
반면에 "HelloWorldHelloWorld"같은 20자, 즉 15자 이상의 문자열은 이렇게 저장된다.
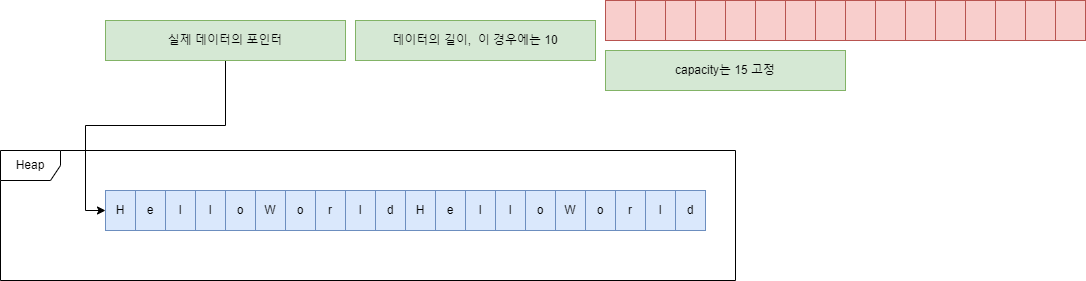
즉 이 구현은 32바이트 중 16바이트는 문자열 정보에, 16바이트는 문자열 캐퍼시티 혹은 sso를 위한 정보에 이용된다.
C++, libc++
C++ 구현 중 하나인 clang++의 표준 라이브러리로 실험에 사용된 버전은 9.0.0이다.
아무래도 같은 c++여서 그런지 libstdc++와 구현하는 방법에 유사점을 느꼈다.
일단 소스코드 중 내가 찾은 내용은 다음과 같다.
template<class _CharT, class _Traits, class _Allocator>
class _LIBCPP_TEMPLATE_VIS basic_string
: private __basic_string_common<true>
{
public:
...
private:
#ifdef _LIBCPP_ABI_ALTERNATE_STRING_LAYOUT
struct __long
{
pointer __data_;
size_type __size_;
size_type __cap_;
};
#ifdef _LIBCPP_BIG_ENDIAN
static const size_type __short_mask = 0x01;
static const size_type __long_mask = 0x1ul;
#else // _LIBCPP_BIG_ENDIAN
static const size_type __short_mask = 0x80;
static const size_type __long_mask = ~(size_type(~0) >> 1);
#endif // _LIBCPP_BIG_ENDIAN
enum {__min_cap = (sizeof(__long) - 1)/sizeof(value_type) > 2 ?
(sizeof(__long) - 1)/sizeof(value_type) : 2};
struct __short
{
value_type __data_[__min_cap];
struct
: __padding<value_type>
{
unsigned char __size_;
};
};
#else
struct __long
{
size_type __cap_;
size_type __size_;
pointer __data_;
};
#ifdef _LIBCPP_BIG_ENDIAN
static const size_type __short_mask = 0x80;
static const size_type __long_mask = ~(size_type(~0) >> 1);
#else // _LIBCPP_BIG_ENDIAN
static const size_type __short_mask = 0x01;
static const size_type __long_mask = 0x1ul;
#endif // _LIBCPP_BIG_ENDIAN
enum {__min_cap = (sizeof(__long) - 1)/sizeof(value_type) > 2 ?
(sizeof(__long) - 1)/sizeof(value_type) : 2};
struct __short
{
union
{
unsigned char __size_;
value_type __lx;
};
value_type __data_[__min_cap];
};
#endif // _LIBCPP_ABI_ALTERNATE_STRING_LAYOUT
union __ulx{__long __lx; __short __lxx;};
enum {__n_words = sizeof(__ulx) / sizeof(size_type)};
struct __raw
{
size_type __words[__n_words];
};
struct __rep
{
union
{
__long __l;
__short __s;
__raw __r;
};
};
__compressed_pair<__rep, allocator_type> __r_;
조건부 컴파일 때문에 소스코드를 보기 힘든데 조건부 컴파일을 지우면 대략 이런 느낌이다.
template<class _CharT, class _Traits, class _Allocator>
class _LIBCPP_TEMPLATE_VIS basic_string
: private __basic_string_common<true>
{
public:
...
private:
struct __long
{
pointer __data_;
size_type __size_;
size_type __cap_;
};
static const size_type __short_mask = 0x80;
static const size_type __long_mask = ~(size_type(~0) >> 1);
enum {__min_cap = (sizeof(__long) - 1)/sizeof(value_type) > 2 ?
(sizeof(__long) - 1)/sizeof(value_type) : 2};
struct __short
{
value_type __data_[__min_cap];
struct
: __padding<value_type>
{
unsigned char __size_;
};
};
union __ulx{__long __lx; __short __lxx;};
enum {__n_words = sizeof(__ulx) / sizeof(size_type)};
struct __raw
{
size_type __words[__n_words];
};
struct __rep
{
union
{
__long __l;
__short __s;
__raw __r;
};
};
__compressed_pair<__rep, allocator_type> __r_;
해당 소스코드를 보면 __long이라는 긴 문자열을 저장할 때는 문자열이 저장된 포인터인 __data, 크기가 저장된 __size_, 캐퍼시티가 저장되는 __cap_으로 총 24바이트로 지정된다.
반대로 짧은 소스코드에선 __short의 __data_에 문자열을 바로 저장하는데 __data_는 동적 배열이 아니므로 문자열이 스택에 저장되게 된다.
이 경우 __long의 sizeof값의 -1을 __min_cap에 저장하는데 이러면 __min_cap은 23이 되고 __short.__data는 char[23] 배열이 된다. (char 형인 경우만 생각합시다.)
이후 __long과 __short의 유니온을 통해 __r_에 실제 문자열을 저장한다.
그래서 컴파일러를 통해 sizeof(string)을 찍어보면 clang에선 24바이트이다.
해당 코드는 https://github.com/llvm-mirror/libcxx/blob/master/include/string#L665-L784에 있다.
해당 SSO의 우수성
libc++의 string 구현은 외국 블로그 글에 많이 올라오고 분석 글이 많았다.
나는 이 이유가 SSO의 효율성 덕분이라고 생각한다.
이녀석은 24바이트로 위의 libstdc++의 구현보다 작음에도 23바이트 크기의 스택에 저장되는 짧은 문자열을 지원한다.
실제로 보면 libstdc++는 문자열 32바이트에 SSO 최대 15바이트였으니 libc++의 문자열 24바이트에 SSO 23바이틍이면 사실상 메모리 효율이 압도적이라고 생각된다.
rust, llvm기반 현대적 프로그래밍 언어
rust는 요즘 뜨고있는 시스템 프로그래밍에 적합한 컴파일 기반 언어이다.
실험에 사용된 버전은 1.57.0이다.
실제 구현
이 녀석은 clang과 동일하게 llvm기반의 프로젝트인데 string의 구현도 clang과 거의 유사하다.
구체적인 코드는 다음과 같다.
pub struct String {
vec: Vec<u8>,
}원본 코드 https://doc.rust-lang.org/stable/src/alloc/string.rs.html#294-296
여기서 String은 Vec<u8>의 별칭이나 다름이 없으니 Vec<u8>을 살펴보자.
pub struct Vec<T, #[unstable(feature = "allocator_api", issue = "32838")] A: Allocator = Global> {
buf: RawVec<T, A>,
len: usize,
}원본 코드 https://doc.rust-lang.org/src/alloc/vec/mod.rs.html#400-403
여기서도 RawVec은 여전히 덜 분해되었으니 더 따라가 보자.
#[allow(missing_debug_implementations)]
pub(crate) struct RawVec<T, A: Allocator = Global> {
ptr: Unique<T>,
cap: usize,
alloc: A,
}원본 코드 https://doc.rust-lang.org/beta/src/alloc/raw_vec.rs.html#52-56
이제 소스코드를 보기 좋게 만들면 대략 이런 느낌이다.
struct String{
vec : struct{
buf : struct{
ptr : Unique<char>,
cap : usize,
alloc : A,
}
len : usize,
}
}이를 보면 libc++와 거의 유사한데 alloc이란 필드만 추가되었다.
이때RawVec을 참조하면 alloc은 A 타입이고 A는 제네릭으로 Allocator트레이트이면서 기본적으로는 Global 구조체이다.
여기서 Global은 소스코드를 보면 크기가 0인 구조체이다.
#[unstable(feature = "allocator_api", issue = "32838")]
#[derive(Copy, Clone, Default, Debug)]
#[cfg(not(test))]
pub struct Global;따라서 해당 구조체를 평평하게 하면 대략 이런 느낌이다.
struct String{
ptr : Unique<char>,
cap : usize,
alloc : Global,
len : usize,
}여기서 Global은 크기가 0인데 Global은 해당 값이 힙에 저장될 때 사용한다고 알고 있다.
그리고 힙은 당연히 하나이므로 특별히 지정해 줄 필요가 없어 구조체가 0인걸로 알고 있다.
여기는 확실치 않다. 어디서 본거 같은데 기억이 잘 안난다.
따라서 rust는 크기가 24바이트이며 포인터, 캐퍼시티, 길이 3개의 요소로 구성된 스트럭트로 문자열을 저장한다.
이를 보면 libc++와 유사하지만 안타깝게도 캐퍼시티와 길이 위치가 서로 반대라서 장난치기에는 불편해 보인다.
rust는 sso가 적용되지는 않았다고 한다.
이유는 다양하겠지만 rust 포럼의 글을 몇개 읽어 본 결과로는 rust의 String 타입은 Vec을 이용해 구성되었는데 Vec이 이러한 sso를 위한 최적화가 존재하지 않는다고 한다.
다만 러스트의 유저 커뮤니티에서는 smallvec같은 SSO 관련하여 관심이 많은 듯 하고, 아마 러스트의 사용 목적과 유저 성향을 고려하면 언젠가 SSO를 위한 최적화가 등장할 확률은 높다고 생각된다.
&str 타입은 굳이 말하자면 c++의 char*에 가까운 개념이니 때려치자
Go, 현대적인 프로그래밍 언어.
Go는 구글에서 제작한 프로그래밍 언어로 요즘 쫌 뜨고 있는 것 같다. (내 두탑 최애 언어라 기분이 좋다. 나머지 하나는 rust)
실험에 사용된 버전은 1.17.5이다.
사실 go에서는 string을 원시타입 취급이라 따로 정의된 부분이 없다.(정의는 있지만 직접적이지는 않았다.)
그래서 처음으로 string을 추론한 방법은 reflect.StringHeader를 이용하는 것이다.
해당 구조체는 아래 코드와 같다.
type StringHeader struct {
Data uintptr
Len int
}소스 코드는 여기에. https://cs.opensource.google/go/go/+/master:src/reflect/value.go;l=2588-2591
해당 구조체는 go 실제 구현은 아니여서 정확하지 않지만 go string은 uintptr형의 Data 필드와 int인 Len이 있음을 예상은 가능했다.
다만 여기서 만족할 순 없지. 더 자세히 소스코드를 읽어보고 go의 언어설계에 해당하는 runtime을 찾아보며 실제 구현에 대해 더 자세히 읽어 보았다.
그래서 찾은 과정은 다음과 같다. 우선 우연히 rawstring이라는 새로운 문자열 구조체를 만드는 생성자를 찾았다.
func rawstring(size int) (s string, b []byte) {
p := mallocgc(uintptr(size), nil, false)
stringStructOf(&s).str = p
stringStructOf(&s).len = size
*(*slice)(unsafe.Pointer(&b)) = slice{p, size, size}
return
}해당 코드는 여기에 https://cs.opensource.google/go/go/+/master:src/runtime/string.go;l=268-281;drc=master;bpv=0;bpt=1
여기서 mallocgc는 string을 위한 메모리 공간 할당이고 의심스러운 stringStructOf를 찾아가 보니 이런 녀석을 찾았다.
type stringStruct struct {
str unsafe.Pointer
len int
}
// Variant with *byte pointer type for DWARF debugging.
type stringStructDWARF struct {
str *byte
len int
}
func stringStructOf(sp *string) *stringStruct {
return (*stringStruct)(unsafe.Pointer(sp))
}코드는 여기 https://cs.opensource.google/go/go/+/master:src/runtime/string.go;l=249-251;drc=master;bpv=0;bpt=1
이렇게 stringStruct 또한 reflect.StringHeader와 동일하게 16 바이트 크기임을 알 수 있었다.
여기 역시도 SSO는 없다고 한다.
다만 rust와는 다르게 go는 지향점이 SSO 같은 최적화 기능을 추가할 것 같지는 않다는 생각이 들었다.
우연히 SSO라는 것을 듣고 난 뒤, 우리는 매일 string 타입을 쓰지만 정작 해당 타입이 어떻게 이루어졌는지는 몰랐다는 사실을 깨닫고 열심히 공부했다.
사실 스트링이 바이트 배열이라고 생각했던 때도 있었으니, 내 무지에 상당히 부끄러움을 느껴 더 노력해서 조사했던 것 같다.
언제나 당연하다고 생각한 부분이야 말로 내가 잘 모르는 것이라는 걸 오늘 뼈저리게 깨달았다.
참고로 해당글을 보고 오늘 조사를 결심했다.
해당 글은 libc++의 string sso에 대한 분석글로 상당히 잘 쓰여졌다고 생각한다.
시간이 된다면 읽어보시는 게 좋을 것 같다.
다만 해당 글에서 내가 이해하는 바로는 해당 글의 이 부분은 좀 의아했다.
size_t size() {
if (__size_ & 1u == 0) { // Short string mode.
return __size_ >> 1;
}
// <Handle long string mode.>
}해당 글에서는 리틀 엔디안이라고 했는데 내가 조사한 소스코드에서는
// 이 부분하고
#ifdef _LIBCPP_BIG_ENDIAN
static const size_type __short_mask = 0x01;
static const size_type __long_mask = 0x1ul;
#else // _LIBCPP_BIG_ENDIAN
static const size_type __short_mask = 0x80;
static const size_type __long_mask = ~(size_type(~0) >> 1);
#endif // _LIBCPP_BIG_ENDIAN
_LIBCPP_INLINE_VISIBILITY size_type size() const _NOEXCEPT
{return __is_long() ? __get_long_size() : __get_short_size();}
// 이 부분
bool __is_long() const _NOEXCEPT
{return bool(__r_.first().__s.__size_ & __short_mask);}이런 부분이 있었다.
글은 리틀 엔디안일 때 기준이라 하니 __short_mask가 0x80인데 그러면 저 코드의 조건문이 __size_ & 0x80 != 0이여야 하는게 아닌가 싶다.
혹시 이부분을 잘 아시는 분이 계시다면 댓글로 내가 이해한 바가 맞는지 틀린지 올려주시면 감사합니다.
