1. Application Log 모니터링
- 지정한 Pod 내의 특정 컨테이너 애플리케이션 로그 확인
$ kubectl logs PODNAME -c CONTAINER_NAME※ 문제1: Application Log 추출하기
-
작업 클러스터 : hk8s
-
Pod custom-app의 로그 모니터링 후 'file not found' 오류가 있는 로그 라인 추출(Extract)해서 /var/CKA2022/CUSTOM-LOG001 파일에 저장하시오.
- 작업 클러스터 확인
$ kubectl config use-context hk8s- 이름이 custom-app인 pod의 로그 중 'file not found' 오류가 있는 로그 라인을 /var/CKA2022/CUSTOM-LOG001 파일에 저장
$ kubectl logs custom-app | grep -i 'file not found' > /var/CKA2022/CUSTOM-LOG001- 파일이 잘 저장되었는지 확인
$ cat /var/CKA2022/CUSTOM-LOG0012. 클러스터 리소스 모니터링
- Pod가 사용하는 CPU나 Memory 리소스 정보 보기
$ kubectl top pods --sort-by=cpu- Node가 사용하는 CPU나 Memory 리소스 정보 보기
$ kubectl top nodes --sort-by=cpu- Json 포맷을 기준으로 특정 리소스 sort해서 보기
$ kubectl get pod -o json
# json 형태 안에서 특정 리소스 sort해서 보기(Pod)
$ kubectl get pods --sort-by=.metadata.name
# json 형태 안에서 특정 리소스 sort해서 보기(Persistent Volume)
$ kubectl get pv --sort-by=.spec.capacity.storage※ 문제2: Persistent Volume 정보 보기
-
작업 클러스터 : hk8s
-
클러스터에 구성된 모든 PV를 capacity 별로 sort하여 /var/CKA2022/my-pv-list 파일에 저장하시오.
-
PV 출력 결과를 sort하기 위해 kubectl 명령만 사용하고, 그 외 리눅스 명령은 적용하지 마시오.
- 작업 클러스터 확인

- 클러스터에 구성된 모든 PV 조회(capacity 확인)
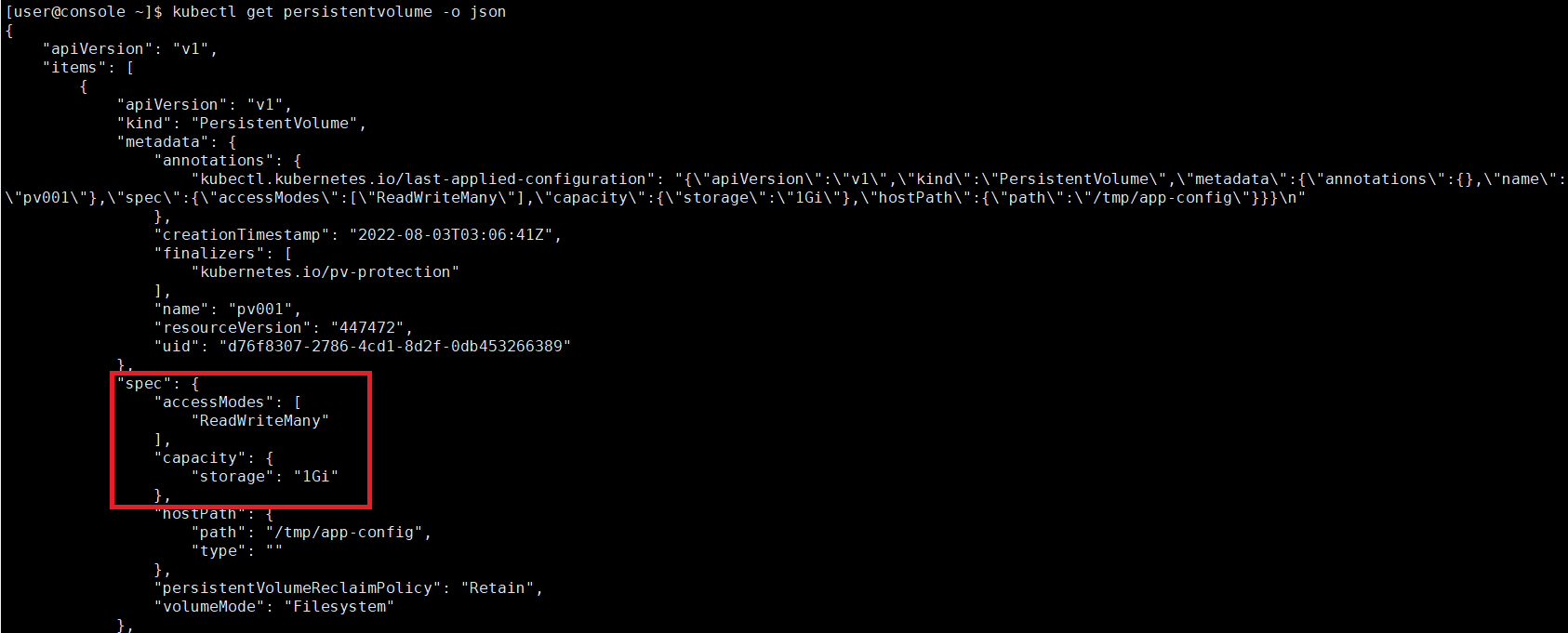
- 클러스터에 구성된 모든 PV를 capacity 별로 sort하여 확인

- 클러스터에 구성된 모든 PV를 capacity 별로 sort한 부분 /var/CKA2022/my-pv-list 파일에 저장 및 결과 확인

문제3: 클러스터 리소스 정보 보기
(참고 URL : https://kubernetes.io/docs/reference/kubectl/cheatsheet/)
-
작업 클러스터 : hk8s
-
'name=overloaded-cpu' 레이블을 사용하는 Pod들 중 CPU 소비율이 가장 높은 Pod의 이름을
찾아서 /var/CKA2022/custom-app-log에 기록하시오.
- 작업 클러스터 확인
$ kubectl config use-context hk8s- 'name=overloaded-cpu' 레이블을 사용하는 Pod들 조회
$ kubectl get pods -o wide --show-labels --all-namespaces | grep -i name=overloaded-cpu
- 레이블 이름이 'overloaded-cpu'인 pod들 CPU 소비율 조회
$ kubectl top pods --sort-by=cpu | grep -e '<레이블 이름이 overloaded-cpu인 pod들>'- 레이블 이름이 'overloaded-cpu' 중 CPU 소비율이 가장 높은 해당 pod를 /var/CKA2022/custom-app-log에 저장
$ echo '<CPU 소비율이 가장 높은 해당 pod>' > /var/CKA2022/custom-app-log- /var/CKA2022/custom-app-log 결과 확인
$ cat /var/CKA2022/custom-app-log3. Installing runtime
Worker node 동작 확인 순서
① Container engine 확인
- Runtime : Path to Unix domain socket
- Docker Engine : /var/run/dockershim.sock
- containerd : /run/containerd/containerd.sock
- CRI-O : /var/run/crio/crio.sock
② kubelet, kubeproxy 확인
- kubelet
- kubeproxy
③ Container Network Interface 확인
- cni
※ 문제4 : Worker Node 동작 문제 해결
-
작업 클러스터 : hk8s
-
hk8s-w2라는 이름의 worker node가 현재 NotReady 상태에 있습니다. 이 상태의 원인을
조사하고 hk8s-w2 노드를 Ready 상태로 전환하여 영구적으로 유지되도록 운영하시오.
- 작업 클러스터 확인

- hk8s 클러스터 node 확인(hk8s-w2 노드 상태가 NotReady인 것 확인)

- hk8s-w2 노드 상태를 보기 위해 hk8s-w2 노드에 접속 후 root 사용자로 변경
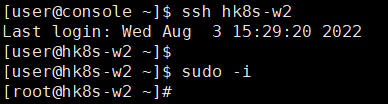
- docker 상태 확인(이상 없음)
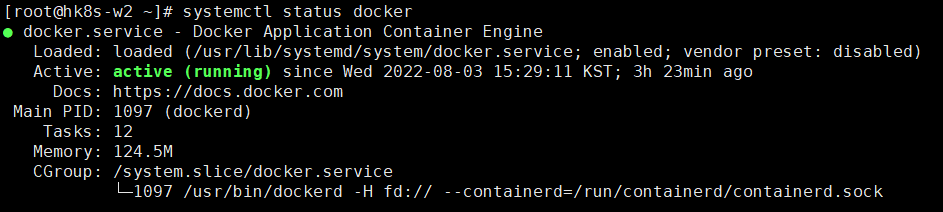
- kubelet 상태 확인(inactive 상태)

- kubelet 상태를 enable로 변경
📌 docker 상태가 inactive 상태여도 같은 방법으로 실행

- 다시 kubelet 상태 확인(active 상태로 변경 된 상태)
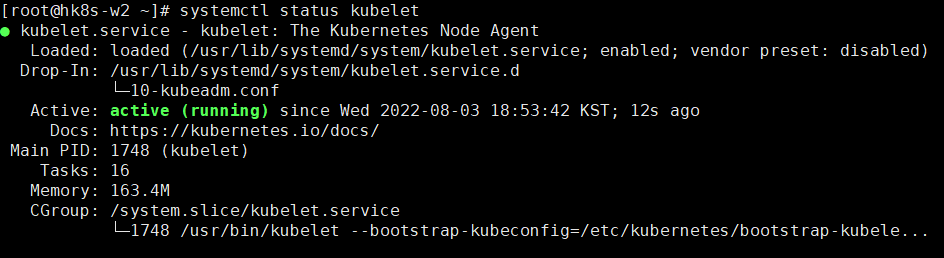
- console로 이동해 node 상태 확인(hk8s-w2 node의 상태가 Ready로 변경)


나만의 데이터베이스