SORT/MERGE JOIN의 사용
- 연결 고리에 인덱스가 전혀 없는 경우
- 대용량의 자료를 조인해야 함으로써 인덱스 사용에 따른 랜덤 액세스의 오버헤드가 많은 경우
- SORT/MERGE JOIN은 DRIVING 테이블이 없다.
SORT/MERGE JOIN은 어떻게 데이터를 읽을까?

- 튜닝 포인트
- 각 테이블로부터 데이터를 빨리 읽어 들이도록 함. (읽어들인 데이터 각각에 대해서 SORTING이 완료되지 않는 한 JOIN을 하지 못한다.)- 메모리(SORT_AREA_SIZE)를 최적화함.
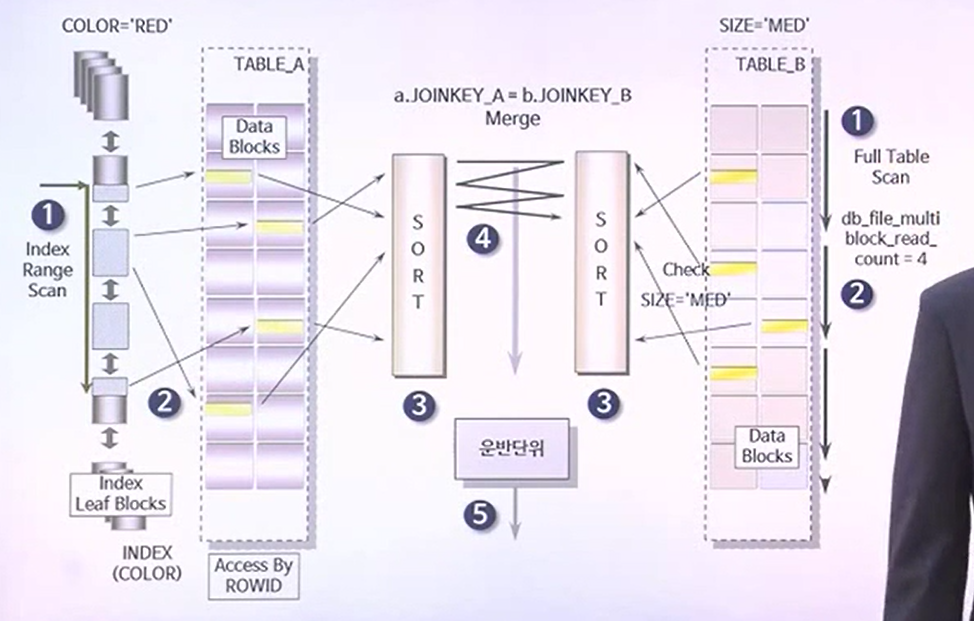
SORT/MERGE JOIN의 수행 절차

- SELECT 다음에 주어진 힌트롤 보면 USE_MERGE라고 되어있다. 즉, JOIN하고자 하는 테이블간의 JOIN방식을 SORT MERGE로 하겠다는 의미이다.
- A는 A에대로 B는 B대로 데이터를 읽어들이는 것이 첫번째 작업이다.
- A에서 읽어들인 데이터는 joinkey_a에 대해서 sorting을 진행하고, b에서 읽은 데이터는 joinkey_b를 기준으로 sorting을 진행한다.
- a, b 둘다 sorting이 완료되지 않는 한, 결코 join을 하지 않는다.
- sorting이 완료되면 =로 조인을 맺는다.
SORT/MERGE JOIN이 불리한 경우
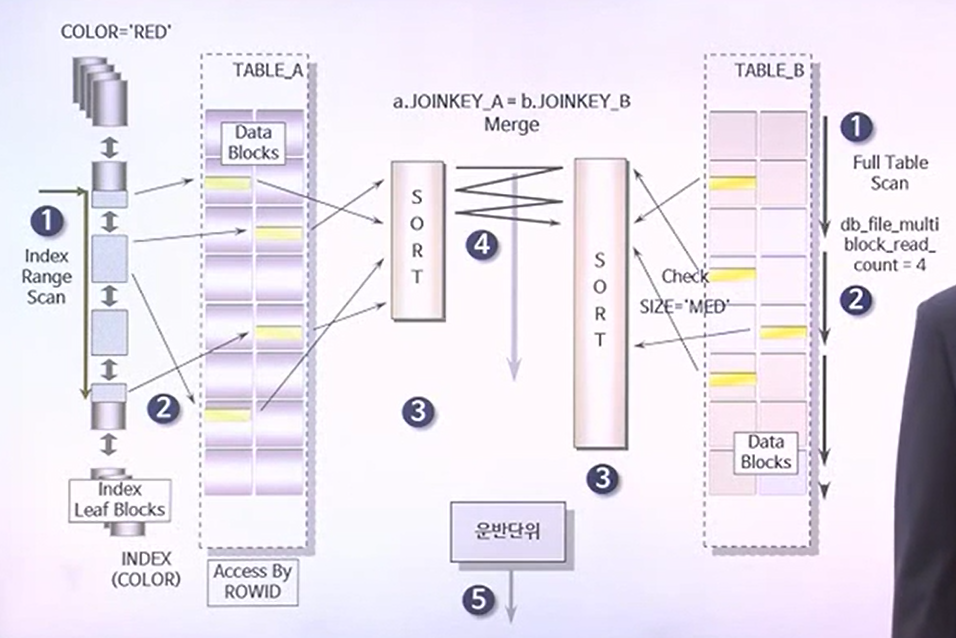
- 테이블 A에서 읽은 SORTING의 데이터 양보다 B에서 읽어들인 데이터 SORTING의 양이 그림 상 큰 차이를 보이며 이와 같은 상태를 비대칭 상태라고 칭한다.
- 데이터 SORTING이 작은 테이블이 먼저 끝이난다. 하지만 SORTING이 먼저 끝났다고 해서 JOIN을 진행하는 것은 아니다. 큰 데이터의 대한 SORTING이 완료되기 전까지는 WATING 상태이다.
- 이와 같은 경우에는 SORT/MERGE JOIN이 성능상 불리한 상태이다.
SORT/MERGE JOIN의 장단점
-연결고리에 인덱스가 생성되어 있지 않은 경우에 빠른 조인을 위하여 사용됨.
- 조인하고자 하는 테이블에 대해서 독립적으로 데이터를 읽어 들일 때, 이를 얼마나 빠르게 할 것인가가 중요함
- 각 테이블로부터 읽혀진 데이터를 연결고리에 대해 정렬을 수행할 때 이를 얼마나 빠르게 할 것인가가 중요함.
- 데이터가 많은 테이블일 경우 full table scan에 읽어들일 block수를 증가시키는것도 중요한 방법중의 하나!
HASH JOIN
- SORT/MERGE 조인과 비교해 보면, 각 테이블에 대한 처리를 독립적으로 하는 것은 같지만 HASH JOIN에서는 Driving Table이 있음 -> Driving을 결정해서 Driving만 먼저 읽는다라고 볼 수 있다. 그 때 읽어 들인 각 테이블의 데이터를 서로 조인하기 위해 해싱(hashing)을 이용해서 해시값을 만듦 -> 해시 값으로 조인을 수행함 (먼저 읽어들인 테이블에서 행하는 작업)
튜닝 포인트
- Driving table을 결정함.
- 각 테이블로부터 데이터를 읽어 들일 때, 빨리 읽을 수 있도록 함.
- 메모리(HASH_AREA_SIZE)를 최적화함.
-> HASH_AREA_SIZE가 넉넉한 경우에는 오히려 큰 데이터르 읽을 수 있는 테이블을 먼저 읽어들일 수 있도록 한다. - 특별히 이 HASH JOIN은 이 JOIN만을 위해서 메모리가 사용되도록 되어있다. 그 메모리는 HASH_AREA_SIZE라는 파라미터를 통해 그 크기가 정해져 있다. SORT_AREA_SIZE보다 2배로 설정되는 것이 기본 값이다.
HASH JOIN의 수행 절차
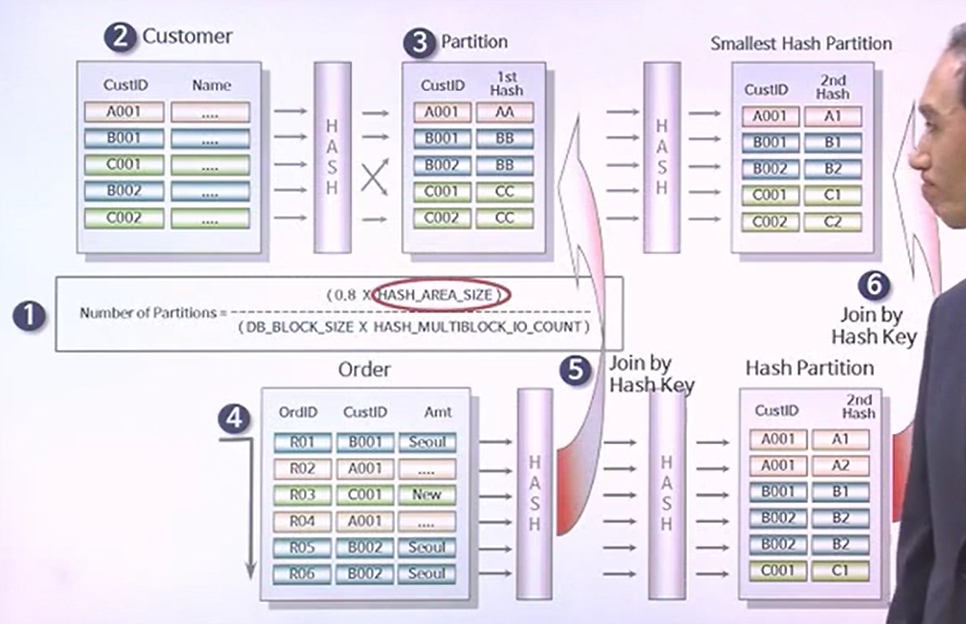
- CUSTOMER, ORDER라는 테이블이 있다. 고객이 주문을 했다라고 볼 때, 고객정보테이블과 주문내역 테이블을 HASH JOIN을 해서 사용하고있다라고 가정.
- CUSTOMER 테이블이 ORDER라는 테이블보다 상대적으로 데이터 수가 적다라고 볼 수 있다.
- 두 테이블의 연결조건은 CUSTID이다.
- 5번을 진행할 때, 과연 조인할 데이터가 있는지, 아니면 JOIN하고자 하는 HASH값 안에 충돌이 있는지 확인하게 된다.
- 5->3으로 가는 것을 보면 컬럼 값은 서로 다르지만 HASH VALUE가 충돌이 나 있는 상태이다. -> 이러면, 오히려 읽지 말아야 할 데이터를 읽는 경우가 있다.
- 따라서 그림의 의미상, 각 컬럼간 서로 다른 HASH VALUE를 만들기 위해 2차 HASHING을 만들게 되었다라는 의미이다. -> 그만큼 넉넉한 메모리를 요구한다라고 볼 수 있다.
HASH JOIN의 장단점
- HASH BUCKEDT이 조인 집합에 구성되어 해시 함수 결과를 저장해야 하는데 이러한 처리에는 많은 메모리와 CPU 자원을 소모하게 된다. (장점이자 단점)
- 기본적으로 HASH_AREA_SIZE에는 지정된 크기만큼의 메모리가 할당되어 사용된다.
- 조인을 수행하기에 메모리가 부족하다면 가장 큰 순서대로 Hash Bucket이 Temporary Tablespace로 내려가서 구성됨
-> 디스크로 내려간 Hash Bucket에 변경이 일어날 때마다 디스크 I/O가 발생하게 되어 성능이 현저하게 저하된다.
하드웨어 자원이 넉넉한 상황에서는 다른 조인에 비해 보다 효율적인 수행이 가능하지만, 부족한 상황에서는 다른 조인 방법보다 오히려 느려질 수도 있다.
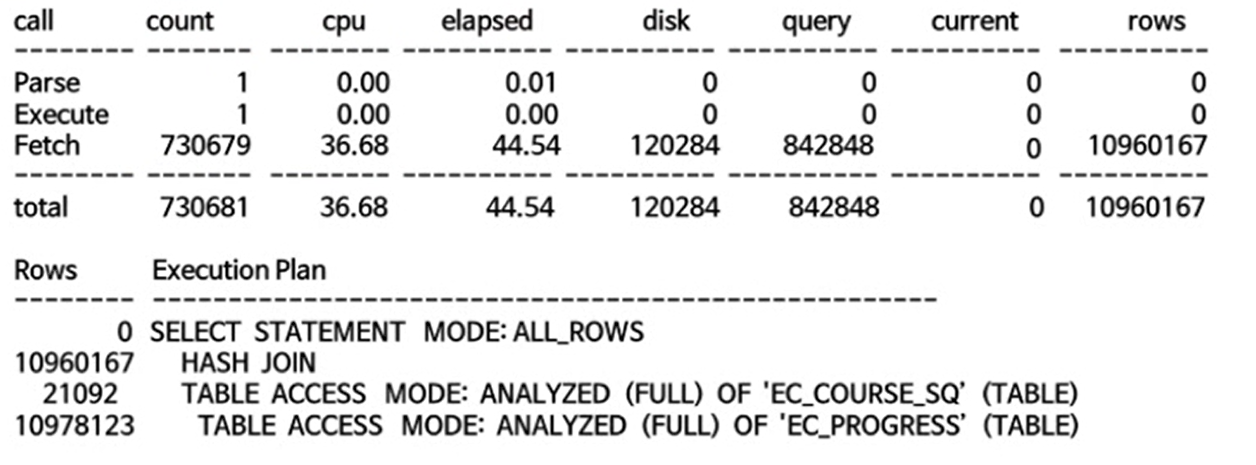
제시문
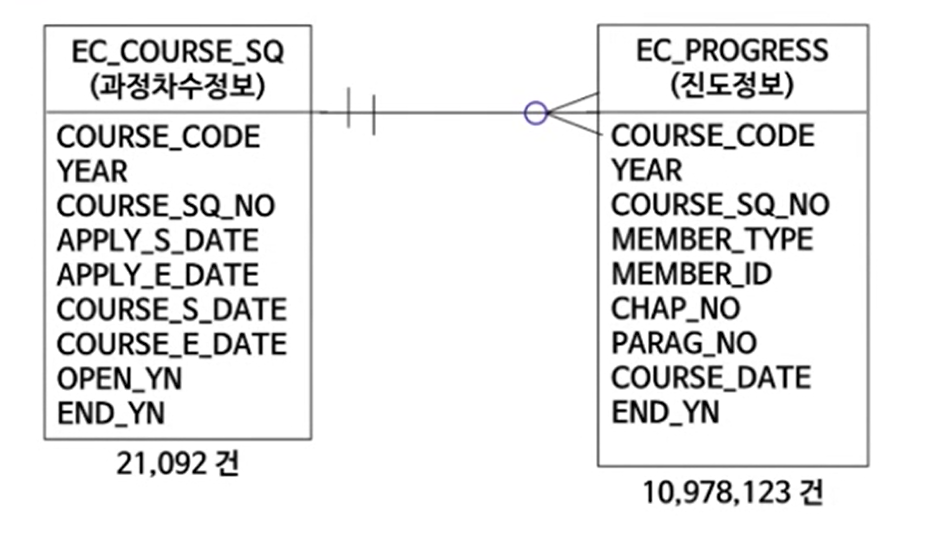
-테이블 간의 관계를 보면 1:N관계이다.

- 이 두테이블을 sort merge하고있다.
- 이 두테이블은 데이터 양의 차이가 심하기 때문에 조인 방식을 바꿔야한다.
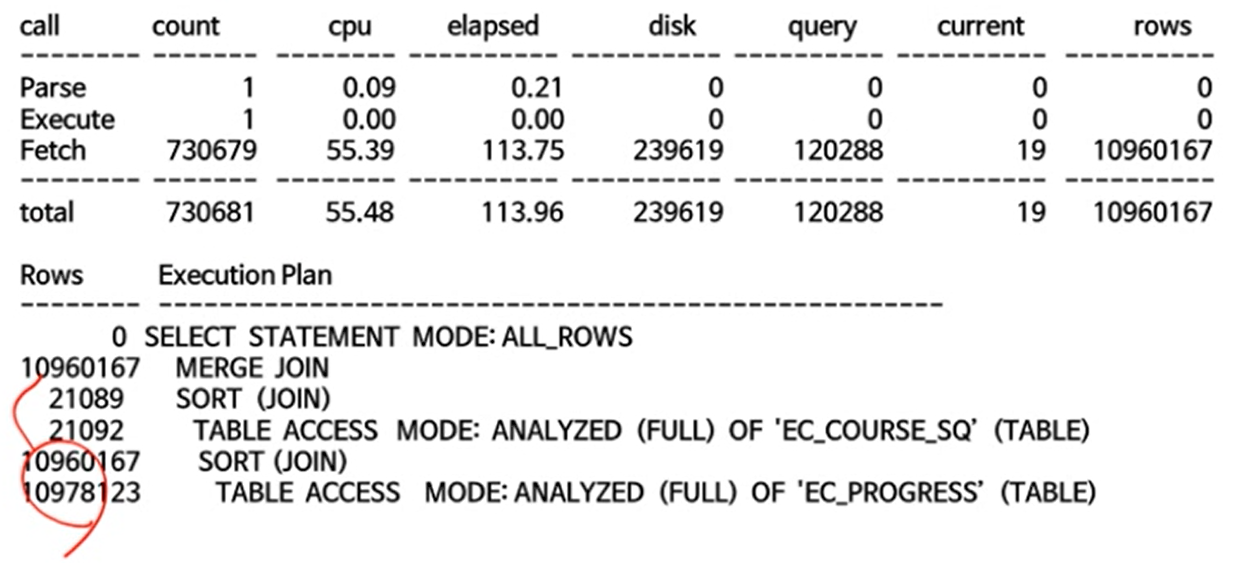
- 해당 쿼리는 비대칭 상태이다.
수정문

튜닝결과