SUBQUERY의 종류
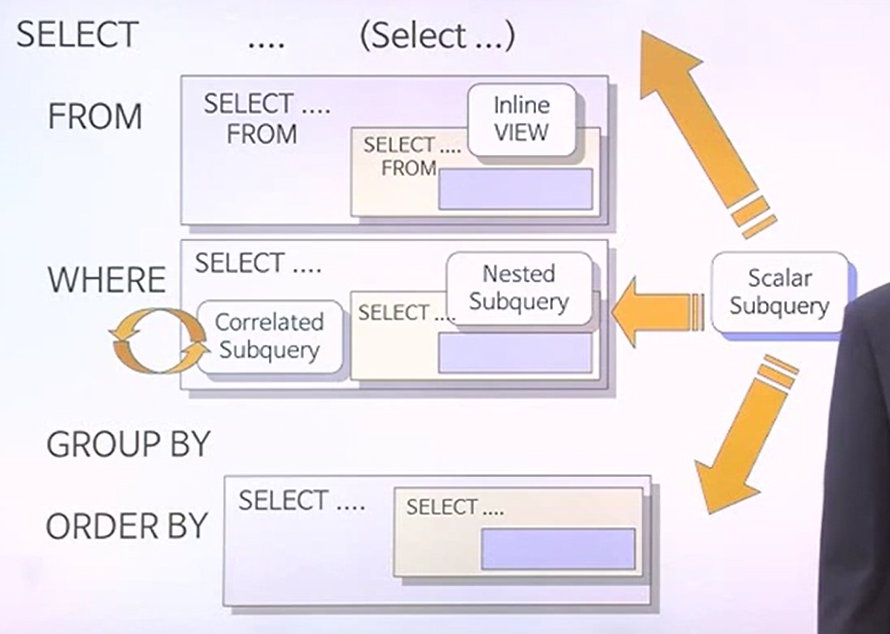
- SELECT문에 대해서 문법적으로 나타낸 사진이다.
- GROUP BY에는 서브쿼리가 위치할 수 없다.
- WHERE절에는 Nested subquery, Correlated Subquery 등이 있다.
- FROM절에는 INLINE VIEW가 있다.
- 위와 같은 것들을 서브쿼리라고 할 수 있다.
NESTED SUBQUERY
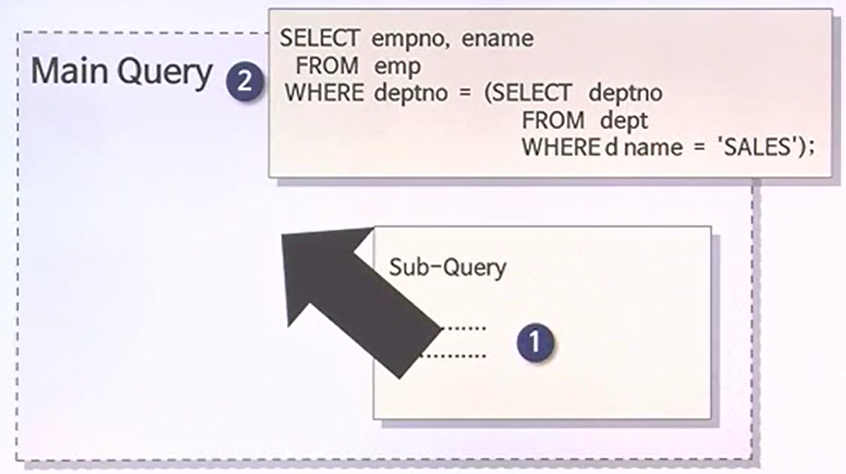
- MAIN쿼리보다 먼저 실행될 때 속도를 낼 수 있는 유형이다.
- 서브쿼리가 먼저 동작하기 위해서는 전제조건이 있다. 서브쿼리가 먼저 데이터를 읽었다고 가정을 할 때, SALES라는 부서를 읽어들였을 것이다. 그 앞에 MAIN쿼리 테이블에도 부서번호가 존재한다. 부서번호에 인덱스가 존재하여야 한다. 그리고 그 해당 인덱스를 사용할 수록 하는 차원에서 조건이 주어져 있을 때, NESTED SUBQUERY는 먼저 동작을 한다.
- 단, 메인쿼리 상에서 부서번호에 대한 인덱스가 없다거나, 또는 인덱스는 있지만 서브쿼리에서 읽은 결과와 비교를 할 때 사용되는 연산자가 메인쿼리에 존재하는 부서번호에 있는 인덱스를 사용할 수 없는 연산자가 있다면 서브쿼리는 먼저 실행될 수 없다.
실행계획

- 다음과 같은 실행계획은 서브쿼리가 먼저 동작되었을 때 결과를 나타내고 있는 것이다.
CORRELATED SUBQUERY
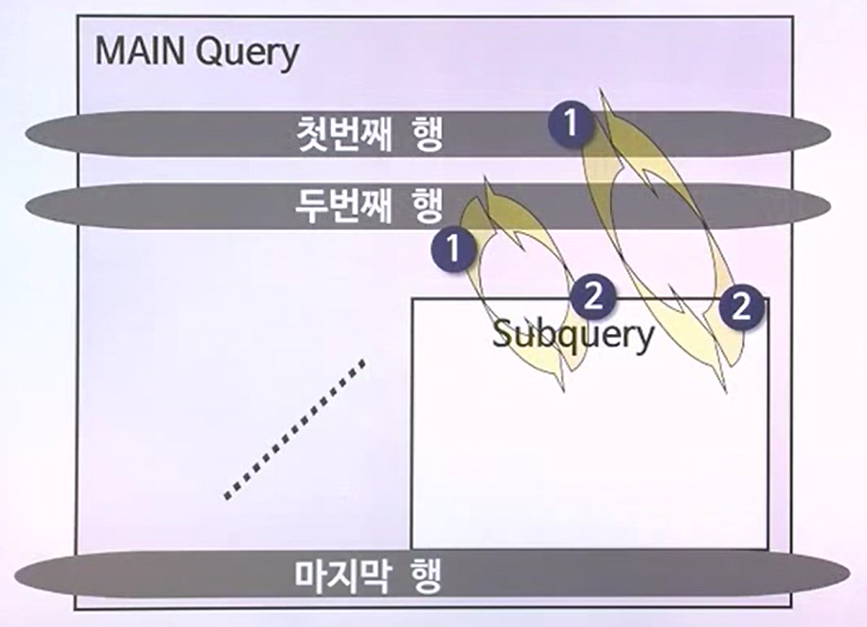
- 반면에, 반드시 메인쿼리가 먼저 동작되는 중에 거기서 읽고있는 데이터 수만큼 서브쿼리가 동작되는 경우가 있다. MAIN보다 나중에 동작되는 서브쿼리가 CORRELATED SUBQUERY이다.
- MAIN에서 하나씩 읽을 때마다 서브쿼리로 알려준다라는 뜻(RETURN)
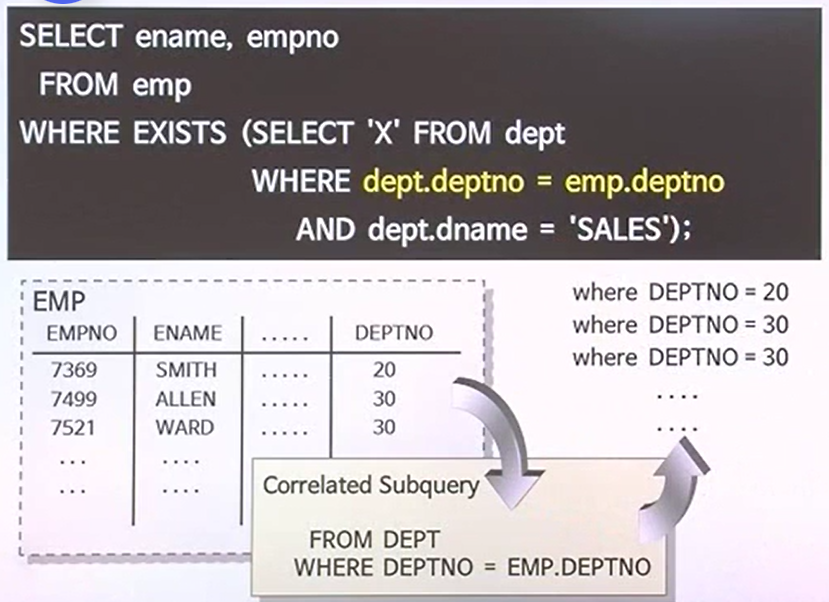
- 부서테이블의 부서번호와 메인쿼리의 테이블의 부서번호를 = 로 연결하고 있다.
- 메인에서 데이터를 먼저 읽고온다.
- 그렇기에 서브쿼리가 먼저 동작할 수 없다.
실행계획
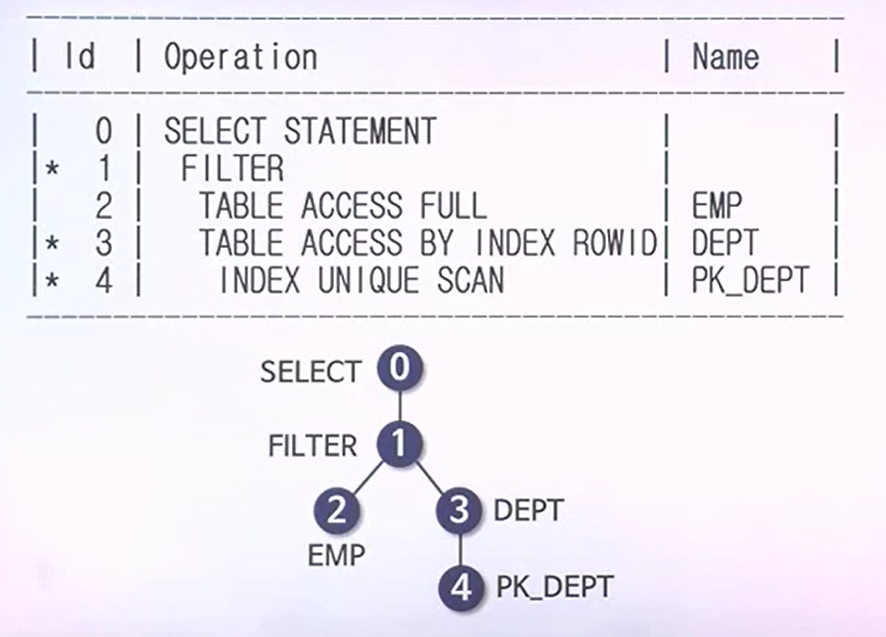
- 2,3번이 같이 들어가있지만 2번이 먼저 들어가 있어서 2번먼저 동작한다.
- 서브쿼리가 나중에 동작한다는 의미가 FILTER이다.
SCALAR SUBQUERY
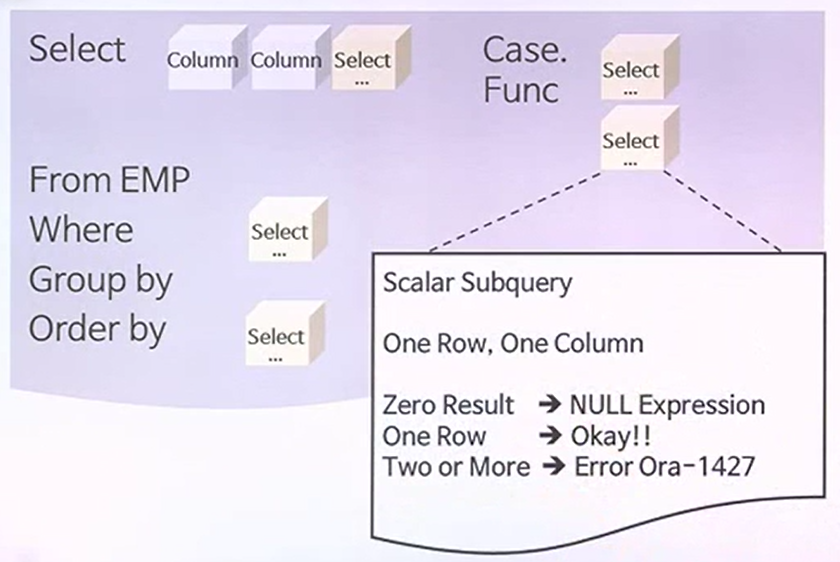
- 스칼라 서브쿼리는 하나의 데이터와 하나의 컬럼에 대한 정보를 return한다는 속성이 있다.
예제1
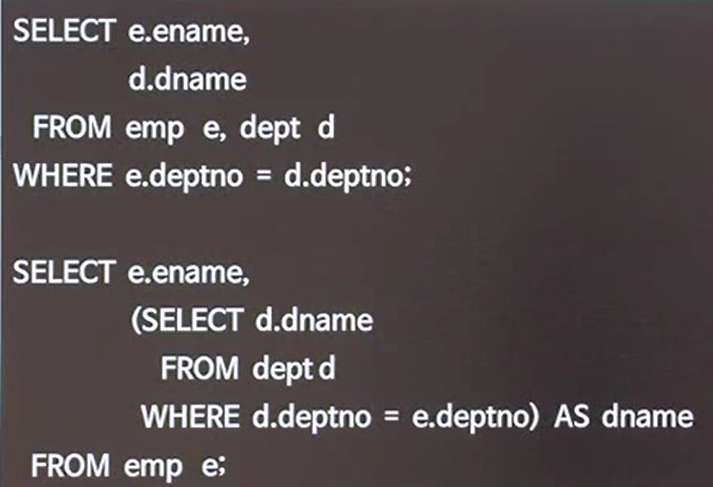
- main에서 읽게 될 데이터 양이 큰 경우에는 서브쿼리 실행횟수가 문제가 될 수 있다는 것을 고려해야 한다. 서브쿼리가 자주 사용된다면 function으로 사용해도 좋다.
예제2 (서브쿼리를 함수로 사용)

- argument를 부서번호로 넣고있다.
- 따라서, main쿼리에서 읽게 될 데이터양이 많은 경우에는 역시 함수사용도 문제가 될 수 있다.
ROLLUP() & CUBE()
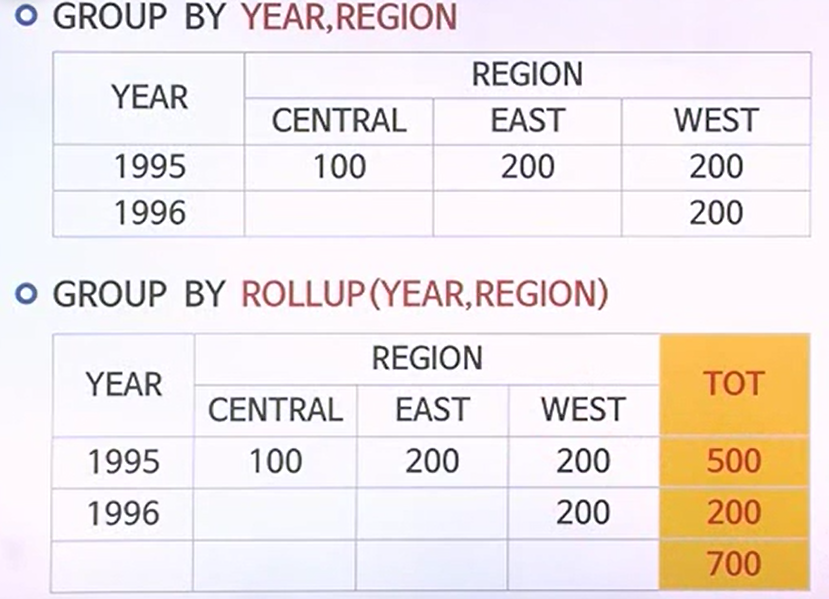
- 함수를 사용하지 않고, 년도의 각 지역별 현황을 집계한다고 본다.
- 그와 같은 출력결과에다가 맨 오른쪽에 위치하는 것처럼 총계항목을 넣고자 한다. 이와 같은 결과를 나타내는 함수가 ROLLUP이다.
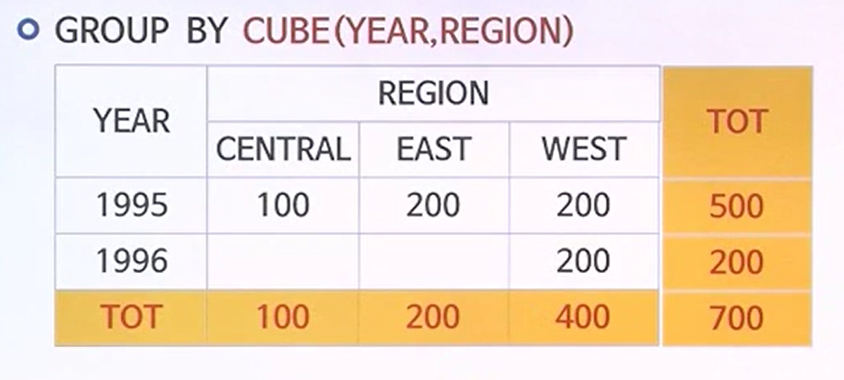
- 각 지역기준에서 소계를 마저 더 넣고자 한다. 그럴려면 CUBE()를 사용한다.
예제

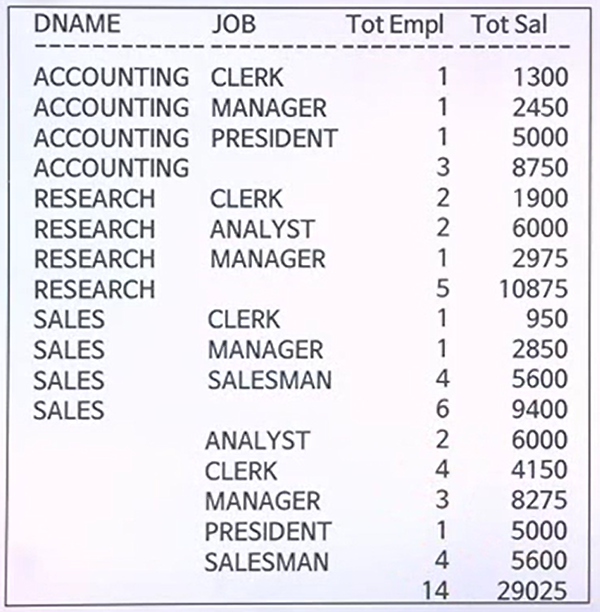
예제 출력결과
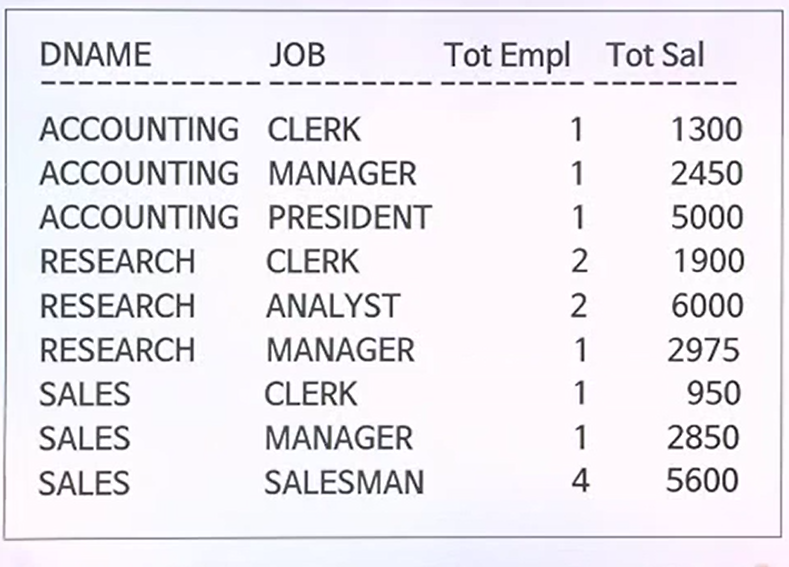
- 이 출력결과에다가 중간중간에 각 부서별 인원에 대한 소계와 급여에 대한 소계와 맨밑에 총인원과 총급여합을 넣고자 한다. 그러면 ROLLUP을 사용한다.
예제 수정문(ROLLUP)

예제 출력결과
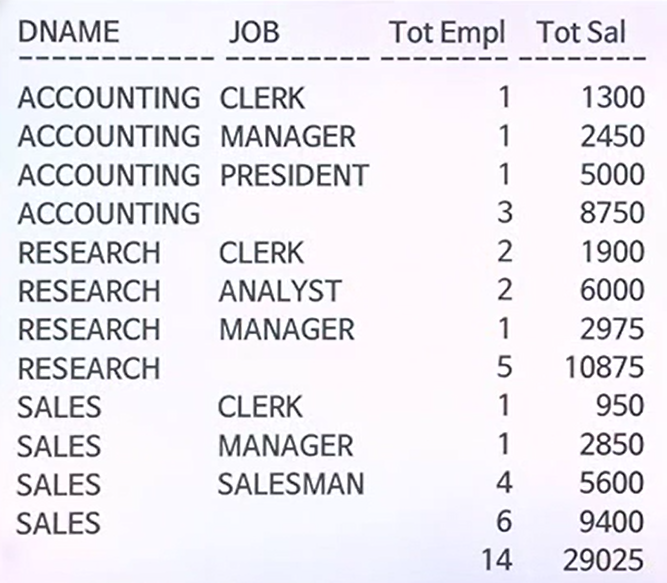
예제 수정문(CUBE)

예제 출력결과
GROUPING SETS()

- 각기다른 GROUP BY 기준상의 컬럼들을 괄호로 나타내고 있다.
- 괄호로 나타낸 컬럼들을 기준에서 각각 인원합과 급여합이 순서대로 출력대로 순서결과에 나타난다.
- ROLLUP으로 나타낸 결과와 일치한다고 볼 수 있다.
- GROUPING SETS로 ROLL UP을 구현했다.

-GROUP BY에다가 e.job 괄호를 추가하면 CUBE와 같은 결과를 출력할 수 있다.
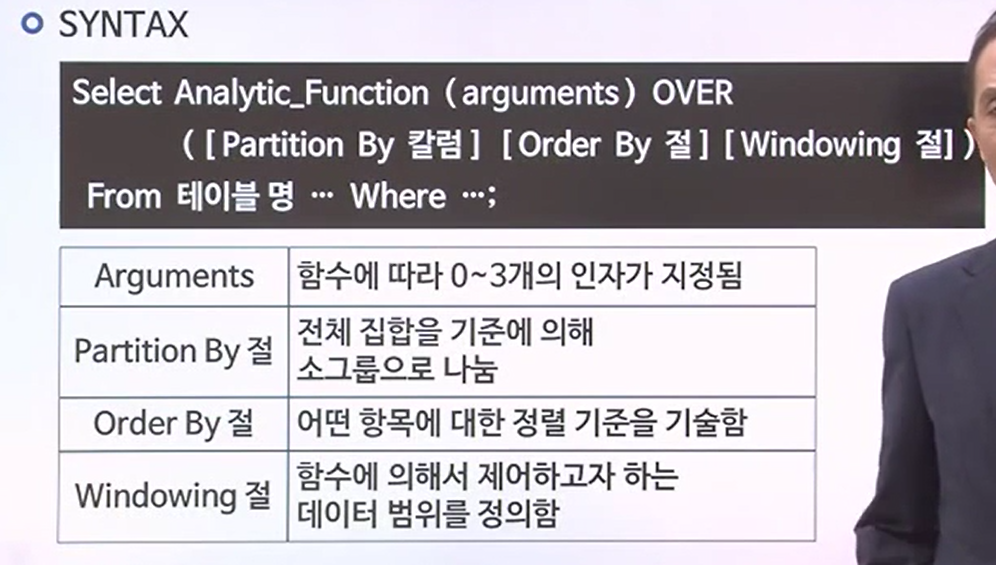
ANALYTICAL FUNCTIONS
- 이 함수는 argument를 갖는데 기본적으로 이 함수를 사용하게 될때 일정부분 우리가 프로그래밍 내에서 구현한 로직을 해소할 수 있다라는 장점을 가지고 있다. 빠른속도를 보장한다.
- 함수 뒤에다가 over를 사용하면서 각각 데이터를 구분하기 위한 partion by구문, 그리고 sorting절을 위한 order by 구문, 데이터 제어 범위를 나타낼 수 있는 windowing 구문 등 키워드를 넣어서 함수 사용할 수 있게 한다.
- 함수에는 argument가 없는것도 있고 3개까지 소유하는 것도 있다.
Windowing 절에 대한 이해
-
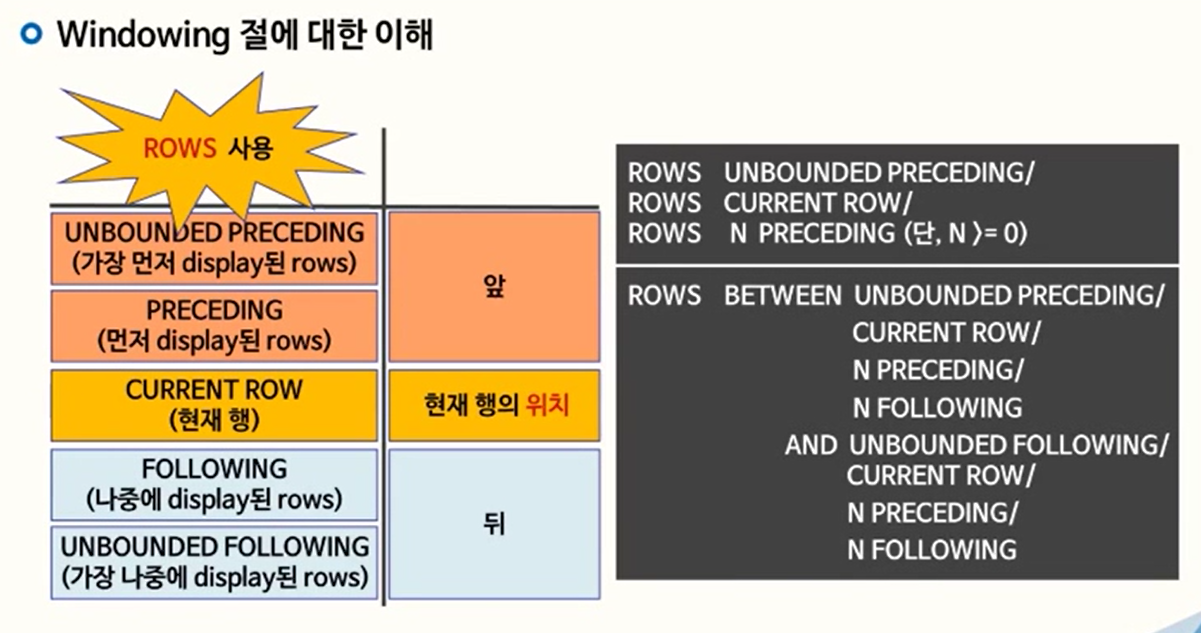
데이터를 읽어들였을 때 컬럼에 값을 갖고서 범위 설정을 하는것이 아니고 현재 데이터의 위치를 갖고서 범위를 선정하려 할 때 ROWS라는 단어를 통해서 그 대상들을 나타낸다.
-
데이터를 가리킴에 있어서 사용할 수 있는 단어는 5개다
<CURRENT ROW, PRECEDING, FOLLOWING, UNBOUNDED PRECEDING, UNBOUNDED FOLLOWING> 이 단어들의 위치는 고정이다. -
EX) ROWS BETWEEN 3번째 앞 AND 5번째 뒤까지라고 가정한다. -> 3 PRECEDING, 5 FOLLOWING
-
ROWS UNBOUNDED PRECEDING/은 가장 먼저 DISPLAY된 ROWS부터 CURRNET ROW 즉, 현재 행까지를 뜻한다.
-
ROWS CURRENT ROW/ 현재행부터 현재행까지를 뜻한다.
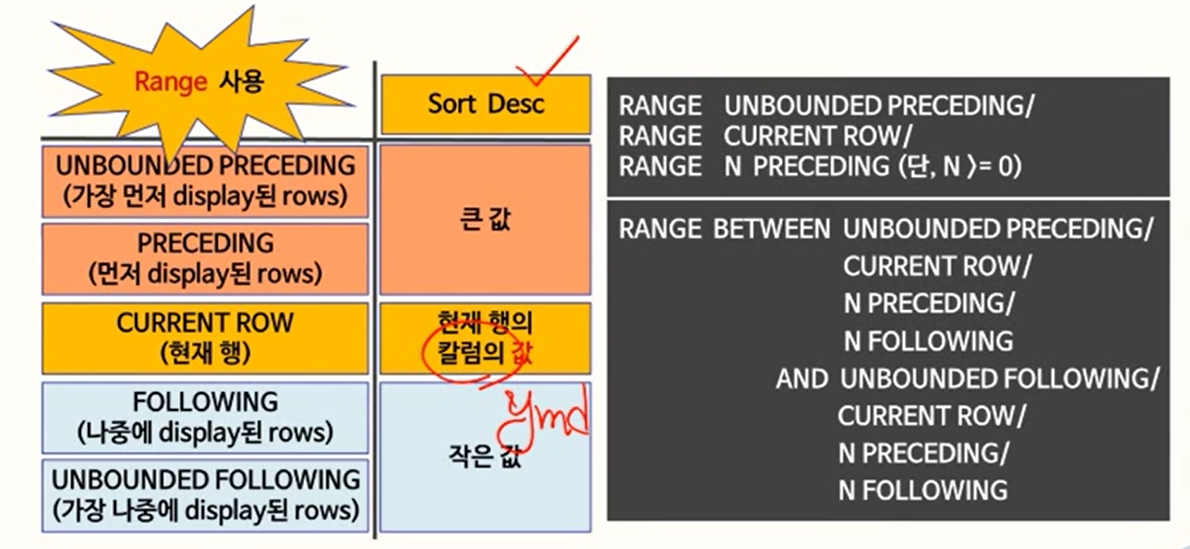
- 요것은 범위
- Range between 2일후 and 3일전이면
Range between 2 preceding and 3 follwoing이 된다.(desc) - Range between 2일후 and 3일전이면
Range between 2 following and 3 preceding이 된다.(asc)
그룹 내 데이터 순위 관련
- EMP 테이블에서 부서(DEPNO) 별로 급여가 높은 사람 순으로 순위를 구하기 위한

- 각각 함수에 대한 결과를 부서별로 구분해서 나타내야 하기에 PARTITION BY 구문이 정해져 있다.
출력되는 결과
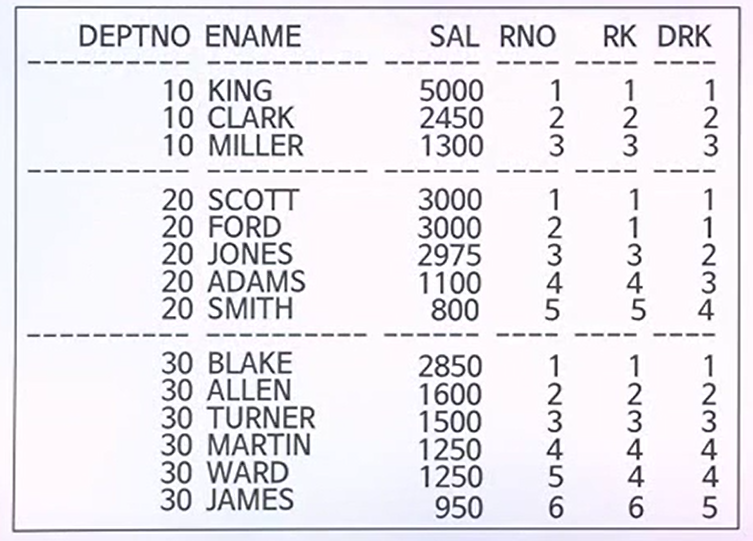
- ROW_NUMBER은 일련번호를 매겨놓고 있다.
- RANK_OVER는 SCOOTT과 FORD를 1로 매기되 그다음순위는 3으로 매긴다.
- DENSE_RANK는 SCOTT과 FORD를 1로 매기되 그다음순위는 2로 매긴다.
일반 그룹 함수 관련
-
EMP 테이블에서 부서 별로 각 사원을 기준으로 해서 급여에 대한 누계를 구하기 위한 SQL

-
각 사원을 기준으로 해서 부서별로 구분해서 구하지만 급여에 대해서 누계를 구하자
-
부서별 근무현황을 그대로 나타내는 중에 SUM이란 함수를 이용해서 누계를 구하고 단, OVER를 붙여서 부서별로 구분하기 위한 차원에서 PARTITION BY 기준을 사용중이고 SORTING기준으로 급여데이터를 넣고 있다.
-
WINDOWING절은 UNBOUNDED PRECDEDING 각부서별로 존재하는 데이터중 맨 위에 데이터부터부터 현재 SUM이 되고있는 데이터까지를 영역으로 하고 있다.
출력결과
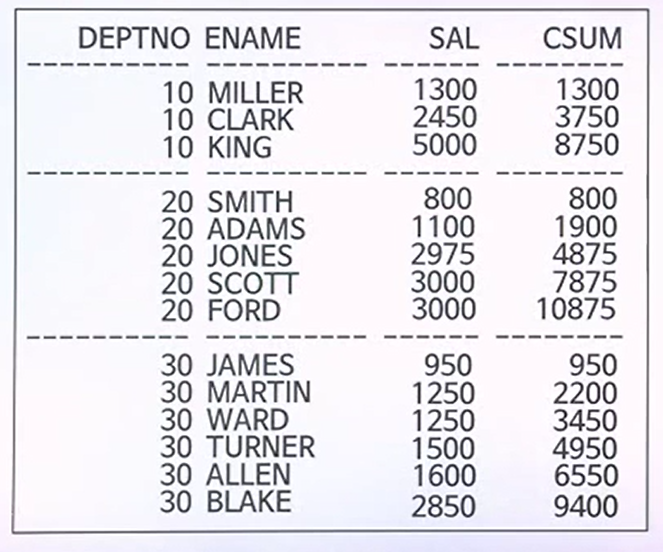
그룹 내 비율관련
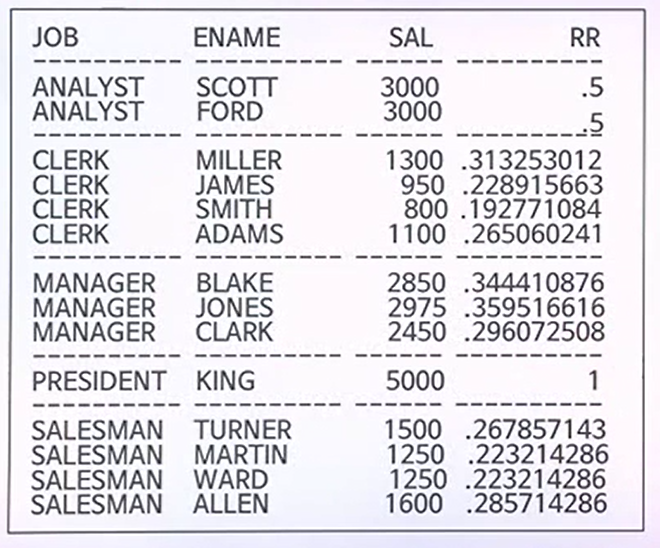
- EMP 테이블에서 업무별로 총급여를 기준으로 각 사원의 급여를 백분율(소수점으로)을 구하기 위한 SQL

- 백분율로 나타내고 싶으때는 RATIO_TO_REPORT함수를 사용하자!
- 이 함수는 OVER다음에 쓸 수 있는 구문이 PARTITION BY이다.
- ORDER BY절과 WINDOWING절을 주지 못한다.
출력결과