옵티마이저의 개념
옵티마이저란?
- 사용자가 실행한 SQL을 해석하고, 데이터 추출을 위한 실행계획을 수립하는 프로세스
옵티마이저의 종류
1. RBO(Rule Based Optimizer) - 초창기 버전부터 제공함
- 기본적으로 15개의 순위가 매겨진 규칙이 있음
-> 이를 기초로 해서 실행계획을 수립함 - SQL에 대한 실행계획이 하나 이상일 경우엔, 순위가 높은 규칙을 이용
- 수립될 실행계획이 에측 가능하기 때문에 개발자가 원하는 처리 경로로
유도하기가 쉬움

1위부터 4위까지 단 하나의 데이터를 찾는다!-
1위 : Rowid에 의한 1row(eqaul 검색)
-
2위 : 클러스터 조인에 의한 1row (클러스터화된 테이블간의 조인을 통해서 1건의 데이터를 찾는 것을 말한다)
-
3위 : Unique나 Primary key를 사용한 해시 클러스터 키에 의한 1row
-
4위 : 클러스터 키에 대해서 1건을 찾는것을 의미한다.
5위~7위 클러스터와 연관되어 있다. -
5위 : 클러스터화된 테이블끼리의 조인
-
6위 : 해시 클러스터
-
7위 : 클러스터 키
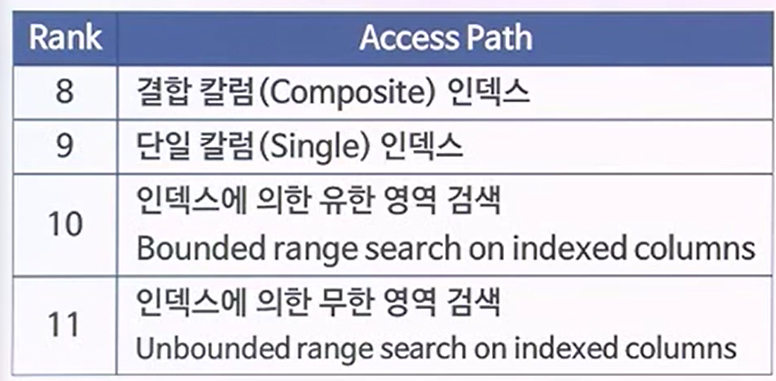
- 8위 : 1개의 인덱스가 2개의 컬럼으로 이루어져있을 때
- 9위 : 단 1개의 컬럼으로 된 인덱스 사용
- 10위 : 영역이 정해져있을 때(equal, between, like)
- 11위 : 10번째보다 범위가 넓을때를 뜻한다.

- 12위 : 소트머지를 했을 때
- 13위 : 인덱스로 구성된 칼럼의 최대 또는 최소
- 14위 : 인덱스로 구성된 칼럼으로 order by
- 15위 : 인덱스 없이 전체 테이블 스캔 (FULL Table Scan)
2. CBO(Cost Based Optimizer) - v10g부터 기본적인 설정으로 적용되고 있음
-
대상 row들을 처리하는데 필요한 자원 사용을 최소화해서, 궁극적으로 데이터를 빨리 처리하는데 목적이 있음
-
CBO에 영향을 미치는 비용 산정 요소
- 각종 통계 정보, Hint, 연산자, Index, Cluster, DBMS 버전, CPU/Memory 용량, Disk I/O등과 같이 매우 다양함.
-
통계 정보
- CBO의 성능을 최적의 상태로 유지시키기 위해서 테이블, 인덱스, 클러스터 등을 대상으로 통계 정보를 생성함 -> 정기적으로 ANALYZE 작업을 하는 것이 가장 중요함
- 가장 효율적인 실행계획을 수립하기 위해 최소비용을 계산할 때 중요하게 사용됨
-
ANALYZE 작업

- ANALYZE 작업이 됐는지, 작업을 하지 않았는지 판단하기 위해서 사용하는 구문!
- emp 테이블을 대상으로 ANALYZE를 하고 있다.
-
ANALYZE 실행 여부 확인

-
DBMS_STATS Package

- table의 owner가 되는 hr을 argument로 주었고, EMP라는 테이블 명을 명시한다.
- 현재 파티션으로 구성되어있는 테이블이 아닌 경우 NULL이라고 넣어주면된다.(지금 첫번째 SQL문 설명)
- 그 다음, SAMPLE의 크기, 맨 끝에 병렬처리를 위한 프로세스 4개를 삽입(지금 첫번째 SQL문 설명!)
- 패키지를 활용하면 병렬처리까지 할 수 있다.
- DBMS_STATS.GATHER_SCHEMA_STATS('hr')은 hr유저가 갖는 모든 object들에 대해서 일괄적으로 작업을 할 수 있도록 한다라는 뜻.
- DBMS_STATS.GATHER_DATABASE_STATS는 데이터베이스에 존재하는 모든 owner들에 대해서 작업을 일괄적으로 하게 하는 것이다.
- 이처럼 패키지를 활용한다면 명령을 사용해서 일일이 할때보다 조금 편리하게 해당 작업을 할 수 있다.
- oracle 10g부터는 이와 같은 것들이 자동으로 되어있다고 한다.
옵티마이저의 레벨별 설정
- Instance Level : initSID.ora를 이용해서 지정함, init.ora라는 파일 안에다가 OPTIMIZER_MODE라는 되어있는 파라미터에 값을 설정하는 것이다. 그때 지정할 수 있는 값이 대표적으로 4가지가 있다. CHOOSE, RULE, FIRST_ROWS, ALL_ROWS 이 중 단 하나의 값이 적용된다.

- Session Level : 우리가 데이터베이스 접속을 통해서 작업을 하려 할 때, 작업하는 SESSION에 한해서만 명령문을 통해 기존과 달리 OPTIMIZER를 제어할 수 있다.(ALTER SESSION)

- Statement Level : SQL문에다가 HINT로 그 방법을 나타낼 수 있다. HINT가 우선순위가 가장 높다. (가장 바람직한 방법)

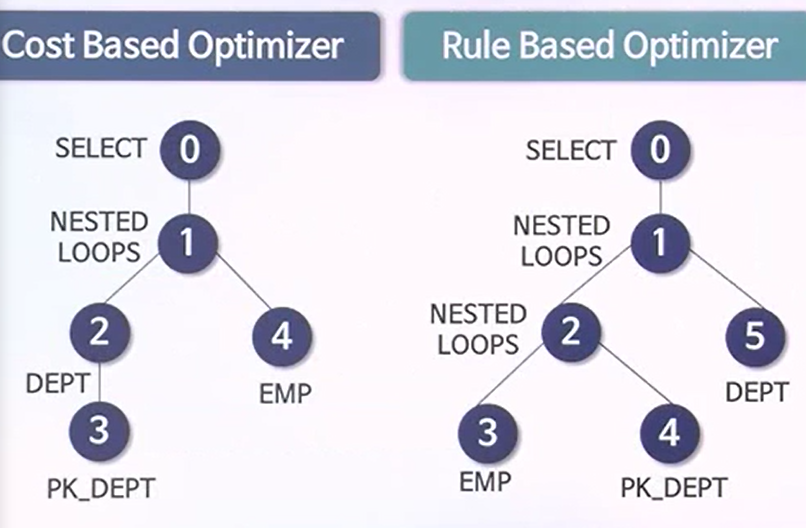
RBO와 CBO의 실행계획 비교

- 조건상에 들어가서 데이터를 처리해오는 프로세스가 RBO
- CBO는 두 테이블간 조인 조건에 의해서 다른 DEPT 테이블에도 같은 조건이 성립되어 있다라고 할 수 있다.
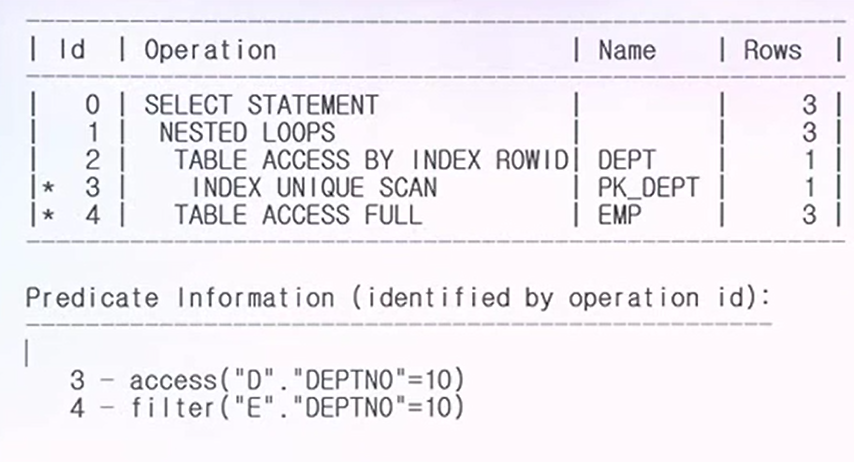
- CBO가 나타내는 실행계획
- 기존에 WHERE조건을 갖지 않았던 DEPT 테이블이 데이터를 먼저 읽어들어가는 테이블로 선택이 되어있다.
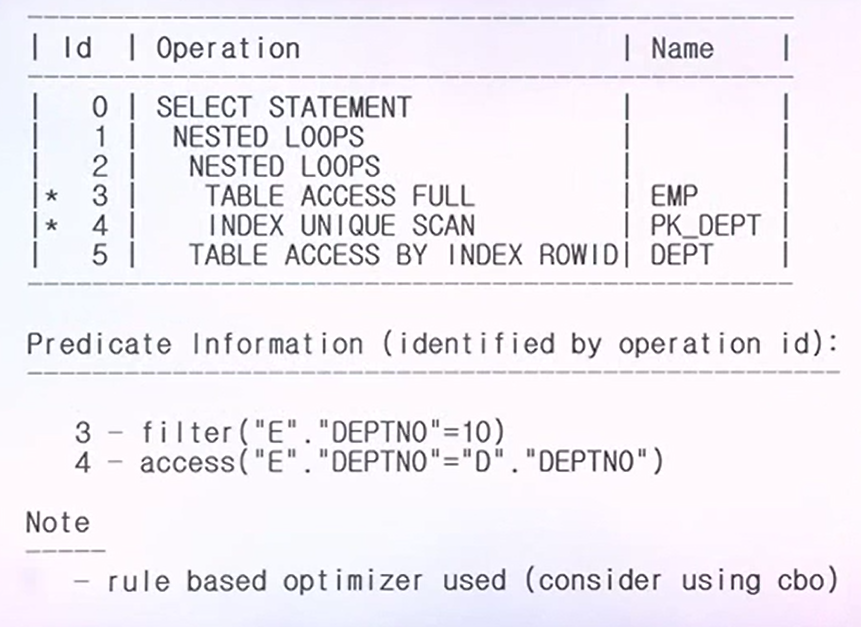
- RBO가 나타내는 실행계획
- WHERE절에 조건을 가진 테이블로부터 데이터를 찾아들이고 있다.