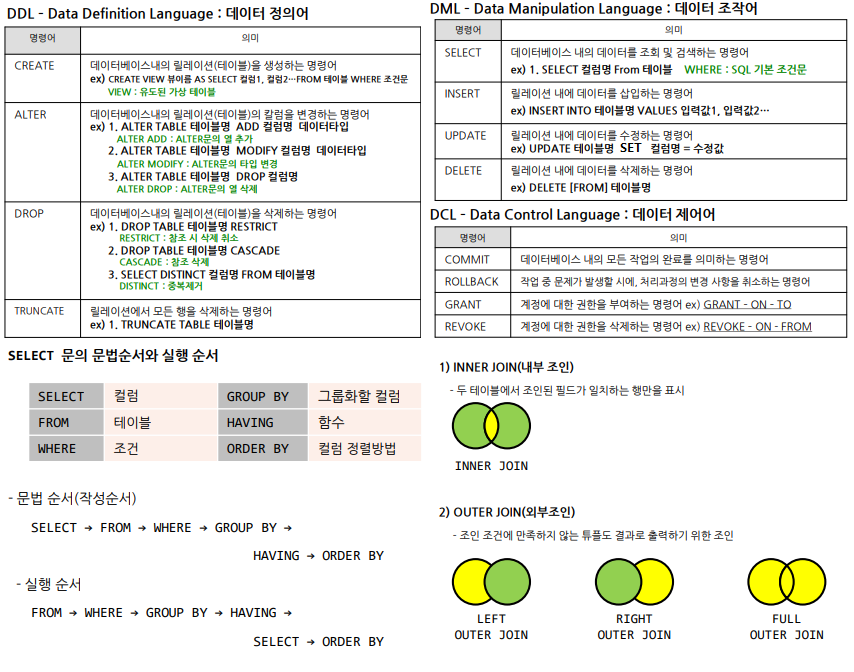
SQL Basics
SQL이란 데이터 베이스 용 프로그래밍 언어를 말하며, 주로 관계형 데이터베이스에서 사용한다.
SQL은 구조화된 Query언어이다. (query : 질의문, 저장되어있는 정보를 필터하기 위한 질문)
다시말해, 데이터 베이스에 query를 보내 원하는 데이터만을 뽑아올 수 있다.
SQL을 사용하기 위해서는 데이터의 구조가 고정되어있어야한다.
데이터베이스는 왜 필요할까?
그동안은 데이터를 저장하기위해 파일에 저장하거나, 인메모리 형태로 데이터를 임시 저장하는 방법을 이용했다. 왜 이 방법을 사용하지 않느냐?
-
java에서 데이터를 다룰 때는 프로그램이 실행될 때만 존재하는 데이터가 있다.
이러면 프로그램이 종료될 때 해당 프로그램이 사용하던 데이터도 사라진다.
예상하지 못한 상황에서 데이터를 보호할 수 없고, 프로그램이 종료된 상태라면 데이터를 원하는 시간에 받아올 수 없으며, 데이터의 수명이 프로그램의 수명이 의존하게되는 문제가 발생한다. -
엑셀 시트나 CSV같은 파일을 읽는 방식으로 작동하게되면 데이터가 필요할 때마다 전체 파일을 매번 읽어야한다. 이러면 파일의 크기가 커질 수록 버겁고, 비효율적이된다. 또한 파일이 손상되거나 여러 개의 파일들을 동시에 다뤄야하는 등 복잡하고 데이터량이 많아질 수록 데이터를 불러들이는 작업이 힘들다. (추가로, 엑셀 시트나 CSV같은 파일등처럼 특정 형태의 파일은 대용량의 데이터를 저장하기 위한 목적이 아니다.)
반면에 관계형 데이터베이스에서는 하나의 CSV파일이나 엑셀 시트를 한개의 테이블로 저장할 수 있다. 한번에 여러 개의 테이블을 가질 수 있기 때문에 SQL을 활용해 데이터를 불러오기가 수월해진다.
SQL 기본 문법
이 문서에서는 MySQL에서 사용하는 기본 문법 내용을 정리한다.
데이터 베이스 생성/ 사용
데이터 베이스를 이용해 테이블을 만들거나 수정 또는 삭제하는 등의 작업을 하려면 먼저 데이터 베이스를 사용하겠다는 명령 (USE)를 전달해야한다.
1) 데이터베이스를 생성할 때
CREATE DATABASE 데이터베이스_이름;
2) 데이터 베이스를 사용할 때
USE 데이터베이스_이름;
3) 테이블 생성 예시
CREATE TABLE user (
id int PRIMARY KEY AUTO_INCREMENT,
name varchar(255),
email varchar(255)
);
4) 테이블 정보 확인
DESCRIBE user;Select
데이터 셋에 포함될 특성을 특정한다.
1) 일반 문자열
SELECT 'hello world'
2) 간단한 연산
SELECT 15 + 3
From
테이블과 관련한 작업을 할 경우 반드시 입력해야함.
FROM뒤에는 결과를 도출해 낼 데이터베이스 테이블을 명시한다.
1) 몇가지의 특성을 테이블에서 사용할 때
SELECT 특성_1, 특성_2
FROM 테이블_이름
2) 테이블의 모든 특성을 선택할 떄
SELECT *
FROM 테이블_이름Where
필터 역할을 한다. 선택적으로 사용가능하다.
1) 특정 값과 동일한 데이터를 찾을 때
SELECT 특성_1, 특성_2
FROM 테이블_이름
WHERE 특성_1 = "특정 값"
2) 특정 값을 제외한 데이터를 찾을 떄
SELECT 특성_1, 특성_2
FROM 테이블_이름
WHERE 특성_2 <> "특정 값"
3) 특정 값보다 크거나 작은 데이터를 필터할 때
SELECT 특성_1, 특성_2
FROM 테이블_이름
WHERE 특성_1 > "특정 값"
SELECT 특성_1, 특성_2
FROM 테이블_이름
WHERE 특성_1 <= "특정 값"
4) 문자열에서 특정 값과 비슷한 값들을 필터할 때
SELECT 특성_1, 특성_2
FROM 테이블_이름
WHERE 특성_2 LIKE "%특정 문자열%"
SELECT 특성_1, 특성_2
FROM 테이블_이름
WHERE 특성_2 LIKE "%a" //문자열 끝이 a로 끝나는 값을 필터할 때
5) 값이 없는 경우를 찾을 때
SELECT *
FROM 테이블_이름
WHERE 특성_1 IS NULL
6) 값이 없는 경우를 제외해서 찾을 떄
SELECT *
FROM 테이블_이름
WHERE 특성_1 IS NOT NULL
-
And, Or, Not
-
Order By
돌려받는 데이터 결과를 어떤 기준으로 정렬하여 출력할지 결정한다. 선택적으로 사용 가능하다.
1) 기본 정렬은 오름차순이다.
SELECT *
FROM 테이블_이름
ORDER BY 특성_1
2) 내림차순으로 정렬할 때
SELECT *
FROM 테이블_이름
ORDER BY 특성_1 DESC
Limit
결과로 출력할 데이터의 개수를 정한다. 선택적으로 사용할 수 있으며 쿼리문에서 사용할 때에는 가장 마지막에 추가해야한다.
1) 데이터 결과를 200개만 출력하려할 때
SELECT *
FROM 테이블_이름
LIMIT 200
Distinct
유니크한 값을 받고 싶을 때에는 SELECT DISTINCT를 사용할 수 있다.
자바에서의 Distinct와 같이 중복을 제거할 때 사용하는 것으로 이해했다.
1) 특성_1을 기준으로 유니크한 값들만 선택할 때
SELECT DISTINCT 특성_1
FROM 테이블_이름
2) 특성_1,2,3의 유니크한 '조합' 값들을 선택할 때
SELECT
DISTINCT
특성_1
,특성_2
,특성_3
FROM 테이블_이름Insert Into
데이터를 추가할 때 사용하는 것으로 이해했다.
INSERT INTO
Customers
(
CustomerName,
Address,
City,
PostalCode,
Country
)
VALUES
(
'Hekkan Burger',
'Gateveien 15',
'Sandnes',
'4306',
'Norway'
)
;-
Null Values
빈 값이 들어가면 안될 때 테이블 생성 시 사용하는 것으로 이해했다.
-
Update
데이터를 갱신할 때 사용하는 것으로 이해했다.
-
Delete
데이터를 삭제할 때 사용하는 것으로 이해했다.
-
Count
데이터의 갯수를 세아릴 때 사용하는 것으로 이해했다.
-
Wildcards
-
Aliases
-
Joins
INNER JOIN이나 JOIN으로 실행할 수 있다.
1) 둘 이상의 테이블을 서로 공통된 부분을 기준으로 연결한다.
SELECT *
FROM 테이블_1
JOIN 테이블_2 ON 테이블_1.특성_A = 테이블_2.특성_BOuter Join
다양한 선택지가 있다.
1) LEFT OUTER JOIN
SELECT *
FROM 테이블_1
LEFT OUTER JOIN 테이블_2 ON 테이블_1.특성_A = 테이블_2.특성_B
2) RIGHT OUTER JOIN
SELECT *
FROM 테이블_1
RIGHT OUTER JOIN 테이블_2 ON 테이블_1.특성_A = 테이블_2.특성_B
-
Group By
-
여러 쿼리 문을 한번에 쓸 때 예시
SELECT c.CustomerId, c.FirstName, count(c.City) as 'City Count'
FROM customers AS c
JOIN employees AS e ON c.SupportRepId = e.EmployeeId
WHERE c.Country = 'Brazil'
GROUP BY c.City
ORDER BY 3 DESC, c.CustomerId ASC
LIMIT 3함께 수업을 듣는 동기분이 올리신 자료인데 정리가 잘 된 이미지같아 첨부한다.