자연어처리 연구 및 모델 평가에서 사용되는 데이터셋 중 논문에서 자주 보이는 데이터셋들을 몇 가지 정리해보려고함. 이게 뭔지는 알고 써야하니까..
MS MARCO (Microsoft MAchine Reading COmprehension)
https://arxiv.org/abs/1611.09268
요약
대규모 기계 독해(Machine Reading Comprehension, MRC) 데이터셋으로, Bing 검색 로그에서 샘플링된 1,010,916개의 익명화된 질문과 182,669개의 사람이 다시 작성한 정답을 포함하고 있음.
8,841,823개의 passages가 있고 Bing 검색을 통해 수집된 3,564,545개의 웹 문서에서 추출된거임
실제 사용자 검색 쿼리 기반 질문을 포함하여, 기존 공개 데이터셋과 차별화됨.
한 질문에 대해 여러 개의 정답이 있을 수도 있고, 아예 정답이 없을 수도 있음.
데이터셋 구성 요소
- 질문 (Questions)
- Bing 검색 로그에서 익명화된 사용자 질문 수집
- 사람이 추가로 질문을 검토하여 답변 가능 여부 평가
- 문단 (Passages)
- 각 질문당 평균 10개의 문단 제공
- 사람이 읽고 정답을 생성하는 데 사요한 문단은 is_selected=1로 표시
- 정답 (Answers)
- 질문에 대해 사람이 직접 문단을 읽고, 문단에서 필요한 정보를 추출하여 자연어로 답변 생성
- 일부 질문에는 정답이 존재하지 않을 수도 있음
- 자연스러운 정답 (Well-formed Answers)
- 기존 정답을 사람이 다시 검토하고 문법적 오류 수정 및 보다 명확한 표현으로 재작성
- 문서 (Documents)
- 문단이 추출된 원본 문서의 URL, 본문, 제목 포함
- 일부 문서는 검색 인덱스에서 제거되어 검색이 되지 않을 수 있음
- 질문 유형 (Question Type)
- 질문은 기계 학습 모델을 이용하여 다음과 같은 유형으로 자동 분류됨
- NUMERIC (숫자 기반)- ENTITY (개체명)
- LOCATION (위치)
- POERSON (인물)
- DESCRIPTION (설명)
MS MARCO 챌린지
- Novice(초급) 태스크
- 제공된 패시지에서 질문에 대한 답을 찾을 수 있는지 에측
- 답변이 존재하지 않으면 "No Answer Present"를 반환
- Intermediate(중급) 태스크
- 생성된 답변이 문맥 없이도 자연스럽게 이해될 수 있도록 해야함
- 즉, 답변이 질문이나 패시지 없이도 완전한 문장이어야함
- Passage Re-ranking 태스크
- BM25로 검색된 1000개의 패시지를 제공받고, 질문과 관련성이 높은 순으로 재배치
실험

SQuAD (Stanford Question Answering Dataset)
https://arxiv.org/abs/1606.05250
요약
crowdworkes에 의해 위키 백과 문서 기반으로 작성된 데이터셋으로 crowdworkers가 제시한 질문들과, 각 질문에 대한 답이 해당 기사 내의 텍스트 일부로 이루어져 있음
536개의 기사에 대해 107,785개의 질문-답변 쌍을 포함하고 있음
dependency trees(의존성 트리)와 constituency trees(구문 트리)를 활용했음
데이터셋 수집
본문 수집, 크라우드소싱을 통한 질문-답변 생성, 추가적인 답변 수집. 이렇게 총 3 단계로 수집했음
-
본문 수집
Project Nayuki의 PageRank를 사용해서 영어 위키백과에서 상위 10,000개의 기사를 추출한 후 536개의 기사를 무작위로 샘플링을 진행함.
각 기사에서 개별 문단을 추출하고, 이미지, 그림, 표는 제외한 후, 500자 미만의 문단은 삭제함. 이렇게 추출된 문단은 다양한 주제를 다루고 있음 -
질문-답변 생성
그다음 crowdworker를 고용해서 질문을 만들었음. crowdworker는 97% 이상 HIT 수락률과 최소 1000개의 HIT를 수행한 경험을 가진 사람들로 이루어져있음.worker는 시간당 $9 받아갔음 ;;
좋은 샘플과 나쁜 샘플 그리고 그 이유를 worker들에게 주고 각 문단에 대해 최대 5개의 질문을 만들었음. -
추가적인 답변 수집
SQuAD에 대한 인간의 성과를 파악하고, 더 강화하기 위해 개발 세트와 테스트 세트의 각 질문에 대해 최소 2개의 추가적인 답변을 수집했음. 각 worker는 질문과 함께 문단을 보고, 그 문단에서 질문에 가장 적합한 짧은 스팬을 선택했음. 만약 문단에서 질문에 대한 답변을 찾을 수 없으면 "답변할 수 없음"으로 표시하였고 전체 데이터 세트에서 2.6%는 답변할 수 없었음.
데이터셋 분석
이것도 3가지 테스크로 나눴는데 답변 유형의 다양성, 추론의 난이도, 질문과 답변 문장 간의 구문적 차이로 나눔
-
답변 유형의 다양성
답변을 숫자형(날짜, 숫자)과 비숫자형(이름, 장소, 단어)으로 나눈 후 비숫자형 답변은 문법적인 구조를 분석해 사람 이름, 장소, 기타 엔터티 등으로 세분화 함 -
답변을 위한 추론 요구 사항
데이서세에 있는 48개 기사에서 각각 4개의 질문을 뽑아, 어떤 논리적 과정이 필요한지 수동으로 분류함. 대부분의 질문과 답변은 문장에서 단순히 단엄나 찾아서 답할 수 없었음. -
구문적 차이를 통한 계층화
질문과 답변이 포함된 문장이 얼마나 비슷한지 비교하기 위해 질문과 답변에서 공통 단어를 찾은 후, 이 단어를 중심으로 문장 구조를 분석했음. 두 문장 구조의 차이를 측정하는 방법으로 edit distance(편집 거리)를 사용함
- edit distance가 작으면 질문과 답변 문장이 비슷
- 반대로 크면 답변이 많이 변형됨을 의미
방법
슬라이싱 윈도우 방식보다 더 정교한 Feature를 활용하여 정답을 예측하는 로지스틱 회귀(Logistic Regression)를 사용했음
일반적으로 문장에서 가능한 모든 단어 조합을 정답 후보로 고려하면 계산량이 너무 많음. 따라서 Stanford CoreNLP의 문법 분석(Constituency Parsing) 을 사용하여, 문장에서 특정한 Constituent(구, 의미 있는 단어 묶음)를 정답 후보로 선택했음
로지스틱 회귀 모델은 각 후보 정답에 대해 다양한 Feature를 추출하여 정답을 예측함.
특징은 다음과 같음
1. 단어 및 바이그램 빈도 : 질문과 후보 정답이 포함된 문장 사이의 유사도를 판단
2. 정답 길이와 위치 : 일반적인 정답 길이 및 위치 패턴 반영
3. 품사 태그와 구문 구조 정보 : 올바른 정답 유형을 예측
4. 의미적 변형(동의어 등) 보정 : 단어 변형 대응
5. 구문 구조 차이 고려 : 문법적 구조를 반영
실험
정확도를 평가하기 위해 두 가지 지표를 사용
1. 정확 일치(Exact Match, EM)
모델이 예측한 정답이 실제 정답 중 하나와 완전히 일치하는 비율 측정
2. F1 점수 (Marco-averaged F1 score)
예측한 정답과 실제 정답이 얼마나 겹치는지를 평ㅇ가
두 정답을 단어 단위로 나누어 비교한 후, 최대 F1 점수를 계산
이후, 모든 질문에 대해 평균을 구함
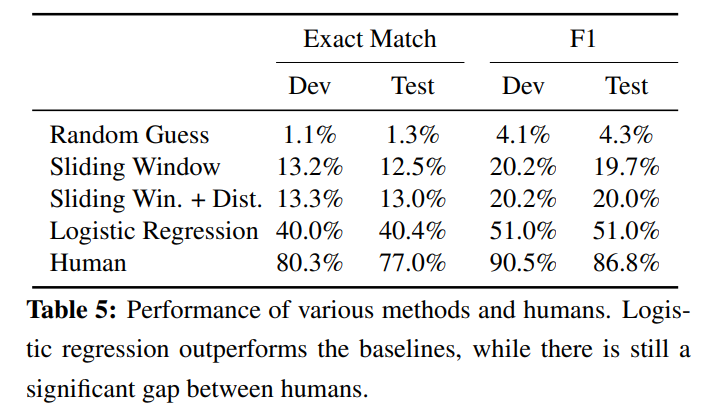
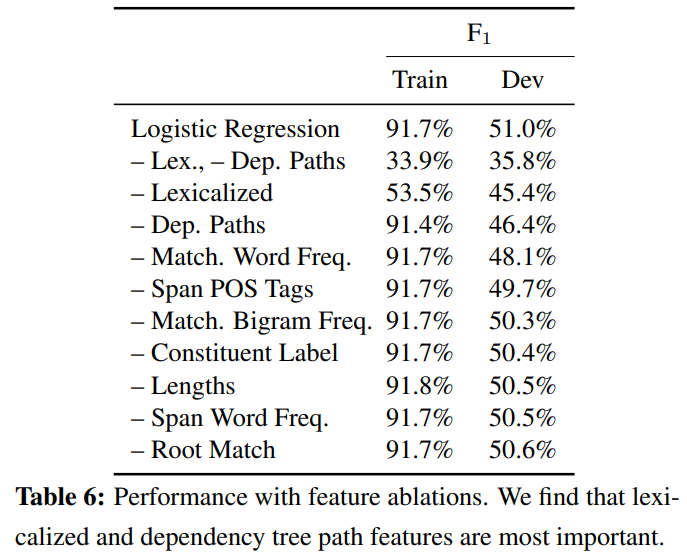
로지스틱 회귀 모델은 다른 baselines에 비해 우수한 성능을 보임, 하지만 human performance에는 한참 미치지 못하는 것을 확인할 수 있음. 이유는 문장 내의 specific span을 찾는 task의 난이도 때문이라고 보임
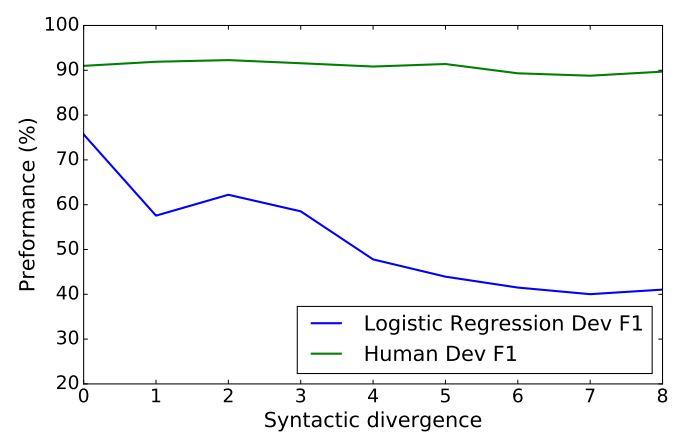
그리고 syuntactic divergence를 기준으로 human performance와 비교했을 때, 발전의 여지가 많이 남았다고 볼 수 있음. syntatic divergence가 심해질수록 성능 저하가 급격하다.
HotpotQA
https://arxiv.org/abs/1809.09600
요약
위키백과 기반의 113,000개 질문-답변 쌍을 포함하는 데이터셋인데 네 가지 주요 특징을 갖고있음
- 멀티-홉핑 추론 요구
답변을 도출하기 위해 여러 개의 문서를 찾아 추론해야 한다. - 다양한 질문 유형
사전 정의된 지식베이스나 스키마에 제한되지 않은 질문들로 구성 - 문장 수준의 근거 제공
QA 시스템이 강한 지도 학습을 통해 추론하고, 예측을 설명할 수 있도록 문장 단위의 근거를 제공 - 비교 질문 포함
관련 정보를 추출하고 비교할 수 있는 능력을 평가하는 새로운 유형의 사실 기반 질문 포함
데이터 수집
다양하면서 설명 가능한 질의응답(QA) 데이터셋을 구축하는 것이며, 특히 멀티-호핑 추론이 필수적인 데이터셋을 만드는 데 중점을 둔다.
텍스트 기반 멀티-호핑 질문을 수집하는 것은 다음과 같은 어려움이 있다.
- 임의의 문단 집합을 crowd worker에게 제공하는 방식은 비효율적
- 대부분의 문단 조합에서는 의미 있는 멀티-호핑 질문을 생성하기 어려움
이 문제를 해결하기 위해 체계적인 파이프라인을 설계하여 텍스트 기반 멀티-호핑 질문을 수집했음
데이터 구축 과정
- 위키백과 하이퍼링크 그래프 구축
- 하이퍼링크는 문맥 속에서 두 개체(entity) 간의 관계를 자연스럽게 나타냄
- 이는 멀티-호핑 추론을 위한 연결 고리로 활용 가능
- 각 문서의 첫 번째 단락(lead paragraph)는 질의응답을 위한 중요한 정보를 포함
- 따라서, 모든 문서의 첫 단락에서 하이퍼링크 추출
- 후보 문단 쌍 생성
- Bridge Entity를 이요한 문단 쌍 생성
- 예를 들어 질문이 Radiohead의 싱어송라이터는 언제 태어났는가? 라면
- 먼저, Radiohead의 싱어송라이터 = Thom Yorke라는 사실을 추론해야함
- 이후, Thom Yorke의 출생일을 찾아야 함
이처럼 중간 과정에서 핵심 역할을 하는 개체를 '브릿지 개체(Bridge Entity)라고 함
- 비교 질문(Comparison Questions) 생성
- 멀티-호핑 QA 질문의 다양성을 높이기 위해 비교 질문 추가
- 동일한 범주(category)에 속하는 두 개체를 비교
- 정답 근거(supporting facts) 수집
- QA 시스템이 설명 가능한(explainable) 답변을 생성하도록 하기 위해 정답을 결정하는 데 필요한 문장도 수집
- crowd workers에게 답을 도출하는 데 필요한 문장을 명시적으로 표시하도록 요청
데이터셋 분석
먼저 수집된 각 질문에 대해 휴리스틱하게 질문 유형을 식별 함. 질문 유형을 식별하기 위해 먼저 질문에서 중심 질문 단어(CQW)를 찾는다. HOTPOTQA에는 비교 질문과 예/아니오 질문이 포함되어 있으므로, 질문 단어로 WH-단어, 연결 동사(is, are) 및 조동사(does, did)를 고려한다.