Intro
- Google Cloud Storage에서 데이터를 읽어와 처리하는 실습을 진행해보겠습니다.
Contents
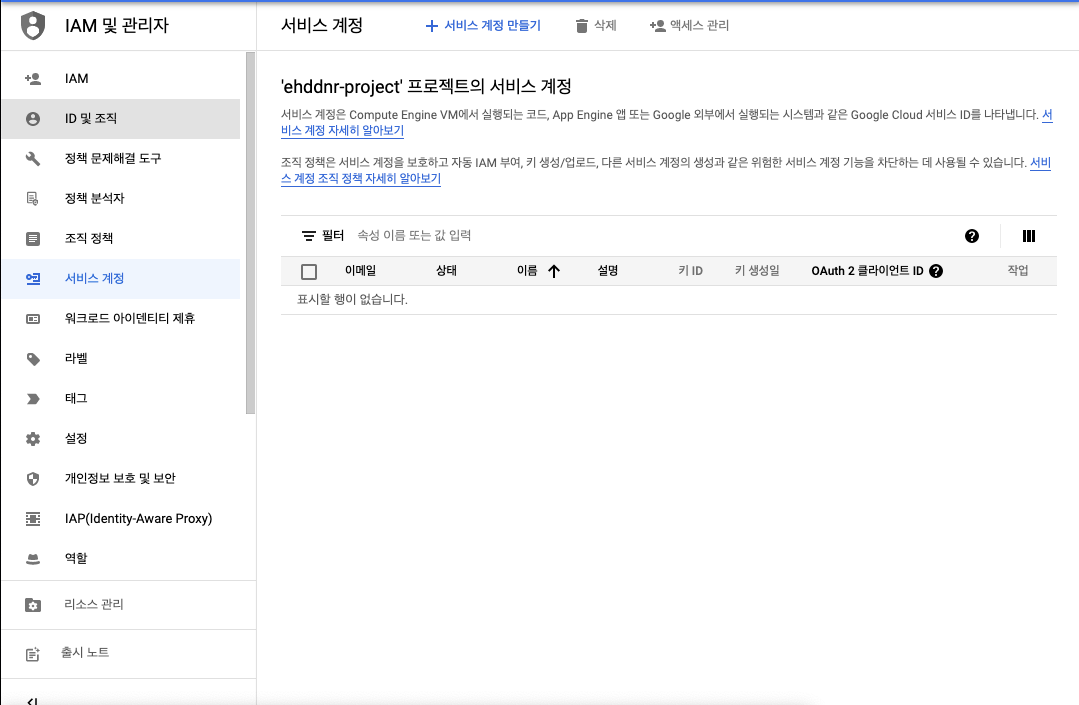
- IAM & Admin 으로 들어갑니다.
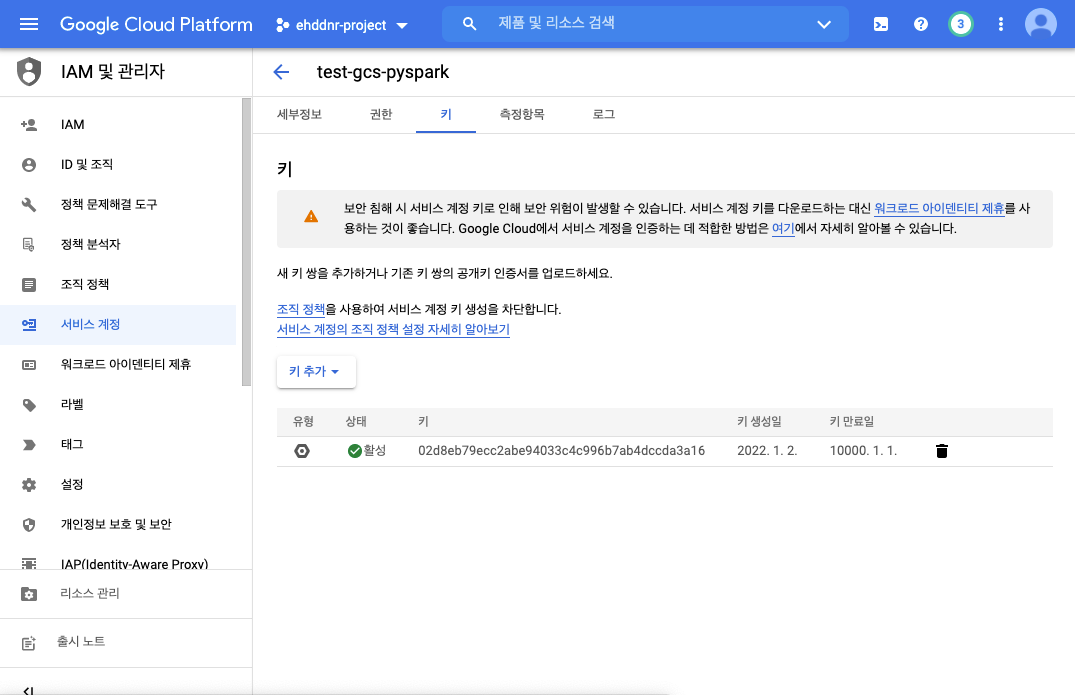
- 키 추가를 눌러 위와같이 키를 생성합니다.
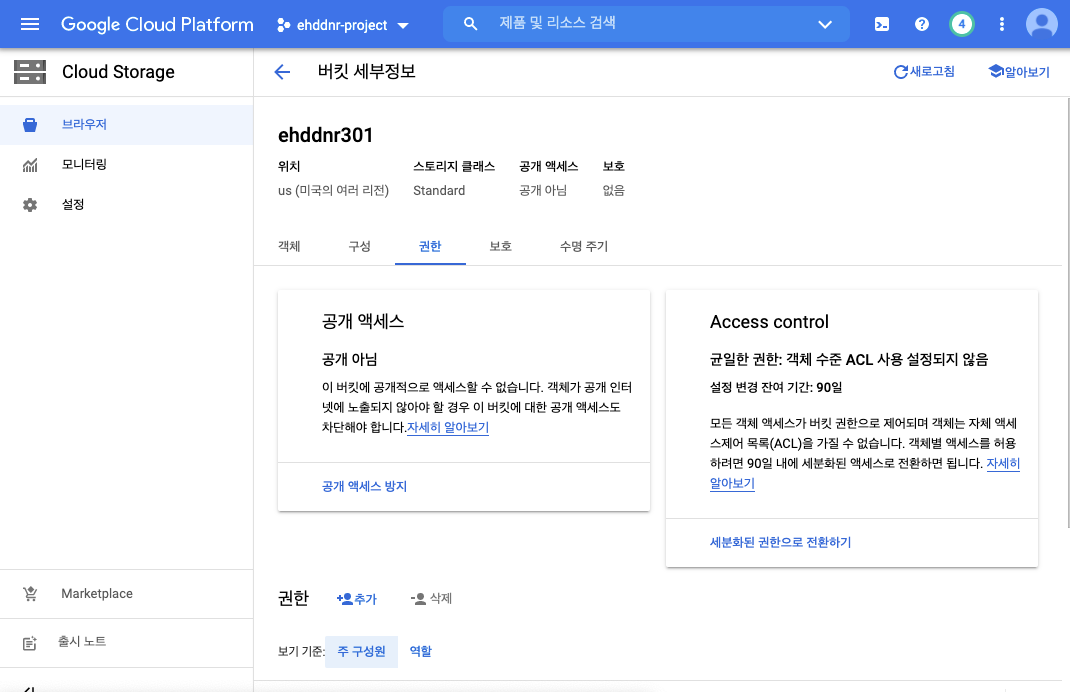
- Cloud Storage로 들어가서 버킷을 생성합니다.
- 버킷으로 들어가 권한 옆의 추가 버튼을 누릅니다.
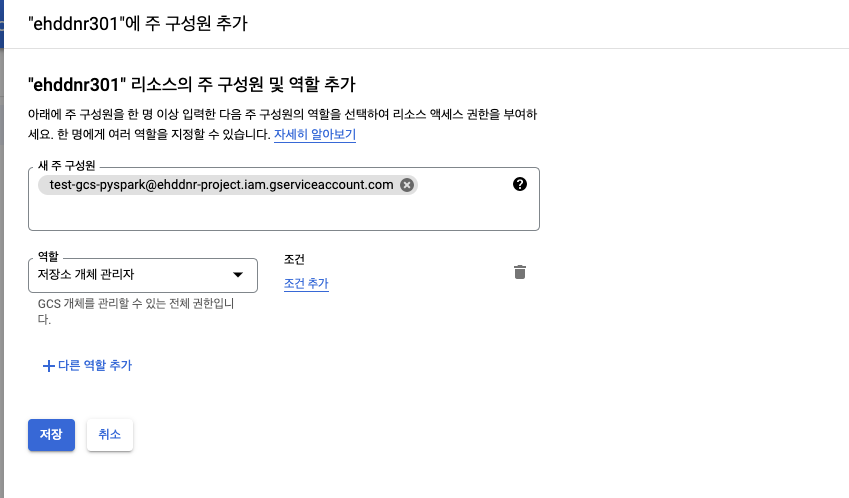
- 위와같이 처음에 생성한 키를 저장소 개체 관리자로 추가하여 줍니다.
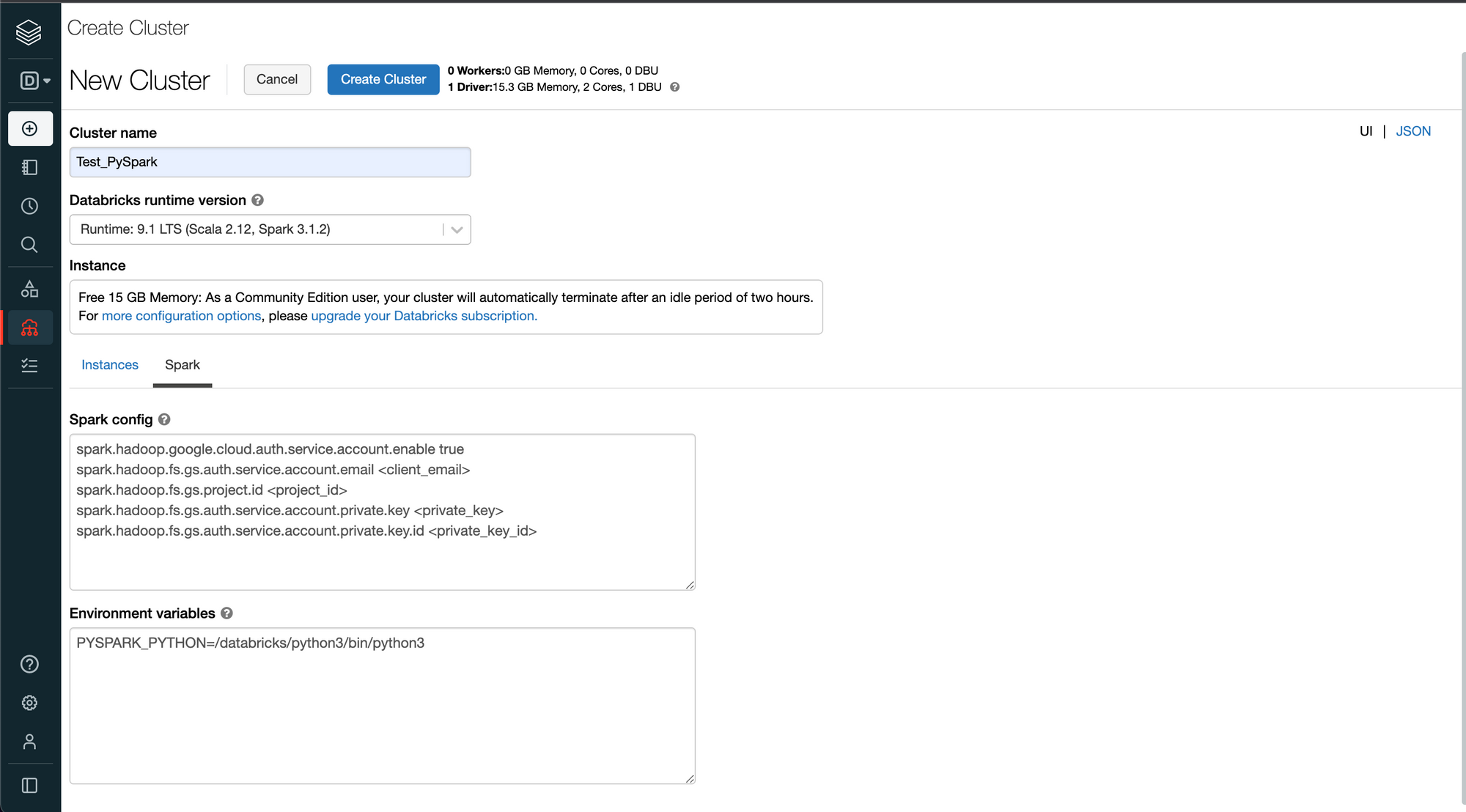
- databricks community로 이동하여 아까 키 추가를 하며 다운로드 받은 json파일 내부의 정보를 cluster생성때 추가하여 줍니다.
- <client_email> 과 같은 정보가 모두 json파일 안에 있기때문에 그대로 복사 붙여넣기 합니다.
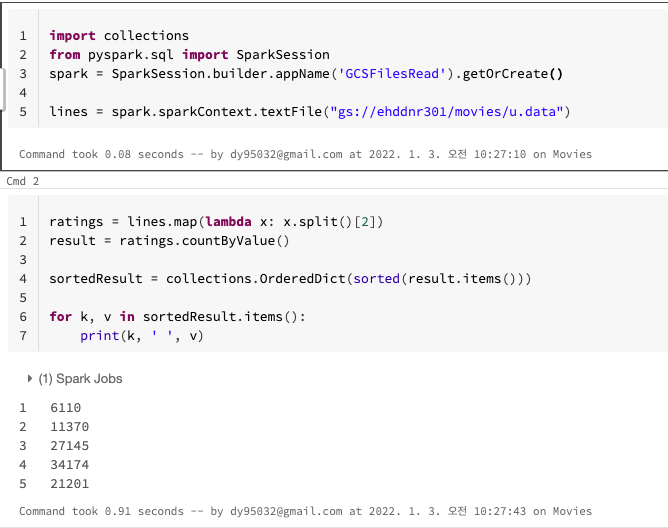
- 다음과 같이 google cloud storage에서 데이터를 읽어올 수 있습니다.
- 사용된 데이터는 ml-100k데이터 이고 링크 에서 다운받을 수 있습니다.
import collections
from pyspark.sql import SparkSession
spark = SparkSession.builder.appName('GCSFilesRead').getOrCreate()
lines = spark.sparkContext.textFile("gs://ehddnr301/movies/u.data")
ratings = lines.map(lambda x: x.split()[2])
result = ratings.countByValue()
sortedResult = collections.OrderedDict(sorted(result.items()))
for k, v in sortedResult.items():
print(k, ' ', v)Outro

- Datalake로 사용되는 gcs에서 data를 load해보는 것을 실습해 보았습니다.
- 추후에 업로드까지 실습해보도록 하겠습니다.
- 다음글은 PySpark를 활용한 분석이나 분산처리 실습이 될 것 같습니다.
- 글 마치는게 어색해서 귀여운 춘식이로 마무리합니다.

공부해서 남주자