Intro

- Databricks Community를 사용하여 PySpark를 실습하고 있는데 실습을 하면서 좀 더 다른것과 연계해보고 싶다는 생각이 들어서 Hadoop부터 시작해서 하나하나 설치한 후 프로젝트를 진행해보려 합니다.
- 하둡은 분산 환경에서 빅 데이터를 저장하고 처리할 수 있는 자바 기반의 오픈 소스 프레임 워크입니다. 하지만 실습환경을 구축은 single node를 사용하려 합니다.
- 참고한 공식문서, 블로그, 블로그
Contents
실습 세팅
- Google Compute Engine
- Ubuntu 18.04
- e2-standard-4 (RAM 16GB)
- 저장공간 70GB
설치
Java
- Java™ must be installed. Recommended Java versions are described at HadoopJavaVersions.
- Hadoop 설치를 위해서는 Java가 필요합니다.
sudo apt-get update
sudo apt-get install openjdk-8-jdk -y- 설치 후
javac -version로 잘 설치되었는지 확인합니다.
ssh

ssh-keygen -t rsa -P '' -f ~/.ssh/id_rsa
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
chmod 0600 ~/.ssh/authorized_keys- 설치과정에서 자기자신으로 ssh 접속이 가능해야하기때문에 위와 같이 커맨드를 입력하여 설정합니다.
Hadoop Install

- 링크 로 가면 hadoop을 다운받을 수 있도록 링크를 제공합니다.
- We suggest the following site for your download: 아래 링크를 눌러 hadoop을 설치할 수 있는 파일의 링크주소를 복사합니다. 저는 hadoop-3.3.1로 진행하였습니다.
wget https://dlcdn.apache.org/hadoop/common/hadoop-3.3.1/hadoop-3.3.1.tar.gz
tar xzf hadoop-3.3.1.tar.gz- 위와 같이 다운받습니다.
sudo mv -f hadoop-3.3.1 /opt
sudo ln -s /opt/hadoop-3.3.1 /opt/hadoop- opt 경로로 이동시켜서 hadoop이라는 이름으로 symbolic link를 해 경로를 단축해서 쓸 수 있도록 합니다.
Hadoop Config
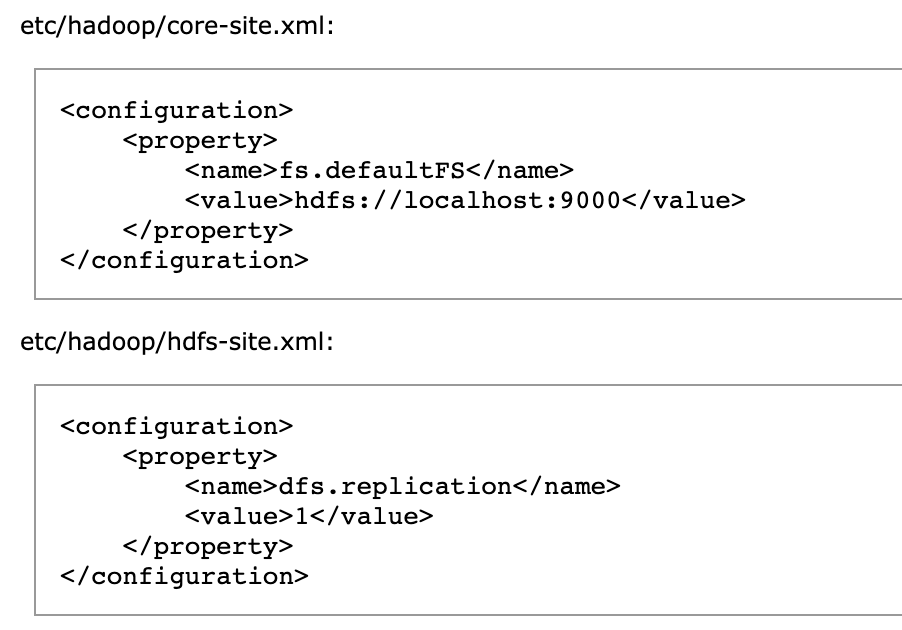
- Config을 위해서 주로 어떤 값을 사용하나 찾아보았습니다.
vi /opt/hadoop/etc/hadoop/core-site.xml
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>
</configuration>- core-site.xml은 공식문서상의 내용을 그대로 사용하였습니다.
vi /opt/hadoop/etc/hadoop/hdfs-site.xml
<configuration>
<property>
<name>dfs.namenode.name.dir</name>
<value>/opt/hadoop/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/opt/hadoop/dfs/data</value>
</property>
<property>
<name>dfs.namenode.checkpoint.dir</name>
<value>/opt/hadoop/dfs/namesecondary</value>
</property>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
</configuration>- hdfs-site.xml의 경우 블로그를 참고하여 설정하였습니다.
- 링크에 property에 대한 설명이 자세히 나와있습니다.
- 저장할 경로에 관한 설정입니다.
vi ~/.profile 을 통해 우리가 설치한 환경에 대해 아래와 같이 환경변수를 추가합니다.
export HADOOP_HOME=/opt/hadoop
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
export JAVA_HOME=/usr/lib/jvm/java-1.8.0-openjdk-amd64vi /opt/hadoop/etc/hadoop/hadoop-env.sh를 통해 hadoop 환경변수도 추가합니다.
export JAVA_HOME=/usr/lib/jvm/java-1.8.0-openjdk-amd64Execute Hadoop

hdfs namenode -format한 후에ssh ${USER}@localhost해서 다시 접속한 후에start-dfs.sh하여 잘 설치되었는지 테스트 합니다.
Config Hadoop YARN
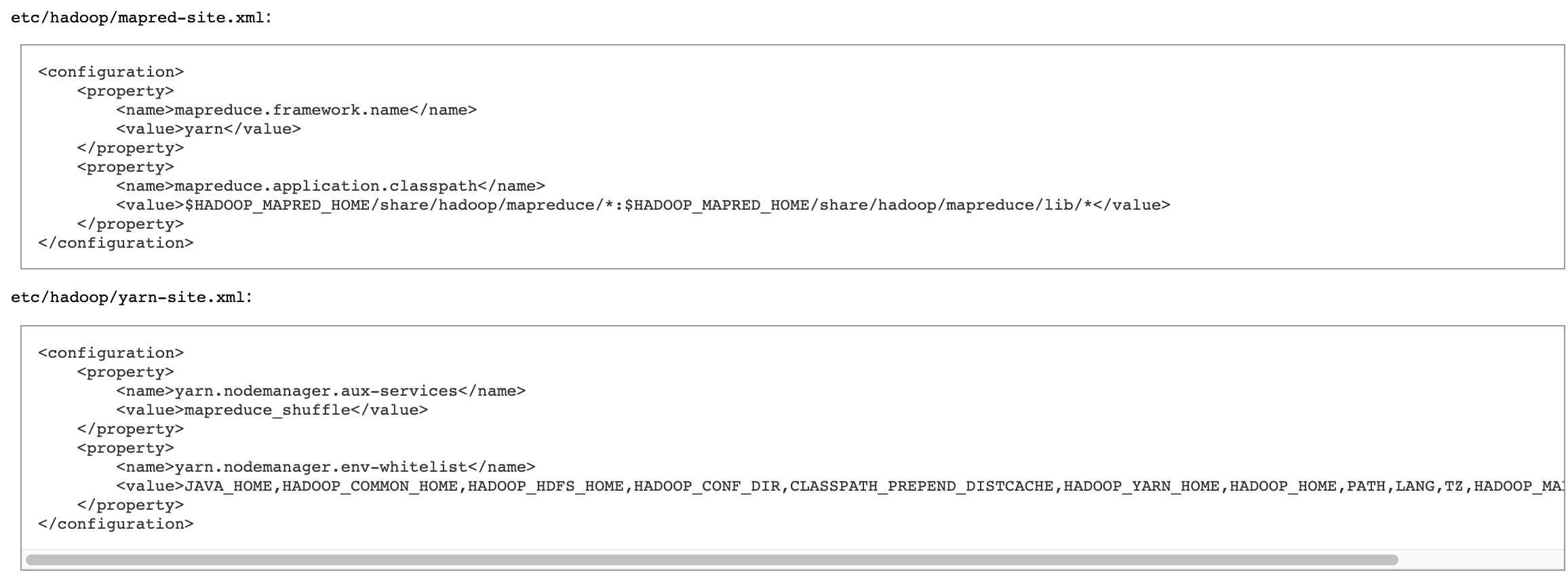
-
공식문서의 값을 그대로 사용하였습니다.
-
vi /opt/hadoop/etc/hadoop/yarn-site.xml
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.env-whitelist</name>
<value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_HOME,PATH,LANG,TZ,HADOOP_MAPRED_HOME</value>
</property>
</configuration>vi /opt/hadoop/etc/hadoop/mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.application.classpath</name>
<value>$HADOOP_MAPRED_HOME/share/hadoop/mapreduce/*:$HADOOP_MAPRED_HOME/share/hadoop/mapreduce/lib/*</value>
</property>
</configuration>- 설정이 완료되면
start-yarn.sh나stop-yarn.sh로 테스트해 볼 수 있습니다.
Outro

- 간단하게 Hadoop을 설치해보았습니다.
- 추후에 kafka나 Spark설치 등도 포스팅 할 예정입니다.

공부해서 남주자