
웹 페이지로부터 우리가 원하는 정보를 추출하는 방법에는 웹 스크래핑(Web scraping)과 웹 크롤링(Web crawling)이 있다. 웹 스크래핑과 크롤링은 서로 관련된 개념이지만 약간의 차이가 있다. 이번 글에서 그 차이를 알아보고 python을 활용하여 정적 웹 페이지에서 웹 스크래핑 하는 방법을 알아보겠다.
웹 스크래핑과 웹 크롤링
스크래핑과 크롤링의 개념
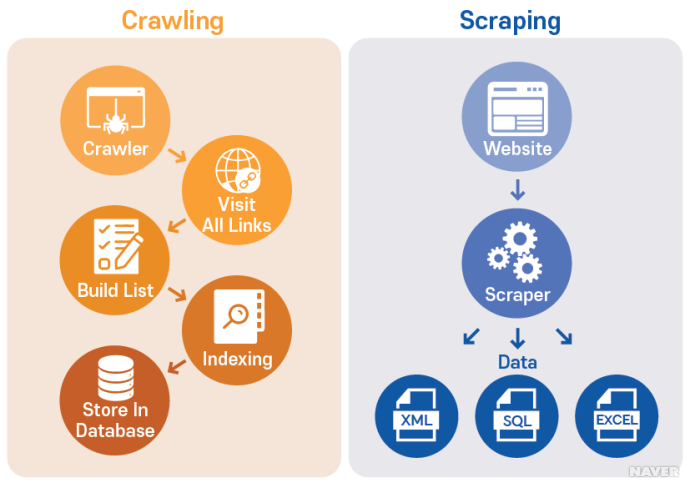
웹 스크래핑(Web scraping)
웹 스크래핑(Web scraping)은 특정한 웹 사이트에서 필요한 데이터를 수집하는 방법이다. 스크래핑은 크롤링보다는 좁은 범위의 데이터 수집에 주로 사용된다. 예를 들어, 온라인 쇼핑몰에서 상품 정보를 추출하거나, 뉴스 사이트에서 최신 기사를 수집하는 등의 작업을 수행할 때 주로 사용된다. 크롤링에 비해 스크래핑은 특정한 웹 사이트에서 필요한 데이터를 추출하는 데 초점을 둔다는 차이점이 있다.
웹 크롤링(Web crawling)
웹 크롤링(Web crawling)은 인터넷 상에 존재하는 모든 웹 페이지를 방문하여 데이터를 수집하는 방법이다. 즉, 크롤러는 인터넷 상의 모든 페이지를 방문하며, 각 페이지의 링크를 따라가면서 자동으로 데이터를 수집한다. 크롤링은 대부분의 검색 엔진에서 사용되며, 예를 들어 구글, 네이버 같은 검색 엔진의 검색 결과를 보여줄 때도 크롤러를 사용하여 인덱싱 작업을 수행한다. 스크래핑과 가장 큰 차이점은 특정한 웹 페이지가 아닌 URL을 타고다니며 반복적으로 데이터를 가져오는 과정(데이터 색인)이 진행된다는 것이다.
주의사항
웹 스크래핑/크롤링을 올바르게 하기 위해 몇 가지 고려해야 할 것들이 존재한다.
-
웹 스크래핑/크롤링을 통해 어떤 목적을 달성하고자 하는가?
추출한 결과물을 상업적으로 사용하기 위해서는 저작권이나 데이터베이스권을 침해하지 않는지 항상 고려해야 한다. 웹 사이트는 이용 약관에서 스크래핑/크롤링을 금지하거나, 일부 제한을 두고 있을 수 있다. 따라서 스크래핑/크롤링을 수행하기 전에 해당 웹 사이트의 이용 약관을 반드시 확인해야 한다. -
나의 웹 스크래핑/크롤링이 서버에 영향을 미치지 않는가?
서버 부하를 줄이기 위해 스크래핑/크롤링 작업을 수행할 때, 적절한 딜레이를 적용해야 한다. 딜레이를 적용하지 않으면 웹 서버에 대한 불필요한 부하를 유발하게 되어 서버에서 스크래핑/크롤링을 차단하는 경우가 발생할 수 있다. -
로봇 배제 표준(Robots Exclusion Standard)을 준수했는가?
로봇 배제 표준은 웹 사이트의 소유자가 로봇에 대한 액세스 권한을 제어하는 프로토콜이다. 따라서, 스크래핑/크롤링을 수행하기 전에 해당 웹 사이트의 robots.txt 파일을 반드시 확인하고, 로봇 배제 표준을 준수해야 한다. robots.txt 파일은 "URL/robots.txt" 형식으로 쉽게 확인할 수 있다.
robots.txt란?
robots.txt는 웹사이트에서 크롤링하며 정보를 수집하는 검색엔진 크롤러(또는 검색 로봇)가 액세스 하거나 정보수집을 해도 되는 페이지가 무엇인지, 해서는 안 되는 페이지가 무엇인지 알려주는 역할을 하는 .txt (텍스트) 파일이다. robots.txt 파일은 검색엔진 크롤러가 웹사이트에 접속하여 정보 수집을 하며 보내는 요청(request)으로 인해 사이트 과부하되는 것을 방지하기 위해 사용된다.
웹 스크래핑/크롤링 시, 웹 서버에 요청할 때 사용자 에이전트 HTTP 헤더 (user agent HTTP header)에 나의 브라우저 정보를 전달하면 웹 서버가 나를 진짜 사용자로 인식할 수 있게 된다. (나의 브라우저 정보를 전달하지 않으면 봇으로 인식해 막히는 경우가 있다.)
나의 UserAgent 정보는 해당 링크에서 확인이 가능하다.
Python으로 정적인 웹 페이지에서 웹 스크래핑하기
BeautifulSoup이란
Python으로 http 요청과 응답을 처리하기 위해서는 requests 라이브러리를 사용할 수 있다. requests 라이브러리를 통해 받은 결과값은 html을 '의미있는', 즉 Python이 이해하는 객체 구조로 만들어주지는 못한다. 단순히 문자열을 반환할 뿐이기 때문에 정보를 추출하기가 어렵다.
따라서 스크래핑을 하는데 BeautifulSoup 라이브러리를 추가적으로 사용하는 것이 일반적이다. BeautifulSoup은 파이썬의 HTML 및 XML 문서를 파싱하고 구문 분석하는 데 사용된다.
BeautifulSoup 설치 및 사용
다음은 BeautifulSoup 라이브러리를 설치하는 명령어이다. Jupyter notebook 환경이라면 앞에 '%'를 추가로 붙여야한다.
pip install bs4다음은 예제 링크에 접속하여 <h1> 태그의 내용을 추출하는 코드이다. 링크의 내용은 아래와 같고, <h1> 태그의 내용은 'Example Domain'이다.
import requests
from bs4 import BeautifulSoup
# www.example.com 사이트를 요청한 후 응답 받기
res = requests.get("https://www.example.com")
# BeautifulSoup 객체를 생성
# 첫번째 인자로는 response의 body를 텍스트로 전달
# 두번째 인자로는 "html"로 분석한다는 것을 명시
soup = BeautifulSoup(res.text, "html.parser")
# 객체 soup의 .prettify()를 활용하면 분석된 HTML을 보기 편하게 반환
print(soup.prettify())
# soup 객체를 통해서 HTML의 특정 요소를 가지고 올 수 있음
print(soup.title)
print(soup.head)
print(soup.body)
# <h1> 태그로 감싸진 요소 하나 찾기
h1 = soup.find("h1")
# <h1> 태그로 감싸진 요소들 찾기
h1_ = soup.find_all("h1")
print(h1.name) # 태그 이름 가져오기
print(h1.text) # 태그 내용 가져오기BeautifulSoup 특정 기능 살펴보기
특정 태그 안의 속성에 접근하기
soup.find("h3") 의 결과가 다음과 같을 때,
<h3><a href="../../../its-only-the-himalayas_981/index.html" title="It's Only the Himalayas">It's Only the Himalayas</a></h3>
a 태그의 title 속성 값에 접근하기 위한 코드는 다음과 같다.
soup.find("h3").a["title"]특정 id를 활용하여 태그 찾기
id가 results인 div 태그를 찾기 위한 코드는 다음과 같다. soup은 BeautifulSoup 객체이다.
soup.find("div", id="results")특정 class를 활용하여 태그 찾기
class가 page-header인 div 태그를 찾기 위한 코드는 다음과 같다. 특정 id를 활용하여 찾을 때와 달리 파라미터명을 지정하지 않아도 된다.
soup.find("div", "page-header")BeautifulSoup 실습
해당 사이트에서 질문 목록을 스크래핑하는 실습을 진행하겠다.
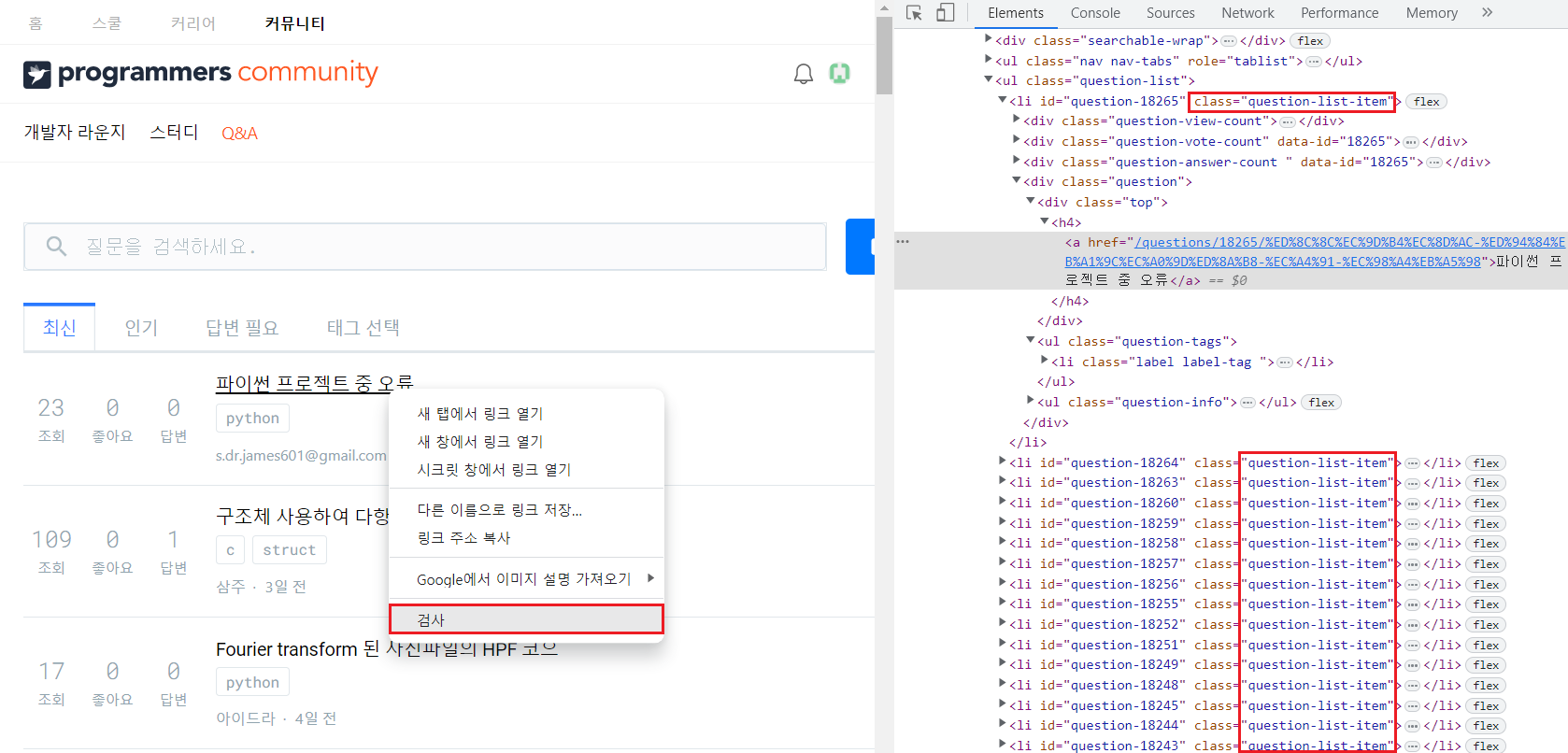
우선 질문 제목의 검사창을 통해 개발자 도구를 쉽게 띄울 수 있다. html 내용을 살펴보면 각 질문이 li 태그의 question-list-item class에 속해 있는 것을 확인할 수 있다. 그리고 해당 태그 내부에 질문 제목이 속해있는 것을 확인할 수 있다. 따라서 li 태그의 question-list-item class를 활용하여 스크래핑을 진행하면 된다는 결론을 도출할 수 있다.
스크래핑을 위해 사이트에 요청을 할 때, http header에 User-Agent를 추가하여 보낼 수 있다. 사이트 마다 User-Agent 필드가 비어있으면 봇으로 인식하여 원하는 결과를 반환하지 않는 경우가 있기 때문에 스크래핑을 할 때는 해당 필드를 채워서 보내는 것이 좋다. 해당 링크에서 나의 User-Agent 정보를 확인할 수 있다.
다음은 첫 번째 페이지에 있는 질문 목록을 출력하는 코드이다.
import requests
from bs4 import BeautifulSoup
# header에 넣을 자신의 User-Agent 정보
user_agent = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/112.0.0.0 Safari/537.36"}
# 요청 시, get 메서드 두 번째 인자에 헤더 정보를 넣을 수 있는데, 이 때 User-Agent 값을 넘겨줄 수 있음
res = requests.get("https://qna.programmers.co.kr/", user_agent)
# 응답을 바탕으로 BeautifulSoup 객체를 생성
soup = BeautifulSoup(res.text, "html.parser")
questions = soup.find_all("li", "question-list-item")
for question in questions:
print(question.find("div", "question").find("div", "top").h4.text)
위 예제에서 첫 번째 페이지에 있는 질문 목록을 출력하는 코드를 작성해 보았다. 하지만 대부분의 웹 사이트는 페이지네이션(Pagination)을 통해 일정 개수의 데이터만 보여주기 때문에 모든 질문 목록이 필요한 경우, 위의 예제는 제대로 수행할 수 없다.
각 페이지마다 질문 목록을 받아오는 코드는 다음과 같다.
import time
for i in range(1, 6): # 1-5 페이지
res = requests.get("https://qna.programmers.co.kr/?page={}".format(i), user_agent)
soup = BeautifulSoup(res.text, "html.parser")
questions = soup.find_all("li", "question-list-item")
for question in questions:
print(question.find("div", "question").find("div", "top").h4.text)
time.sleep(0.5) # 과도한 요청 방지를 위해 0.5초마다 호출
혹시 import request 에서 request가 없다고 나오는데 따로 라이브러리를 설치 해야 하나요?