
Elasticsearch 다운로드 및 실행 파일 생성하기
이번 글에서는 Elasticsearch와 Kibana를 다운받고 실행시키는 방법을 다뤄보겠다. 이전에 구축했던 리눅스 환경에서 Elasticsearch를 설치하고 실행시켜 보겠다. 다음의 링크를 통해 다운 받을 수 있다. 다운받길 원하는 버전이 있다면 해당 버전으로 다운받으면 된다. 해당 글에서는 Elasticsearch와 Kibana 둘다 7.17.0 버전을 활용하겠다.
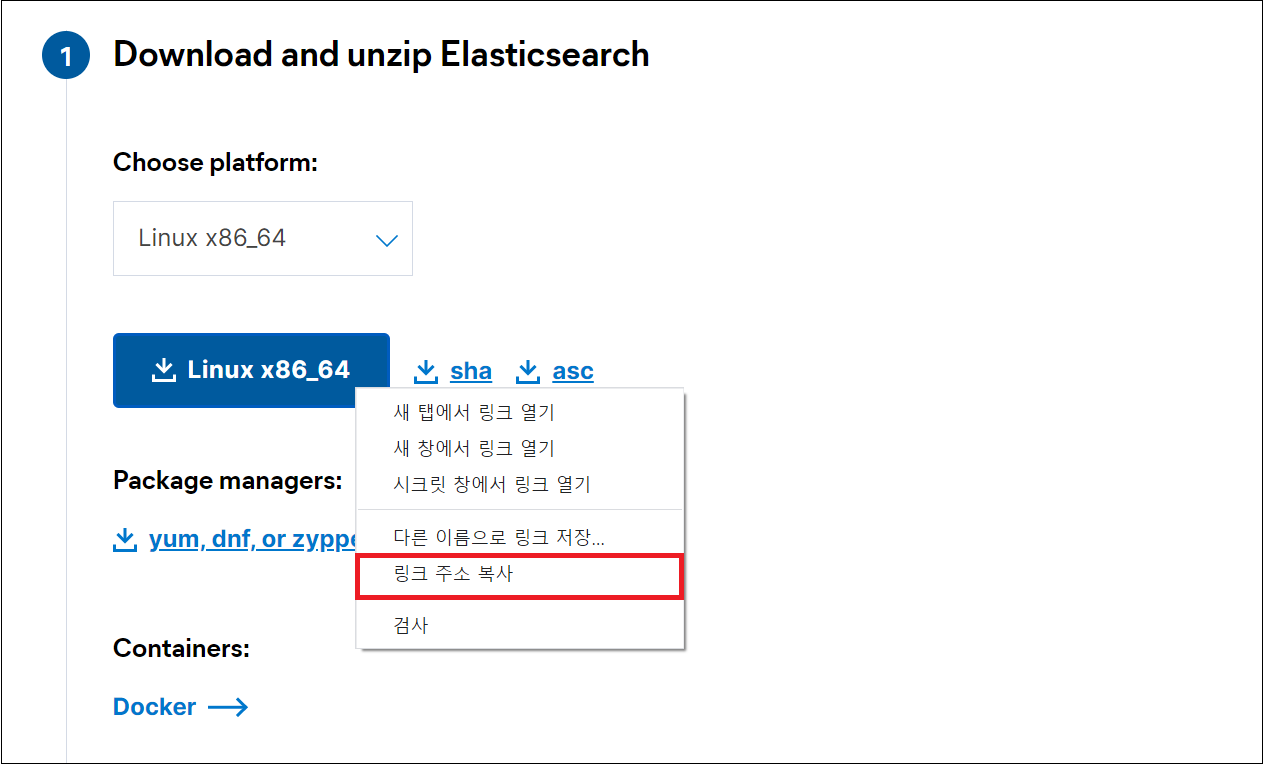
리눅스 환경에 설치할 것이기 때문에 플랫폼을 Linux x86_64로 지정하고 링크 주소를 복사한다.
이제 리눅스 환경에서 Elasticsearch를 설치하기 위해서 wget 명령어를 사용해야한다. 만약 wget 명령어를 사용할 수 없다면 (인스턴스를 Cent OS로 생성 했기 때문에)yum 명령어를 사용하여 설치해야한다.
sudo yum install wget
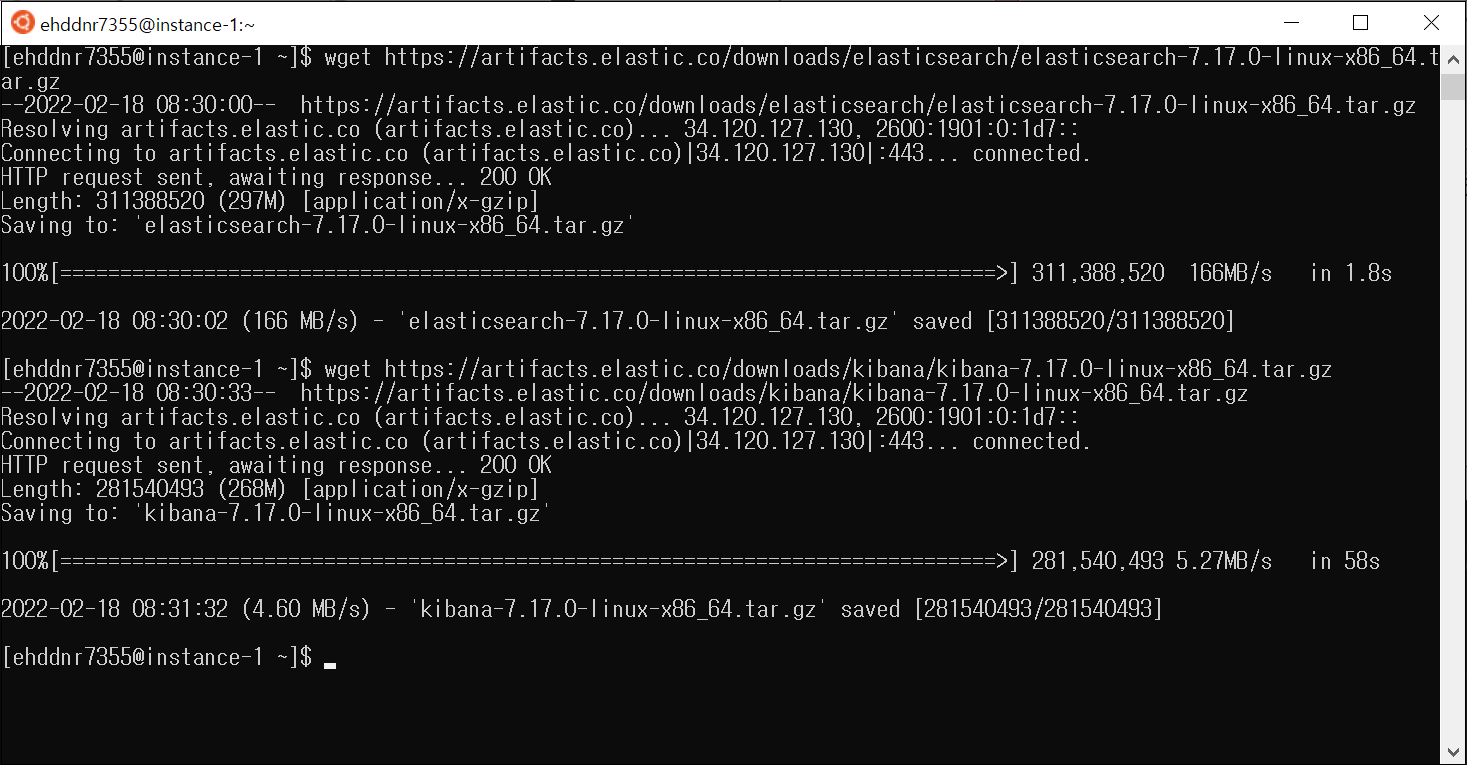
다음과 같이 wget 명령어와 함께 복사한 주소로 Elasticsearch를 다운 받는다. 해당 링크를 통해 Kibana도 다운받는다. 참고로 같은 버전의 Elasticsearch와 Kibana를 다운 받아야한다.
다운받은 파일의 압축을 풀어야 한다. 압축을 풀기 위해서 다음의 명령어를 입력해야 한다.
tar xfz elasticsearch-7.17.0-linux-x86_64.tar.gz
tar xfz kibana-7.17.0-linux-x86_64.tar.gz
이제 Elasticsearch를 실행시켜보겠다. Elasticsearch를 실행시키기 위해서 cd 명령어로 elasticsearch-7.17.0 내부로 이동해야 한다.
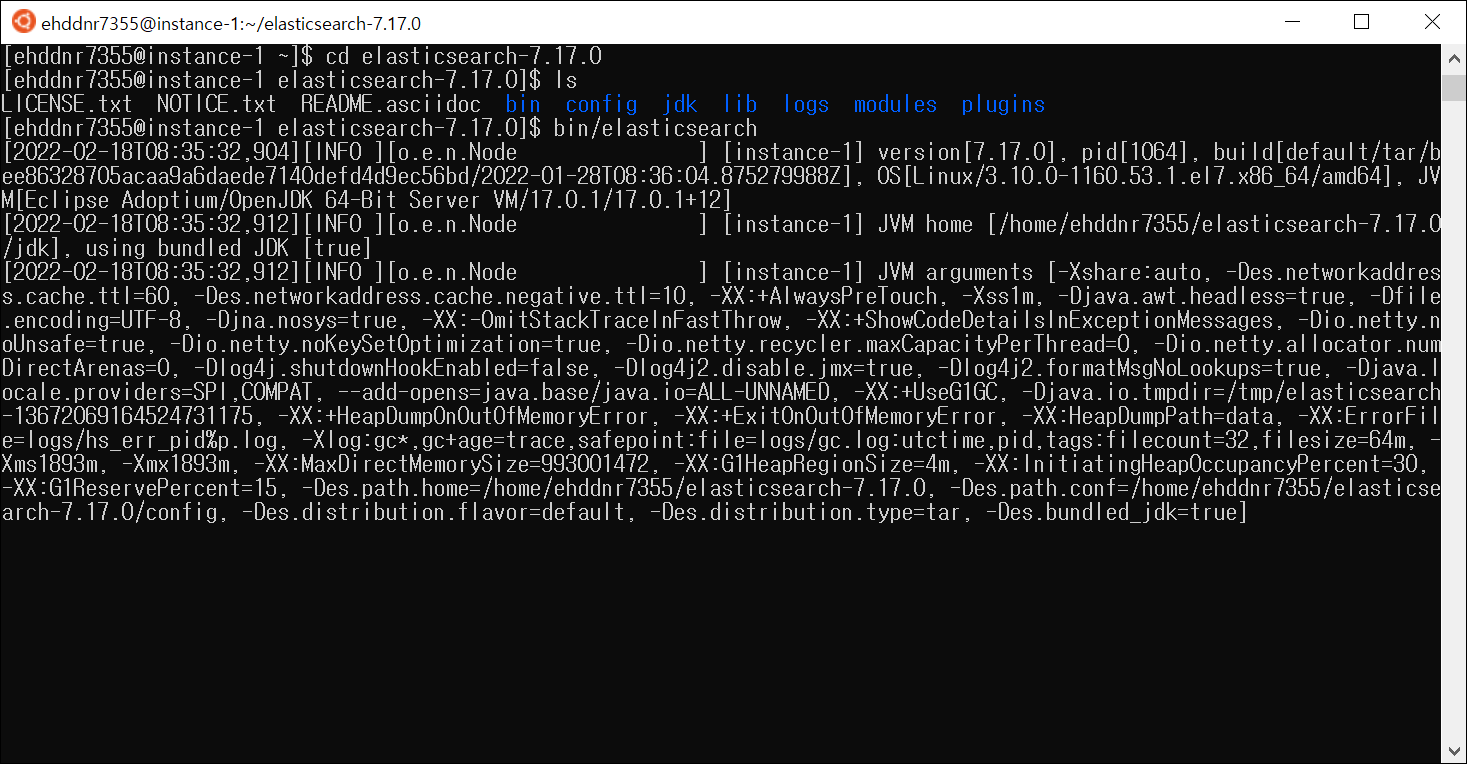
Elasticsearch 실행파일은 bin 디렉토리 아래에 있다. 따라서 bin/elasticsearch 명령어를 입력하면 Elasticsearch가 실행된다.
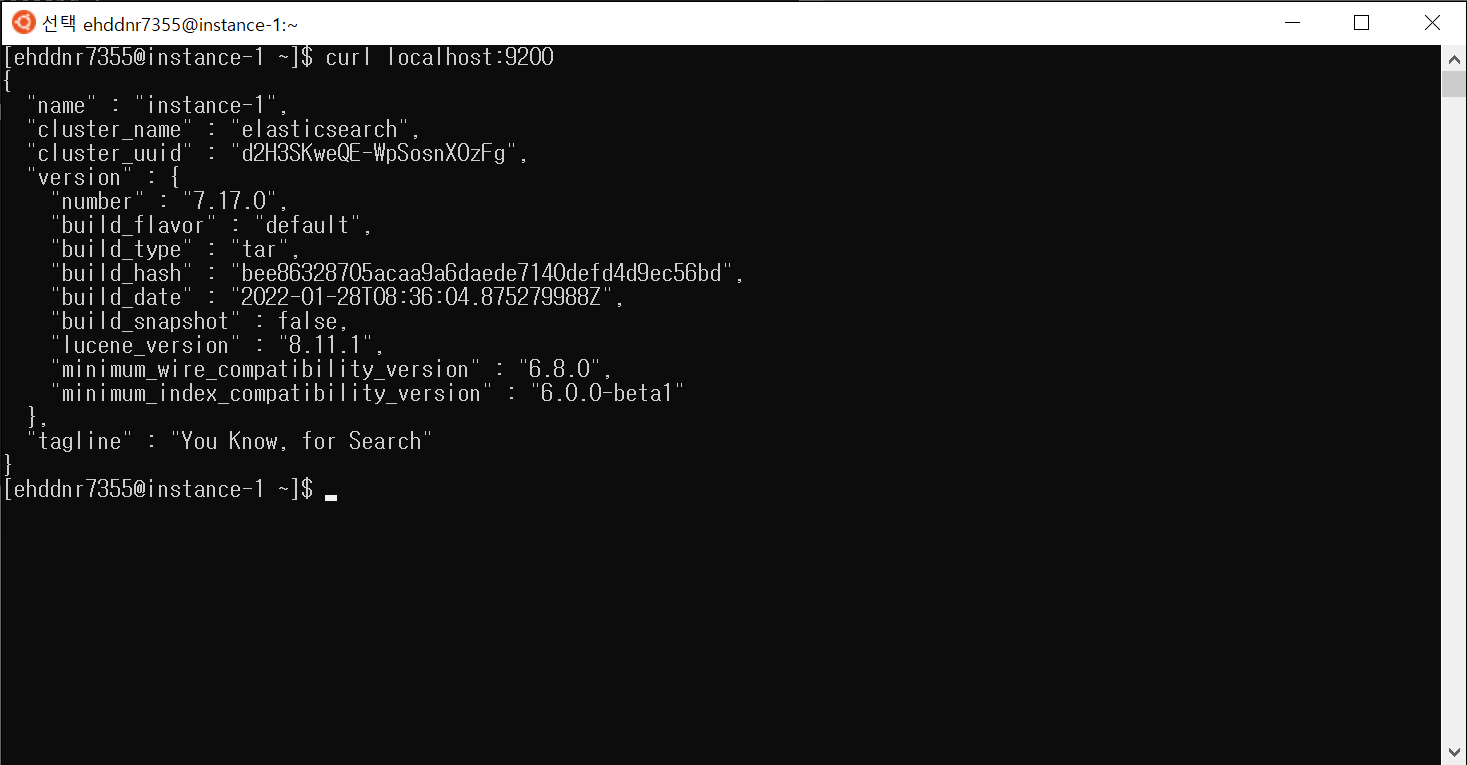
새로운 콘솔을 띄워 curl 명령어로 접근해보자. 포트 번호는 9200번으로 입력해야 한다. 위와 같은 화면이 나오면 Elasticsearch가 정상적으로 실행된 것이다. 참고로 Ctrl+c를 누르면 실행 중인 프로세스를 중단할 수 있다.
만약 elasticsearch를 실행 시킬 때 -d 옵션으로 실행 시키다면 데몬으로 실행 돼 백그라운드에서 실행된다. -p 옵션은 실행 중인 프로세스 번호를 지정한 파일에 저장 후 프로세스가 종료되면 자동으로 삭제된다. 여기서 실행 되는 내용을 확인하고 싶다면 tail 명령어를 사용하면 된다. (tail은 파일의 뒷 부분을 보여주는 명령어이고, -f 명령어는 실시간으로 업데이트 되는 내용을 보여주는 옵션)
bin/elasticsearch -d -p <파일명>
tail -f logs/(클러스터 명).log
다음은 데몬으로 실행되고 있는 elasticsearch를 종료하기 위한 방법이다. ps -ef 명령어로 실행중인 elasticsearch 프로세스 번호를 찾은 후, kill 명령어로 종료하면 된다.
ps -ef | grep elasticsearch
kill (프로세스 번호)
하지만 위와 같은 방법으로 프로세스 종료를 위해 매번 프로세스 번호를 찾고 종료하는 방법은 매우 번거롭다. 따라서 프로세스 시작과 종료를 위한 파일을 만들어 활용하면 번거로움을 줄일 수 있다. 해당 명령어는 elasticsearch-7.17.0 내부에서 실행한다.

vi start.sh : elasticsearch 프로세스 실행을 위한 파일
bin/elasticsearch -d -p <파일명> : elasticsearch 프로세스 실행을 위한 명령어
vi stop.sh : elasticsearch 프로세스 종료를 위한 파일
killcat es.pid: elasticsearch 프로세스 종료를 위한 명령어
이렇게 만든 파일은 읽기, 쓰기 권한만 있고 실행 권한은 없다. 따라서 실행을 위해선 권한 변경을 해야한다. 권한 변경을 위해서 다음 명령어를 입력하자.
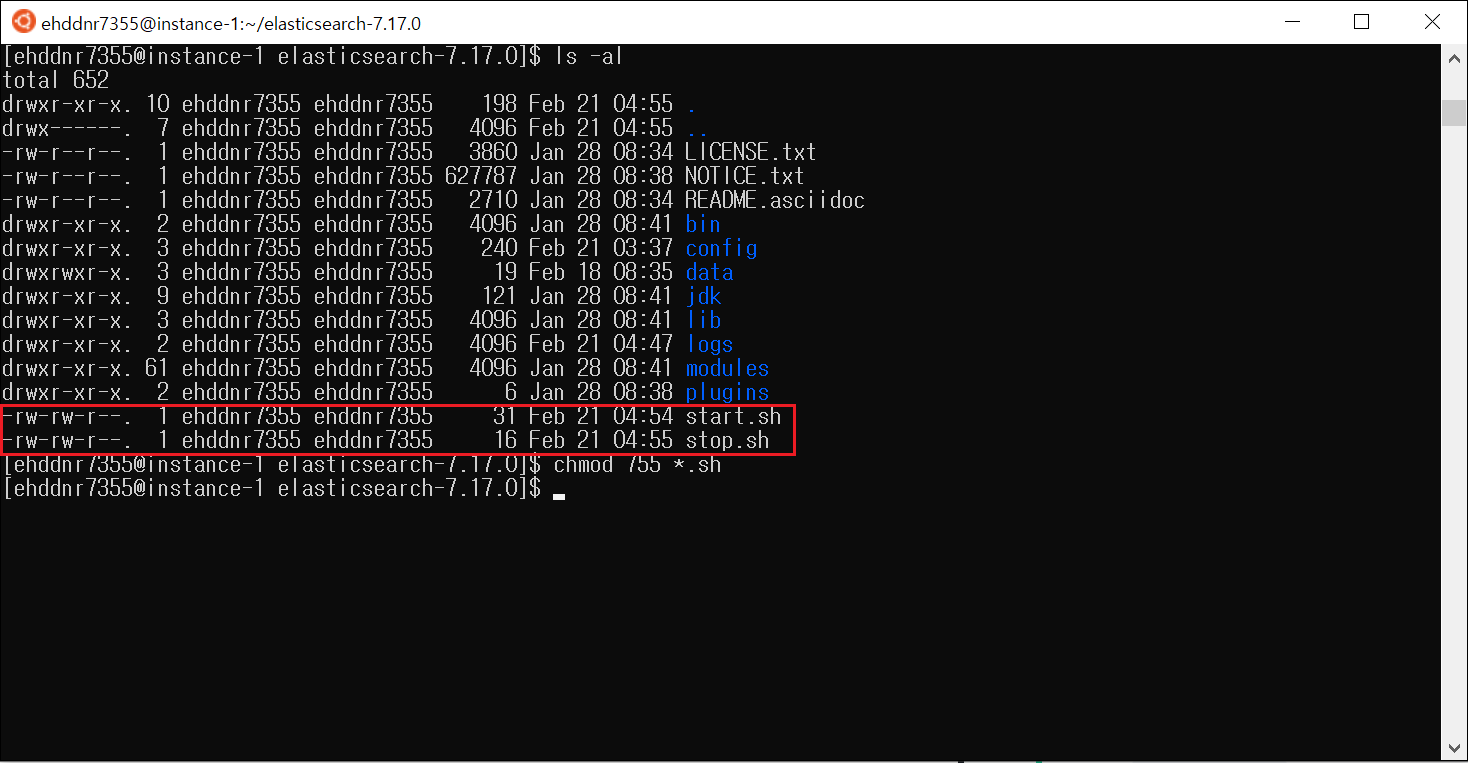
chmod 755 *.sh : 확장자가 .sh인 파일 권한을 755로 바꿔준다는 의미
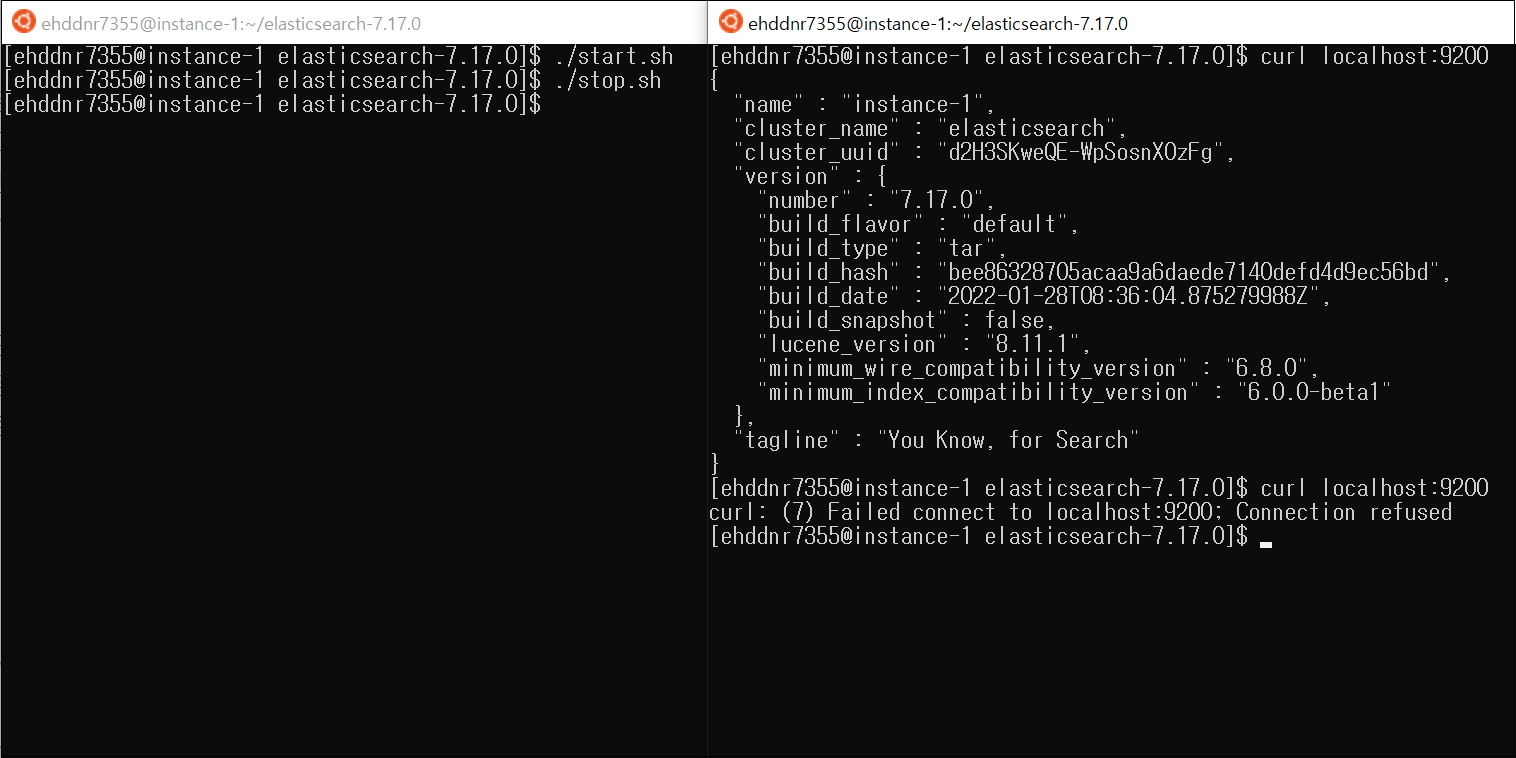
만들었던 start.sh 파일을 실행 시키면 elasticsearch가 정상적으로 실행 되는 것을 확인할 수 있고, stop.sh 파일을 실행시키면 프로세스가 정상적으로 종료된 것을 확인할 수 있다.
Elasticsearch 환경 설정
Elasticsearch 환경 설정 파일들은 config 디렉토리 아래에 있다. 대표적인 환경 설정 파일들과 역할은 다음과 같다
jvm.option : elasticsearch가 사용할 Java 힙메모리 크기 및 환경변수
elasticsearch.yml : Elasticsearch 옵션
log4j2.properties : 로그 관련 옵션
elasticsearch.yml 파일 내의 몇 가지 설정들을 살펴보자. config 디렉토리 내에서 vi 명령어로 접근해야 한다.
cluster.name : 해당 노드가 속한 클러스터의 이름
node.name : 해당 노드 이름
path.data : 데이터를 저장하는 경로
path.logs : 로그 데이터를 저장하는 경로
network.host : default는 로컬에서만 접근 가능, 변경 시 외부에서도 접근 가능
http.port : 기본값은 9200이지만, 실제 운영환경에서는 바꿔주는 편이 안전
discovery.seed_hosts : 다른 호스트를 찾을 필요한 네트워크 주소
cluster.initial_master_nodes : 여러 노드들 중 마스터 노드가 될 후보 노드
bootstrap.memory_lock : elasticsearch가 사용중인 힙메모리 영역을 다른 자바프로그램이 간섭 못하도록 하는 설정
또한 Elasticsearch를 처음 실행할 때 -E 옵션을 통해 클러스터 이름과 노드 이름을 지정하여 실행 시킬 수 있다. 이 방식으로 실행 시키는 것이 elasticsearch.yml보다 우선순위가 높기 때문에 이름이 변경되어 실행된다.
bin/elasticsearch -E cluster.name=my-cluster -E node.name="새로운 노드 이름"
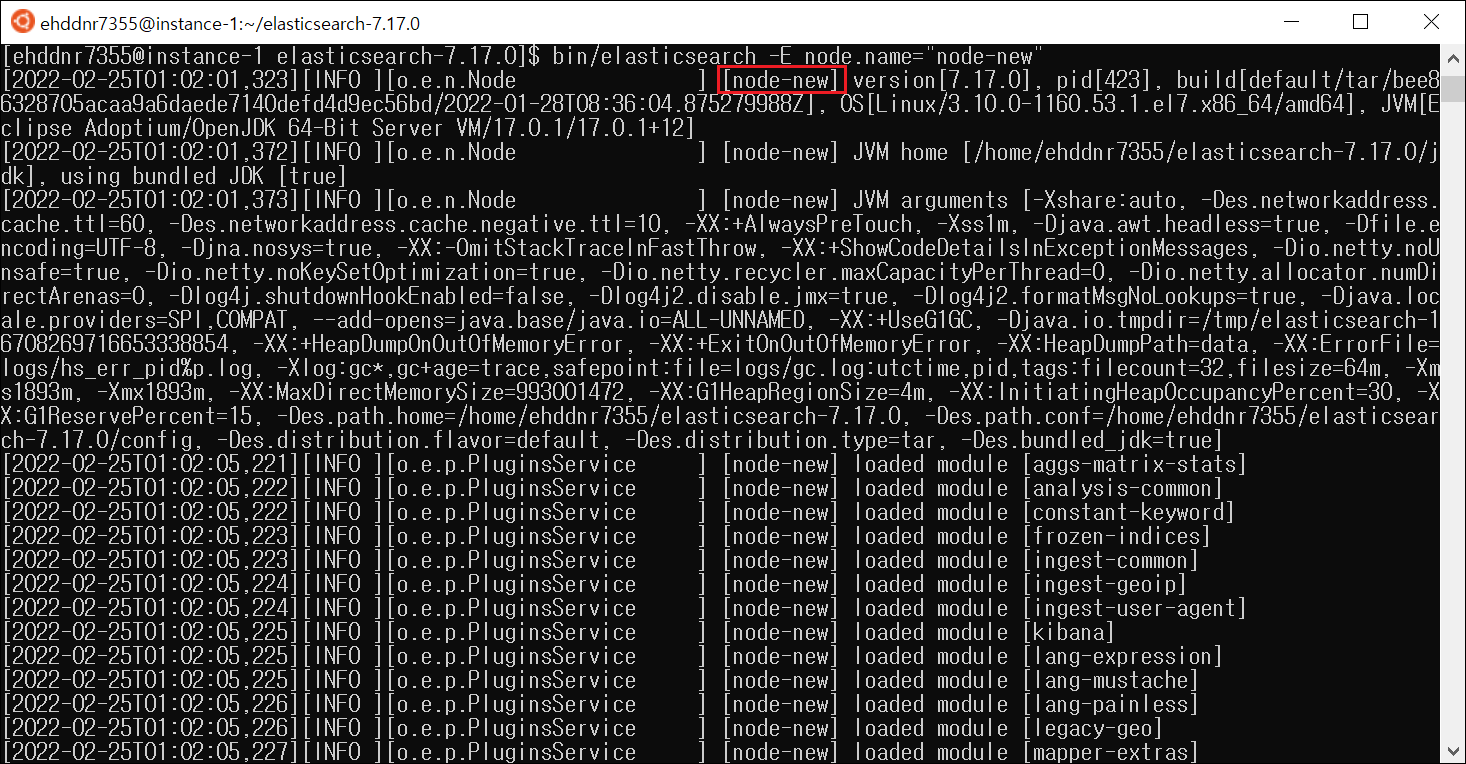
-E 옵션을 통해 노드 이름을 변경 후 실행 시킨 결과, 지정한 노드 이름으로 바뀌어 실행 된 것을 확인할 수 있다.
참고
한국 Elastic 사용자 그룹, 처음부터 시작하는 Elastic, https://www.youtube.com/watch?v=Ks0P49B4OsA&list=PLhFRZgJc2afp0gaUnQf68kJHPXLG16YCf
