HTML 디버깅 (Debugging HTML)
디버깅, 전혀 두렵지 않아요! (Debugging isn't scary)
어떤 종류의 코드든 작성할 때는 보통 순조롭게 진행되죠. 하지만 에러가 발생하는 그 끔찍한 순간이 오기 전까지는요! 여러분이 무언가를 잘못 작성해서 코드가 아예 작동하지 않거나, 의도한 대로 동작하지 않는 상황 말이에요. 예를 들어, 아래 이미지는 Rust라는 프로그래밍 언어로 작성된 간단한 프로그램을 컴파일(compile)하려고 할 때 보고된 에러를 보여주고 있어요.

여기서 에러 메시지는 비교적 이해하기 쉬워요. "unterminated double quote string (종료되지 않은 큰따옴표 문자열)"이라고 친절하게 알려주고 있거든요. 코드를 자세히 보면 println!(Hello, world!"); 부분에서 논리적으로 큰따옴표 하나가 빠져있다는 걸 아마 눈치채셨을 거예요. 하지만 프로그램의 규모가 커질수록 에러 메시지는 금방 복잡해지고 해석하기 어려워질 수 있어요. 심지어 이렇게 간단한 경우라도 Rust에 대해 전혀 모르는 사람에게는 조금 위압적으로 보일 수 있답니다.
하지만 디버깅을 너무 두려워할 필요는 없어요! 어떤 코드든 편안하게 작성하고 디버깅하기 위한 핵심 열쇠는, 바로 그 언어와 관련 도구들에 익숙해지는 것이니까요.
💡 강사의 팁! > 프론트엔드 개발자로 기술 면접을 볼 때, 문제 해결 능력(디버깅)은 정말 중요한 평가 요소예요. "에러를 만났을 때 어떻게 접근하나요?"라는 질문은 면접 단골 질문이기도 합니다. 에러 메시지를 꼼꼼히 읽고, 원인을 논리적으로 추적하는 습관을 들이는 것이 좋습니다.
HTML과 디버깅 (HTML and debugging)
다행히도 HTML은 Rust만큼 이해하기 복잡하지 않아요. HTML은 파싱(parsing, 구문 분석)되기 전에 다른 형태로 컴파일되지 않습니다. (HTML은 컴파일되는 것이 아니라 해석(interpreted)된답니다). 게다가 HTML의 요소(Element) 문법은 Rust나 JavaScript, Python 같은 "진짜 프로그래밍 언어"들보다 훨씬 이해하기 쉽다고 할 수 있죠.
브라우저가 HTML을 파싱하는 방식은 대부분의 프로그래밍 언어들이 파싱되는 방식보다 훨씬 더 관대(permissive)합니다. 이는 장점이 되기도 하지만, 동시에 단점이 되기도 해요.
그런데 먼저, 관대하다는 게 무슨 뜻일까요? 일반적으로 여러분이 코드에서 무언가 잘못했을 때, 크게 두 가지 주요 에러 유형을 만나게 될 거예요:
- 구문 에러 (Syntax errors): 앞서 본 Rust 에러처럼 프로그램이 아예 실행되지 않게 만드는 코드 상의 오타나 문법 오류입니다. 언어의 문법에 익숙하고 에러 메시지가 의미하는 바를 안다면 보통 고치기 쉽습니다.
- 논리 에러 (Logic errors): 구문 자체는 맞아서 프로그램이 실행은 되지만, 코드가 여러분이 의도한 대로 작동하지 않는 에러입니다. 이런 에러는 문제의 원인을 직접적으로 가리키는 에러 메시지가 없기 때문에 구문 에러보다 고치기가 훨씬 까다로운 경우가 많아요.
HTML 자체는 브라우저가 매우 관대하게 파싱하기 때문에 구문 에러로 인해 화면이 멈추는 일은 겪지 않아요. 즉, 소스 코드에 구문 에러가 있더라도 페이지는 여전히 화면에 표시된다는 뜻이죠! 브라우저에는 잘못 작성된 HTML 마크업(흔히 유효하지 않거나(invalid) 형식을 갖추지 못한(badly-formed) 마크업이라고 부릅니다)을 어떻게 해석할지에 대한 규칙이 내장되어 있어서, 이를 자동으로 유효한 마크업으로 수정해 줍니다.
예를 들어, 아래의 HTML 스니펫은 요소들이 잘못 중첩되어 있어요:
<p>I didn't expect to find the <em>next-door neighbor's <strong>cat</em></strong> here!</p>닫는 </strong> 태그는 닫는 </em> 태그보다 앞에 있어야 하지만, 지금은 뒤에 위치해 있죠.
이 HTML을 브라우저에 불러온 다음 렌더링된 DOM을 살펴보면, 브라우저가 알아서 중첩을 올바르게 고쳐놓은 것을 확인할 수 있어요:
<p>
I didn't expect to find the
<em>next-door neighbor's <strong>cat</strong></em> here!
</p>이게 왜 장점이자 단점일까요? 음, 이 경우에는 브라우저가 의도했던 결과를 잘 만들어주었지만, 나중에 보시게 되겠지만 항상 그런 것은 아니에요. 어떻게든 화면에 무언가를 띄워주긴 하겠지만, 브라우저가 항상 여러분의 의도를 완벽하게 파악하는 것은 아니기 때문에 예상치 못한 레이아웃 문제나 버그를 일으킬 수 있습니다. 따라서 처음부터 올바른 마크업을 작성하는 것이 훨씬 좋아요.
참고: HTML이 관대하게 파싱되는 이유는, 초창기 웹이 만들어졌을 때 문법이 완벽하게 정확한지 확인하는 것보다 콘텐츠를 널리 발행하고 공유하는 것이 더 중요하다고 판단했기 때문이에요. 만약 웹이 처음부터 너무 엄격했다면, 아마 지금처럼 대중적으로 성공하지 못했을지도 몰라요.
💡 강사의 팁! 추가 보충 설명 > 프론트엔드 개발자로서 React.js나 Next.js 같은 모던 라이브러리/프레임워크를 다루게 되실 텐데요. 이때 이 "관대한 HTML 파싱"이 큰 적이 될 수 있어요! 서버에서 렌더링한 HTML과 브라우저가 관대하게 자동 수정해버린 HTML 구조가 다르면, 유명한 Hydration 에러가 발생합니다. 예를 들어,
<p>태그 안에<div>를 넣는 등 웹 표준에 어긋나는 마크업을 하면 브라우저는 이걸 강제로 쪼개버리거든요. 그래서 항상 표준에 맞는 올바른 HTML을 작성하는 습관이 중요합니다.
그렇다면 마크업 에러는 어떻게 찾을 수 있을까요? 나중에 HTML 검사기(HTML validator)라는 도구를 사용해 에러를 찾는 방법을 보여드릴 거지만, 먼저 DOM 검사기를 사용해 HTML을 수동으로 점검하는 방법을 알아보고, 브라우저가 이런 마크업 에러들을 어떻게 해석하는지 살펴볼게요.
DOM 검사기 사용하기 (Using the DOM inspector)
모든 최신 브라우저에는 개발자 도구 (devtools)가 내장되어 있습니다. 이 도구들은 현재 탭에 로드된 웹페이지를 검사할 수 있는 다양한 기능을 제공해요. 페이지에 렌더링된 HTML이 무엇인지, 각 DOM 노드에 어떤 CSS가 적용되었는지, 어떤 JavaScript가 실행 중인지 등을 보여줍니다. 또한 실행 중인 코드를 직접 수정하고 그 결과가 페이지에 실시간으로 반영되는 것도 볼 수 있죠.
각 브라우저에서 개발자 도구를 여는 방법은 비슷합니다. 자세한 방법은 브라우저에서 개발자 도구 여는 방법을 참고해 주세요.
이 글에서 우리가 살펴볼 핵심 기능은 DOM 검사기입니다. 현재 렌더링된 HTML DOM을 보여주고 수정할 수 있게 해주는 기능이에요. 자, 한번 살펴볼까요?
- 브라우저에서 개발자 도구를 엽니다.
- DOM 검사기를 엽니다. 각 브라우저에서 위치는 같습니다. 개발자 도구의 첫 번째 탭이죠. Firefox에서는 Inspector(검사기)라고 되어 있고, Safari, Edge, Chrome에서는 Elements(요소)라고 되어 있습니다. 개발자 도구를 열었을 때 기본적으로 선택되어 있을 텐데, 만약 아니라면 직접 선택해 주세요.
- 탭에 표시된 DOM 트리 구조를 살펴보고, 각 DOM 노드 앞의 작은 확장 화살표를 클릭해 노드를 펼치거나 접어서 자식 노드들을 확인할 수 있다는 점을 눈여겨보세요. 키보드의 위/아래 방향키로 노드를 이동하고, 좌/우 방향키로 노드를 펼치고 접을 수도 있습니다.
- 노드 위에 마우스를 올려보거나(또는 방향키로 선택해 보면서) 뷰포트(화면)에서 해당 요소가 어떻게 하이라이트(강조 표시)되는지 관찰해 보세요.
- 렌더링된 DOM을 직접 수정할 수도 있어요! 이 글에서 편집 기능을 직접 사용하진 않겠지만, 궁금하시다면 어떻게 하는지 한 번 찾아보시는 것도 추천합니다.
직접 해보기: DOM 검사기로 HTML 살펴보기 (Your turn: Studying HTML using the DOM inspector)
이 섹션에서는 DOM 검사기를 사용해 코드를 살펴보고, 브라우저가 흔한 마크업 에러들을 어떻게 처리하는지 직접 확인해 볼 거예요.
- 먼저, 아래의 HTML 코드 리스팅을 복사해서 로컬 컴퓨터 어딘가에
debug-example.html이라는 이름으로 저장해 주세요. 이 데모 코드는 우리가 직접 살펴볼 수 있도록 고의적으로 에러를 포함시켜 두었습니다.
<!doctype html>
<html lang="en-US">
<head>
<meta charset="utf-8">
<title>HTML debugging examples</title>
</head>
<body>
<h1>HTML debugging examples</h1>
<p>What causes errors in HTML?
<ul>
<li>Unclosed elements: If an element is <strong>not closed properly,then its effect can spread to areas you didn't intend
<li>Badly nested elements: Nesting elements properly is also very important for code behaving correctly. <strong>strong <em>strong emphasized?</strong> what is this?</em>
<li>Unclosed attributes: Another common source of HTML problems. Let's look at an example: <a href="[https://www.mozilla.org/](https://www.mozilla.org/)>link to Mozilla homepage</a>
</ul>
</body>
</html>-
이제 저장한 파일을 브라우저에서 열어보세요. 아래 이미지와 비슷하게 보일 겁니다.

-
한눈에 봐도 뭔가 상태가 영 안 좋아 보이죠? 소스 코드를 보면서 이유를 파악해 볼까요? (body 내용만 가져왔습니다):
<h1>HTML debugging examples</h1>
<p>What causes errors in HTML?
<ul>
<li>Unclosed elements: If an element is <strong>not closed properly,
then its effect can spread to areas you didn't intend
<li>Badly nested elements: Nesting elements properly is also very important
for code behaving correctly. <strong>strong <em>strong emphasized?</strong>
what is this?</em>
<li>Unclosed attributes: Another common source of HTML problems. Let's
look at an example: <a href="[https://www.mozilla.org/](https://www.mozilla.org/)>link to Mozilla
homepage</a>
</ul>-
문제점들을 하나씩 짚어보겠습니다:
- 단락(
p)과 목록 항목(li) 요소들에 닫는 태그가 없습니다. 위 화면 결과를 보면, 요소가 어디서 끝나고 시작되는지 브라우저가 나름대로 쉽게 유추할 수 있었기 때문에 화면 렌더링에 아주 심각한 영향을 주진 않은 것 같네요. - 첫 번째
<strong>요소에 닫는 태그가 없습니다. 이건 좀 더 골치 아픈 문제예요. 요소가 도대체 어디서 끝나야 하는지 알 수 없기 때문이죠. 사실상 그 아래에 있는 모든 텍스트가 전부 굵은 글씨로 렌더링되어 버렸습니다. - 이 부분은 중첩이 잘못되었습니다:
<strong>strong <em>strong emphasized?</strong> what is this?</em>. 이전의<strong>태그가 닫히지 않은 문제와 겹쳐서 브라우저가 이걸 도대체 어떻게 해석했는지 예측하기가 쉽지 않네요. href속성값에 닫는 큰따옴표가 빠져 있습니다. 이 부분이 가장 큰 문제를 일으킨 것 같아요. 링크가 아예 렌더링되지도 않았거든요!
- 단락(
-
이제 소스 코드 말고, 렌더링된 DOM을 직접 확인해 봅시다. 브라우저의 DOM 검사기를 열어주세요. 렌더링된 마크업의 실제 구조가 보일 겁니다.

-
브라우저가 우리의 엉망진창인 HTML 에러를 어떻게 '수정(fix)'하려고 시도했는지 관찰해 보세요. (우리는 Firefox에서 확인했지만, 다른 최신 브라우저들도 동일한 결과를 보여줄 거예요):
- 단락과 목록 항목들에 브라우저가 임의로 닫는 태그를 넣어주었습니다.
- 첫 번째
<strong>요소가 어디서 닫혀야 하는지 불분명했기 때문에, 브라우저는 문서 맨 끝까지 이어지는 각각의 독립된 텍스트 블록들을 모두 별도의<strong>요소로 감싸버렸습니다! - 잘못된 중첩은 브라우저에 의해 아래와 같이 수정되었습니다:
<strong>
strong
<em>strong emphasized?</em>
</strong>
<em> what is this?</em>- 닫는 큰따옴표가 빠진 링크는 아예 흔적도 없이 삭제되어 버렸습니다. 마지막 목록 항목은 결국 이렇게 렌더링되었네요:
<li>
<strong>
Unclosed attributes: Another common source of HTML problems. Let's look
at an example:
</strong>
</li>HTML 유효성 검사 (HTML validation)
위 예제를 통해 HTML을 올바른 형식(well-formed)으로 작성하는 것이 얼마나 중요한지 확실히 느끼셨을 거예요! 하지만 어떻게 검증할 수 있을까요? 방금 본 것처럼 작은 예제 코드라면 코드를 한 줄씩 훑어보며 에러를 찾는 게 쉽겠지만, 거대하고 복잡한 HTML 문서라면 어떨까요?
이럴 때 사용하는 도구가 바로 마크업 검사 서비스(Markup Validation Service) (또는 HTML 검사기)입니다. 이 도구는 (웹 표준 모델에서 배우셨을) W3C에서 만들고 유지보수하는 도구예요. 검사기에 HTML 문서를 입력하면, 문서를 쭉 분석한 뒤 HTML의 어떤 부분이 잘못되었는지 리포트로 알려줍니다.

검사할 HTML을 지정하는 방법은 웹 주소(URL)를 입력하거나, HTML 파일을 직접 업로드하거나, HTML 코드를 직접 복사해서 붙여넣는 방법이 있습니다.
HTML 문서 유효성 검사하기 (Validating an HTML document)
이번 실습에서는 HTML 검사기를 직접 사용해 보겠습니다. 아까 작성했던 샘플 문서의 유효성을 검사하고 어떤 결과가 나오는지 확인해 볼 거예요. 앞서 DOM 검사기로 함께 분석했던 바로 그 코드입니다.
- 먼저, 새 브라우저 탭을 열어 마크업 검사 서비스에 접속해 주세요.
- 상단 탭에서 Validate by Direct Input (직접 입력으로 검사) 탭을 선택합니다.
- 샘플 문서의 코드 전체(body 태그 안의 내용뿐만 아니라 전체 구조 모두)를 복사해서 검사기 화면의 넓은 텍스트 영역에 붙여넣습니다.
- Check(검사) 버튼을 누르세요.
그러면 에러 목록과 유용한 정보들이 나타날 겁니다!
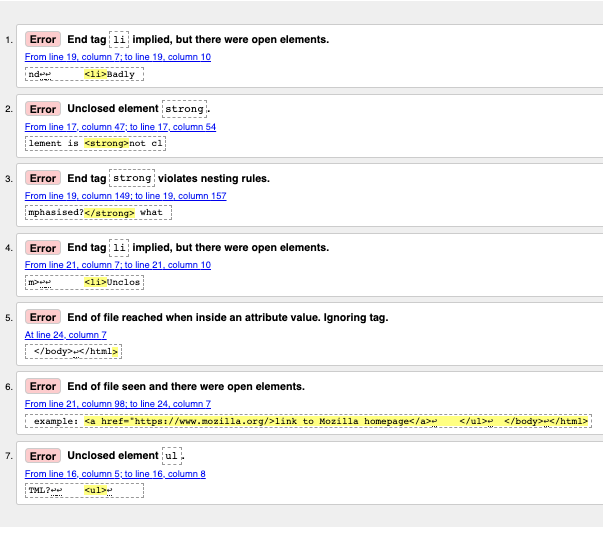
에러 메시지 해석하기 (Interpreting the error messages)
에러 메시지들은 보통 매우 유용하지만, 가끔은 한 번에 이해하기 어려울 때도 있습니다. 약간의 연습만 거치면 이 메시지들을 해석해서 코드를 고치는 방법을 터득하실 수 있을 거예요. 자, 에러 메시지들을 하나씩 살펴보면서 무슨 뜻인지 알아봅시다. 각 메시지에는 에러 위치를 쉽게 찾을 수 있도록 줄(line) 번호와 칸(column) 번호가 함께 제공됩니다.
-
"End tag
liimplied, but there were open elements (2 instances)" (2번 발생): 이 메시지는 닫혀야 할 요소가 열려 있다는 것을 의미해요. 닫는 태그가 문맥상 있어야 하지만 실제로 존재하지 않는다는 뜻이죠. 줄/칸 정보는 원래 닫는 태그가 있었어야 할 곳의 바로 다음 줄을 가리키고 있지만, 이 정도 힌트만으로도 어디가 잘못되었는지 파악하기엔 충분합니다. -
"Unclosed element
strong": 이건 훨씬 이해하기 쉽죠.<strong>요소가 닫히지 않았다는 뜻이며, 줄/칸 정보가 그 정확한 위치를 콕 집어 알려줍니다. -
"End tag
strongviolates nesting rules": 잘못 중첩된 요소들을 지적하는 에러입니다. 역시 위치를 함께 알려줍니다. -
"End of file reached when inside an attribute value. Ignoring tag": 이건 좀 난해하게 들릴 수 있는데요. 어딘가에 속성값이 제대로 닫히지 않았고, 그 상태에서 문서가 끝나버렸다는 뜻입니다. (속성값 따옴표가 닫히지 않은 채로 파일의 끝을 맞이했기 때문이죠). 앞서 브라우저가 링크를 아예 렌더링하지 않았던 것을 떠올려보면, 어떤 요소가 문제인지 좋은 힌트를 얻을 수 있습니다.
-
"End of file seen and there were open elements": 이 메시지도 약간 모호하지만, 기본적으로 아직 제대로 닫히지 않은 요소들이 열려 있는 채로 문서가 끝났다는 것을 의미합니다. 줄 번호는 파일의 마지막 몇 줄을 가리키고 있으며, 열려 있는 요소의 예시를 친절하게 코드 스니펫으로 보여줍니다:
example: <a href="https://www.mozilla.org/>link to Mozilla homepage</a> ↩ </ul>↩ </body>↩</html>참고: 속성에 닫는 따옴표가 빠져 있으면, 그 뒤에 나오는 문서 내용 전체가 속성값의 내용물로 해석되어 버리기 때문에 열린 요소(open element) 문제를 야기할 수 있습니다.
-
"Unclosed element
ul": 이건 별로 도움이 안 되는 메시지네요. 왜냐하면 사실<ul>요소는 제대로 닫혀 있거든요! 이 에러는 닫는 따옴표가 누락되어<a>요소가 제대로 파싱되지 않고 닫히지도 못했기 때문에, 연쇄적으로 발생한 오해일 뿐입니다.
💡 강사의 팁! > 모든 에러 메시지의 의미를 한 번에 완벽히 이해하지 못한다고 해서 너무 걱정하지 마세요. 가장 좋은 전략은 한 번에 몇 개의 에러만 수정한 뒤, 다시 유효성 검사(Revalidate)를 돌려보는 것입니다. 가끔은 가장 위에 있는 근본적인 에러 하나를 고치면, 도미노처럼 연결되어 있던 다른 에러 메시지들이 마법처럼 한 번에 사라지기도 하니까요!
모든 에러를 다 고치고 나면, 보고할 에러가 없다는 귀여운 초록색 배지를 보게 될 거예요. (글 작성 시점 기준으로는 "Document checking completed. No errors or warnings to show." 라고 나옵니다.) 뿌듯한 순간이죠!
