안녕하세요! 프론트엔드 개발자라면 반드시 짚고 넘어가야 할 웹의 통신 기반, HTTP의 세계에 오신 것을 환영합니다! 🎉
오늘은 웹사이트의 성능을 좌우하는 아주 핵심적인 주제인 HTTP/1.x의 연결 관리(Connection management)에 대해 배워보겠습니다. 웹 브라우저가 서버와 어떻게 연결을 맺고 끊는지, 그리고 과거부터 지금까지 성능을 끌어올리기 위해 어떤 꼼수(?)와 기술들이 도입되었는지 이해하면 프론트엔드 개발자로서 성능 최적화에 대한 시야가 확 트이실 거예요.
공식 문서의 내용을 빠짐없이 친절한 구어체로 번역하면서, 실무에서 마주칠 수 있는 상황과 강사의 꿀팁도 듬뿍 추가해 두었으니 꼼꼼히 읽어보세요! 자, 출발해 볼까요?
HTTP/1.x의 연결 관리 (Connection management in HTTP/1.x)
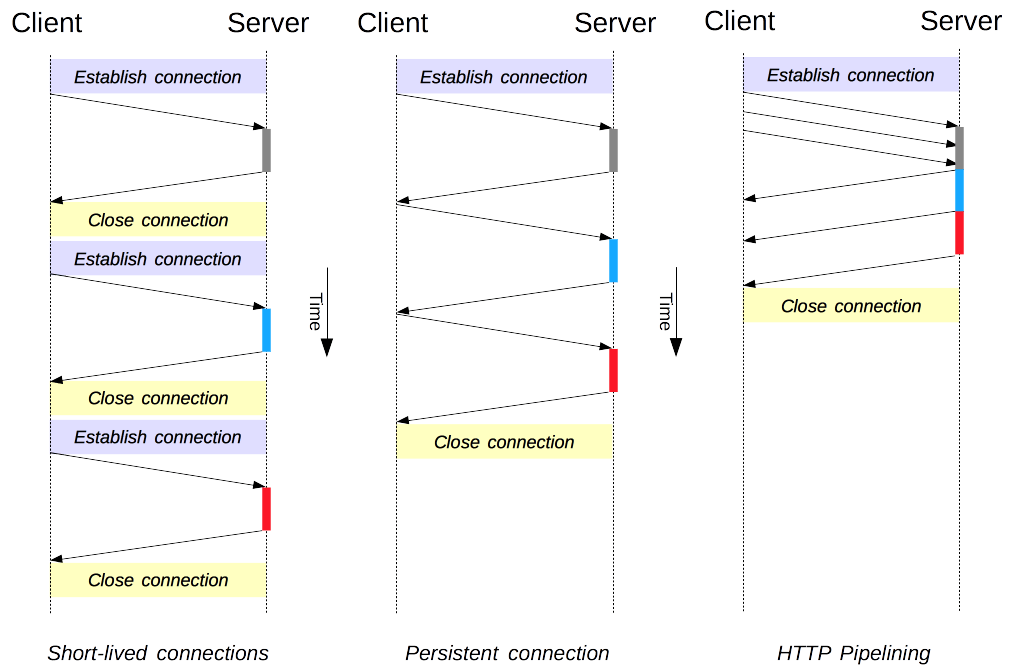
연결 관리(Connection management)는 HTTP에서 아주 핵심적인 주제입니다. 연결을 열고 유지하는 방식은 웹사이트와 웹 애플리케이션의 성능에 어마어마한 영향을 미치거든요. HTTP/1.x 버전에는 크게 세 가지 모델이 존재합니다: 단기 연결(short-lived connections), 지속 연결(persistent connections), 그리고 HTTP 파이프라이닝(HTTP pipelining)입니다.
HTTP는 클라이언트와 서버 사이의 연결을 제공하기 위해 전송 프로토콜로 주로 TCP에 의존합니다. HTTP가 처음 태어났을 무렵에는, 이런 연결을 다루는 방식이 단 한 가지뿐이었습니다. 바로 단기 연결(short-lived connections) 이었죠. 요청을 보내야 할 때마다 매번 새로운 연결을 생성하고, 서버로부터 응답을 받으면 즉시 연결을 닫아버리는 모델이었습니다.
하지만 이 모델은 성능상 근본적인 한계를 가지고 있었습니다. TCP 연결을 매번 새로 여는 작업 자체가 서버와 클라이언트의 자원을 꽤 많이 소모하는 무거운 작업(resource-consuming operation)이거든요. 연결을 맺기 위해 클라이언트와 서버 간에 여러 번의 메시지가 오가야만 합니다. 결국 요청을 보낼 때마다 네트워크 지연(latency)과 대역폭의 영향을 정통으로 받게 되는 것이죠. 요즘의 현대적인 웹 페이지들은 필요한 정보를 다 보여주기 위해 수십 개 이상의 엄청나게 많은 요청을 필요로 하는데, 이 초기 모델을 그대로 쓰기엔 너무 비효율적이었습니다.
💡 강사의 부연 설명!
위에서 말하는 '연결을 열 때 오가는 여러 번의 메시지'가 바로 네트워크 시간에 자주 듣게 되는 TCP 3-Way Handshake(3방향 핸드셰이크)입니다. "나 너한테 데이터 보내도 돼?", "응, 보내도 돼. 나도 너한테 보내도 돼?", "응, 보내!" 이 세 번의 인사를 나누는 데만 해도 꽤 많은 시간(RTT, Round Trip Time)이 낭비되거든요. 이미지 100장을 받으려고 이 인사를 100번 한다고 생각해보세요. 끔찍하죠?
그래서 HTTP/1.1에서는 두 가지 새로운 모델이 만들어졌습니다. 지속 연결(persistent-connection) 모델은 연속적인 요청들 사이에도 연결을 계속 열어두어, 새 연결을 여는 데 필요한 시간을 아껴줍니다. 한 걸음 더 나아간 HTTP 파이프라이닝(HTTP pipelining) 모델은 응답을 기다리지도 않고 연속해서 여러 요청을 쏟아붓듯 보내버려서 네트워크 지연을 획기적으로 줄여줍니다.
참고 (Note):
HTTP/2에서는 연결 관리를 위한 또 다른 새롭고 강력한 모델들(예: 멀티플렉싱)이 추가되었습니다.
여기서 꼭 기억해야 할 중요한 점이 하나 있습니다. HTTP의 연결 관리는 처음부터 끝까지(클라이언트에서 최종 서버까지) 통짜로 적용되는 종단 간(end-to-end) 방식이 아니라, 중간에 거치는 각각의 노드들 사이에서만 유효한 홉-바이-홉(hop-by-hop) 방식이라는 것입니다.
즉, 클라이언트와 첫 번째 프록시 서버 사이에서 사용하는 연결 모델이, 그 프록시와 최종 목적지 서버(또는 중간의 다른 프록시들) 사이에서 사용하는 연결 모델과 다를 수도 있다는 뜻이에요. 연결 모델을 정의하는 데 관련된 Connection이나 Keep-Alive 같은 HTTP 헤더들은 홉-바이-홉 헤더이기 때문에, 중간 노드(프록시 등)가 그 값을 마음대로 변경할 수도 있습니다.
이와 관련된 또 다른 주제로 HTTP 연결 업그레이드(HTTP connection upgrades)라는 개념이 있습니다. 이는 HTTP/1.1 연결을 TLS/1.0, WebSocket, 또는 평문 HTTP/2 같은 아예 다른 프로토콜로 업그레이드하는 과정을 말합니다. 이 프로토콜 업그레이드 메커니즘에 대해서는 다른 문서에 더 자세히 기록되어 있습니다.
단기 연결 (Short-lived connections)
HTTP의 가장 오리지널 모델이자 HTTP/1.0의 기본값이었던 모델이 바로 단기 연결(Short-lived connections)입니다. 각각의 HTTP 요청은 자기 자신만을 위한 독립적인 연결 위에서 완료됩니다. 이 말은 곧 각각의 HTTP 요청이 출발하기 전에 무조건 TCP 핸드셰이크가 일어나야 하며, 요청들이 순차적으로 직렬화(serialized)되어 처리된다는 뜻입니다.
TCP 핸드셰이크 자체도 시간을 많이 잡아먹지만, TCP라는 프로토콜의 특성상 네트워크 부하에 적응하는 시간이 필요해서 연결이 어느 정도 유지되고 데이터가 지속해서 오갈 때(이른바 '따뜻해진(warm) 연결' 상태일 때) 더 효율적으로 동작하도록 설계되어 있습니다.
하지만 단기 연결은 TCP의 이러한 효율성 향상 기능을 전혀 활용하지 못합니다. 매번 갓 태어난 '차가운(cold)' 새 연결 위에서 데이터를 전송하길 고집하기 때문에, 최적의 상태에 비해 성능이 뚝뚝 떨어지게 됩니다.
이 모델은 HTTP/1.0에서 기본으로 사용되는 모델입니다. (Connection 헤더가 아예 없거나, 그 값이 close로 설정된 경우입니다). HTTP/1.1 버전에서는 오직 Connection 헤더가 close라는 값으로 전송되었을 때만 이 단기 연결 모델이 사용됩니다.
참고 (Note):
지속 연결(persistent connection)을 아예 지원하지 못할 정도로 옛날 아주 먼 옛날 시스템을 다루는 게 아니라면, 오늘날 이 단기 연결 모델을 굳이 사용할 만한 설득력 있는 이유는 전혀 없습니다.
지속 연결 (Persistent connections)
단기 연결은 두 가지 큰 걸림돌이 있었죠. 새로운 연결을 맺는 데 시간이 너무 오래 걸린다는 것, 그리고 기반이 되는 TCP 연결이 좀 오랫동안 사용되어야만('따뜻한 연결') 제 성능이 나온다는 점이었습니다. 이 문제들을 완화하기 위해, 심지어 HTTP/1.1이 나오기도 전부터 지속 연결(persistent connection)이라는 개념이 고안되었습니다. 다른 말로는 keep-alive 연결이라고 부르기도 해요.
지속 연결은 한 번 맺은 연결을 일정 시간 동안 열어둔 채로 유지하면서 여러 개의 요청을 처리하는 데 재사용하는 방식입니다. 덕분에 매번 새로운 TCP 핸드셰이크를 할 필요가 없어지고, TCP의 성능 향상 기능(점진적으로 전송 속도를 높이는 기능 등)을 온전히 활용할 수 있게 되죠.
물론 이 연결이 영원히 열려있는 것은 아닙니다. 오고 가는 데이터 없이 아무것도 안 하는(idle) 연결은 일정 시간이 지나면 서버에 의해 닫히게 됩니다. (서버는 연결을 최소한 얼마나 열어둘지 명시하기 위해 Keep-Alive 헤더를 사용할 수 있습니다.)
하지만 지속 연결에도 단점은 있습니다. 아무것도 안 하고 유휴 상태(idling)로 대기하고 있을 때조차 서버의 소중한 자원(메모리 등)을 갉아먹는다는 점이죠. 그래서 서버에 부하가 심할 때 연결을 계속 열어두면 DoS(서비스 거부) 공격에 노출될 위험이 커집니다. 그런 극단적인 부하 상황에서는 차라리 할 일이 끝나자마자 칼같이 연결을 닫아버리는 비-지속(non-persistent) 연결을 사용하는 것이 오히려 더 나은 성능을 제공할 수도 있습니다.
HTTP/1.0에서는 기본적으로 연결이 지속되지 않습니다. 연결을 유지하려면 Connection 헤더를 close가 아닌 다른 값, 보통은 retry-after 같은 값으로 명시적으로 설정해 주어야 지속 연결이 되었습니다.
하지만 HTTP/1.1에서는 이 지속 연결(Persistence)이 아예 기본값(default)이 되었습니다! 그래서 더 이상 연결 유지를 위한 헤더가 필수는 아니지만, 혹시나 서버나 프록시가 HTTP/1.0으로 동작할 경우를 대비해 방어적인 차원에서(fallback) Connection: keep-alive 헤더를 여전히 추가하는 경우가 많습니다.
💡 강사의 실무 TIP!
실무에서 프론트엔드 개발자가 Node.js나 Nginx 같은 서버를 세팅할 일이 생겼을 때, 무작정Keep-Alive시간을 길게 잡는 건 위험합니다. 예를 들어 쇼핑몰 이벤트 오픈 시간에 사용자가 몰리는데, 모든 사용자와의 연결을 60초씩 열어둔다고 상상해 보세요. 서버의 커넥션 풀(Connection Pool)이 꽉 차서 정작 새로 들어오려는 유저들은 접속조차 못하고 사이트가 뻗어버릴 수 있어요! 보통 5초~10초 사이로 짧고 효율적으로 튜닝하는 것이 관건입니다.
HTTP 파이프라이닝 (HTTP pipelining)
참고 (Note):
HTTP 파이프라이닝은 현대의 최신 브라우저들에서는 기본적으로 비활성화되어 있습니다. 그 이유는 다음과 같습니다:
- 버그가 많은 구형 프록시(proxies)들이 여전히 인터넷 곳곳에 많이 남아있는데, 얘네들이 파이프라이닝을 만나면 웹 개발자가 예측하거나 디버깅하기 매우 힘든 이상하고 기괴한 오류들을 뿜어냅니다.
- 파이프라이닝을 완벽하게 구현하는 것 자체가 엄청 복잡합니다. 전송되는 리소스의 크기, 실제 네트워크의 왕복 지연 시간(RTT), 사용 가능한 대역폭 등 수많은 변수들이 파이프라인의 성능 개선 폭에 직접적인 영향을 미칩니다. 이런 걸 제대로 파악하지 못하면, 별로 안 중요한 메시지들 뒤에 진짜 중요한 메시지가 꽉 막혀서 지연되는 불상사가 일어납니다. 심지어 페이지 렌더링 도중에도 어떤 리소스가 더 중요한지 수시로 바뀌거든요! 그래서 파이프라이닝은 고생한 것에 비해 대부분의 경우 아주 미미한 성능 향상만을 가져왔습니다.
- 파이프라이닝은 구조상 HOL 블로킹(Head-of-line blocking) 이라는 치명적인 문제에 시달립니다.
이러한 이유들 때문에 파이프라이닝은 결국 버려졌고, HTTP/2에서 도입된 멀티플렉싱(multiplexing)이라는 훨씬 우월한 알고리즘으로 완벽하게 대체되었습니다.
💡 강사의 부연 설명!
방금 언급된 HOL 블로킹(Head-of-Line blocking)이 뭘까요? 1차선 도로에 차들이 일렬로 달리고 있다고 상상해 보세요. 맨 앞에 있는 덤프트럭(첫 번째 요청)이 고장 나서 멈춰버리면, 그 뒤에 있던 빠르고 작은 스포츠카(이후의 가벼운 요청들)들도 꼼짝없이 멈춰 서서 기다려야만 합니다. 파이프라이닝은 요청을 순서대로 쏟아붓긴 하지만, 응답은 반드시 서버가 요청을 받은 순서대로 순차적으로 보내야 한다는 규칙 때문에 앞선 응답 처리가 오래 걸리면 뒤의 응답들이 전부 막혀버리는 치명적인 약점이 있었답니다.
기본적으로 HTTP 요청은 순차적으로(sequentially) 발생합니다. 현재 보낸 요청에 대한 응답을 완전히 받아야만 그다음 요청을 보낼 수 있죠. 이 방식은 네트워크 지연(latency)이나 대역폭 제한의 영향을 받기 때문에, 서버 입장에서 볼 때 다음 요청을 확인하기까지 상당한 딜레이가 발생하게 됩니다.
파이프라이닝(Pipelining)은 이렇게 기다리는 낭비를 없애기 위해, 하나의 동일한 지속 연결(persistent connection) 위에서 이전 응답을 기다리지 않고 연속적인 요청들을 다다닥 쏘아 보내는 기술입니다. 덕분에 연결 대기 시간(latency)을 피할 수 있죠.
이론적으로는 두 개의 HTTP 요청이 하나의 TCP 메시지 안에 꽉꽉 압축되어 들어가면 성능이 더 향상될 수도 있습니다. 보통 전송 가능한 최대 크기인 MSS (Maximum Segment Size)는 간단한 요청 여러 개를 담기에 충분히 크거든요. (물론 요즘 HTTP 요청의 크기 자체도 점점 비대해지고 있긴 하지만요.)
주의할 점은, 모든 종류의 HTTP 요청을 파이프라이닝 할 수 있는 건 아니라는 사실입니다. 오직 부작용이 없는 멱등성을 가진(idempotent) 메서드들, 즉 GET, HEAD, OPTIONS, TRACE, PUT, DELETE 등만 안전하게 재시도할 수 있기 때문에 파이프라이닝이 가능합니다. 중간에 실패하더라도 파이프라인의 내용을 그냥 통째로 다시 반복(replay)하면 되니까요.
오늘날 모든 HTTP/1.1 호환 프록시와 서버는 이론상 파이프라이닝을 지원해야 마땅하지만, 현실에서는 수많은 제한 사항들을 겪고 있습니다. 이게 바로 최신 브라우저들이 이 기능을 기본값으로 켜두지 않는 가장 결정적인 이유입니다.
도메인 샤딩 (Domain sharding)
참고 (Note):
지금 당장 어쩔 수 없이 아주 특수한 상황에 처한 게 아니라면, 이 오래된 폐기(deprecated) 기술은 절대 사용하지 마세요! 대신 HTTP/2로 넘어가세요. HTTP/2 환경에서 도메인 샤딩은 아무런 쓸모가 없습니다. HTTP/2는 하나의 연결만으로도 병렬로 우선순위 없이 날아오는 수많은 요청을 기가 막히게 잘 처리하거든요. 오히려 HTTP/2에서 도메인 샤딩을 쓰면 성능을 갉아먹는 독이 됩니다. 대부분의 HTTP/2 구현체들은 혹시 모를 도메인 샤딩의 폐해를 되돌리기 위해 연결 병합(connection coalescing) 이라는 기술을 사용하기까지 합니다.
앞서 살펴봤듯 HTTP/1.x 연결은 요청을 일렬로 세워(serializing) 처리하기 때문에, 대역폭이 아무리 빵빵하게 남아돌더라도 병목 현상이 생겨 최적의 속도를 낼 수가 없었습니다.
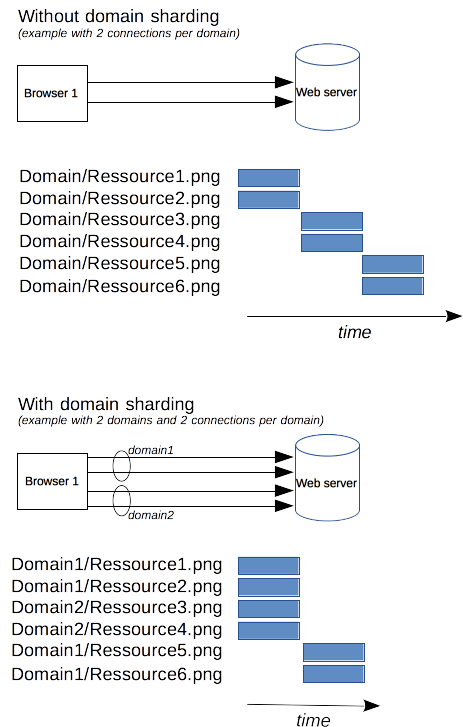
이걸 해결하기 위한 '꼼수'로, 브라우저들은 아예 한 도메인당 여러 개의 TCP 연결을 동시에 열어서 병렬로 요청을 보내는 방식을 택했습니다. 예전에는 도메인당 기본 2~3개 정도의 연결만 열었지만, 요즘은 보통 6개까지 병렬 연결을 여는 것이 일반적입니다. (물론 브라우저가 이 숫자를 무한정 늘리지 않는 이유는, 서버 쪽에서 공격(DoS)으로 오해하고 접속을 차단해 버릴 위험이 있기 때문입니다.)
그런데 만약 우리 웹사이트에 가져올 리소스가 수십 개인데 브라우저가 도메인당 6개씩밖에 연결을 안 맺어준다면?
서버 운영자 입장에서는 웹사이트 로딩 속도를 더 빠르게 만들기 위해 브라우저가 강제로 더 많은 연결을 열게끔 유도하고 싶을 겁니다. 그래서 등장한 기발한 방법이 바로 도메인 샤딩(Domain sharding)입니다.
예를 들어, 모든 이미지나 스크립트 리소스를 www.example.com 하나에 몰아두지 않고, www1.example.com, www2.example.com, www3.example.com 처럼 여러 도메인으로 쪼개서 분산시키는 겁니다. 사실 이 도메인들은 이름만 다를 뿐 결국 뒤에서는 똑같은 단일 서버를 바라보고 있습니다! 하지만 브라우저 입장에서는 "오, 서로 다른 도메인이네?"라고 생각하고 각각의 도메인마다 6개씩, 총 18개의 연결을 뻥 튀겨서 활짝 열게 되죠.
💡 강사의 실무 TIP!
예전 네이버나 다음과 같은 대형 포털 사이트 소스를 까보면 이미지를img1.daumcdn.net,img2.daumcdn.net처럼 숫자만 다른 여러 도메인에서 가져오는 걸 볼 수 있었어요. 그게 바로 이 도메인 샤딩의 흔적입니다!
하지만 윗부분의 Note에서도 경고했듯, 여러분이 HTTP/2를 지원하는 환경(요즘은 거의 다 지원하죠)에서 개발 중이라면 절대 이 꼼수를 쓰시면 안 됩니다! HTTP/2는 단 하나의 연결(Single Connection) 위에서 모든 요청을 병렬로 처리(멀티플렉싱)하는 게 핵심인데, 도메인을 강제로 쪼개면 브라우저가 불필요하게 TCP 핸드셰이크와 TLS 암호화 연결을 낭비하게 되어서 웹사이트가 오히려 더 느려지는 역효과가 납니다!
결론 (Conclusion)
연결 관리를 개선하는 것은 HTTP의 성능을 엄청나게 향상시키는 핵심입니다. HTTP/1.1 이나 HTTP/1.0 환경에서는 적어도 유휴 상태가 될 때까지만이라도 지속 연결(persistent connection)을 사용하는 것이 최고의 성능을 이끌어냅니다.
하지만 파이프라이닝(pipelining) 기술의 뼈아픈 실패는, 결국 그 한계를 극복하고 아예 근본부터 뜯어고친 훨씬 우월한 연결 관리 모델을 설계하게 만들었고, 그 결과물이 바로 오늘날 우리가 사용하는 HTTP/2 랍니다.
함께 보기 (See also)
더 깊이 있는 학습을 원하신다면 아래 MDN 문서들을 확인해 보세요! (원본 영문 링크 기준입니다.)
- HTTP의 진화 (Evolution of HTTP)
- 용어 사전 (Glossary terms):
- HTTP
- HTTP/2
- QUIC (HTTP/3의 기반이 되는 프로토콜!)
- 왕복 지연 시간 (Round Trip Time, RTT)
- TCP 느린 시작 (TCP slow start)
- TLS (전송 계층 보안)
- 전송 제어 프로토콜 (TCP)
이 페이지는 MDN 기여자들에 의해 2025년 11월 19일에 마지막으로 수정되었습니다.
오늘 HTTP 연결 관리에 대한 역사와 원리를 쭉 훑어보셨는데 어떠셨나요? 네트워크 병목을 피하기 위해 선배 개발자들이 얼마나 치열하게 고민하고 꼼수(?)까지 써가며 최적화를 해왔는지 이해하셨다면 대성공입니다! 다음번엔 이 한계들을 모조리 박살 낸 HTTP/2의 멀티플렉싱에 대해서 공부해 보시는 걸 강력히 추천해 드립니다. 수고하셨습니다! 🚀
