안녕하세요! 오늘도 프론트엔드 역량을 탄탄히 다지기 위해 MDN 공식 문서를 깊이 있게 학습하시는 모습이 정말 멋집니다.
이번 주제는 '콘텐츠 협상(Content negotiation)'이네요. 실무에서 글로벌 서비스(다국어 지원)를 개발하거나, 브라우저가 지원하는 압축 방식(gzip, 브로틀리 등)에 맞춰 최적화된 데이터를 내려받을 때 등 웹의 보이지 않는 곳에서 정말 중요하게 작동하는 메커니즘입니다. 원문 내용 하나하나 놓치지 않고, 제 실무 경험을 담은 팁과 함께 구어체로 친절하게 번역해 드릴게요. 자, 시작해 볼까요?
콘텐츠 협상 (Content negotiation)
HTTP에서 콘텐츠 협상(content negotiation)은 동일한 URI에 대해 리소스의 다양한 표현(representations)을 제공하기 위해 사용되는 메커니즘입니다. 사용자 에이전트(주로 브라우저)가 사용자에게 가장 잘 맞는 표현(예를 들어 어떤 언어의 문서인지, 어떤 이미지 포맷인지, 어떤 콘텐츠 압축 방식을 사용할지 등)을 명시할 수 있도록 도와줍니다.
참고 (Note):
WHATWG의 위키 페이지에서 HTTP 콘텐츠 협상의 몇 가지 단점을 찾아보실 수 있습니다. HTML은 콘텐츠 협상을 대체할 수 있는 대안을 제공하는데요, 대표적으로<source>요소를 들 수 있습니다.
💡 강사의 팁:
<source>태그를 사용하면, 브라우저가 최신 이미지 포맷인WebP나AVIF를 지원하는지 확인하고 지원할 경우 해당 포맷을, 지원하지 않는 구형 브라우저라면JPEG나PNG를 다운로드하도록 프론트엔드 단에서 직접 '협상'을 대체할 수 있답니다. 요즘 실무에서 이미지 최적화를 할 때 정말 많이 쓰이는 기법이죠!
이 문서의 내용 (In this article)
- 콘텐츠 협상의 원리 (Principles of content negotiation)
- 서버 주도 콘텐츠 협상 (Server-driven content negotiation)
- 에이전트 주도 협상 (Agent-driven negotiation)
- 같이 보기 (See also)
콘텐츠 협상의 원리 (Principles of content negotiation)
특정한 문서를 리소스(resource)라고 부릅니다. 클라이언트가 리소스를 얻고자 할 때, 클라이언트는 URL을 통해 리소스를 요청합니다. 서버는 이 URL을 사용하여 사용 가능한 여러 변형(variant) 중 하나를 선택하는데요, 이 각각의 변형을 표현(representation)이라고 부릅니다. 그리고 이렇게 선택된 특정 표현을 클라이언트에게 반환하죠. 전체 리소스뿐만 아니라 각각의 표현들 역시 특정한 URL을 가지고 있습니다. 콘텐츠 협상은 리소스가 호출되었을 때 특정한 표현이 어떻게 선택되는지를 결정하는 과정입니다. 클라이언트와 서버 사이에서 협상을 하는 방법에는 몇 가지가 있습니다.
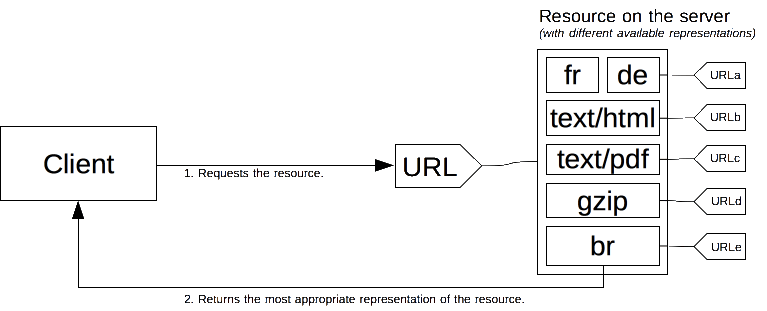
가장 적합한 표현은 다음 두 가지 메커니즘 중 하나를 통해 식별됩니다:
- 클라이언트가 보내는 특정한 HTTP 헤더를 이용하는 방식 (서버 주도 협상(server-driven negotiation) 또는 사전 협상(proactive negotiation)). 이것이 특정 종류의 리소스를 협상하는 표준적인 방법입니다.
- 서버가 보내는
300(Multiple Choices),406(Not Acceptable),415(Unsupported Media Type) 등의 HTTP 응답 코드를 이용하는 방식 (에이전트 주도 협상(agent-driven negotiation) 또는 사후 협상(reactive negotiation)). 이 방식은 주로 대체(fallback) 메커니즘으로 사용됩니다.
수년에 걸쳐 투명한 콘텐츠 협상(transparent content negotiation)이나 Alternates 헤더 같은 다른 콘텐츠 협상 방식들이 제안되기도 했습니다. 하지만 이들은 큰 호응을 얻지 못하고 결국 폐기되었습니다.
서버 주도 콘텐츠 협상 (Server-driven content negotiation)
서버 주도 콘텐츠 협상, 또는 사전 콘텐츠 협상(proactive content negotiation)에서는 브라우저(또는 다른 종류의 사용자 에이전트)가 URL과 함께 여러 개의 HTTP 헤더를 전송합니다. 이 헤더들은 사용자가 선호하는 선택지를 설명해 주죠. 서버는 이 헤더들을 힌트(힌트)로 삼아, 내부 알고리즘을 돌려 클라이언트에게 제공할 가장 좋은 콘텐츠를 선택합니다. 만약 적합한 리소스를 제공할 수 없다면, 서버는 406 (Not Acceptable)이나 415 (Unsupported Media Type) 응답을 보내고, 서버가 지원하는 미디어 타입에 대한 헤더를 설정할 수 있습니다 (예: POST나 PATCH 요청에 대해 각각 Accept-Post 또는 Accept-Patch를 사용). 이 알고리즘은 서버마다 다르며 표준에 명확히 정의되어 있지 않습니다. Apache의 협상 알고리즘을 참고해 보세요.
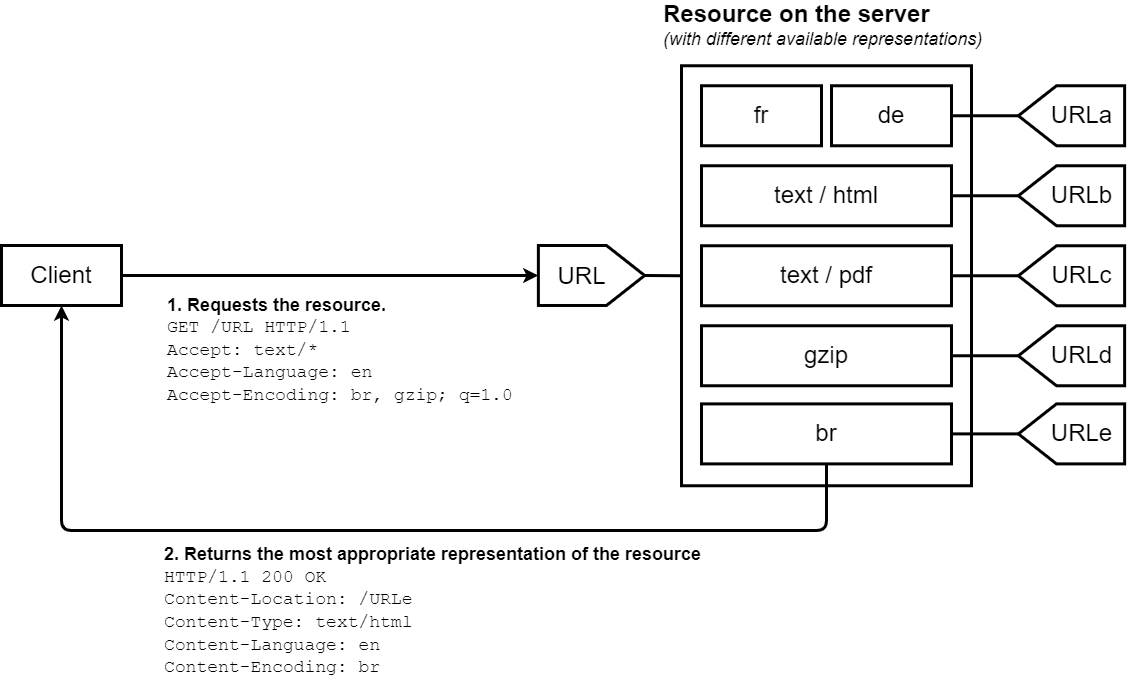
HTTP/1.1 표준은 서버 주도 협상을 시작하는 표준 헤더들의 목록을 정의하고 있습니다 (예: Accept, Accept-Encoding, Accept-Language 등). User-Agent는 이 목록에 없지만, 요청된 리소스의 특정 표현을 전송하기 위해 종종 사용되기도 합니다. 하지만 이는 항상 좋은 방법으로 여겨지지는 않습니다. 서버는 Vary 헤더를 사용하여 콘텐츠 협상 시 실제로 어떤 헤더(더 정확히는 그와 연관된 요청 헤더)를 사용했는지 알려줍니다. 이를 통해 캐시(caches)가 최적으로 작동할 수 있게 됩니다.
💡 강사의 팁:
Vary헤더는 프론트엔드 성능 최적화(CDN 캐싱 등)에서 매우매우 중요합니다! 만약 서버가 영어/한국어 문서를 제공하는데Vary: Accept-Language를 설정하지 않았다면, 캐시 서버(CDN)는 "어? 주소가 똑같네?" 하고 한국 유저에게 저장된 영어 페이지를 보여주는 참사가 발생할 수 있어요.Vary는 캐시 서버에게 "이 응답은 이 헤더값에 따라 다를 수 있으니 따로따로 저장해!"라고 알려주는 필수 설정입니다.
이 외에도 사용 가능한 헤더 목록에 헤더를 더 추가하려는 실험적인 제안이 있는데, 이를 클라이언트 힌트(client hints)라고 부릅니다. 클라이언트 힌트는 사용자 에이전트가 실행되고 있는 기기가 어떤 종류인지(예를 들어 데스크톱 컴퓨터인지 모바일 기기인지)를 알려줍니다.
서버 주도 콘텐츠 협상이 특정 리소스 표현에 동의하는 가장 흔한 방법이긴 하지만, 몇 가지 단점도 가지고 있습니다:
- 서버는 브라우저에 대한 완벽한 지식을 가지고 있지 않습니다. 심지어 Client Hints 확장을 사용하더라도 브라우저의 기능에 대해 전부 다 알 수는 없죠. 클라이언트가 직접 선택을 하는 사후(reactive) 콘텐츠 협상과 달리, 서버의 선택은 항상 어느 정도 임의적(arbitrary)일 수밖에 없습니다.
- 클라이언트가 보내는 정보가 꽤 장황하고(HTTP/2 헤더 압축이 이 문제를 어느 정도 완화해 주긴 합니다만), 개인정보 유출 위험(HTTP 핑거프린팅(fingerprinting))이 존재합니다.
- 주어진 리소스의 여러 표현들이 전송되기 때문에, 공유 캐시(shared caches)의 효율성이 떨어지고 서버 구현이 더 복잡해집니다.
Accept 헤더 (The Accept header)
Accept 헤더는 에이전트(브라우저)가 처리할 의향이 있는 미디어 리소스의 MIME 타입 목록을 나열합니다. 이 값은 쉼표(,)로 구분된 MIME 타입 목록이며, 각각의 타입은 서로 다른 MIME 타입 간의 상대적인 선호도를 나타내는 파라미터인 품질 계수(quality factor, q-factor)와 결합될 수 있습니다.
Accept 헤더는 브라우저나 다른 사용자 에이전트에 의해 정의되며, 상황(context)에 따라 달라질 수 있습니다. 예를 들어, HTML 페이지를 가져올 때와 이미지, 비디오, 또는 스크립트를 가져올 때가 다릅니다. 주소창에 입력해서 문서를 가져올 때와, <img>, <video>, 또는 <audio> 요소로 연결된 요소를 가져올 때의 값이 다르죠. 브라우저들은 자신들이 가장 적절하다고 생각하는 헤더 값을 자유롭게 사용할 수 있습니다. 일반적인 브라우저들의 기본 Accept 값 목록도 찾아볼 수 있습니다.
Accept-CH 헤더 (The Accept-CH header)
참고 (Note):
이것은 Client Hints라고 불리는 실험적인(experimental) 기술의 일부입니다. 초기 지원은 Chrome 46 이상부터 포함되었습니다. Device-Memory 값은 Chrome 61 이상부터 지원됩니다.
실험적인 Accept-CH 헤더는 서버가 적절한 응답을 선택하는 데 사용할 수 있는 설정 데이터 목록을 나열합니다. 유효한 값의 예시는 다음과 같습니다:
| 값 | 의미 |
|---|---|
Sec-CH-Device-Memory | 기기 RAM의 대략적인 용량을 나타냅니다. 이 값은 2의 거듭제곱으로 가장 가깝게 반올림한 뒤 1024로 나눈 근사치입니다. 예를 들어 512 메가바이트는 0.5로 보고됩니다. |
Sec-CH-Viewport-Width | 레이아웃 뷰포트(viewport)의 너비를 CSS 픽셀 단위로 나타냅니다. |
Sec-CH-Width | 리소스의 너비를 물리적 픽셀 단위로 나타냅니다 (즉, 이미지의 고유한/실제 크기). |
Accept-Encoding 헤더 (The Accept-Encoding header)
Accept-Encoding 헤더는 허용 가능한 콘텐츠 인코딩(지원하는 압축 방식)을 정의합니다. 값은 인코딩 값들의 우선순위를 나타내는 q-factor 목록(예: br, gzip;q=0.8)입니다. 별도의 언급이 없다면, 기본값인 identity(압축 안 함)가 가장 낮은 우선순위를 가집니다.
HTTP 메시지를 압축하는 것은 웹사이트의 성능을 향상시키는 가장 중요한 방법 중 하나입니다. 전송되는 데이터의 크기를 대폭 줄여주고 가용한 대역폭(bandwidth)을 훨씬 더 잘 활용하게 만들어 주죠. 브라우저는 항상 이 헤더를 전송하며, 서버는 압축을 사용하도록 설정되어 있어야 합니다.
💡 강사의 팁: 브라우저 개발자 도구 네트워크 탭에서 JS나 CSS 파일을 클릭해 보시면
Accept-Encoding: gzip, deflate, br이라는 헤더를 거의 항상 보실 수 있을 거예요. 여기서br이 바로 구글이 만든 최신 압축 알고리즘인 'Brotli(브로틀리)'입니다. 프론트엔드 개발 시 번들 크기를 줄이는 것도 중요하지만, 서버에서 이 압축을 지원하도록 세팅하는 것이 훨씬 파워풀한 최적화 방법이랍니다!
Accept-Language 헤더 (The Accept-Language header)
Accept-Language 헤더는 사용자가 선호하는 언어를 나타내는 데 사용됩니다. 이 역시 품질 계수(quality factors)를 포함한 값들의 목록입니다 (예: de, en;q=0.7). 대개 사용자 에이전트(브라우저)의 그래픽 인터페이스 언어 설정에 따라 기본값이 세팅되지만, 대부분의 브라우저에서 사용자가 다른 언어 선호도를 설정할 수 있도록 허용하고 있습니다.
설정에 기반한 엔트로피(configuration-based entropy) 증가 문제로 인해, 수정된 값을 사용자의 핑거프린트(fingerprint, 식별자)를 따는 데 사용할 위험이 있습니다. 이 값을 변경하는 것은 권장되지 않으며, 웹사이트 입장에서도 이 값이 사용자의 실제 의도를 정확히 반영한다고 무조건 신뢰해서는 안 됩니다. 웹사이트 설계자는 이 헤더를 통한 언어 감지 기능에 너무 의존하지 않는 것이 좋습니다. 자칫 잘못하면 안 좋은 사용자 경험을 유발할 수 있으니까요.
- 항상 사용자가 서버가 선택한 언어를 덮어쓸(무시하고 직접 선택할) 수 있는 방법(예: 사이트 내 언어 선택 메뉴 제공)을 마련해 두어야 합니다. 대부분의 사용자 에이전트는 사용자 인터페이스 언어에 맞춰진
Accept-Language헤더의 기본값을 제공합니다. 일반 사용자들은 설정 방법을 모르거나 컴퓨터 환경 상 변경할 수 없어서 이 값을 수정하지 않는 경우가 많습니다. - 사용자가 서버가 선택한 언어를 한 번 덮어쓰고 나면(직접 언어를 선택하면), 웹사이트는 더 이상 언어 감지 기능을 사용하지 말고 사용자가 명시적으로 선택한 언어를 계속 유지해야 합니다. 다시 말해, 사이트의 '진입(메인) 페이지'에서만 이 헤더를 사용해 적절한 언어를 초기 선택해 주는 것이 좋습니다.
User-Agent 헤더 (The User-Agent header)
참고 (Note):
콘텐츠를 선택하기 위해 이 헤더를 정당하게 사용하는 경우도 있지만, 사용자 에이전트(브라우저)가 어떤 기능들을 지원하는지 파악하기 위해 이 헤더에 의존하는 것은 나쁜 관행(bad practice)으로 여겨집니다.
User-Agent 헤더는 요청을 보내는 브라우저가 무엇인지 식별합니다. 이 문자열에는 공백으로 구분된 제품 토큰(product tokens)과 주석(comments) 목록이 포함될 수 있습니다.
제품 토큰은 Firefox/4.0.1처럼 이름 뒤에 /가 오고 그 뒤에 버전 번호가 붙는 형태입니다. 사용자 에이전트는 원하는 만큼 여러 개의 토큰을 포함시킬 수 있습니다. 주석은 괄호로 둘러싸인 선택적인 문자열입니다. 주석 안에 들어가는 정보는 표준화되어 있지는 않지만, 여러 브라우저들이 \;로 구분된 여러 토큰들을 추가하곤 합니다.
Vary 응답 헤더 (The Vary response header)
앞서 살펴본 클라이언트가 보내는 Accept-* 헤더들과 대조적으로, Vary HTTP 헤더는 웹 서버가 자신의 응답에 실어서 보냅니다. 이 헤더는 서버가 '서버 주도 콘텐츠 협상' 단계에서 사용한 헤더들의 목록을 나타냅니다. Vary 헤더는 캐시 서버에게 응답을 어떤 기준에 따라 결정했는지 알려주어, 캐시가 그 기준을 똑같이 재현할 수 있도록 하기 위해 꼭 필요합니다. 이를 통해 사용자에게 올바른 콘텐츠가 전송되도록 보장하면서 동시에 캐시 기능이 정상적으로 작동할 수 있습니다.
특별한 값인 *는 서버 주도 콘텐츠 협상이 적절한 콘텐츠를 선택할 때 '헤더에 전달되지 않은 정보'까지도 사용했음을 의미합니다.
Vary 헤더는 HTTP 1.1 버전에 추가되었으며 캐시가 적절하게 작동하도록 해줍니다. 서버 주도 콘텐츠 협상과 함께 캐시가 제대로 작동하려면, 캐시는 서버가 전송할 콘텐츠를 선택할 때 '어떤 기준'을 사용했는지 알아야만 합니다. 그래야만 캐시 서버가 그 알고리즘을 똑같이 따라 해서, 원본 서버에 추가 요청을 보내지 않고도 클라이언트에게 허용되는 콘텐츠를 직접 반환할 수 있으니까요. 당연하게도 와일드카드 *를 사용하면 캐시는 이 응답 뒤에 어떤 기준이 숨어있는지 알 수 없으므로 캐싱이 일어나는 것을 막아버립니다. 더 자세한 정보는 HTTP 캐싱 > 응답 구분하기(Varying responses) 문서를 참조해 주세요.
에이전트 주도 협상 (Agent-driven negotiation)
서버 주도 협상에는 몇 가지 단점이 있는데, 바로 '확장성(scale)'이 좋지 않다는 것입니다. 협상을 위해 기능(feature) 하나당 헤더 하나씩이 사용됩니다. 만약 여러분이 화면 크기, 해상도, 또는 다른 측정 기준(dimensions)을 사용하고 싶다면, 새로운 HTTP 헤더를 계속 만들어야만 합니다. 그리고 그 헤더들은 매번 요청할 때마다 꼬박꼬박 전송되어야 하죠. 헤더가 몇 개 없을 때는 큰 문제가 아니지만, 헤더의 개수가 늘어나면 메시지 크기가 커져 결국 성능에 악영향을 미칠 수 있습니다. 또한 헤더가 더 정밀하게 전송될수록 전송되는 엔트로피(정보량)가 커져서 HTTP 핑거프린팅이 더 쉬워지고, 그에 따른 개인정보 보호 문제도 발생합니다.
그래서 HTTP는 또 다른 협상 유형을 허용하고 있습니다. 바로 에이전트 주도 협상(agent-driven negotiation), 또는 사후 협상(reactive negotiation)입니다. 이 경우, 서버는 모호한(명확한 선호도가 없는) 요청을 받았을 때, 사용 가능한 대체 리소스들에 대한 '링크'를 포함하는 페이지를 클라이언트에게 돌려보냅니다. 그러면 사용자에게 이 리소스 목록이 표시되고, 사용자가 사용할 것을 직접 선택하게 되죠.
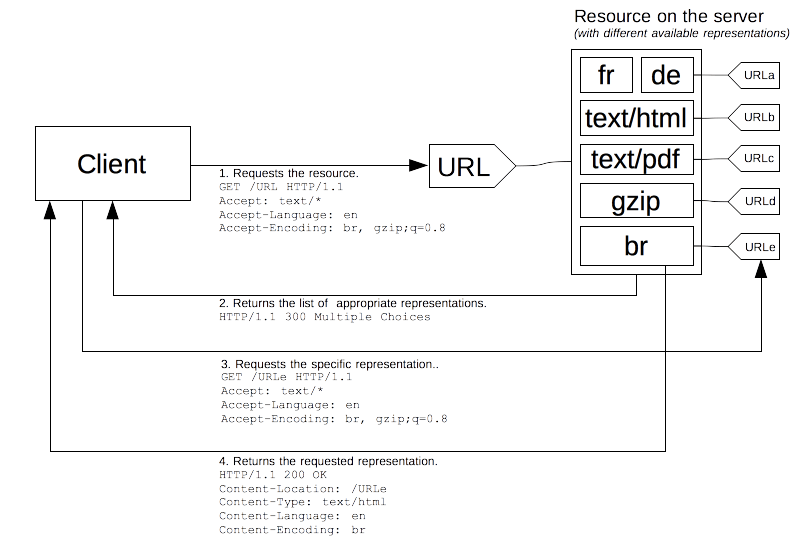
불행히도, HTTP 표준은 사용 가능한 리소스들 중에서 하나를 선택하도록 돕는 이 페이지의 '형식(format)'을 구체적으로 지정하지 않았습니다. 이 때문에 과정을 자동화하기가 불가능해졌죠. 결국 서버 주도 협상으로 되돌아가는 방법 외에는, 이 방식은 스크립팅, 특히 JavaScript 리다이렉션과 함께 거의 항상 사용됩니다. 즉, 스크립트가 협상 기준(예: 언어, 해상도 등)을 체크한 뒤 알아서 리다이렉션을 수행하는 식이죠. 이 방식의 두 번째 문제점은 실제 리소스를 가져오기 위해 '요청을 한 번 더' 보내야 하므로, 사용자가 리소스를 받기까지의 시간이 더 오래 걸린다는(느리다는) 점입니다.
💡 강사의 팁: 현대의 웹 개발에서는 이 300번대 응답을 통한 에이전트 주도 협상은 거의 쓰이지 않습니다. 대신 우리가 React나 Vue로 개발할 때 사용하는 SPA(Single Page Application) 라우팅이나, JavaScript를 활용해 클라이언트 단에서 브라우저 언어(
navigator.language)나 화면 크기(window.innerWidth)를 파악한 뒤 알아서 필요한 데이터를 비동기(fetch)로 불러오는 방식이 이를 사실상 완벽하게 대체하고 있다고 보시면 됩니다!
같이 보기 (See also)
MDN 개선에 참여하기 (Help improve MDN)
이 페이지가 도움이 되셨나요?
- [예 (Yes)]
- [아니요 (No)]
기여하는 방법 알아보기 (Learn how to contribute)
이 페이지는 MDN 기여자들 (MDN contributors)에 의해 2025년 12월 21일에 마지막으로 수정되었습니다.
