안녕하세요! 오늘 다뤄볼 주제는 프론트엔드 개발자가 서버와 소통할 때 반드시 이해해야 하는 핵심, 바로 'HTTP 메시지(HTTP messages)'입니다.
우리가 React나 Next.js로 화면을 예쁘게 만들고 나서, 백엔드 서버에 "유저 목록 좀 줘!" 하거나 "새로운 게시글 저장해 줘!"라고 요청할 때 브라우저 내부에서는 끊임없이 이 HTTP 메시지들이 오가고 있답니다. 이 구조를 정확히 알면 에러가 났을 때 어디가 문제인지 단번에 파악할 수 있는 엄청난 디버깅 실력을 갖추게 될 거예요. 자, 원본 내용 빠짐없이, 제 실무 팁을 팍팍 섞어서 친절하게 번역해 드릴게요!
HTTP 메시지 (HTTP messages)
HTTP 메시지는 HTTP 프로토콜에서 서버와 클라이언트 간에 데이터를 교환하기 위해 사용되는 메커니즘이에요.
메시지에는 두 가지 유형이 있습니다. 클라이언트가 서버에 어떤 동작을 일으키기 위해 보내는 요청(requests), 그리고 그 요청에 대한 서버의 답변인 응답(responses)이죠.
개발자들이 HTTP 메시지를 밑바닥부터 직접 텍스트로 치면서 만드는 경우는 거의(혹은 아예) 없어요.
브라우저, 프록시, 또는 웹 서버와 같은 애플리케이션들은 HTTP 메시지를 안정적이고 효율적으로 만들어 내도록 설계된 소프트웨어를 사용하거든요.
메시지가 어떻게 생성되고 변환되는지는 브라우저의 API(예: fetch나 XMLHttpRequest), 프록시나 서버의 설정 파일, 또는 다른 인터페이스들을 통해 제어됩니다.
💡 강사의 팁: 프론트엔드 개발자는 JavaScript로
fetch('...')함수나axios라이브러리를 사용해 API를 호출하죠? 그러면 브라우저가 알아서 우리가 짠 코드를 규격에 맞는 'HTTP 요청 메시지'로 예쁘게 포장해서 서버로 보내주는 거랍니다!
HTTP/2 이전 버전까지의 프로토콜에서 메시지는 텍스트 기반이었기 때문에, 형식을 조금만 눈에 익히면 읽고 이해하기가 비교적 직관적이었어요.
하지만 HTTP/2에서는 메시지가 바이너리 프레이밍(binary framing)으로 감싸져 있어서, 사람이 눈으로 직접 읽기는 조금 더 어려워졌습니다.
그렇지만 프로토콜에 깔려 있는 근본적인 의미(semantics)는 똑같기 때문에, 우리는 텍스트 기반인 HTTP/1.x 메시지의 형식을 통해 HTTP 메시지의 구조와 의미를 배우고, 이 이해를 HTTP/2나 그 이후 버전에 똑같이 적용할 수 있습니다.
이 가이드에서는 읽기 편하도록 HTTP/1.1 메시지를 사용하며, HTTP/1.1 형식을 기준으로 HTTP 메시지의 구조를 설명할 거예요.
그리고 마지막 섹션에서는 HTTP/2를 이해하는 데 필요한 몇 가지 차이점들을 짚어보겠습니다.
참고 (Note):
개발자 도구의 네트워크(Network) 탭에서 브라우저가 주고받는 HTTP 메시지를 직접 눈으로 확인할 수 있어요. 또는 curl 같은 CLI(명령줄 인터페이스) 도구를 사용해 콘솔에 HTTP 메시지를 출력해 볼 수도 있답니다.
(위 이미지처럼 개발자 도구를 열어 Network 탭을 확인하는 습관은 프론트엔드 개발자의 필수 소양입니다!)
이 문서의 내용 (In this article)
- HTTP 메시지의 구조 (Anatomy of an HTTP message)
- HTTP 요청 (HTTP requests)
- HTTP 응답 (HTTP responses)
- HTTP/2 메시지 (HTTP/2 messages)
- 결론 (Conclusion)
- 같이 보기 (See also)
HTTP 메시지의 구조 (Anatomy of an HTTP message)
HTTP 메시지가 어떻게 동작하는지 이해하기 위해, HTTP/1.1 메시지의 구조를 살펴볼게요.
다음 그림은 HTTP/1.1에서 메시지가 어떻게 생겼는지를 보여줍니다.

요청과 응답은 모두 비슷한 구조를 공유하고 있어요:
- 시작 줄(start-line)은 HTTP 버전과 함께 요청 메서드, 혹은 요청의 결과 상태를 설명하는 단일 줄이에요.
- 선택적으로 들어가는 HTTP 헤더(HTTP headers)의 집합입니다. 여기에는 메시지를 설명하는 메타데이터가 담겨요. 예를 들어, 리소스를 요청할 때는 '어떤 포맷의 리소스를 받을 수 있는지'를 헤더에 포함할 수 있고, 응답할 때는 '실제로 어떤 포맷으로 리소스를 반환하는지'를 나타내는 헤더가 포함될 수 있어요.
- 메시지의 메타데이터가 끝났음을 알리는 빈 줄(empty line)이 들어갑니다.
- 선택적으로 메시지와 관련된 데이터를 담고 있는 본문(body)이 옵니다. 요청 시 서버로 보낼 POST 데이터가 될 수도 있고, 응답 시 클라이언트에게 반환되는 어떤 리소스(HTML, JSON 등)가 될 수도 있죠.
메시지가 본문을 포함할지 말지는 시작 줄과 HTTP 헤더에 의해 결정된답니다.
HTTP 메시지의 시작 줄과 헤더들을 합쳐서 요청의 헤드(head)라고 부르고, 그 뒤에 실제 콘텐츠가 들어가는 부분을 본문(body)이라고 부릅니다.
HTTP 요청 (HTTP requests)
사용자가 웹 페이지에서 폼(form)을 제출했을 때 전송되는 다음과 같은 HTTP POST 요청 예시를 살펴볼까요?
POST /users HTTP/1.1
Host: example.com
Content-Type: application/x-www-form-urlencoded
Content-Length: 49
name=FirstName+LastName&email=bsmth%40example.comHTTP/1.x 요청에서 시작 줄(위 예시의 POST /users HTTP/1.1)은 "요청 줄(request-line)"이라고 불리며, 다음 세 가지 부분으로 구성됩니다:
<method> <request-target> <protocol><method>
: HTTP 메서드 (HTTP method) (또는 HTTP 동사라고도 불려요)는 정해진 단어들의 집합 중 하나로, 요청의 의미와 원하는 결과를 설명합니다.
예를 들어, GET은 클라이언트가 리소스를 돌려받기를 원한다는 뜻이고, POST는 클라이언트가 서버로 데이터를 보내고 있다는 뜻이에요.
💡 강사의 팁: 실무에서 데이터를 단순히 읽어올 때는
GET을, 새로운 데이터를 생성할 때는POST를, 수정할 때는PUT이나PATCH를, 삭제할 때는DELETE를 명확히 구분해서 사용하는 것이 좋은 API 설계(RESTful)의 기본입니다!
<request-target>
: 요청 대상(request target)은 일반적으로 절대적(absolute)이거나 상대적(relative)인 URL이며, 요청의 맥락(context)에 의해 그 특징이 결정됩니다.
요청 대상의 형식은 사용된 HTTP 메서드와 요청 맥락에 따라 달라져요.
이에 대해서는 아래의 요청 대상 (Request targets) 섹션에서 더 자세히 설명합니다.
<protocol>
: HTTP 버전을 말하며, 남은 메시지의 구조를 정의하고 서버에게 응답을 보낼 때 어떤 버전을 사용하길 기대하는지 알려주는 지표 역할을 합니다.
HTTP/0.9와 HTTP/1.0은 구식이 되었기 때문에, 이 값은 거의 항상 HTTP/1.1이에요.
HTTP/2 이상부터는 연결을 설정할 때 이미 버전을 서로 파악하기 때문에 메시지 안에 프로토콜 버전이 포함되지 않습니다.
요청 대상 (Request targets)
요청 대상을 설명하는 방법에는 몇 가지가 있지만, 압도적으로 가장 흔하게 쓰이는 것은 "출처 형식(origin form)"이에요.
다음은 타겟의 유형들과 각각이 언제 사용되는지에 대한 목록입니다:
-
출처 형식 (Origin form): 수신자가 절대 경로(absolute path)를
Host헤더의 정보와 결합하는 방식입니다.
추가적인 정보를 위해 경로 뒤에 쿼리 스트링(query string)을 덧붙일 수 있어요 (보통key=value형태죠).
이 방식은GET,POST,HEAD, 그리고OPTIONS메서드와 함께 사용됩니다.GET /en-US/docs/Web/HTTP/Guides/Messages HTTP/1.1💡 강사의 팁: 프론트엔드 코드에서
fetch('/api/users?page=1')이라고 호출할 때 브라우저가 만들어내는 요청의 타겟이 바로 이 형태랍니다. -
절대 형식 (Absolute form): 권한(authority)을 포함한 완전한 URL입니다. 주로 프록시 서버에 연결할 때
GET과 함께 사용됩니다.GET [https://developer.mozilla.org/en-US/docs/Web/HTTP/Guides/Messages](https://developer.mozilla.org/en-US/docs/Web/HTTP/Guides/Messages) HTTP/1.1 -
권한 형식 (Authority form): 권한(도메인 등)과 포트 번호를 콜론(
:)으로 구분한 형태입니다.
HTTP 터널을 설정할 때CONNECT메서드와 함께 단독으로만 사용됩니다.CONNECT developer.mozilla.org:443 HTTP/1.1 -
별표 형식 (Asterisk form): 명명된 특정 리소스가 아니라 서버 전체를 나타내고 싶을 때(
*),OPTIONS메서드와 함께 단독으로 사용됩니다.OPTIONS * HTTP/1.1
요청 헤더 (Request headers)
헤더는 시작 줄과 본문(body) 사이에서 요청과 함께 전송되는 메타데이터입니다.
위의 폼 제출 예시에서, 메시지의 다음 줄들이 바로 헤더에 해당해요:
Host: example.com
Content-Type: application/x-www-form-urlencoded
Content-Length: 49HTTP/1.x에서 각 헤더는 대소문자를 구분하지 않는(case-insensitive) 문자열 뒤에 콜론(:)이 붙고, 그 뒤에 각 헤더의 종류에 따라 포맷이 정해진 값이 따라오는 형태입니다.
값까지 포함하여 헤더 전체는 단일 줄(한 줄)로 구성돼요.
어떤 경우에는 이 줄이 꽤 길어질 수도 있는데, Cookie 헤더가 대표적인 예입니다.

일부 헤더는 요청에만 독점적으로 사용되는 반면, 어떤 헤더는 요청과 응답 양쪽 모두에서 전송될 수 있거나 조금 더 구체적인 카테고리로 분류될 수 있어요:
- 요청 헤더 (Request headers): 요청에 추가적인 맥락을 제공하거나, 서버가 이 요청을 어떻게 처리해야 하는지에 대한 추가 로직을 더해줍니다 (예: 조건부 요청).
💡 강사의 팁: 우리가 로그인을 구현하고 나면 발급받는 JWT 토큰 아시죠? 그 토큰을 매 요청마다 실어 보낼 때 쓰는
Authorization: Bearer <token>역시 대표적인 요청 헤더 중 하나입니다! - 표현 헤더 (Representation headers): 메시지에 본문(body)이 있을 때 요청에 포함되며, 메시지 데이터의 원본 형태와 적용된 인코딩 방식 등을 설명합니다.
이를 통해 수신자는 데이터가 네트워크를 통해 전송되기 전 원래 어떤 형태였는지 파악하고, 그 리소스를 다시 원래대로 재구성할 수 있게 됩니다.
요청 본문 (Request body)
요청 본문은 서버로 정보를 실어 나르는 요청의 일부분입니다.
PATCH, POST, PUT 요청만이 본문을 가질 수 있어요. (GET 요청은 본문이 없습니다!)
폼 제출 예시에서 다음 부분이 본문에 해당합니다:
name=FirstName+LastName&email=bsmth%40example.com폼 제출 요청의 본문은 key=value 쌍의 형태로 비교적 적은 양의 정보를 담고 있지만, 요청 본문은 서버가 기대하는 다른 다양한 형태의 데이터를 담을 수도 있어요:
{
"firstName": "Brian",
"lastName": "Smith",
"email": "bsmth@example.com",
"more": "data"
}💡 강사의 팁: React나 Next.js 개발자들이 가장 사랑하는 JSON 포맷이죠!
fetch를 쓸 때 이 JSON 객체를JSON.stringify()로 문자열화해서 바로 이 body에 실어 보내는 거랍니다. 이때 헤더에Content-Type: application/json을 꼭 넣어줘야 서버가 "아, 이 문자열은 JSON이구나!" 하고 파싱을 할 수 있어요.
또는 다음과 같이 여러 부분으로 나뉜 데이터(multiple parts)를 담을 수도 있습니다:
--delimiter123
Content-Disposition: form-data; name="field1"
value1
--delimiter123
Content-Disposition: form-data; name="field2"; filename="example.txt"
Text file contents
--delimiter123--💡 강사의 팁: 위 형태는
multipart/form-data라는 타입이에요. 프로필 이미지를 업로드하거나 파일을 전송할 때 브라우저가 자동으로 위와 같이 데이터를 경계선(--delimiter123)으로 쪼개서 본문을 만들어 줍니다.
HTTP 응답 (HTTP responses)
응답(Responses)은 클라이언트의 요청에 대한 대답으로 서버가 다시 돌려보내는 HTTP 메시지입니다.
응답은 클라이언트에게 요청의 결과가 어땠는지를 알려주죠.
새로운 유저를 생성하는 POST 요청에 대한 전형적인 HTTP/1.1 응답 예시를 살펴볼게요:
HTTP/1.1 201 Created
Content-Type: application/json
Location: [http://example.com/users/123](http://example.com/users/123)
{
"message": "New user created",
"user": {
"id": 123,
"firstName": "Example",
"lastName": "Person",
"email": "bsmth@example.com"
}
}응답에서 시작 줄(위 예시의 HTTP/1.1 201 Created)은 "상태 줄(status line)"이라고 불리며, 세 가지 부분으로 나뉩니다:
<protocol> <status-code> <reason-phrase><protocol>
: 메시지의 HTTP 버전입니다.
<status-code>
: 요청이 성공했는지 실패했는지를 나타내는 숫자 형태의 상태 코드 (status code)입니다.
가장 흔한 상태 코드로는 200(성공), 404(찾을 수 없음), 또는 302(리다이렉션)가 있습니다.
💡 강사의 팁: 프론트엔드 코드를 짤 때 가장 중요한 부분입니다! 200번대는 성공, 400번대는 클라이언트 잘못(파라미터를 빼먹었거나 권한이 없거나 등), 500번대는 서버 잘못(백엔드 에러)으로 크게 외워두시면 디버깅이 정말 편해집니다.
<reason-phrase> (선택 사항)
: 상태 코드 뒤에 선택적으로 붙는 텍스트로, 사람이 요청의 결과를 쉽게 이해할 수 있도록 상태를 간략하게 설명해 주는 순수 정보성 텍스트입니다.
이 사유 구문(reason phrase)은 가끔 괄호 안에 들어가기도 하는데 (예: "201 (Created)"), 이는 필수가 아닌 선택 사항임을 의미합니다.
응답 헤더 (Response headers)
응답 헤더는 응답과 함께 전송되는 메타데이터입니다.
HTTP/1.x에서 각 헤더는 대소문자를 구분하지 않는 문자열 뒤에 콜론(:)이 붙고, 그 뒤에 사용된 헤더에 따라 형식이 결정되는 값이 따라옵니다.

요청 헤더와 마찬가지로, 응답에도 나타날 수 있는 수많은 종류의 헤더들이 있으며, 다음과 같이 분류됩니다:
-
응답 헤더 (Response headers): 메시지에 대한 추가적인 맥락을 제공하거나, 클라이언트가 이후에 어떻게 다음 요청을 만들어야 하는지에 대한 추가 로직을 제공합니다.
예를 들어,Server같은 헤더는 서버 소프트웨어에 대한 정보를 포함하고,Date헤더는 응답이 언제 생성되었는지 알려줍니다.
또한 반환되는 리소스의 콘텐츠 타입(Content-Type)이나 캐싱 방법(Cache-Control)과 같이 리소스 자체에 대한 정보도 있습니다.💡 강사의 팁: 프론트엔드 개발자들이 API 통신을 할 때 제일 많이 마주치는 악명 높은 에러, CORS 에러 아시죠? 서버가 이 응답 헤더에
Access-Control-Allow-Origin: *같은 헤더를 내려주어야만 브라우저가 차단을 풀고 데이터를 우리 코드에 넘겨준답니다. 응답 헤더의 중요성, 확 와닿으시죠? -
표현 헤더 (Representation headers): 메시지에 본문이 있는 경우, 메시지 데이터의 형식과 적용된 인코딩에 대해 설명합니다.
예를 들어, 똑같은 리소스라도 XML이나 JSON 같은 특정 미디어 타입으로 포맷될 수도 있고, 특정 언어나 지리적 지역에 맞춰 현지화될 수도 있으며, 전송을 위해 압축되거나 다르게 인코딩될 수도 있습니다.
이를 통해 수신자는 데이터가 네트워크를 통해 전송되기 전 원래 형태가 어땠는지 이해하고 리소스를 복구할 수 있습니다.
응답 본문 (Response body)
응답 본문은 클라이언트에게 응답할 때 대부분의 메시지에 포함됩니다.
요청이 성공적이었다면, 응답 본문에는 클라이언트가 GET 요청에서 달라고 요구했던 바로 그 데이터가 들어있죠.
만약 클라이언트의 요청에 문제가 있었다면, 응답 본문에 '왜 요청이 실패했는지', 그리고 '그 실패가 영구적인지 일시적인지'에 대한 힌트를 설명해 주는 것이 일반적입니다.
응답 본문은 다음과 같을 수 있습니다:
- 단일 리소스 본문 (Single-resource bodies):
Content-Type과Content-Length두 가지 헤더에 의해 정의되거나, 길이를 알 수 없어Transfer-Encoding이chunked로 설정되어 조각(chunk) 단위로 인코딩되어 전송되는 본문입니다. - 다중 리소스 본문 (Multiple-resource bodies): 각기 다른 정보를 담고 있는 여러 개의 파트(부분)들로 구성된 본문입니다.
멀티파트 본문은 전형적으로 HTML 폼(Forms)과 관련이 있지만, 범위 요청 (Range requests)에 대한 응답으로 전송될 수도 있습니다.
메시지 콘텐츠를 굳이 포함할 필요 없이 상태 코드만으로 요청에 답할 수 있는 경우(예: 201 Created나 204 No Content), 해당 응답은 본문을 갖지 않습니다.
HTTP/2 메시지 (HTTP/2 messages)
HTTP/1.x는 사람이 읽고 작성하기 직관적인 텍스트 기반 메시지를 사용하지만, 그 결과 몇 가지 단점도 가지고 있습니다.
메시지 본문(body)은 gzip이나 다른 압축 알고리즘을 사용해서 압축할 수 있지만, 헤더는 압축할 수가 없었어요.
클라이언트와 서버의 통신 과정에서 헤더들은 종종 비슷하거나 심지어 완전히 똑같은 경우가 많은데, 하나의 연결 위에서 연속되는 메시지마다 이 똑같은 헤더들이 계속 반복해서 전송됩니다.
반복되는 텍스트를 아주 효율적으로 압축할 수 있는 훌륭한 방법들이 이미 많이 알려져 있는데도, 이런 방법들을 적용하지 못해서 방대한 대역폭(네트워크 자원) 절감의 기회를 날려버리고 있던 셈이죠.
HTTP/1.x는 또한 클라이언트가 다음 요청을 보내기 전에 서버로부터 이전 요청에 대한 응답을 기다려야만 하는 홀 블로킹(head-of-line (HOL) blocking) 문제도 안고 있었습니다.
HTTP 파이프라이닝 (pipelining)이라는 기술로 이를 우회하려고 노력했지만, 지원이 미비하고 구현이 복잡해서 올바르게 사용하기가 어려워 거의 쓰이지 않았어요.
그래서 요청들을 동시에(concurrently) 보내려면 여러 개의 TCP 연결을 따로 열어야만 했죠. 게다가 TCP 특성상 방금 막 새로 연 연결(콜드 연결)보다는 이미 열려서 활발히 통신 중인 연결(웜 연결)이 훨씬 더 효율적인데도 말이죠.
HTTP/1.1에서 만약 두 개의 요청을 병렬로 처리하고 싶다면, 그림처럼 두 개의 연결을 열어야만 했습니다:
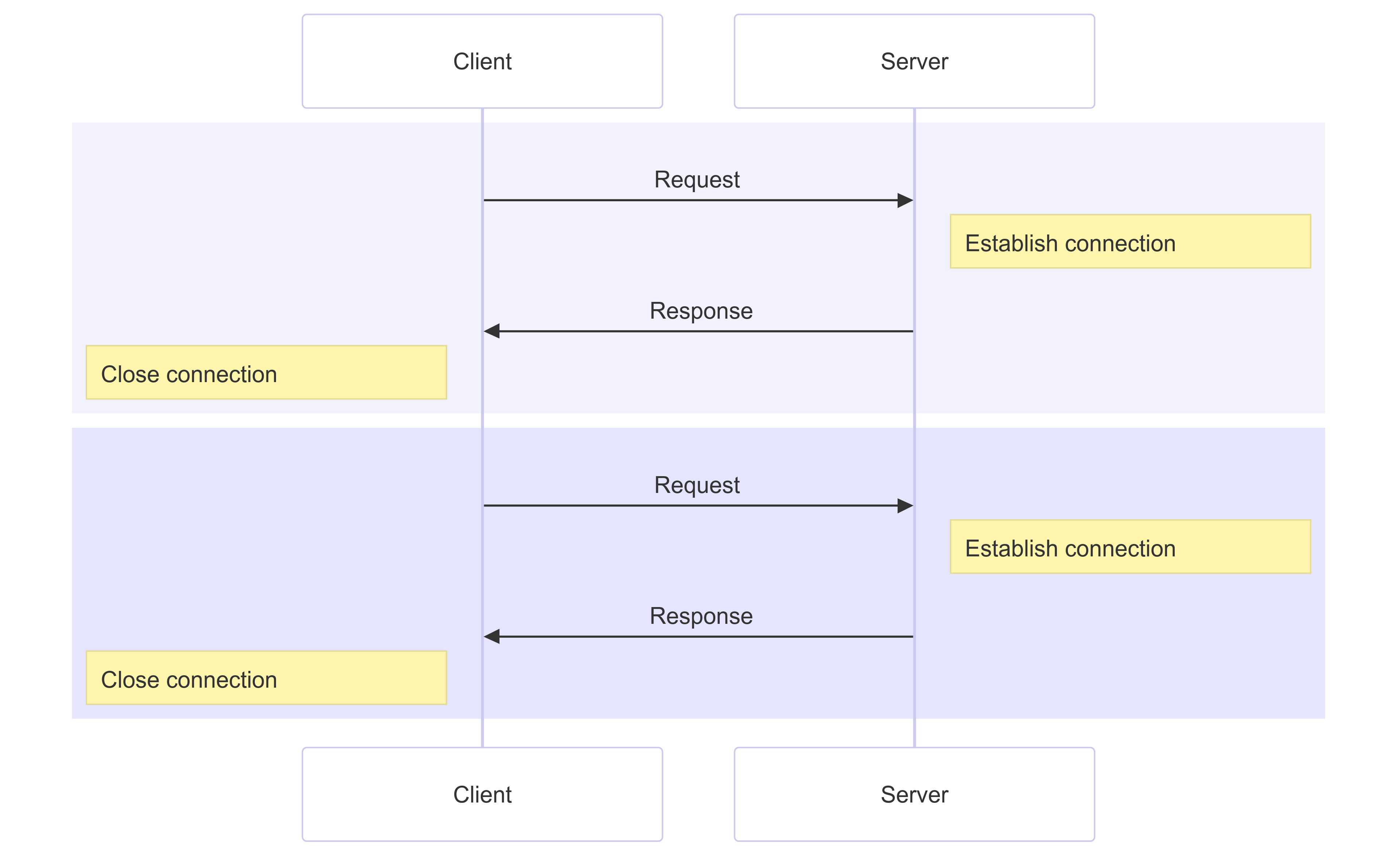
이는 브라우저가 동시에 다운로드하고 렌더링할 수 있는 리소스의 수에 한계가 있다는 것을 의미했고, 전형적으로 한 도메인당 최대 6개의 병렬 연결로 제한되어 왔습니다.
반면, HTTP/2는 여러 개의 요청과 응답을 동시에 처리하는 데 단 하나의 TCP 연결만 사용합니다.
이것은 메시지를 바이너리 프레임(binary frame)으로 감싸고, 연결 위에서 번호가 매겨진 스트림(stream) 형태로 요청과 응답을 전송함으로써 이루어집니다.
데이터 프레임과 헤더 프레임이 서로 분리되어 처리되기 때문에, HPACK이라는 알고리즘을 통해 마침내 헤더를 압축할 수 있게 되었어요.
이처럼 동일한 TCP 연결을 사용하여 여러 요청을 동시에 처리하는 방식을 멀티플렉싱(multiplexing)이라고 부릅니다.
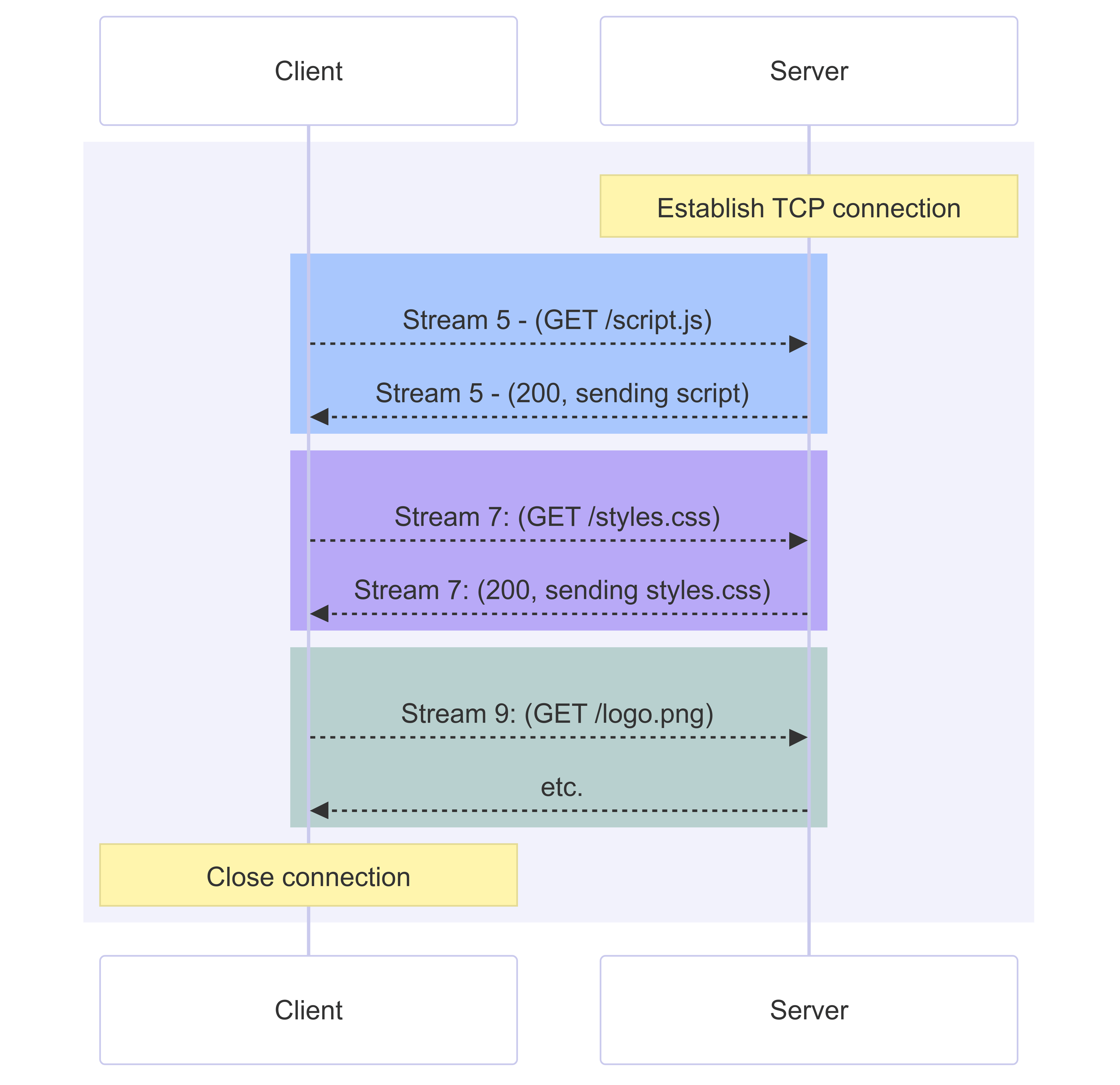
이제 요청들은 순차적이지 않아도 됩니다. 예를 들어 스트림 9는 스트림 7이 끝날 때까지 기다릴 필요가 없어요.
여러 스트림에서 온 데이터들은 보통 하나의 연결 위에서 서로 교차되어(interleaved) 전송되므로, 클라이언트는 스트림 9번과 7번의 데이터를 동시에 수신할 수 있습니다.
또한 프로토콜 내에 각 스트림이나 리소스의 우선순위를 정하는 메커니즘도 생겼어요.
중요도가 낮은 리소스는 다른 스트림을 통해 전송될 때 중요도가 높은 리소스보다 대역폭을 덜 차지하도록 조정되거나, 만약 먼저 처리해야 할 아주 중요한 핵심 리소스가 있다면 단일 연결 내에서도 효과적으로 순차 전송되도록 할 수 있습니다.
💡 강사의 팁: Zustand, SWR 등을 쓰면서 프론트 상태 관리를 최적화하는 것도 좋지만, 화면을 띄울 때 수십 개의 이미지나 스크립트 파일을 브라우저가 한 번에 끊김 없이 가져올 수 있는 건 바로 이 HTTP/2의 멀티플렉싱 덕분입니다. 면접에서도 "HTTP/2의 장점이 무엇인가요?" 라는 질문에 '헤더 압축(HPACK)'과 '멀티플렉싱을 통한 HOL 블로킹 해결'이라고 답하시면 완벽합니다!
전반적으로, HTTP/1.x에 비해 이렇게나 많은 개선점과 추상화가 더해졌음에도 불구하고, 개발자들이 HTTP/1.x 대신 HTTP/2를 사용하기 위해 기존에 쓰던 API 코드를 수정할 필요는 사실상 전혀 없습니다.
브라우저와 서버 양쪽 모두에서 HTTP/2를 지원하기만 하면, 자동으로 HTTP/2로 스위칭되어 사용되기 때문이죠.
의사 헤더 (Pseudo-headers)
HTTP/2 메시지에서 눈에 띄는 큰 변화 중 하나는 바로 '의사 헤더(pseudo-headers, 가짜 헤더)'의 사용입니다.
HTTP/1.x가 메시지 '시작 줄'을 사용했던 곳에, HTTP/2는 :로 시작하는 특별한 의사 헤더 필드들을 사용해요.
요청(requests) 시에는 다음과 같은 의사 헤더들이 존재합니다:
:method- HTTP 메서드:scheme- 타겟 URI의 스킴 부분 (대부분 HTTP 혹은 HTTPS):authority- 타겟 URI의 권한(도메인) 부분:path- 타겟 URI의 경로 및 쿼리 부분
응답(responses) 시에는 딱 하나의 의사 헤더만 존재하는데, 바로 응답 코드를 제공하는 :status 입니다.
nghttp 도구를 사용해 example.com을 조회하는 HTTP/2 요청을 보내보면, 요청이 조금 더 읽기 쉬운 형태로 출력되는 것을 볼 수 있어요.
다음 명령어를 사용해 요청을 보낼 수 있는데, -n 옵션은 다운로드된 데이터를 버린다는 뜻이고, -v는 '상세하게(verbose)' 출력하여 프레임의 송수신 내역을 모두 보여주겠다는 뜻입니다:
nghttp -nv [https://www.example.com](https://www.example.com)출력된 내용을 아래로 쭉 살펴보면, 전송되고 수신된 각 프레임의 타이밍을 볼 수 있습니다:
[ 0.123] <send|recv> <frame-type> <frame-details>이 출력의 모든 세부 사항을 다 깊이 파고들 필요는 없지만, [ 0.123] send HEADERS frame ... 포맷으로 된 HEADERS 프레임을 눈여겨보세요.
헤더 전송이 표시된 바로 다음 줄들에서 다음과 같은 내용을 볼 수 있을 겁니다:
[ 0.447] send HEADERS frame ...
...
:method: GET
:path: /
:scheme: https
:authority: [www.example.com](https://www.example.com)
accept: */*
accept-encoding: gzip, deflate
user-agent: nghttp2/1.61.0만약 HTTP/1.x 환경에 이미 익숙하시다면, 이 가이드 앞부분에서 다뤘던 개념들이 여전히 그대로 적용되고 있어서 꽤 친숙해 보이실 거예요.
이것이 바로 example.com에 대한 GET 요청을 담은 바이너리 프레임이 nghttp에 의해 사람이 읽기 편한 형태로 변환된 모습입니다.
명령어 출력 내용의 조금 더 아래를 살펴보면, 서버로부터 수신된 스트림 중 하나에 :status 의사 헤더가 들어있는 것도 확인하실 수 있습니다:
[ 0.433] recv (stream_id=13) :status: 200
[ 0.433] recv (stream_id=13) content-encoding: gzip
[ 0.433] recv (stream_id=13) age: 112721
[ 0.433] recv (stream_id=13) cache-control: max-age=604800
[ 0.433] recv (stream_id=13) content-type: text/html; charset=UTF-8
[ 0.433] recv (stream_id=13) date: Fri, 13 Sep 2024 12:56:07 GMT
[ 0.433] recv (stream_id=13) etag: "3147526947+gzip"
...그리고 여기서 타이밍 정보와 스트림 ID 부분만 살짝 지워보면, 구조가 훨씬 더 익숙하게 다가올 거예요:
:status: 200
content-encoding: gzip
age: 112721메시지 프레임, 스트림 ID, 그리고 연결이 정확히 어떻게 관리되는지 더 깊이 파고드는 것은 이 가이드의 범위를 벗어납니다. 하지만 HTTP/2 메시지를 이해하고 디버깅하려는 목적이라면, 이 문서에서 다룬 지식과 도구들만으로도 이미 충분한 무기를 갖추신 셈입니다.
결론 (Conclusion)
이 가이드에서는 HTTP/1.1 포맷을 예제로 삼아 HTTP 메시지의 구조(해부학적 형태)에 대한 전반적인 개요를 제공해 드렸습니다.
우리는 또한 HTTP/2의 메시지 프레이밍에 대해서도 살펴보았죠. 이는 HTTP의 기본적인 의미론(semantics)을 본질적으로 수정하지 않으면서도, HTTP/1.x의 문법과 그 아래의 전송 프로토콜 사이에 새로운 계층을 하나 추가한 기술입니다.
HTTP/2는 요청들을 멀티플렉싱(다중화)할 수 있게 함으로써, 기존 HTTP/1.x에 존재했던 홀 블로킹 (head-of-line blocking) 이슈를 해결하기 위해 도입되었어요.
하지만 HTTP/2에도 한 가지 남은 문제점이 있었는데요. 바로 프로토콜 레벨(HTTP 수준)에서의 홀 블로킹은 해결되었지만, 그 아래 전송 레벨인 TCP 내부의 홀 블로킹 때문에 여전히 성능상의 병목 현상이 존재했다는 점입니다.
HTTP/3는 TCP 대신 UDP 기반으로 만들어진 QUIC이라는 프로토콜을 사용함으로써 이 한계점마저 극복해 냈습니다.
이러한 변화는 퍼포먼스를 향상시키고, 연결 설정에 드는 시간을 단축하며, 네트워크 상태가 나쁘거나 불안정할 때 안정성을 한층 더 끌어올려 줍니다.
물론 HTTP/3 역시 기존의 핵심적인 HTTP 의미론을 그대로 유지하고 있기 때문에, 요청 메서드, 상태 코드, 헤더 같은 기능들은 세 가지 주요 HTTP 버전 모두에서 일관성 있게 똑같이 작동합니다.
결론적으로, 여러분이 HTTP/1.1의 의미(semantics)를 이해하고 있다면, 이미 HTTP/2와 HTTP/3를 파악하기 위한 탄탄한 기초를 갖춘 셈입니다.
핵심적인 차이점은 이러한 의미들이 전송 레벨에서 '어떻게(how)' 구현되었는지에 있을 뿐이죠.
이 가이드의 예시와 개념들을 쭉 따라오셨다면, 이제 HTTP를 능숙하게 다루고 메시지의 의미를 해석하며, 웹 애플리케이션이 데이터를 주고받기 위해 HTTP를 어떻게 사용하는지 완전히 이해할 준비가 되셨을 거예요!
같이 보기 (See also)
- HTTP의 진화 (Evolution of HTTP)
- 프로토콜 업그레이드 메커니즘 (Protocol upgrade mechanism)
- 용어 사전 (Glossary terms):
