모든 배치 처리는 다량의 데이터를 읽어서, 계산하고, 그 결과를 쓰는 작업이다.
스프링 배치는 따라서 bulk read, wirte를 위해 세가지 핵심 인터페이스를 제공한다.
Item Reader
ItemReader는 간단한 개념이긴하지만, 매우 다양한 입력으로부터 데이터를 읽는 수단이다. 대부분의 예제는 아래 예시를 포함한다.
- 플랫 파일 : 플랫 파일 아이템 reader는 일반적으로 필드가 고정된 위치에 있거나 특정한 특수문자로 필드를 구분하는 파일을 읽는다.
- XML : XMLItemReader는 파싱, 매핑, 검증에 사용되는 기술과는 독립적으로 XML을 처리한다. 입력데이터 유효성은 XSD 스키마로검증한다.
- Database : 데이터 베이스에 접근해 처리할 객체에 매핑되는 결과셋을 얻어온다. 디폴트
ItemReader구현체는RowMapper를 호출해서 오브젝트를 리턴하고, 재시작을 대비해 현재 로우를 추저하고 기본적인 통꼐를 저장하며, 뒤에서 설명할 개선된 트랜잭션을 제공한다.
추가적으로 사용가능한 모든 ItemReader 구현체는 링크에 존재한다.
ItemReader는 일반적인 입력작업을 위한 포괄적인 인터페이스다.
public interface ItemReader<T> {
T read() throws Exception, UnexpectedInputException, ParseException, NonTransientResourceException;
}read 메소드는 아이템 하나를 리턴하거나, 더이상 아이템이 없는경우 null을 리턴한다.
아이템 하나는 파일의 한줄을 의미하거나, 데이터베이스의 row 하나가 될수도 있고, xml에서는 하나의 element일 수도 있다. (보통 아이템은 도메인 오브젝트로 매핑되는데) 꼭 그럴 필요는 없다.
ItemReader의 구현체는 앞에서 뒤로만 읽고 역행하지 말아야한다.(forward only)
그러나 별도의 트랜잭션 처리가 있는 리소스에서 데이터를 읽는다면 read 메소드는 롤백 후 다시 호출해도 같은 아이템을 리턴해야 한다.
ItemReader가 더 이상 처리할 아이템이 없어도 예외를 발생시키지 않는다는점을 알아둘 필요가 있다.
즉, 결과가 0개인 쿼리로 설정된 데이터베이스는 ItemReader read를 호출할 때부터 null을 반환할 것이다.
ItemWriter
ItemWriter는 ItemReader와 비슷하지만 하는 일은 정 반대다. 리소스는 여전히 필요하고, 또 열리고 닫혀야 하지만, ItemWriter는 읽는게 아니라 쓴다는 점이 다르다. 데이터베이스나 큐를 사용한다면 이 동작은 Insert, update or send일 것이다. 결과물의 직렬화 형식은 각 job마다 다르다.
ItemReader처럼 ItemWriter도 꽤 포괄적인 인터페이스다
public interface ItemWriter<T> {
void write(List<? extends T> items) throws Exception;
}ItemReader의 read 메소드처럼 write메소드가 ItemReader의 가장 본질적인 역할을 정의한다.
리소스가 열려 있다면 전달받은 아이템 리스트를 write한다. 일반적으로 아이템은 청크로 묶여서 결과물을 만들기 때문에, 이 인터페이스는 아이템 하나가 아니라 아이템 리스트를 받는다.
ItemProcessor
ItemReader와 ItemWriter는 각자 맡은 작업을 잘 수행하지만, write전에 비즈니스 로직을 추가하고 싶다면 어떻게 해야하는가? 한 가지 방법은 Composite 패턴을 이용하는것
-> Composite 패턴은 다른 클래스들의 컴포넌트도 동일한 인터페이스를 가짐으로써 특정기능을 각 클래스에 맞게 지원할 수 있게 하는 패턴
ex) shape interface의 draw, triangle의 draw, circle의 draw 그림판은 shape의 draw 메소드로, triangle, circle 클래스 각각에 맞는 기능을 실행할 수 있다.
public class CompositeItemWriter<T> implements ItemWriter<T> {
ItemWriter<T> itemWriter;
public CompositeItemWriter(ItemWriter<T> itemWriter) {
this.itemWriter = itemWriter;
}
public void write(List<? extends T> items) throws Exception {
//Add business logic here
itemWriter.write(items);
}
public void setDelegate(ItemWriter<T> itemWriter){
this.itemWriter = itemWriter;
}
}앞의 클래스는 다른 ItemWriter 하나를 포함하고 있는데, 비즈니스 로직을 처리하고 나서 write 처리를 위임한다.
그렇지만, write시에 넘겨받은 데이터를 실제로 쓰기 전에 변환만 된다면, 굳이 write를 직접 제어할 필요가 없다. item을 수정한 뒤에 넘기면 된다. 이런경우를 위해 스프링 배치는 ItemProcessor를 제공한다.
public interface ItemProcessor<I, O> {
O process(I item) throws Exception;
}예제
public class Foo {}
public class Bar {
public Bar(Foo foo) {}
}
public class FooProcessor implements ItemProcessor<Foo,Bar>{
public Bar process(Foo foo) throws Exception {
//Perform simple transformation, convert a Foo to a Bar
return new Bar(foo);
}
}
public class BarWriter implements ItemWriter<Bar>{
public void write(List<? extends Bar> bars) throws Exception {
//write bars
}
}Chaining ItemProcessors
변환 하나로도 충분한 경우도 많지만 여러 ItemProcessor 구현체를 연결하고 싶으면 어떻게 해야할까? 이전에 언급한 composite 패턴을 사용하면 된다.
public class Foo {}
public class Bar {
public Bar(Foo foo) {}
}
public class Foobar {
public Foobar(Bar bar) {}
}
public class FooProcessor implements ItemProcessor<Foo,Bar>{
public Bar process(Foo foo) throws Exception {
//Perform simple transformation, convert a Foo to a Bar
return new Bar(foo);
}
}
public class BarProcessor implements ItemProcessor<Bar,Foobar>{
public Foobar process(Bar bar) throws Exception {
return new Foobar(bar);
}
}
public class FoobarWriter implements ItemWriter<Foobar>{
public void write(List<? extends Foobar> items) throws Exception {
//write items
}
}아래 예제에서는 함께 ‘연결(chained)된’ FooProcessor와 BarProcessor가 최종 결과물로 Foobar로 만든다.
@Bean
public Job ioSampleJob() {
return this.jobBuilderFactory.get("ioSampleJob")
.start(step1())
.end()
.build();
}
@Bean
public Step step1() {
return this.stepBuilderFactory.get("step1")
.<String, String>chunk(2)
.reader(fooReader())
.processor(compositeProcessor())
.writer(foobarWriter())
.build();
}
@Bean
public CompositeItemProcessor compositeProcessor() {
List<ItemProcessor> delegates = new ArrayList<>(2);
delegates.add(new FooProcessor());
delegates.add(new BarProcessor());
CompositeItemProcessor processor = new CompositeItemProcessor();
processor.setDelegates(delegates);
return processor;
}Filtering Records
item Processor는 ItemWriter로 데이터를 넘기기 전 필터링 하는데에도 많이 사용된다. 필터링은 스킵과 다른 액션이다. 스킵은 데이터가 유효하지 않는것이고, 필터링은 단순히 데이터를 write 하지 않겠다는 것이다.
예를들어 세가지 유형의 파일을 읽어야 하는 배치 job을 떠올려봐라, insert 데이터, update할 데이터, delete할 데이터, 레코드 삭제를 지원하지 않는 시스템이라면, ItemWriter에 삭제 대상 데이터를 넘기지 않으면 된다. 그렇지만 이 데이터가 잘못된 데이터가 아니므로 스킵보단 필터링이 맞다.
아이템을 필터링 하고 싶으면 Item Processor에서 null을 리턴하면 된다.
결과가 null이라면 프레임워크가 ItemWriter에 전달되는 아이템 리스트에서 제외시킨다. 늘 그렇듯 ItemProcessor에서 예외가 발생하면 스킵된다.
Fault Tolerance
청크가 롤백되면 데이터를 읽을 때 이미 캐시해둔 아이템이 다시 처리될 수 있다. 내결함성이 있는 step이라면 모든 ItemProcessor는 멱등성(idempotence)을 보장해야 한다. 보통은 ItemProcessor의 입력 데이터는 바꾸지 않고 결과로 사용할 인스턴스만 바꾸는 식으로 구현한다.
ItemStream
ItemReader, ItemWriter 모두 맡은 역할은 잘 처리하지만, 양쪽 다 다른 인터페이스가 필요한 경우도 있다. 일반적으로 배치 job의 일환으로 reader와 writer는 리소스를 열고 닫아야하며 상태를 저장하기 위한 메커니즘이 필요하다. ItemStream은 reader, writer가 파일을 어느정도로 읽고 썼는지에 대한 상태를 기록하고 있는ExecutionContext를 포함하고 있으며, reader나 writer는 execution Context를 읽어 다음 쓸 정보들을 확인한다.
public interface ItemStream {
void open(ExecutionContext executionContext) throws ItemStreamException;
void update(ExecutionContext executionContext) throws ItemStreamException;
void close() throws ItemStreamException;
}각 메소드를 설명하기 전 ExecutionContext를 짚고 넘어가자.
- open : 리소스를 열 때 사용한다.
- close : 리소스를 안전하게 닫을 때 사용한다.
- update : 현재까지 진행된 모든 상태를
ExecutionContext에 저장한다.
The Delegate Pattern And Registering With the Step
CompositeItemWriter는 스프링 배치에서 흔히쓰는 Delegate 패턴이다. 위임받는 객체 자체가 StepListener같은 콜백 인터페이스 구현하는 경우도 있다. 스프링 배치 코어의 Step에서 위임 패턴을 사용한다면 거의 모든 경우 수동으로 Step을 등록해야 한다. ItemStream이나 StepListener인터페이스를 Step과 직접 연결하는 reader, writer, prcoessor로 구현하면 자동으로 등록된다.
그러나 Step은 위임 객체를 알 수 없으므로 아래 보이는 예제 처럼 listener, stream으로 직접 연결해야한다.
@Bean
public Job ioSampleJob() {
return this.jobBuilderFactory.get("ioSampleJob")
.start(step1())
.end()
.build();
}
@Bean
public Step step1() {
return this.stepBuilderFactory.get("step1")
.<String, String>chunk(2)
.reader(fooReader())
.processor(fooProcessor())
.writer(compositeItemWriter())
.stream(barWriter())
.build();
}
@Bean
public CustomCompositeItemWriter compositeItemWriter() {
CustomCompositeItemWriter writer = new CustomCompositeItemWriter();
writer.setDelegate(barWriter());
return writer;
}
@Bean
public BarWriter barWriter() {
return new BarWriter();
}Flat Files
플랫 파일은 벌크 데이터를 교환할 때 가장 흔히 사용하는 방법 중 하나
일반적으로 플랫 파일은 두 유형중 하나에 속한다.
- 구분자(delimiterd)
- 고정길이
The FieldSet
스프링 배치에서 플랫 파일을 다룬다면 입력데이터든 출력데이터든 상관없이 FieldSet이 제일 중요한 클래스다. FieldSet은 파일 리소스로부터 필드를 바인딩하기 위해 스프링 배치가 제공하는 인터페이스다.
FieldSet은 개념적으로 JDBC ResultSet과 유사하다. FieldSet에 String 배열로 토큰을 넘겨주기만 하면 된다.
String[] tokens = new String[]{"foo", "1", "true"};
FieldSet fs = new DefaultFieldSet(tokens);
String name = fs.readString(0);
int value = fs.readInt(1);
boolean booleanValue = fs.readBoolean(2);FlatFileItemReader
플랫 파일은 최대 2차원으로 표현된 데이터라면 어떤 것이든 담을 수 있다. 스프링 배치 프레임워크에서는 기본적인 플랫 파일 읽기와 파싱을 지원하는 FlatFileItemReader로 플랫 파일을 읽는다.
FlatFileItemReader를 사용하려면 가장 중요한 Resource와 LineMapper 두 가지가 필요하다. resource프로퍼티는 스프링 코어의 Resource를 나타낸다.
이 유형의 빈을 만드는 법이 궁금하다면 Spring Framework, Resources를 참조하라
@Test
public void useFlatFileItemReader() throws IOException {
Resource fileSystemResource = new FileSystemResource("src/main/resources/application.properties");
Resource classPathResource= new ClassPathResource("foo1true.txt");
}- FlatFileItemReader 의 Properties는 다음과 같다.
| Property | Type | Description |
|---|---|---|
| comments | String[] | 행전체를 주석 처리하는 prefix |
| encoding | String | 사용할 텍스트 인코딩, 디폴트는 Charset.defaultCharset() |
| lineMapper | LineMapper | String을 item Object로 변환 |
| linesToSkip | int | 파일 상단에 있는 무시할 라인 수 |
| recordSeparatorPolicy | RecordSeparatorPolicy | 라인이 끝나는 지점과, 따옴표로 묶인 문자열 안에서 라인이 끝나면 같은 라인으로 처리할지 등을 결정 |
| resource | Resource | 읽어야할 리소스 |
| skippedLinesCallback | LineCallbackHandler | 건너뛸 라인의 원래 내용을 전달하는 인터페이스 |
| strict | boolean | strict 모드에선 입력 리소스가 없으면, ExecutionContext에서 예외를 발생시킨다. |
LineMapper
ResultSet같은 저수준의 구조를 처리해 Object를 반환하는 RowMapper처럼 플랫 파일도 String 한줄을 Object로 변환한다.
public interface LineMapper<T> {
T mapLine(String line, int lineNumber) throws Exception;
}기본 역할은 현재 라인과 라인 넘버를 받아 도메인 객체를 변환하는 것이다. 그러나 RowMapper와는 달리 반만 처리한 것과 마찬가지인 단순 문자열을 가진다.
이는 문자열을 객체로 매핑할 수 있는 FieldSet으로 토큰화 해야 한다.
LineTokenizer
플랫 파일은 파일마다 형식이 다르기 때문에 문자열을 FieldSet으로 변환하는 작업을 추상화시켜야 한다.
스프링 배치가 제공하는 인터페이스는 LineTokenizer이다.
public interface LineTokenizer {
FieldSet tokenize(String line);
}LineToTokenizer는 입력받은 라인을 FieldSet으로 변환해서 리턴한다. 이 FieldSet은 FieldSetMapper로 넘겨 처리할 수 있다.
LineTokenizer 구현체를 제공한다.
- DelimitedLineTokenizer : 구분자로 필드를 구분하는 파일에 사용한다 구분자로, 쉼표를 가장 많이 쓰지만 파이프나 세미콜론도 많이 사용한다.
- FiexedLengthTokenizer: 각 필드를 고정된 길이로 정의하는 파일에 사용한다. 각 필드 길이는 각 레코드마다 정의해야한다.
- PatternMatchingCompositeLineTokenizer : 패턴을 보고 각 라인에서 사용할 LineTokenizer를 결정한다.
FieldSetMapper
FieldSetMapper는 FieldSet 객체를 받아 다른 객체로 매핑시키는 메소드 하나를 정의하고 있는 인터페이스다. 이 객체는 job 성격에 따라 커스텀 DTO일수도있고, 도메인 객체나 배열일 수 도 있다.
public interface FieldSetMapper<T> {
T mapFieldSet(FieldSet fieldSet) throws BindException;
}DefaultLineMapper
flat 파일을 읽기 위해서는 다음 3가지 절차가 필요하다.
- 파일에서 라인을 한 줄 읽는다.
- String을
LineTokenizer#tokenize()메소드로 넘겨FieldSet을 받는다. - 토크나이저로부터 받은
FieldSet을FieldSetMapper로 넘겨ItemReader#read()메소드 결과를 받는다.
위에서 다룬 두 인터페이스는 두가지 독립적인 처리를 한다.
1. 문자열을 FieldSet으로 변환한다.
2. FieldSet을 도메인 객체에 매핑한다.
DefaultLineMapper는 사용자들이 이런 작업을 처리해준다.
public class DefaultLineMapper<T> implements LineMapper<>, InitializingBean {
private LineTokenizer tokenizer;
private FieldSetMapper<T> fieldSetMapper;
public T mapLine(String line, int lineNumber) throws Exception {
return fieldSetMapper.mapFieldSet(tokenizer.tokenize(line));
}
public void setLineTokenizer(LineTokenizer tokenizer) {
this.tokenizer = tokenizer;
}
public void setFieldSetMapper(FieldSetMapper<T> fieldSetMapper) {
this.fieldSetMapper = fieldSetMapper;
}
}예제
- people.txt
donggeun,12
donggeun2,23가 classpath에 존재하고
Person과 PersonMapper를 다음과 같이 정의한다.
- Person.java
@Data
public class Person {
private String name;
private int age;
}
- PersonMapper.java
public class PersonMapper implements FieldSetMapper<Person> {
@Override
public Person mapFieldSet(FieldSet fieldSet) throws BindException {
Person person = new Person();
person.setName(fieldSet.readString(0));
person.setAge(fieldSet.readInt(1));
return person;
}
} Resource resource = new ClassPathResource("people.txt");
System.out.println("파일존재 : " + resource.exists());
FlatFileItemReader<Person> personItemReader = new FlatFileItemReader<>();
personItemReader.setResource(resource);
DefaultLineMapper<Person> personDefaultLineMapper = new DefaultLineMapper<>();
personDefaultLineMapper.setLineTokenizer(new DelimitedLineTokenizer());
personDefaultLineMapper.setFieldSetMapper(new PersonMapper());
personItemReader.setLineMapper(personDefaultLineMapper);
personItemReader.open(new ExecutionContext());
Person person = personItemReader.read();
System.out.println(person); 
제대로 파일이 읽힌것을 확인할 수 있다.
Mapping Fields by name
DelimitdLineTokenizer, FiexedLengthTokenizer는 다른 기능이 하나 더 있는데, resultSet 과 유사한 기능이다.
필드명을 LineTokenizer 구현체중 하나에 주입해주면 가독성 있게 매핑이 가능하다.
DelimitedLineTokenizer delimitedLineTokenizer = new DelimitedLineTokenizer();
delimitedLineTokenizer.setNames("name","age");
personDefaultLineMapper.setLineTokenizer(delimitedLineTokenizer);public class PersonMapper implements FieldSetMapper<Person> {
@Override
public Person mapFieldSet(FieldSet fieldSet) throws BindException {
Person person = new Person();
person.setName(fieldSet.readString("name"));
person.setAge(fieldSet.readInt("age"));
return person;
}
}Automapping FieldSets To Domain Objects
매번 FieldSetMapper에 매핑 규칙을 나열하는건 번거롭다. 스프링 배치에서는 FieldSetMapper가 자바빈 명세(JavaBean Specification)를 사용해 객체의 setter와 일치하는 필드명을 자동으로 매핑해주기 때문이다.
@Bean
public FieldSetMapper fieldSetMapper() {
BeanWrapperFieldSetMapper fieldSetMapper = new BeanWrapperFieldSetMapper();
fieldSetMapper.setPrototypeBeanName("person");
return fieldSetMapper;
}
@Bean
@Scope("prototype")
public Person person() {
return new Person();
}Fiexed Length File Format
구분자를 사용하는 delimited 파일뿐만 아니라, 고정길이의 파일에 대해서도 Reader를 지원한다.
크게 어려운 내용이나, 학습해둘 내용은 아닌것 같아서 기억만 해두고 나중에 사용시에 읽어 볼 수 있도록 링크로 대체한다.
Multiple Record Types Within a Single File
Exception Handling in Flat Files
라인을 토큰화할 때 예외가 발생할 수 있다.형식이 잘못된 레코드가 있는 불완전한 플랫 파일도 많다.
대부분 잘못된 라인은 라인원본과 라인번호를 로깅하고 그냥 넘어가길 선택한다.
나중에 로그를 수동으로 확인하거나 다른 배치 job으로 점검하는 방식이다.
이런 경우 파싱 예외를 처리할 수 있도록 스프링 배치는 Exception계층을 제공한다.
FlatFileParseException과 FlatFileFormatException 을 제공한다.
- FlatFileParseException : 파일을 읽어들이는 동안 에러가 발생했을 때
- FlatFileFormatException :
LineTokenizer인터페이스 구현부에서 던져지는데, 토큰화 중 좀 더 구체적인 에러가 발생한 케이스다. - IncorrectTokenCountException :
FieldSet을 만들 때 사용할 컬럼명 갯수가 실제 토큰화한 컬럼 수와 다르다면 FieldSet을 만들 수 없으므로 Error를 발생한다.
tokenizer.setNames(new String[] {"A", "B", "C", "D"});
try {
tokenizer.tokenize("a,b,c");
}
catch(IncorrectTokenCountException e){
assertEquals(4, e.getExpectedCount());
assertEquals(3, e.getActualCount());
}- IncorrectLineLengthException : 고정길이를 사용하는 파일은 구분자를 사용하는 파일과 달리, 각 컬럼의 길이가 미리 정의되어있기 때문에 요구사항이 하나 더있다. 즉
한 줄의 길이가 정해진 컬럼의 길이와 일치 하지않는다면 해당 예외를 발생시킨다.
tokenizer.setColumns(new Range[] { new Range(1, 5),
new Range(6, 10),
new Range(11, 15) });
try {
tokenizer.tokenize("12345");
fail("Expected IncorrectLineLengthException");
}
catch (IncorrectLineLengthException ex) {
assertEquals(15, ex.getExpectedLength());
assertEquals(5, ex.getActualLength());
}FlatFileItemWriter
플랫을 write 할 때는 read할 때와 같은 이슈가 있다. step은 트랜잭션을 지원하면서 구분자(delimit)형식이나 고정길이형식으로 write할 수 있어야 한다.
LineAggregator
item을 String으로 바꿔 파일에 기록하려면 여러 필드를 하나의 String으로 만들 방법이 필요하다.
LineAggregator가 그 역할을 하고 있다
public interface LineAggregator<T>{
public String aggregate(T item);
}LineAggregator는 논리적으로 LineTokenizer와 정반대다. item을 받아 String을 리턴한다.
가장 흔히 사용하는 LineAggregator의 구현체는 PassThroughLineAggregator이다.
public class PassThroughLineAggregator<T> implements LineAggregator<T> {
public String aggregate(T item) {
return item.toString();
}
}Simplified File Writing Example
- wirte 할 객체를
LineAggregator로 넘겨String을 리턴받는다. String을 설정해둔 파일에 쓴다.
다음 코드는 FlatFileItemWriter의 write()이다.
public void write(T item) throws Exception {
write(lineAggregator.aggregate(item) + LINE_SEPARATOR);
}@Bean
public FlatFileItemWriter itemWriter() {
return new FlatFileItemWriterBuilder<Foo>()
.name("itemWriter")
.resource(new FileSystemResource("target/test-outputs/output.txt"))
.lineAggregator(new PassThroughLineAggregator<>())
.build();
}FieldExtractor
앞에 나온 예제도 유용하지만, FlatFileItemWriter는 대부분 도메인 객체와 사용하며, 그 객체를 문자열로 바꿔야 한다.
- item을 Writer에 전달한다.
- item의 필드를 배열로 반환한다.
- 배열을 합쳐 문자열로 만든다.
public interface FieldExtractor<T> {
Object[] extract(T item);
}FieldExtractor 인터페이스 구현체는 전달받은 객체의 필드를 보고 배열을 만들고, 덕분에 구분자 사이나 혹은 고정 길이 라인 일부에 필드를 쓸 수 있다.
PassThroughFieldExtractor
컬렉션이나 맵을 배열로 추출할 때 사용한다
public class PassThroughFieldExtractor<T> implements FieldExtractor<T> {
*/ @Override
public Object[] extract(T item) {
if (item.getClass().isArray()) {
return (Object[]) item;
}
if (item instanceof Collection<?>) {
return ((Collection<?>) item).toArray();
}
if (item instanceof Map<?, ?>) {
return ((Map<?, ?>) item).values().toArray();
}
if (item instanceof FieldSet) {
return ((FieldSet) item).getValues();
}
return new Object[] { item };
}
}BeanWrapperFieldExtractor
BeanWrapperFieldSetMapper처럼 직접 도메인 객체를 변환하기보다는 도메인 객체를 배열로 바꾸게끔 설정가능하다.
BeanWrapperFieldExtractor<Name> extractor = new BeanWrapperFieldExtractor<>();
extractor.setNames(new String[] { "first", "last", "born" });
String first = "Alan";
String last = "Turing";
int born = 1912;
Name n = new Name(first, last, born);
Object[] values = extractor.extract(n);
assertEquals(first, values[0]);
assertEquals(last, values[1]);
assertEquals(born, values[2]);BeanWrapperFieldSetMapper를 사용할때는 getter와 매핑하기 위한 필드명을 알아둬야할 필요는 있다.
Delimited File Writing Example
public class CustomerCredit {
private int id;
private String name;
private BigDecimal credit;
//getters and setters removed for clarity
}@Bean
public FlatFileItemWriter<CustomerCredit> itemWriter(Resource outputResource) throws Exception {
BeanWrapperFieldExtractor<CustomerCredit> fieldExtractor = new BeanWrapperFieldExtractor<>();
fieldExtractor.setNames(new String[] {"name", "credit"});
fieldExtractor.afterPropertiesSet();
DelimitedLineAggregator<CustomerCredit> lineAggregator = new DelimitedLineAggregator<>();
lineAggregator.setDelimiter(",");
lineAggregator.setFieldExtractor(fieldExtractor);
return new FlatFileItemWriterBuilder<CustomerCredit>()
.name("customerCreditWriter")
.resource(outputResource)
.lineAggregator(lineAggregator)
.build();
}Handling File Creation
FlatFileItemWriter의 경우 파일이 있다면 예외를던지고, 없으면 파일을 생성해서 쓴다.
하지만 만약 Job을 재시작하는 경우에는 반대의 경우가 된다.
파일이 있다면 마지막으로 썼던 위치에서 쓰고, 없다면 예외를 던진다.
만약 job의 파일명이 동일하다면?
재시작의 경우만 아니라면 존재하는 파일을 지우고 새로 쓰는 옵션이 있다.
shouldDeleteIfExists 프로퍼티를 사용하면 가능하다.
Json Item Readers And Writers
json 리소스를 읽고 쓰는 객체를 지원한다.
JsonItemReader
jsonItemReader는 json 파싱을 JsonObjectReader인터페이스 구현체에 위임한다. 이 인터페이스는 JSON 오브젝트를 청크로 읽을 수 있는 스트리밍 API로 구현한다.
JsonObjectReader는 2가지 구현체로 구현되어있다.
- JacksonJsonObjectReader
- GsonJsonObjectReader
JSON으로 write 하려면 다음이 필요하다
Resource, JsonObjectMarshaller
JsonObjectMarshaller : 객체를 JSON 형식으로 마샬링하는 객체
@Bean
public JsonFileItemWriter<Trade> jsonFileItemWriter() {
return new JsonFileItemWriterBuilder<Trade>()
.jsonObjectMarshaller(new JacksonJsonObjectMarshaller<>())
.resource(new ClassPathResource("trades.json"))
.name("tradeJsonFileItemWriter")
.build();
}JsonFileItemWriter
JsonFileITemWriter는 마샬링을 JsonObjectMarshaller 인터페이스에 위임한다.
마샬링도 위와 마찬가지로 2가지 구현체로 되어있다
- JacksonJsonObjectMarshaller
- GsonJsonObjectMarshaller
Json을 처리하려면 다음이 필요하다.
Resource, JsonObjectReader
Database
배치는 시스템이 처리해야 하는 데이터 셋 사이즈가 다르다는 점에서 다른 어플리케이션과 구분된다. 백만 개의 로를 리턴하는 SQL을 사용하면 결과셋이 모두 row를 다 읽을 때까지 메모리에 유지된다. 스프링 배치는 이를 해결할 수 있는 두가지 솔루션을 제공한다.
- 커서 기반
ItemReader구현체 - 페이징 기반
ItemReader구현체
Cursor-based ItemReader Implementations
데이터 베이스 커서는 관계형 데이터를 스트리밍 해주는 데이터베이스 솔루션이기 때문에, 배치에서도 가장 일반적으로 사용하는 접근법이다.
자바 ResultSet 클래스는 본질적으로 커서를 조직하기 위한 객체다.
스프링 배치의 커서 기반 ItemReader구현체는 초기화할 때 커서를 열고 read를 호출할 때마다 커서를 한 행씩 이동시켜서, 나중에 처리할 수 있는 매핑된 객체를 호출한다.
그다음 모든 리소스를 반환할 수 있게 close 메소드를 호출한다.
JdbcTemplate은 콜백 패턴을 사용해서 ResultSet의 모든 로를 매핑하고 제어가 호출부로 넘어가기전에 close 시킨다. 하지만 배치에서는 step이 종료될 때까지 기다려야 한다.
아래 이미지는 커서 기반 ItemReader의 동작 원리를 표현하는 일반적인 다이어그램이다.
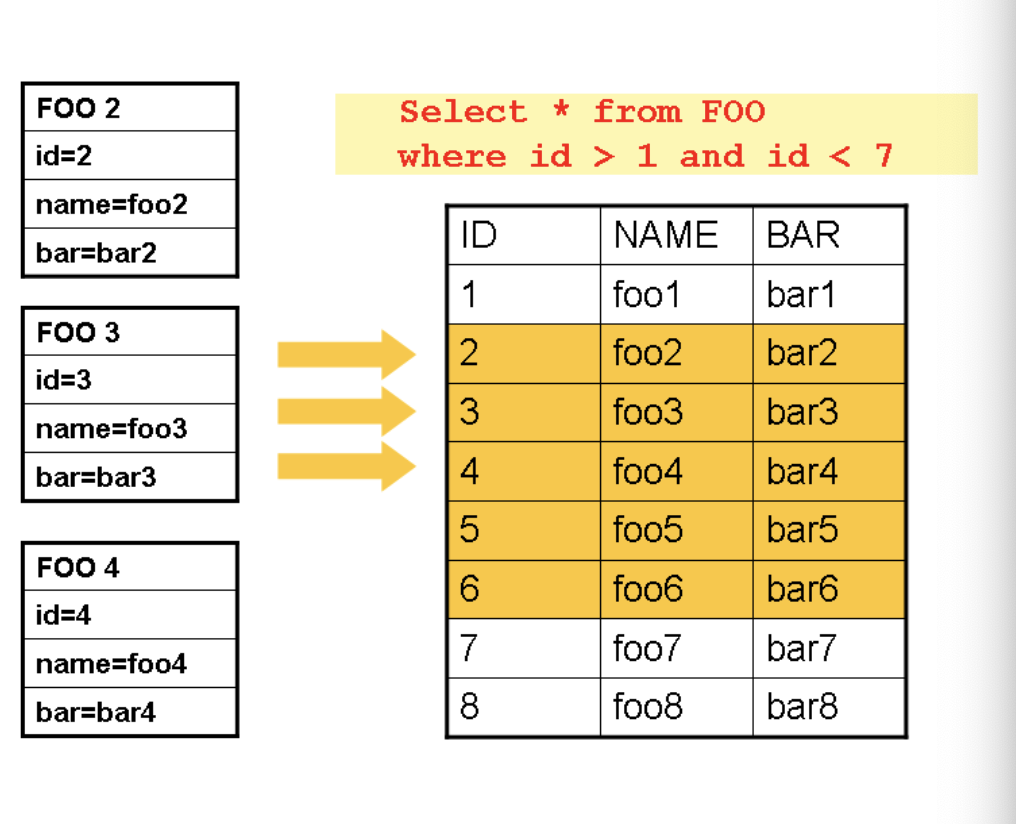
read가 호출될때마다 바로 결과를 쓰기 때문에 이미 읽은 객체는 가비지 컬렉터에 수집될 수 있다.
즉, 현재 ID가 3번을 가리키고 있다면 2번은 이미 결과로 쓰여졌기 때문에 가바지 컬렉터에 수집되어 메모리를 절약할 수 있다.
JdbcCursorItemReader
JdbcCussorItemReader 는 커서 기반 테크닉을 구현한 JDBC 구현체다. ResultSet 과 함께 동작하며, DataSource에서 커넥션을 얻어와서 SQL을 실행한다.
public class CustomerCreditRowMapper implements RowMapper<CustomerCredit> {
public static final String ID_COLUMN = "id";
public static final String NAME_COLUMN = "name";
public static final String CREDIT_COLUMN = "credit";
public CustomerCredit mapRow(ResultSet rs, int rowNum) throws SQLException {
CustomerCredit cusotmerCredit = new CustomerCredit();
customerCredit.setId(rs.getInt(ID_COLUMN));
customerCredit.setName(rs.getString(NAME_COLUMN));
customerCredit.setCredit(rs.getBigDecimal(CREDIT_COLUMN));
return customerCredit;
}
}
만약 CUSTOMER 데이터베이스에 1000개의 Row가 있다고 가정한다.
JdbcTemplate jdbcTemplate = new JdbcTemplate(dataSource);
List customerCredits = jdbcTemplate.query("SELECT ID, NAME, CREDIT from CUSTOMER",
new CustomerCreditRowMapper());위코드를 실행하게 되면 customerCredit 리스트에서는 1000개의 customerCredit 객체가 있을 것이다.
JdbcCursorItemReader itemReader = new JdbcCursorItemReader();
itemReader.setDataSource(dataSource);
itemReader.setSql("SELECT ID, NAME, CREDIT from CUSTOMER");
itemReader.setRowMapper(new CustomerCreditRowMapper());
int counter = 0;
ExecutionContext executionContext = new ExecutionContext();
itemReader.open(executionContext);
Object customerCredit = new Object();
while(customerCredit != null){
customerCredit = itemReader.read();
counter++;
}
itemReader.close();위코드를 실행하고 나면 counter 값은 1000이 된다. 위 코드에 아까 리턴된 customerCredit을 리스트에 넣었다면 jdbcTemplate예제 결과와 완전히 같았을 것이다.
하지만 중요한건 ItemReader는 아이템을 스트림 처리해준다는점.
read 메소드를 한번 호출한다음 ItemWriter로 아이템을 쓸 수 있고, 다음 아이템을 다시 read 할 수 있다. 이를 통해 아이템을 주기적으로 커밋하면서 청크 단위로 쓸 수 있으며, 이는 고성능 배치 처리의 핵심이다.
아래처럼 Step에 주입하기에도 매우 쉽다.
@Bean
public JdbcCursorItemReader<CustomerCredit> itemReader() {
return new JdbcCursorItemReaderBuilder<CustomerCredit>()
.dataSource(this.dataSource)
.name("creditReader")
.sql("select ID, NAME, CREDIT from CUSTOMER")
.rowMapper(new CustomerCreditRowMapper())
.build();
}Additional Properties
자바에서 커서를 열때는 매우 다양한 옵션이 있기 때문에 jdbcCursorItemReader에 설정할 수 있는 프로퍼티도 다양하다.
| 프로퍼티 | 설명 |
|---|---|
| ignoreWarnings | SqLWarnings를 로깅할지 예외를 발생시킬지 결정한다. default는 true이다 |
| fetchSize | 데이터를 추가로 읽을때 데이터베이스에서 fetch 해야하는 row수를 설정한다. |
| maxRows | 한번에 가져올 수 있는 로수를 제한한다. |
| queryTimeout | 쿼리 실행을 얼마동안 기다릴지 초단위로 설정한다. 이 제한을 넘어가면 DataAccessException이 발생한다. |
| verifyCursorPosition | ItemReader는 동일한 ResultSet을 RowMapper 에 전달하므로 사용자가 ResultSet.next()를 실행하면 reader 내부에 count 이슈가 생길수 있다. 이값을 true로 지정하면 RowMapper를 호출한 후 커서 위치가 이전과 달라졌을 때 예외를 발생시킨다. |
| saveState | ItemStream#update(ExecutionContext) 메소드로 ExecutionContext에 reader 상태를 저장할지 결정한다. |
| driverSupportsAbsolute | JDBC 드라이버가 ResultSet커서 강제이동을 지원하는지 나타낸다. 해당 기능을 지원하는 드라이버를 사용한다면, 성능을 위해 true로 설정하는 게 좋다. step이 중간에 실패했을때 좋은 성능을 발휘한다. |
| setUseSharedExtendedConnection | ExtendedConnectionDataSource 로 감싸야 한다. true로 설정했을 땐 커서를 열 떄 사용하는 statement를 READ_ONLY와 HOLD_CURSORS_OVER_COMMIT상태로 생성한다. |
HibernateCursorItemReader
Spring batch는 HibernateCursorItemReader도 지원한다.
스프링 배치에서는 배치에서 문제가 생길수 있는 하이버네이트의 캐싱과 엔터티 변경을 사용하지 않기 위해 표준 세션대신 StatelessSession을 사용한다.
HibernateCursorItemReader에 HQL문을 선언하면 SessionFactory를 전달하고, JdbcCursorItemReader와 같은 방식으로 read를 호출할 때마다 아이템 하나를 돌려준다.
HibernateCursorItemReader itemReader = new HibernateCursorItemReader();
itemReader.setQueryString("from CustomerCredit");
//For simplicity sake, assume sessionFactory already obtained.
itemReader.setSessionFactory(sessionFactory);
itemReader.setUseStatelessSession(true);
int counter = 0;
ExecutionContext executionContext = new ExecutionContext();
itemReader.open(executionContext);
Object customerCredit = new Object();
while(customerCredit != null){
customerCredit = itemReader.read();
counter++;
}
itemReader.close();Customer 테이블을 위한 적절한 하이버네이트 매핑 파일이 있다면, 여기서 설정한 ItemReader는 JdbcCursorItemReader에서 설명한 방법과 정확하게 일치하는 방법으로 CustomerCredit 을 리턴한다.
@Bean
public HibernateCursorItemReader itemReader(SessionFactory sessionFactory){
return new HibernateCursorItemReaderBuilder<CustomerCredit>()
.name("creditReader")
.sessionFactory(sessionFactory)
.queryString("from CustomerCredit")
.build();
}Paging ItemReader Implementations
데이터 베이스 커서를 사용하는 다른 방법은 결과의 일부만 가져오는 쿼리를 여러번 가져오는 것이다. 이 결과의 일부를 페이지라고 한다.
JdbcPagingItemReader
JdbcPagingItemReader는 ItemReader의 페이징 구현체다. JdbcPagingItemReader는 PagingQueryProvider 로부터 row를 페이지로 구성해 돌려주는 SQL 쿼리를 제공받아야 한다. 데이터 베이스마다 페이징 지원 전략이 다르기 때문에 각 데이터베이스 지원 유형 마다 다른 PagingQueryProvider 를 사용한다. 사용할 데이터베이스를 자동으로 감지하고 적절한 PagingQueryProvider 구현체를 결정해주는 SqlPagingQueryProviderFactoryBean이라는 것도 있다.
SqlPagingQueryProviderFactoryBean을 사용하려면 Select절과 from절이 필요하다.
example
@Bean
public JdbcPagingItemReader itemReader(DataSource dataSource, PagingQueryProvider queryProvider) {
Map<String, Object> parameterValues = new HashMap<>();
parameterValues.put("status", "NEW");
return new JdbcPagingItemReaderBuilder<CustomerCredit>()
.name("creditReader")
.dataSource(dataSource)
.queryProvider(queryProvider)
.parameterValues(parameterValues)
.rowMapper(customerCreditMapper())
.pageSize(1000)
.build();
}
@Bean
public SqlPagingQueryProviderFactoryBean queryProvider() {
SqlPagingQueryProviderFactoryBean provider = new SqlPagingQueryProviderFactoryBean();
provider.setSelectClause("select id, name, credit");
provider.setFromClause("from customer");
provider.setWhereClause("where status=:status");
provider.setSortKey("id");
return provider;
}JpaPagingItemReader
JpaPagingItemReader 는 페이징 처리를 지원하는 또 하나의 Item Reader 구현체다. JPA는 하이버네이트의 StatelessSession 같은 개념이 없기 때문에 JPA명세에서 제공하는 다른 기능을 사용해야 한다.
JpaPagingItemReader는 JPQL 문을 사용해서 EntityManagerFactory에 전달한다.
ItemReader의 기본방식대로 read를 호출할 때마다 아이템을 하나씩 돌려준다.
@Bean
public JpaPagingItemReader itemReader() {
return new JpaPagingItemReaderBuilder<CustomerCredit>()
.name("creditReader")
.entityManagerFactory(entityManagerFactory())
.queryString("select c from CustomerCredit c")
.pageSize(1000)
.build();
}Database ItemWriters
데이터베이스의 경우에는ItemWriter 인스턴스가 필요하지 않는다.
데이터베이스가 트랜잭션에 필요한 모든 기능을 제공해준다. (flush, clean)등
ItemWriter 인터페이스를 구현하는 DAO를 만들거나 일반적인 문제를 처리하는 ItemWriter 를 사용하면 된다.
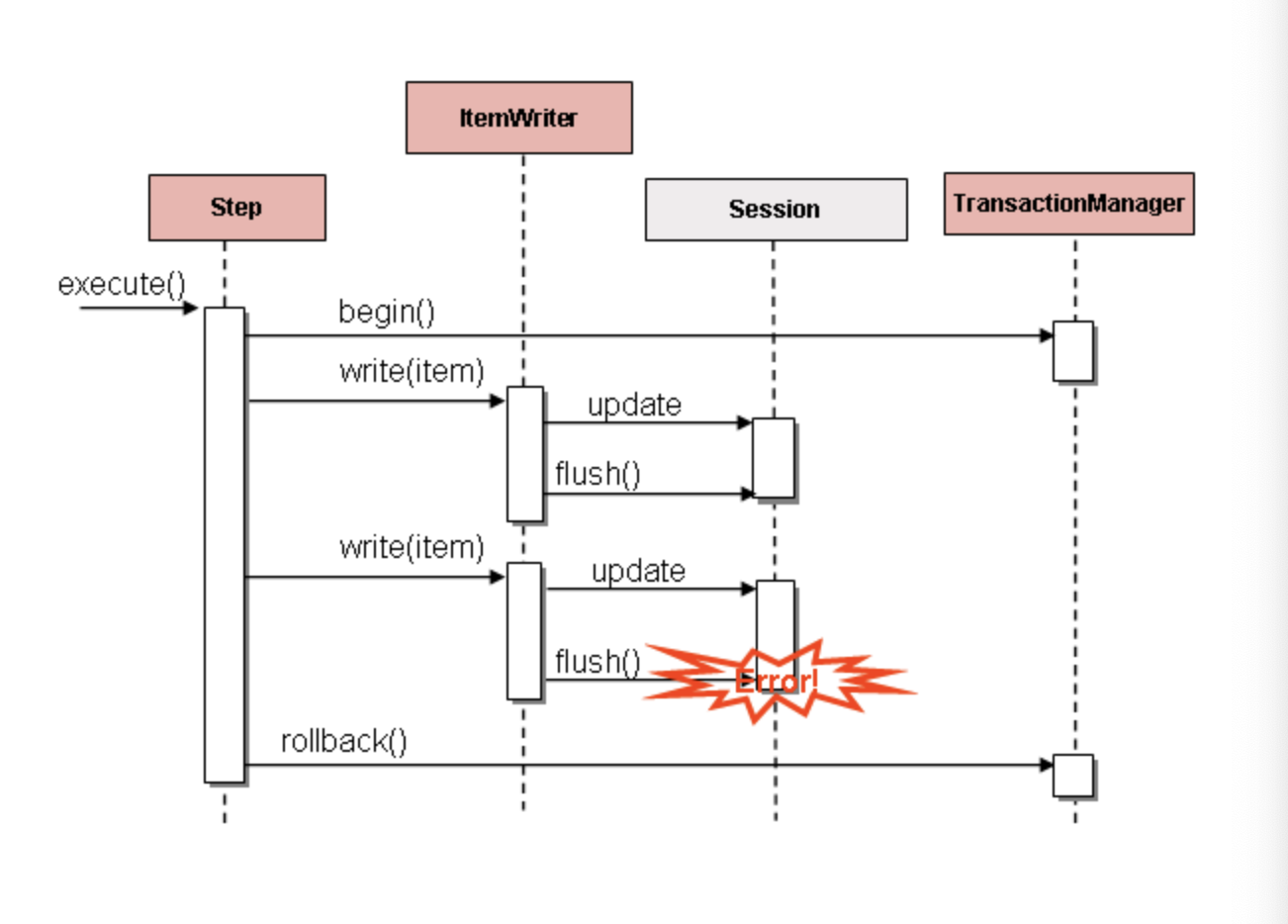
다만 주의해야할점이 Hibernate 가 아니라 JDBC 배치 모드를 사용할 때는, 데이터를 쓰는동안 발생한 에러는 충돌을 발생 시킬 수 있다.
이때는 아이템 하나 때문에 문제가 발생했다해도 어떤아이템이 예외를 발생시켰는지 알 수 없다.
그래서 jdbcTemplate를 사용할때에는 write를 호출할때마다 flush 할 수 있도록 ItemWriter를 구현하도록 가이드 하고있다.