링크: https://school.programmers.co.kr/learn/courses/30/lessons/43165
문제 설명
n개의 음이 아닌 정수들이 있습니다. 이 정수들을 순서를 바꾸지 않고 적절히 더하거나 빼서 타겟 넘버를 만들려고 합니다. 예를 들어 [1, 1, 1, 1, 1]로 숫자 3을 만들려면 다음 다섯 방법을 쓸 수 있습니다.
1+1+1+1+1 = 3 +1-1+1+1+1 = 3 +1+1-1+1+1 = 3 +1+1+1-1+1 = 3 +1+1+1+1-1 = 3
사용할 수 있는 숫자가 담긴 배열 numbers, 타겟 넘버 target이 매개변수로 주어질 때 숫자를 적절히 더하고 빼서 타겟 넘버를 만드는 방법의 수를 return 하도록 solution 함수를 작성해주세요.
제한사항
- 주어지는 숫자의 개수는 2개 이상 20개 이하입니다.
- 각 숫자는 1 이상 50 이하인 자연수입니다.
- 타겟 넘버는 1 이상 1000 이하인 자연수입니다.
입출력 예
| numbers | target | return |
|---|---|---|
| [1, 1, 1, 1, 1] | 3 | 5 |
| [4, 1, 2, 1] | 4 | 2 |
입출력 예 설명
입출력 예 #1
문제 예시와 같습니다.
입출력 예 #2
+4+1-2+1 = 4 +4-1+2-1 = 4
- 총 2가지 방법이 있으므로, 2를 return 합니다.
문제풀이
목표: 사용할 수 있는 숫자가 담긴 배열 numbers, 타겟 넘버 target 이 매개변수로 주어질 때 숫자를 적절히 더하고 빼서 타겟 넘버를 만드는 방법의 수를 return
내 풀이:
numbers 의 각 숫자별로 더하거나 빼거나 두 가지 경우의 수가 존재하고, 그 더하거나 빼는걸 어떻게 구현해야 하지? 고민하던 중 문제 위에 깊이/너비 우선 탐색(DFS/BFS)를 발견해버렸다. 하지만 배운지 오래되어 기억이 가물가물… 구글링을 해보자.
✅ DFS(Depth-First Search) - 깊이 우선 탐색
DFS는 트리나 그래프의 루트(또는 시작 노드)에서 출발해, 가능한 한 깊이(자식 노드)로 내려가며 탐색하는 방법. 자식 노드가 더 이상 없을 경우, 가장 최근의 부모 노드로 돌아와서 다른 자식을 탐색.
동작 방식:
- 시작 노드에서 출발하여, 아직 방문하지 않은 노드를 깊이 탐색.
- 현재 노드에서 가능한 한 자식 노드를 방문하며 탐색을 진행.
- 더 이상 방문할 자식 노드가 없으면, 다시 부모 노드로 돌아가서 다른 자식 노드를 탐색.
- 이 과정을 반복하여 모든 노드를 방문.
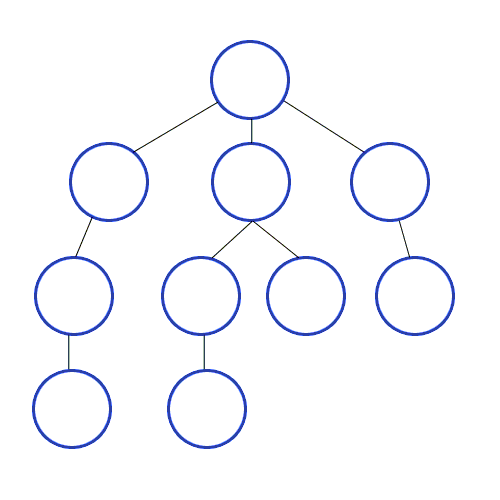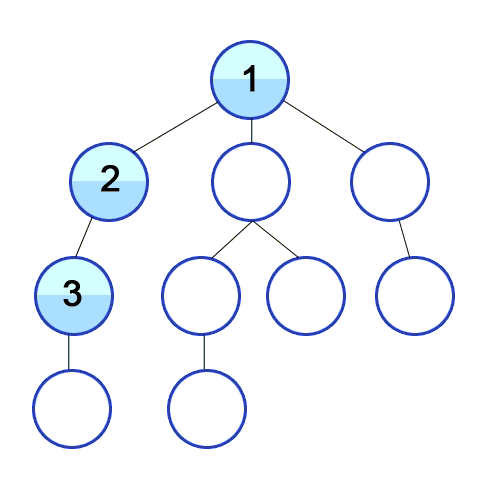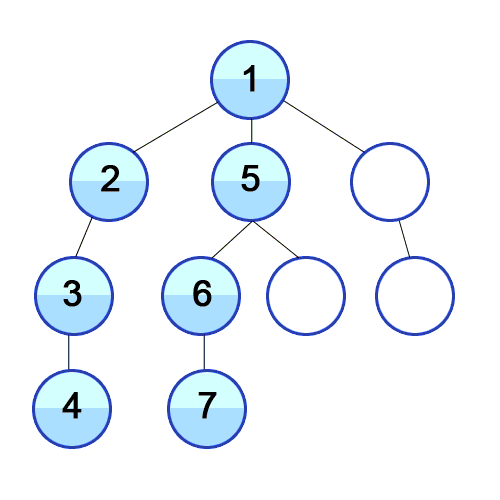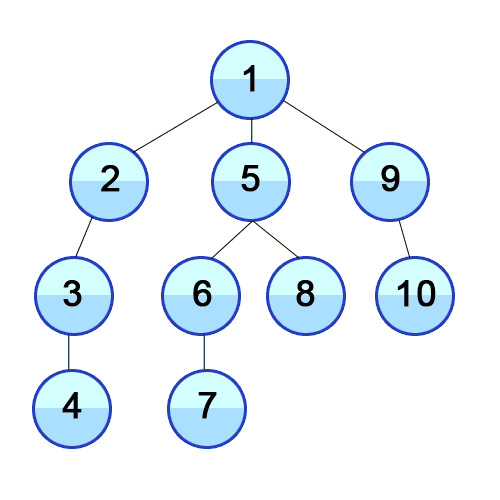
출처: 위키미디어
✅ BFS(Breadth-First Search) - 너비 우선 탐색
BFS는 시작 노드에서 출발해 인접한 모든 노드를 우선적으로 탐색한 후, 그 다음 레벨의 노드를 탐색하는 방법. 한 단계(레벨)의 모든 노드를 탐색한 후에야 다음 단계로 넘어가는 방식.
동작 방식:
- 시작 노드에서 출발하여, 모든 인접 노드를 큐에 넣는다.
- 큐에서 노드를 하나씩 꺼내며, 해당 노드의 인접 노드를 다시 큐에 추가한다.
- 이 과정을 반복해 모든 노드를 방문한다.
출처: 위키미디어
{kind=link}
DFS, BFS 동작 비교
DFS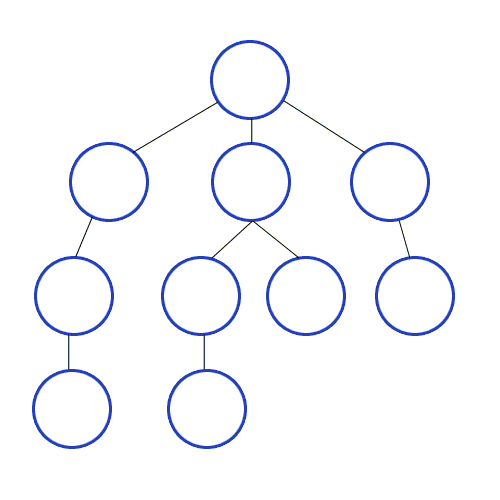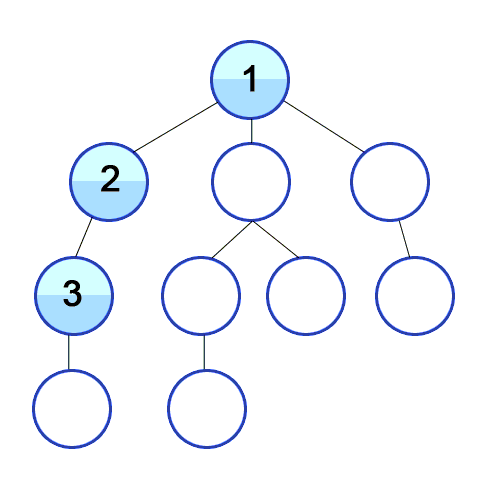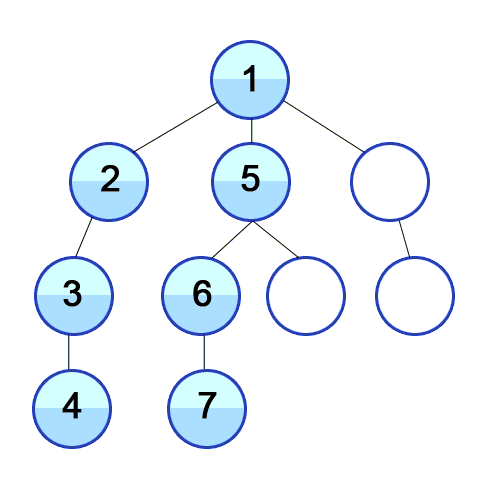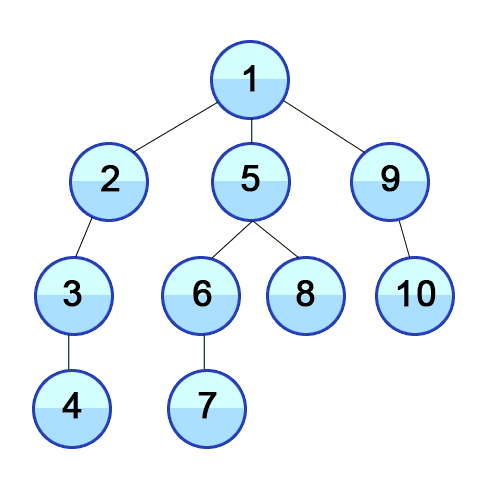 | BFS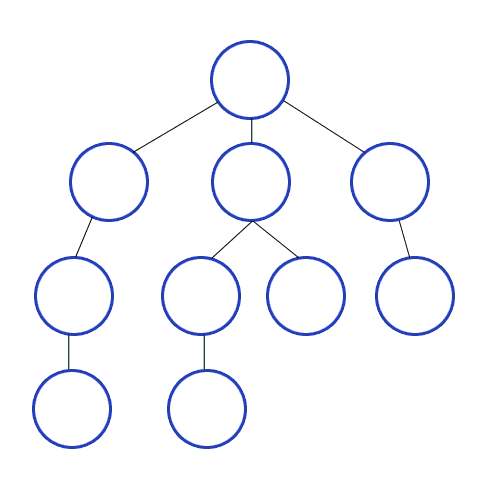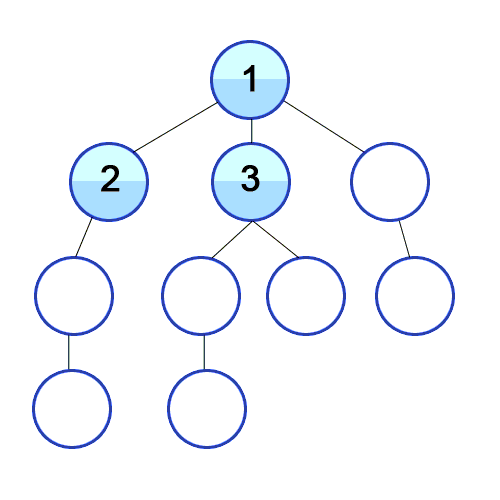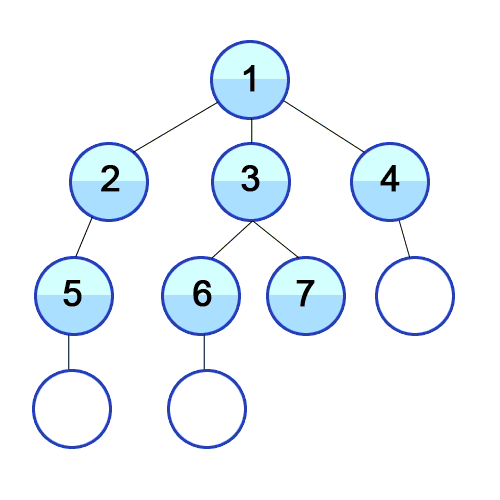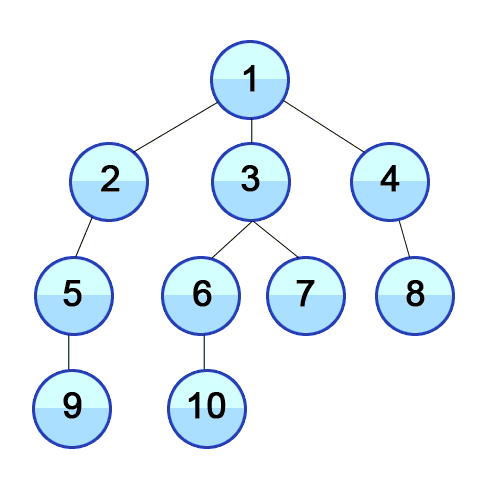 |
|---|
그러면 DFS, BFS에 대해서 알게 됐으니 각각의 방식으로 문제를 풀어보자.
✅ DFS 코드 구현
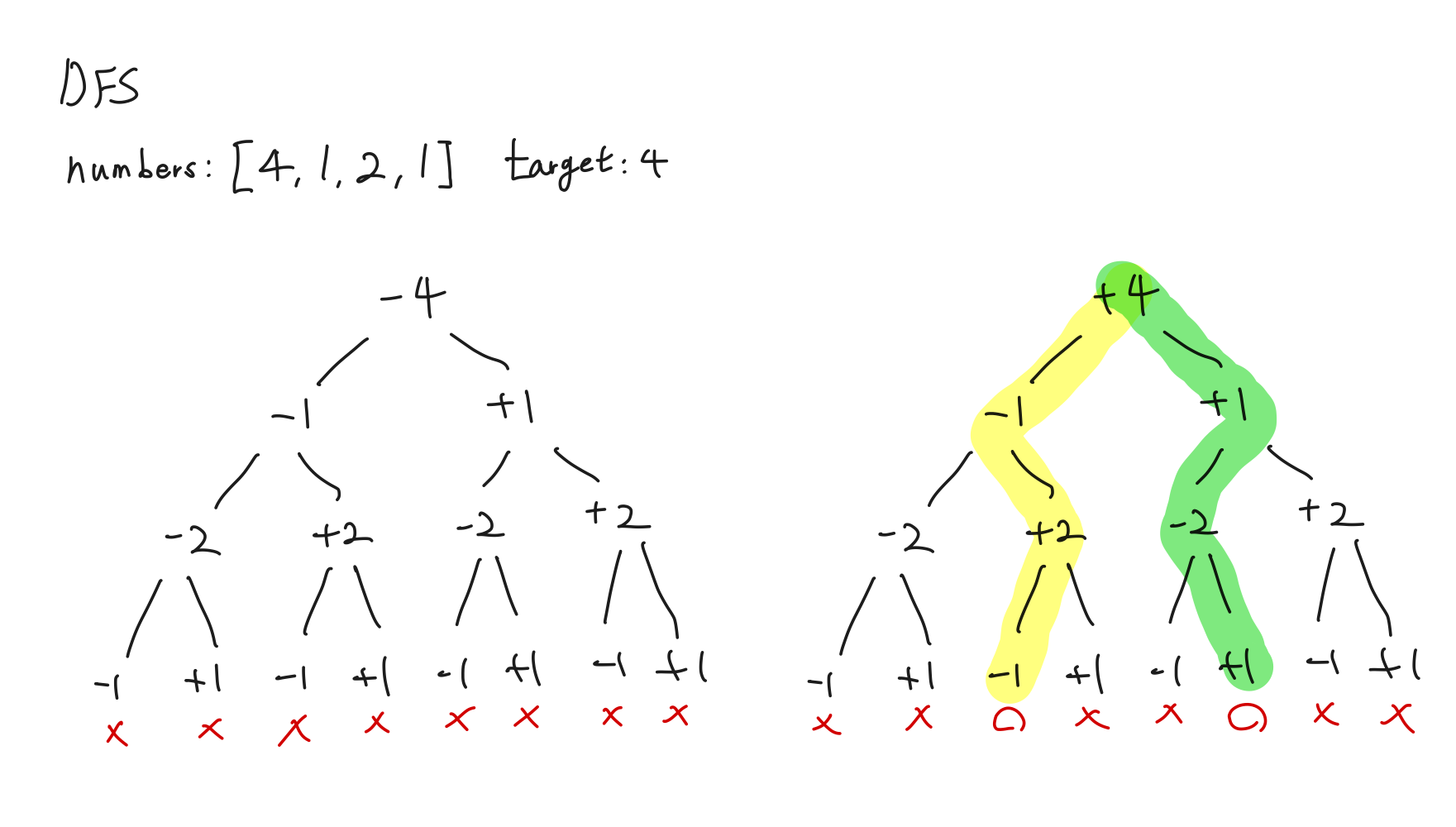
def dfs(numbers, target, idx, values, cnt): # idx: 깊이, values: 현재까지의 합, cnt: 타겟 넘버를 만들 수 있는 방법의 수
# 깊이가 끝까지 닿았고, 합이 타겟과 같으면 카운트를 증가
if idx == len(numbers):
if values == target:
return cnt + 1
return cnt
# 재귀함수로 탐색을 진행 (카운트 값을 계속 넘겨줌)
cnt = dfs(numbers, target, idx + 1, values + numbers[idx], cnt)
cnt = dfs(numbers, target, idx + 1, values - numbers[idx], cnt)
return cnt
def solution(numbers, target):
cnt = dfs(numbers, target, 0, 0, 0) # 초기 인덱스, 합, cnt는 0으로 시작
return cnt✅ BFS 코드 구현
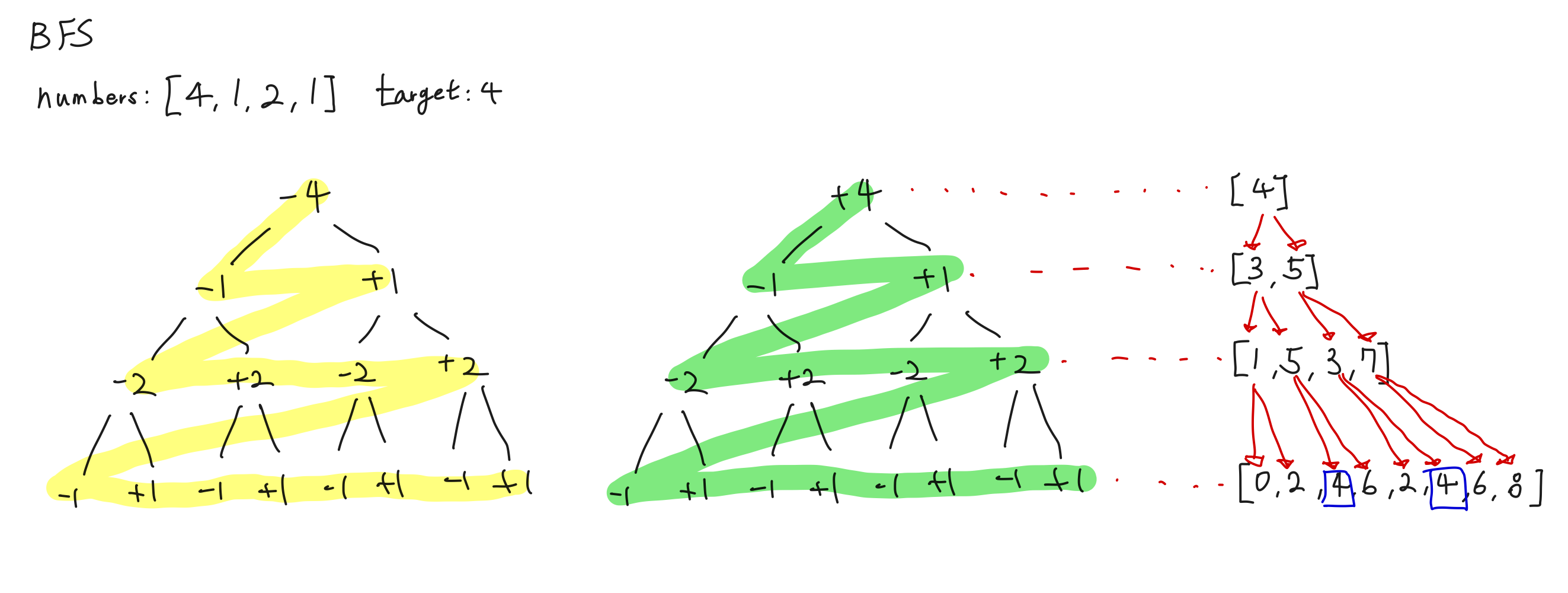
그리고 보니 모양이 좀…def solution(numbers, target):
leaves = [0] # 초기 상태: 0으로 시작
cnt = 0
for num in numbers:
temp = []
# 현재 단계의 모든 노드에 대해 두 가지 연산을 적용
for leaf in leaves:
temp.append(leaf + num) # 숫자를 더하는 경우
temp.append(leaf - num) # 숫자를 빼는 경우
leaves = temp # 다음 단계의 노드로 업데이트
# 모든 경우의 수에서 타겟과 일치하는 값을 찾기
for leaf in leaves:
if leaf == target:
cnt += 1
return cnt✅ 성능 비교
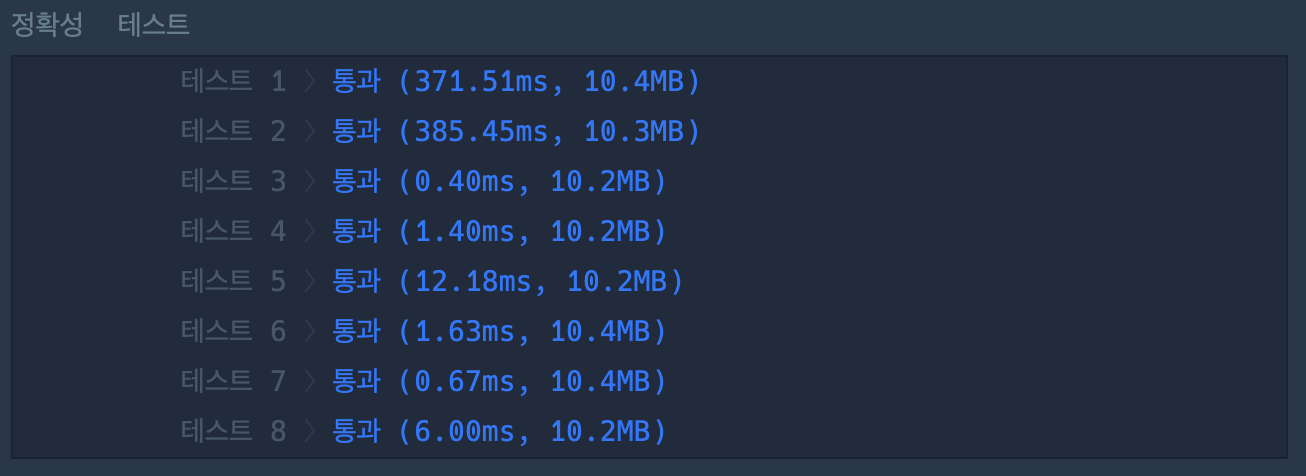
- DFS
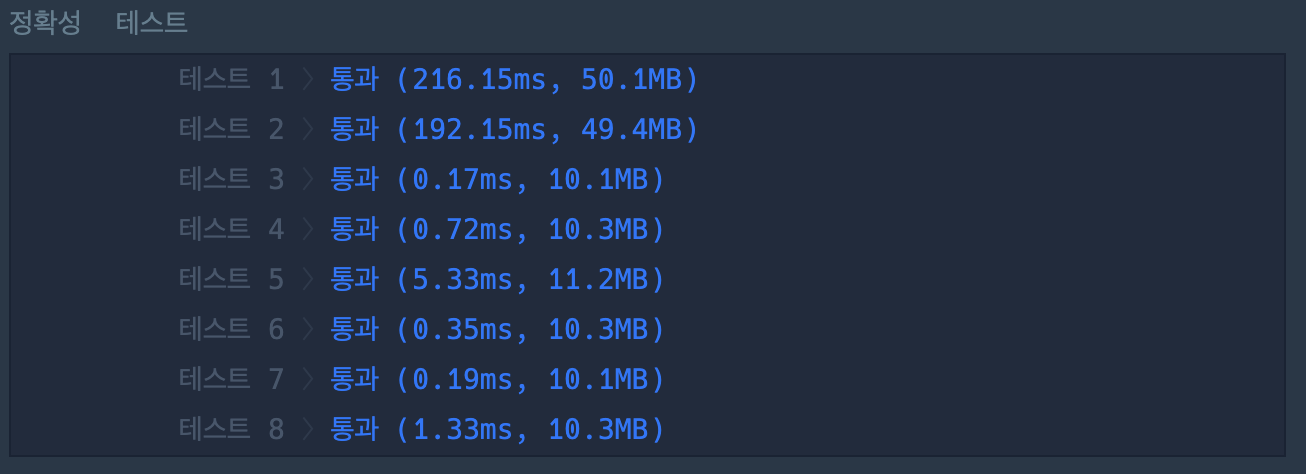
- BFS
결과:
- DFS:
- DFS는 BFS에 비해 실행 시간이 더 길어, 깊이 탐색이 비교적 비효율적일 수 있다.
- 하지만, 현재 경로만 저장하면 되므로 메모리 사용량이 적다.
- BFS:
- BFS 방식이 DFS보다 실행 시간이 더 짧다.
- 하지만, BFS는 모든 가능한 상태를 큐에 저장해야 하므로 메모리 소모가 크다.
