쿠버네티스 (kubernetes)
컨테이너 오케스트레이션 도구 중의 하나이다.
컨테이너화된 애플리케이션을 자동으로 배포, 조정, 관리할 수 있는 오픈소스 플랫폼이다.
- nginx, spring, mysql 등을 Docker로 만들었을 때
- 서버가 많아지고, 컨테이너가 수십~수백 개가 되면
- 자동 배포/확장/장애 복구/트래픽 분산이 필요함
→ 이걸 자동화하는 것이 Kubernetes
컨테이너 오케스트레이션의 특징
- 컨테이너 자동 배치 및 복제 : ReplicaSet, Deployment
- 컨테이너 그룹에 대한 로드밸런싱 : Service, ClusterIP, LoadBalancer, Ingress
- 컨테이너 장애 복구 : Self-healing, LivenessProbe, ReadinessProbe, Deployment, ReplicaSet
- 클러스터 외부에 서비스 노출 : NodePort, LoadBalancer, Ingress
- 컨테이너 확장 및 축소 : Horizontal Pod Autoscaler (HPA)
- 컨테이너 서비스 간 인터페이스를 통한 연결 : Service, DNS
클러스터(Cluster)
여러 대의 컴퓨터(노드)를 하나처럼 묶어서 사용하는 시스템 구조이다.
-
쿠버네티스는 여러 개의 노드를 하나의 논리적인 그룹으로 구성해 앱을 안정적이고 자동화된 방식으로 운영한다.
-
Master node : 클러스터의 상태를 관리
-
Worker node : App 실행
-
Master 는 Azure 등에서 제공, Worker를 사용한 만큼만 돈을 냄
-
여러 노드들을 묶어서 앱을 자동으로 배포/관리한다.
-
카프카 클러스터도 여러 브로커(서버)를 묶어서 메시지를 안정적으로 송수신한다.
CNCF (Cloud Native Computing Foundation)
클라우드 네이티브 기술을 표준화하고 발전시키는 재단
쿠버네티스를 비롯한 다양한 오픈소스 인프라 기술을 관리/지원하는 조직
- 한 기업이 소유하면 독점적 방향으로 가기 쉬움
- 중립적으로 여러 기술을 공동 관리한다.
대표적인 프로젝트
- Kubernetes (컨테이너 오케스트레이션)
Container Orchestration의 기능
자가 치유
원하는 상태 (desired) 을 유지하도록 노력하는 것이다.
desired(4) <- actual(3) 로 하도록 노력하는 것
- 예: 사용자가 4개 컨테이너를 원하면 (desired = 4)
- 실제 컨테이너가 3개면 (actual = 3) → 1개를 자동으로 생성
- 비어있는 곳에 생성하거나 사용하지 않지만 pool에서 가져온 곳에 생성한다.
확장
요청이 많아지면 컨테이너 수를 늘린다.
need to scale out 으로 desired == actual일 떄 더 필요하다고 보낸다.
무중단 배포
앱을 중단하지 않고, 점진적으로 새 버전으로 교체한다.
- 기존의 컨테이너를 하나씩 내리고,
- 새 버전을 하나씩 올린다.
- 새로운 업데이트에 대해서 찰나에 순간에 서비스가 중단될 수 있다. (ex 게임)
정기점검, 임시점검, 연장점검, 긴급점검 => 쿠버네티스가 이걸 막아준다.
AKS(Azure Kubernetes Service)
MS azure에서 쿠버네티스를 쉽게 쓸 수 있게 도와주는 서비스이다
복잡하게 직접 쿠버네티스를 설치하지 않아도, ASK를 사용해서 버튼 몇 번 클릭으로 구버네티스를 자동으로 설치해준다.
- azure에서는 계정관리 azure ad(active directory) 로 관리한다.
- user, groups, apps 을 이용해서 권한 인증을 한다.
- 구독(Azure Subscriptions) 이라는 단위(돈을내는 단위)로 여러 리소스를
여러 리소스를 묶여서 리소스 그룹이라고 한다. - 리소스들 중에서 쿠버네티스 서비스를 사용한다.
acr registry 로 컨테이너 저장소
- 전체 흐름
- Azure 로그인(users)
- 구독(Azure Subscriptions) 확인 (어떤 요금제 쓸지)
- 리소스 그룹 만들기 (리소스들을 묶는 바구니)
- AKS 클러스터 만들기 (쿠버네티스 서버)
- 연결해서 내 앱 배포하기
- 리소스 그룹 만들기
Azure 리소스들을 묶어서 관리하는 논리적 컨테이너
- 리소스 그룹명 예시: a071212-rsrcgrp
- 영역(Region): Korea Central (한국 서울 리전)
- 이 그룹 안에 쿠버네티스 클러스터, 노드, 네트워크, 디스크 등이 함께 배치됨
- 쿠버네티스 서비스 생성
Azure에서 제공하는 완전관리형 Kubernetes 클러스터 서비스
- 클러스터 이름 예시: a071212-aks
- 클러스터 유형: 개발/테스트용 선택 (비용 낮고 구성 단순)
- Production 클러스터는 고가용성, 보안, 로깅 등이 추가되어 복잡하고 비쌈
- agent pool
실제 컨테이너(Pod)를 실행시키는 워커 노드(Worker Node) 들이 포함된 풀
워커 노드
- 쿠버네티스 클러스터에서 컨테이너를 실제로 실행하는 VM
- Azure는 마스터 노드는 무료로 제공한다
- 워커 노드 비용만 사용자가 지불한다.
노드 사양 예시
- DS2_v2: 2 vCPU / 7GB RAM
- 테스트/개발 환경에 적합
- 여러 개의 워커 노드를 묶은 것이 노드 풀(Node Pool)
- 도커 로그인과 Azure CLI 연동
- 보통 AKS는 도커 이미지 기반 앱을 실행하기 때문에 docker login이 필요
az- kubectl : 쿠버네티스 제어툴
쿠버네티스를 제어하는 대표 CLI 도구
- 쿠버네티스 자체에 손을 대려면
kubectl을 사용한다. - 쿠버네티스를 다루는 tool 에게 azure 로그인 이후에 접속 정보를 받아서 넣어줘야 한다.
실습1 : Azure에서 쿠버네티스
구독확인
리소스 그룹
만들기 > 구독누르고 > 리소스그룹 이름 설정

Azure Kubernetes Service 생성
만들기 > 쿠버네티스 클러스터 > 구독 > 리소스그룹(생성했던거) > 클러스터 세부 정보(반드시 개발/테스트) > 쿠버네티스 이름 설정
다음 > 노드 풀(worker node 모음) > 크기 선택 DS2_v2 , 최소2 최대2 설정 > 업데이트

설치 확인
초기 세팅
/init.sh 을 터미널에 입력하면 초기 세팅을 해준다.
sudo apt-get update
sudo apt-get install net-tools
sudo apt install iputils-ping
pip install httpie
curl -LO "https://dl.k8s.io/release/$(curl -L -s https://dl.k8s.io/release/stable.txt)/bin/linux/amd64/kubectl"
sudo install -o root -g root -m 0755 kubectl /usr/local/bin/kubectl
curl -sL https://packages.microsoft.com/keys/microsoft.asc | gpg --dearmor | sudo tee /etc/apt/trusted.gpg.d/microsoft.gpg > /dev/null
echo "deb [arch=amd64] https://packages.microsoft.com/repos/azure-cli/ jammy main" | sudo tee /etc/apt/sources.list.d/azure-cli.list
sudo apt update
sudo apt install azure-cli
- kubectl : 쿠버네티스를 다루기 위함
- azure-cli : azure 다루기
터미널에서 az와 kubectl 으로 확인한다.
클라이언트의 CLI 환경을 준비
curl -sL https://aka.ms/InstallAzureCLIDeb | sudo bash

클라이언트 Client 설정
az aks get-credentials --resource-group (RESOURCE-GROUP-NAME) --name (Cluster-NAME)
어디 클러스트에 붙는지에 따라서

kubectl get all 으로 쿠버네티스의 서비스 객체를 확인할 수 있다.

kubectl get node 으로 워커 노드들의 목록을 확인할 수 있다.

Kubernetes 기본 구성 관계
[Deployment]
↓ (자동으로 생성)
[ReplicaSet]
↓ (자동으로 생성)
[Pod]
↓ (안에 포함)
[Container] ← Docker 이미지가 메모리에 올라가서 실행되는 단위
Deployment는 가장 상위의 관리자이다.
몇개의 pod를 만들지, 업데이트는 어떻게 할지 전체를 관리한다.
ReplicaSet 은 실제로 pod의 개수를 유지한다.
3개를 유지한다면, 죽으면 다시 만든다.
Pod는 컨테이너가 들어 있는 실행 단위이다.
1개 또는 여러 컨테이너가 들어갈 수 있다.
Container 는 우리가 만든 이미지(jinyoung/monolith-order)가 메모리에 올라가서 실행되는 실제 앱
kubectl create deploy order --image=... 하면
- Deployment 생성됨
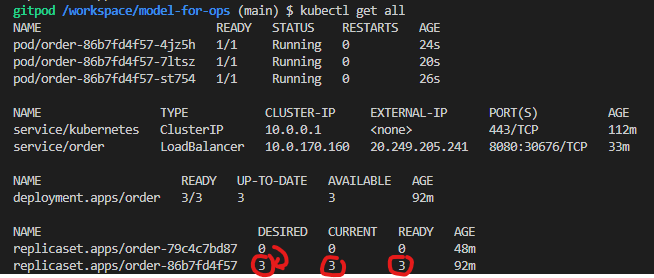
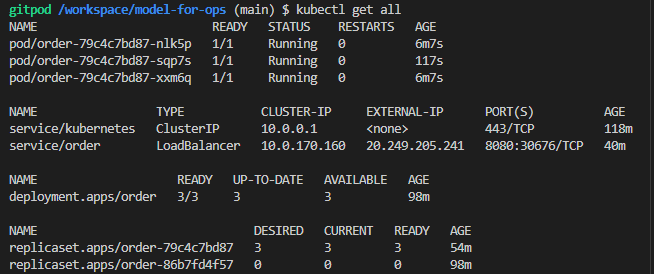
deployment.apps/order생성된다. - Deployment가 자동으로 ReplicaSet 생성
내부적으로replicaset.apps/order-86b7fd4f57생성된다. - ReplicaSet이 자동으로 Pod 생성
그 안에pod/order-86b7fd4f57-xxxxx생성된다. - Pod 안에서 Container가 실행됨 (이미지가 메모리에 올라감)
Deployment를 만들면 자동으로 ReplicaSet이 생성되고,
그 안에 Pod가 만들어지며,
Pod 안에서 우리가 만든 Container(Image) 가 메모리에 올라가 실행된다.
Pod
Pod는 Kubernetes의 가장 작은 배포 단위이다.
이 경우, order라는 이름의 Pod 하나가 생성되어 실행(Running) 중입니다.
컨테이너는 Pod 내부에 존재하며, Pod는 실제로 애플리케이션이 실행되는 공간입니다.
Pod 이름 뒤의 -86b7fd4f57-...은 자동 생성된 ReplicaSet과 고유 식별자입니다.
💡 요약: 컨테이너를 메모리에 올리고 실행하는 실질적인 실행 단위가 Pod입니다.
pod는 휘발성임
이상이 생기거나 문제가 있으면 바로 내린다.
pod의 연속
실습2 : 컨테이너 오케스트레이션
kubectl create deploy order --image=jinyoung/monolith-order:v202105042
deploy 는 개발하는 단위(배포하는 단위)
order 서비스를 배포단위로 배포한다. --image를 jinyoung/monolith-order:v202105042 으로 해서 해주세요
create 한거
접수만 한 상태이다. 확인 필요
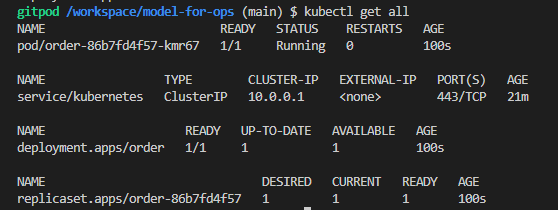
container가 서버 단위의 pod
pod는 이미지를 메모리에 올린 컨테이너 역할이다.
get all 만든 모든 객체를 다 가져오는 것
kubectl get pod
레플리카셋-pod의 고유id
컨테이너들은 여러개 생길 수 있고 고유한 아이디가 필요하다.

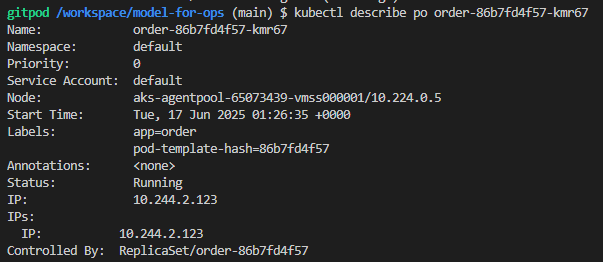
pod의 자세한 정보 출력
kubectl describe po [pod명]
- 이벤트
- 상태
- 어떤 이미지인지
- 어떤 노드에 있는지
가운데 노드에 배치했다.
pod 안에 컨테이너에서 출력된 로그 실시간 확인
kubectl logs -f order-86b7fd4f57-kmr67
kubectl exec -it order-86b7fd4f57-kmr67 -- bin/sh
내부파일 확인
pod 삭제
kubectl delete pod order-86b7fd4f57-kmr67
pod를 아예 지우려면 deploy를 지워야한다.
pod는 항상성? 되돌아가려는 성질이 있나.
외부에서 App에 접근하는 방식
2초에 한번씩 관측한다.
watch kubectl get pod
kubectl delete pod -l app=order
를 하면 ID와 age가 바뀐다. 항상성을 유지하려는 특징이 있다.
kubectl expose + LoadBalancer
목적
pod 들은 외부에서 바로 접근하기 어려워서, Service 객체를 통해 접근 가능하게 한다.
클라우드 벤더에서 퍼블릭 IP를 자동 할당해서 외부에서도 직접 접근할 수 있게 해준다.
- Deployment를 외부에 노출할 수 있는 Service를 생성한다.
LoadBalancer는 클라우드 환경에서 퍼블릭 IP를 자동으로 만들어서 외부에서 접속 가능하게 한다.
service 객체를 붙여줘야 실행이 가능하다.
pod 5개는 각각다 별도의 ip 포트를 가지고 있다.
외부에서 pod들에게 접속하려면 pod들의 포트들을 다 알아야한다.
이게 싫어서 api gateway를 사용한다.
pod는 일회성이여서 5개에서 -> 4개가 될 수도 이렇게 다이렉트로 pod를 가르킬 수 업음
서비스 디스커버리로 pod가 구동될 때 등록시키도록 하는 방법을 사용한다.
컨테이너들의 정보를 kubernetes는 다 알고 있다.
가상의 객체(접속용 객체) service 객체를 연결하고
여기에 pod들이 연결되어 있다.
이 것을 로드밸런서 겸 서비스디스커버리이다.
실제 pod와 상관없이 독립적으로 만들 수 있다. pod가 없어도 생성할 수 있다.
실물 세계를 pod., replica -set,
kubectl expose deploy order --type=LoadBalancer --port=8080
order라는 서비스 객체를 만들어라!
벤더사의
LoadBalancer 는 외부에서 바로 접속할 수 있는 ip를 벤더 사에서 제공한다.

로드밸런서는 ip 획득이 필요하고, ip획득에 따라서 비용이 발생한다.
kubectl port-forward
- Kubernetes 클러스터 안의 Pod(또는 Deployment)**에 직접 연결하는 임시 통신 터널을 만듦
- 현재 gitpod 컴퓨터에서 localhst:8080 -> 클러스터 내부의 Pod : 8080 에 직접 연결
kubectl port-forward deploy/order 8080:8080
서버의 8080으로 데이터를 쏘면 클러스터 안에 서비스에 접속된다.
- kubectl이 터널을 열고 직접 통신
- production에서는 비추 : 서버의 부하
- test용으로 사용하는 것을 추천한다.
instance 확장
레블리카 셋으로 pod를 확장 가능하다
scale deploy order
deploy order 를 대상으로 스케일을 desired를 3으로 해줘
kubectl scale deploy order --replicas=3
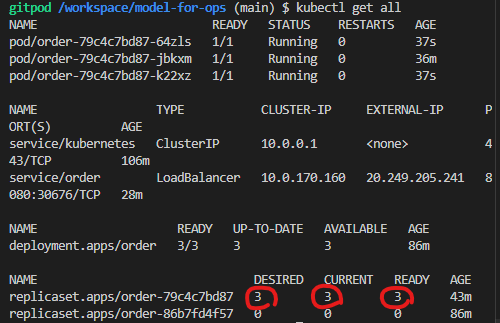
pod 3개가 살아잇어서 더 많은 요청을 담을 수 있다.
rollback
이전 버전으로 돌아가야 한다.
kubectl rollout udo deploy order
pod 깔쌈하게 지우기
deployment 지우기
kubectl delete deploy order
아예 배포되었던 사실을 없애야 한다.
deploy order를 service 객체로 만든 사실을 살아있다.
이는 별도의 가상 객체여서
접속을 위한 가상 객체와 실제 객체 중에 실제 객체가 삭제된 것이다.
이 둘은 독립된 성격을 가진다.

service를 지우기
kubectl delete service order
실제 azure의 로드밸런서를 지우는 것으로
다시 ip를 반납해야 해서 시간이 좀 걸린다.

Deployment 선언 파일을 정의
Deployment 객체로 정의하고 Pod을 몇 개 배포할지, 어떤 이미지 쓸지를 지정
Lab 폴더를 새로 만든다.
/Lab/order.yml
스팩을 정해줄 수 있다.
deployment를 배부해라..?
-
apiversion : 타입에 따른 버전
-
type : 어떤 리소스 타입을 쓰냐에 따라서 다르다.
-
metadata : deployment에 정보를 넣는다. (이름과 검색을 위한 레이블)
-
spec : deployment를 배포할 때의 replicaset 영역이다.
- selector : pod까지의 연결고리를 정해주는 부분
- template : deployment를 배포할 때의 pod의 영역이다.
- spec : pod의 스팩을 설정한다.
pod 하나 안에 여러 개의 컨테이너를 넣을 수 있다.
되도록이면 2개까지 권장한다.
다수의 컨테이너가 하나의 pod안에 들어갈 수 있다.
- image : 실제 컨테이너를 구성하는 주요 구성요소인 이미지(latest는 권장하지 않는다.)
- ports : 8080로 컨테이너 내부에서 노출할 포트이다.
cd Lab
kubectl apply -f order.yml
해당 파일을 적용할 수 있다.

적용된 이름이 order-by-yaml 이기에
kubectl port-forward deploy/order-by-yaml 8080:8080 해준다.
kubectl get deploy order-by-yaml -o yaml > order2.yaml 으로 조회한거를 뺄수도 있다.
실전 실습
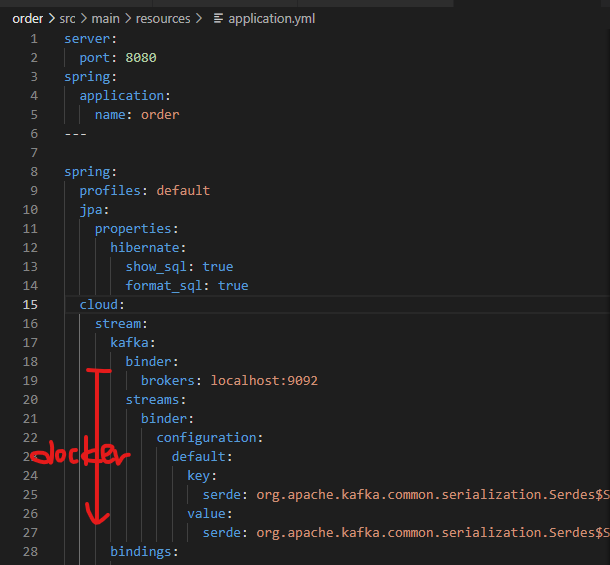
kafka를 kubernetes 환경에 배포할 때, Helm 을 사용해 간편하게 설치하고, service로 연결하여 접근할 수 있도록 구성한다.
Helm
kubernetes 애플리케이션을 설치하고 관리하기 위한 패키지 매니저이다.
kafka는 기본적으로 clusterIP 서비스로 생성되어 내부 통신만 가능하지만,
kafka도 인프라로써 사용한다.
service를 붙여서 동일하게
my-kafka 이름이기만 하면 되고 다운로드 받아서 설치만 잘하면 된다.
Helm 으로 설치파일이 이미 들어있다.
Helm으로 kafkaf를 설치하기만 하면 9092로 띄우고 하지 않아도 ㄱ된다.
어디에 저장되어있ㄴ느 어플래키에션을 받아올지 등록을 해야한다.
기존의 앱을 모ㅓㄴ저 배포한다.
cd order
mvn package
target 폴더에 jar 파일이 생성이 되었는지 확인한다.
docker login (최초 1회 실행한다)
docker build -t [dockerhub ID]/order:[오늘날짜] .
docker push [dockerhub ID]/order:[오늘날짜]
Docker hub에서 image 확인
클러스터를 배포한다.
az login --use-device-code
az aks get-credentials --resource-group [RESOURCE-GROUP-NAME] --name [Cluster-NAME]
kubectl get all
helm 설치하기
curl https://raw.githubusercontent.com/helm/helm/master/scripts/get-helm-3 > get_helm.sh
chmod 700 get_helm.sh
./get_helm.sh
- Helm Chart 저장소(repository) 를 등록
bitnami 은 Kafka를 포함한 다양한 오픈소스 소프트웨어를 템플릿 형식으로 제공하는 대표적인 저장소이다.
helm repo add bitnami https://charts.bitnami.com/bitnami
helm repo update
- 카프카 설치하기 (이름 : my-kafka)
helm install my-kafka bitnami/kafka --version 23.0.5
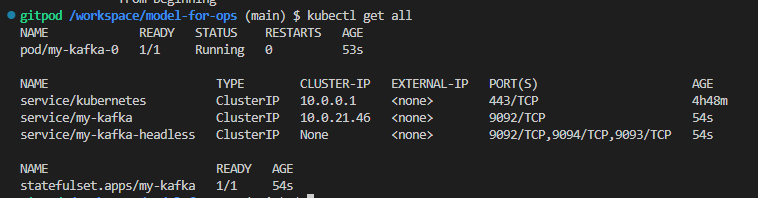
폴더마다 kubernetes 폴더에 deployment.yaml
deployment 타입으로
order라는 이름으로
replicaset은 1개로
image name에 이전에 도커허브에 push한 이미지의 이름을 적어줘야 한다.
kubectl apply -f [해당 폴더 경로까지 가줘야한다.]
kubectl apply -f kubernetes/deployment.yaml
deployment가 잘 생성되었고, 해당 deploy의 order가 running으로 잘 작동되고 있다.
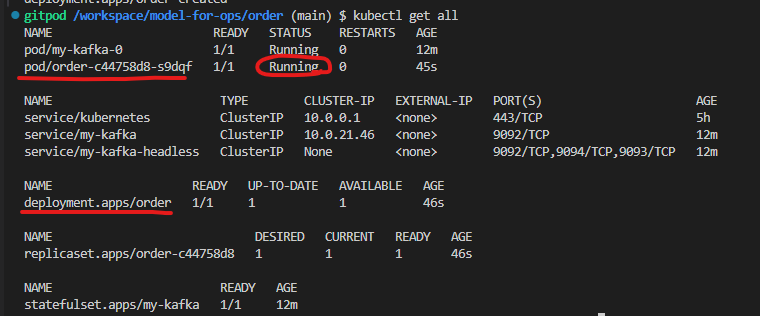
폴더마다 kubernetes 폴더에 service.yaml
targetport는 Pod 내부의 컨테이너가 실제로 열고 있는 포트 번호와 같아야한다.
/kubernetes/deployment.yaml
containers:
- name: order-container
image: jinyoung/order:v1
ports:
- containerPort: 8080/kubernetes/service.yaml
apiVersion: v1
kind: Service
metadata:
name: order
labels:
app: order
spec:
ports:
- port: 8080
targetPort: 8080
selector:
app: order
-
containerPort: 8080이므로,targetPort: 8080으로 설정해야 맞다.
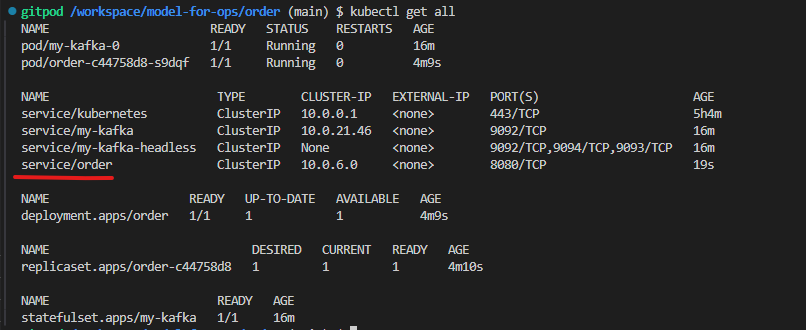
-
kubectl apply -f kubernetes/deployment.yaml
kubectl apply -f kubernetes/service.yaml
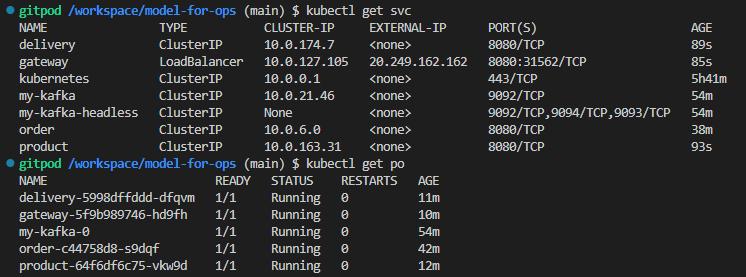
gateway의 external ip로 외부 요청을 통한 주문 생성
http 20.249.162.162:8080/inventories id=1 stock=100
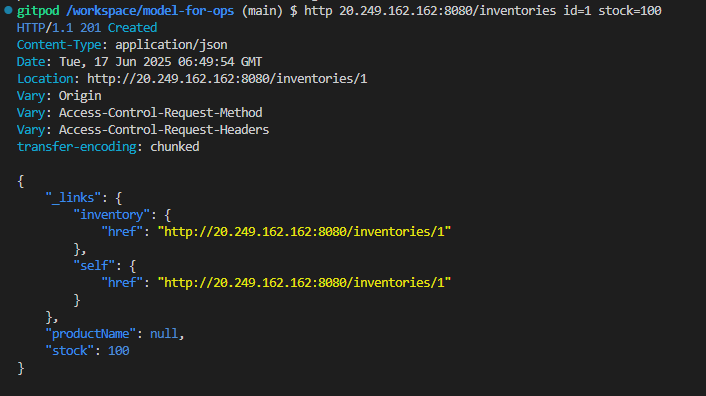
cluster ip로 내부에서 주고 받는다. (모든 서비스와 kafka 간의 통신)
kafka 클러스터 내부 통신 테스트용
클라이언트 pod를 하나 띄운다.
해당 클라이언트 Pod 안에 kafka 메시지를 콘솔로 받아보는 consumer를 싱핸한다.
-
서비스들(order, product 등)은 kafka로 메시지를 주고 받는다.
-
pod -> kafka 통신은
-
클라이언트 Pod 를 생성한다.
kubectl run my-kafka-client --restart='Never' --image docker.io/bitnami/kafka:3.5.0-debian-11-r21 --namespace default --command -- sleep infinity -
해당 pod에 접속한다.
kubectl exec --tty -i my-kafka-client --namespace default -- bash -
Kafka 메시지 소비(Consumer 실행)
kafka-console-consumer.sh --bootstrap-server my-kafka.default.svc.cluster.local:9092 --topic modelforops --from-beginning
kafka delete po --all
frontend를 정적웹서버로 서빙
frontend 앱을 docker이미지로 만들고, 웹서버 컨테이너로 배포하는 과정
정적 HTML/CSS/JS 를 웹서버로 서빙한다.
프론트엔드 앱 로컬 확인
npm install
npm run serve 으로 서빙이 되는지 확인한다.
빌드(정적 웹 페이지 생성)
npm run build ㅇ로 빌드의 결과이다.
build는 패키징한거를 dist에 담아둔다.
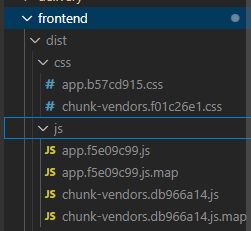
- dist/ 폴더 안에 index.html, main.js, style.css 등 정적 파일 생성된다.
- 웹서버에 넣어서 사용이 가능하다.
Docker 이미지로 패키징
docker build -t ehekaanldk/frontend:20250617 .
- Dockerfile에서 dist 폴더의 내용을 웹서버(Nginx 등)에 복사해서 정적 파일을 서빙하는 이미지 생성
docker hub에 이미지 푸시
해당 폴더에서 docker build하면 된다.
docker push ehekaanldk/frontend:20250617
빌드를 하면 dist 폴더 내에 html, css, js 가 만들어진다.
html, css, js를 웹서버에 원래는 가져가서 웹서버가 떠잇는 상태니까 브라우저가 요청?을 하면? 웹서버가 index.html을 넘겨주면서
이후에 브라우저는 모두 받아서 그걸 이용해서 cSR를 한다.
html, css, js파일들을 이용해서 웹서버에게 주고 contrainer가 되면 된다.
웹서버게에 복사해서 주고 그거를 컨테이너로 띄우는 것이다.
빌드를 하고 정적 웹서비스에 올릴 수 있다.
gateway ip의 external 포트 : 8080 으로 접속할 수 있다.

Label
쿠버네티스에서 객체를 식별하고 분류하기 위한 key-value 쌍의 메타데이터
selectors 로 특정 리소스를 필터링한다.
레이블은 지정한 이후에 선택할 수 있다.
- env==dev
- 배포 환경(env=dev, env=prod),
- 앱 버전(version=v1),
- 역할(tier=frontend) 등을 식별한다.
label
kubectl delete deploy --all
kubectl delete svc --all라벨을 달아서 deploy를 생성한다.
kubectl apply -f - <<EOF ... EOF 명령은 라벨(label)을 포함한 Deployment 객체를 생성하는 코드
kubectl apply -f - <<EOF
apiVersion: apps/v1
kind: Deployment
metadata:
name: home
spec:
replicas: 1
selector:
matchLabels:
app: home
template:
metadata:
labels:
app: home
spec:
containers:
- name: home
image: apexacme/welcome:v1
ports:
- containerPort: 80
EOF
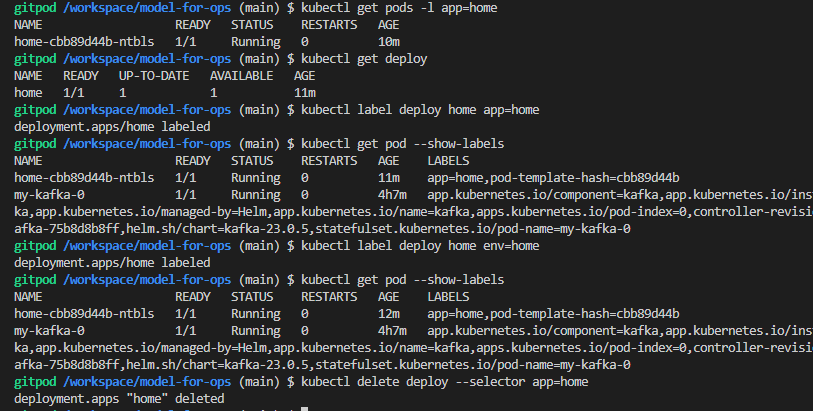
kubectl get pods -l app=home
kubectl get pods --selector app=home
kubectl delete pod -l app=home
kubectl get pods --selector 'app in (home, home1)'
kubectl get po --selector 'env in(home, home1), app in (home, home1)'
kubectl get deploy
kubectl label deploy home app=home
kubectl get deployment --show-labels
kubectl delete deploy --selector app=home
kubectl get all
서비스 롤백에 annotation 활용
kubectl create deploy home --image=apexacme/welcome:v1
버전을 관리한다.
kubectl get deploy -o wide
원래꺼보다 더 많은 정보를 보여준다.
배포 주석으로 해당 home에 내용을 기록한다.
kubectl annotate deploy home kubernetes.io/change-cause="v1 is The first deploy of My Homepage."
이미지를 set할 떄 어느 deploy를 할지 적어준다. home
kubectl set image deploy home welcome=apexacme/welcome:v2
- deploy이름 container이름 순으로 작성해줘야 한다.
annotation을 모두 확인한다.
kubectl rollout history deploy home
rollback한다.
kubectl rollout undo deploy home
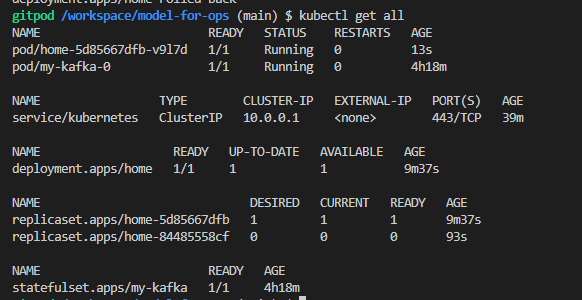
ver1로 rollback되었다.

Scale out
- monolith 로 서비스를 배포한다.
kubectl create deploy order --image=jinyoung/monolith-order:v20210504 - expose 하면 서비스가 등록된다.
kubectl expose deploy order --port=8080

- scale 하면 replicaset 를 늘릴 수 있다.
kubectl scale deploy order --replicas=3
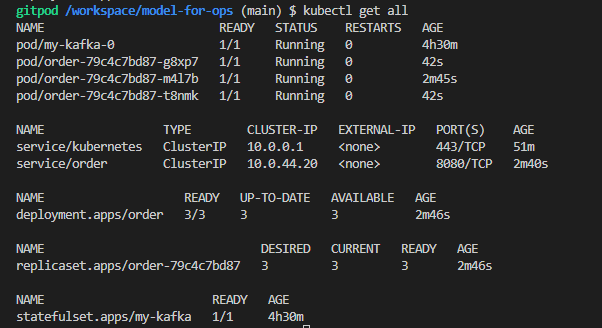
Auto scale out
Pod로 부하를 준다. (시즈?)
siege 라고 하는 파트 안에 들어가서 /bin/bash로 들어갈 수 있다.
kubectl exec -it siege -- /bin/bash
siege -c1 -t2s -v http://order:8080/orders
AKS 안에 oreder라는 서비스를 만들어서 배포를 했고, siege 라는 pod를 만들어서 배포했다. 모든 요청은 하나의 pod 안에 다 들어가도록
어느정도 cpu를 사용하는지 측정
원래는 meteric을 설치해야하지만 이미 설치가 되어 있음
kubectl top pods
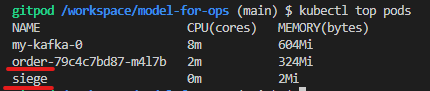
1개에서 3개 사이의 스케일 범위?>? 준다?
kubectl autoscale deployment order --cpu-percent=50 --min=1 --max=3
auto scaling은 절대적인 기준이 필요하다.
order라는 서비스를 deploy할 때 기대하는 기준값이 있어야 이를 보고 50%인지 80%라고 할 수 있다.
/order-deploy.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: order
labels:
app: order
spec:
replicas: 1
selector:
matchLabels:
app: order
template:
metadata:
labels:
app: order
spec:
containers:
- name: order
image: jinyoung/monolith-order:v20210602
ports:
- containerPort: 8080
resources:
requests:
cpu: "200m"
readinessProbe:
httpGet:
path: '/actuator/health'
port: 8080
initialDelaySeconds: 10
timeoutSeconds: 2
periodSeconds: 5
failureThreshold: 10
livenessProbe:
httpGet:
path: '/actuator/health'
port: 8080
initialDelaySeconds: 120
timeoutSeconds: 2
periodSeconds: 5
failureThreshold: 5kubectl apply -f order-deploy.yaml
배포 파일에 기준에 대한 것을 작성해줘야 한다.
limit , requset 를 보고 agent pool 에서 워커 노드들을 배치할지를 정한다.

Router for Containers : Service
service scope
apiVersion: v1
kind: Service
metadata:
name: my-service
spec:
selector:
app: order
ports:
- protocol: TCP
port: 8080
targetPort: 8080
type: ClusterIP/NodePort/LoadBalancer - type을 생략하면 clusterIP가 된다.
yaml파일을 사용(kubectl apply -f kubernetes/service.yaml
)해서 하거나 kubectl expose deploy order --type=ClusterIP --port=8080 --target-port=8080 를 사용해서 할 수 있다.
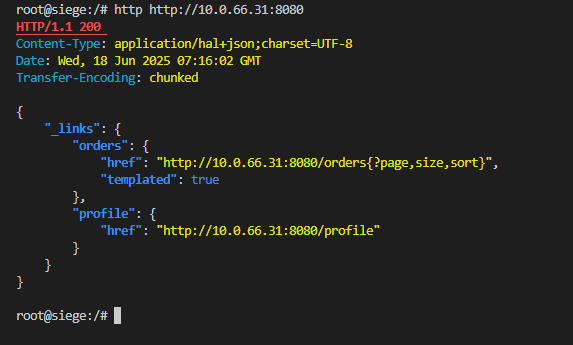
order cluster는 실제 order pod를 가르키고 있다.
서비스를 얼마나 공개하고 싶은지에 대해서 3가지 방법 중에 선택할 수 있다.
kube-dns
서비스를 조회할 때 서비스의 이름으로 바로 조회해준다.
뭔소리고~

블로거님 언제 다음 글 올라올까요??