CS 스터디를 하면서 눈에 띈 주제를 발견했다.
"www.naver.com을 치면 일어나는 일"
너무나도 밀접했던 네이버 주소라 궁금증이 생기지도 않았었다.
그리고 새삼 동작 흐름에 대해 궁금해 지기 시작했다.
naver.com을 검색해보자
나는 보통 크롬 브라우저를 사용한다. 그리고 브라우저에서 검색도하고 주소를 입력하기도 한다.
그러니까, 크롬 검색창에 네이버라고 쓸 때도 있고, naver.com이라고 검색한 적도 있다.
네이버는 검색 결과가 나오고, naver.com은 www.naver.com 페이지로 이동하게 된다.
naver.com을 치면 발생하는 일
시작. 크롬 브라우저에 naverc.com을 입력한다
1. 입력한 텍스트 정보를 확인한다.
2. 네트워크를 호출한다.
3. 렌더링 작업을 실시한다.
끝. Naver 등⭐장
시작과 끝을 제외하면 크게 세 단계로 나눌 수 있다.
1. 입력한 정보 확인
이 브라우저를 보면 요상한 점을 볼 수 있다.
Google에서 검색하거나 URL을 입력하세요.
즉, 우리가 알고 있는 검색창뿐만 아니라 주소창에도 검색을 할 수 있다는 것이다.
즉, 브라우저는 텍스트가 검색어인지 URL인지 판단하여 각 텍스트에 맞는 작업을 수행한다.
- 검색어라면?
브라우저는 검색 엔진의 URL에 검색어를 포함한 주소로 페이지를 이동시킨다. - URL이라면?
브라우저 엔진에서 네트워크 스레드를 통해 네트워크 호출을 수행한다.
이번 포스트는 URL을 입력했다고 가정하자.
2. 네트워크 호출
크롬 브라우저는 일단 Naver 에서 만든 브라우저가 아니다.
그래서 크롬 브라우저에서 URL로 검색할 때 Naver 페이지에 필요한 HTML/CSS 문서, 스크립트, 이미지 등의 데이터를 가져와야 한다.
어디서 가져올까? 크롬 브라우저의 쿠키나 세션에 네이버 관련 데이터가 저장되어 있지 않다(흥, 당연한 소리)
그래서 이 데이터를 Naver 서버 컴퓨터에서 가져온다.
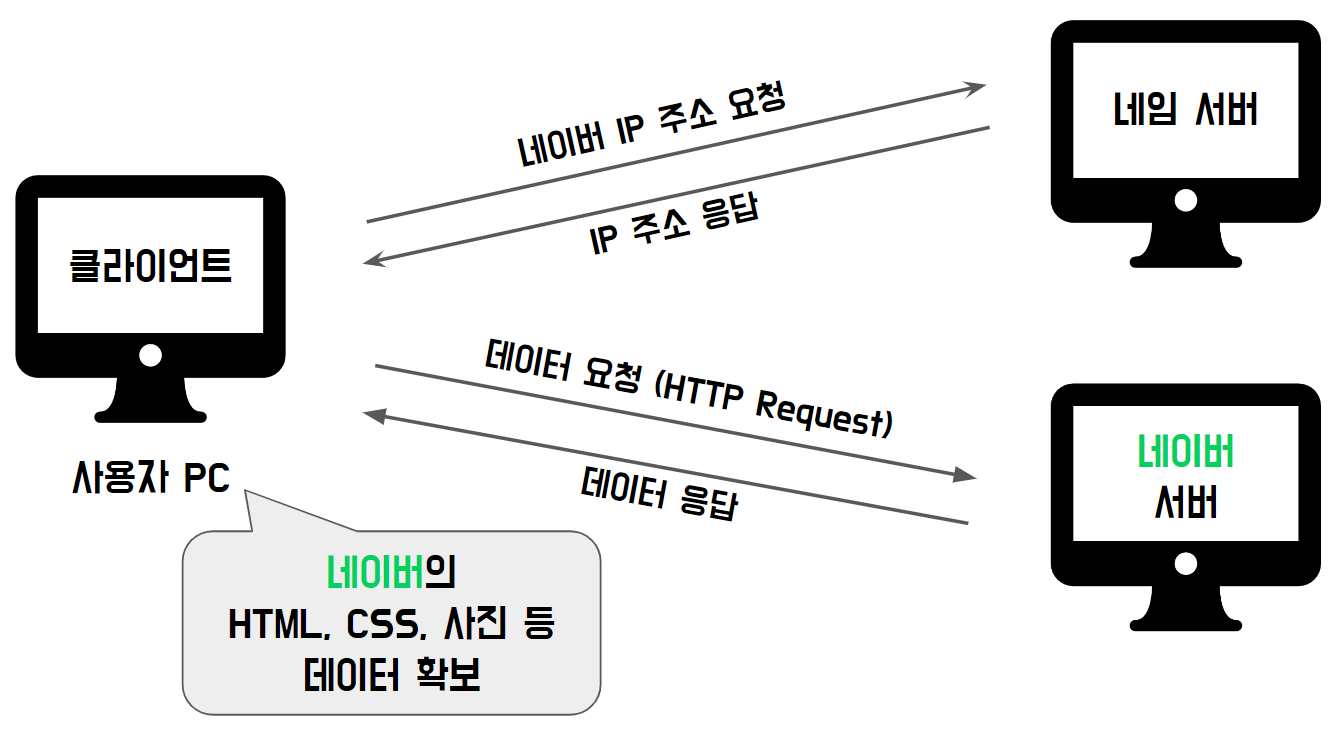
그래서, 네이버 서버와 네트워크 통신을 통해 데이터를 가져온다.
그러기 위해서 Naver 서버 컴퓨터 IP 주소를 알아야 한다.
a. 네이버 서버의 주소에 대한 Name Server(DNS)와 통신
b. 가져온 주소로 네이버 서버와 통신하여 데이터 받기
a. 네이버 서버의 주소에 대한 Name Server와 통신
우리는 검색창에 IP주소로 검색한 것이 아닌, 주소 이름으로 검색했다.
마치 변수처럼 IP 주소에 대응하는 이름을 도메인 이름이라고 하는데, 검색창에 naver.com으로 검색한 것은 도메인 이름으로 검색했다고 할 수 있다.
그럼 도메인 이름을 IP 주소로 변환하기 위해 DNS를 통해 대응되는 IP 주소로 변환한다.
b. 가져온 주소로 네이버 서버와 통신하여 데이터 받기
정보는 HTTP 통신 방식으로 데이터를 받는다. HTTP Request를 통해 요청하고 HTTP Response로 데이터를 받아온다.
3. 렌더링
네이버 서버로부터 받은 데이터에 악성 바이러스는 없는지 검사한다. 이를 브라우저 엔진의 네트워크 스레드에서 검사한다.
이 데이터는 바이트 형태의 텍스트 문서다. 그래서 브라우저에서 읽을 수 없기 때문에 브라우저 엔진의 UI 스레드에서 렌더링 엔진에게 해석하고 웹 페이지 화면 렌더링 요청한다.
렌더링 과정
- HTML을 파싱하여 DOM 트리 구축, CSS를 파싱하여 CSSOM 트리 구축, JS도 파싱함.
- DOM 트리와 CSSOM 트리를 통해 랜더 트리 구축 (Attachment / 형상 구축)
- 랜더 트리 배치 (Layout / Reflow)
- 랜더 트리 그리기 (Paint)
여기서 파싱이란, 문자 스트림을 브라우저가 이해할 수 있는 트리 구조로 변환하는 과정을 말한다.
파싱에는 두 가지 종류가 있는데,
1. 어휘 분석 (by 어휘 분석기): 문자열을 토큰으로 분해
2. 구분 문석 (by Parser): 문법에 따라 토큰 간의 위계관계를 분석하고 파싱 트리 생성
으로 나눠진다.
