
싸피 페어의 과제아닌 과제를 도와주던 중, 나도 헷갈리는 이진 탐색의 Lower Bound, Upper Bound를 다시 복습 겸 정리하고자 한다.
이진 탐색
이진 탐색이란,
정렬된 배열에서 원하는 값을 찾기 위한 탐색 알고리즘으로써
중앙을 기준으로 원하는 값(기준)보다 작으면 왼쪽, 크면 오른쪽으로 탐색하는 방법이다.
예를 들어, 나는
1 2 3 4 5 6 7 8 9 10
이라는 정렬된 배열에서 7이라는 숫자를 찾고 싶다.
이진 탐색을 몰랐던 나는 1부터 순차적으로 조회하고 확인하며 7까지 약 7번 만에 도달했을 것이다.
하지만, 싸피에서 열심히 수업을 들으면서 이진 탐색의 신이 되었다고 가정해 보자.
그럼 난 중앙에 위치한 5를 먼저 조회하고 내가 원하는 7은 5보다 크다(또는 크거나 같다)는 것을 확인할 수 있다.
그럼 5보다 작은 부분은 조회할 필요가 없어진 것이다.
즉, 나는 이제 5에서 10 사이 중간에 위치한 8을 꺼내 확인하고 이러한 방법을 반복하여 7을 찾아낼 것이다.
또한, 최악의 경우 순차적으로 찾을 때O(n)보다 더 빠른logN 속도로 조회가 가능해 진다.
코드
이제 말로 해본 것을 Java로 작성해 보자.
public class BinaryTest {
public static void main(String[] args) {
int[] arr = {1,2,3,4,5,6,7,8,9,10};
// int 원하는_값의_index = binarySearch(배열, 찾고_싶은_값, 0번_인덱스, 마지막_인덱스);
System.out.println(binarySearch1(arr, 7, 0, arr.length - 1));
System.out.println(binarySearch2(arr, 2, 0, arr.length - 1));
}
static int binarySearch1(int[] arr, int target, int low, int high) {
while(low <= high) {
int mid = (low + high) / 2;
if(target == arr[mid]) return mid; // 원하는 값을 찾음
else if (target < arr[mid]) // 원하는 값이 왼쪽에 있음
return binarySearch1(arr, target, low, mid - 1);
else // 원하는 값이 오른쪽에 있음
return binarySearch1(arr, target, mid + 1, high);
}
return -1; // 원하는 값을 찾지 못함
}
static int binarySearch2(int[] arr, int target, int low, int high) {
while(low <= high) {
int mid = (low + high) / 2;
if(target == arr[mid]) return mid;
else if (target < arr[mid])
high = mid - 1;
else
low = mid + 1;
}
return -1;
}
}Lower Bound & Upper Bound
둘 다 경계값을 찾는 알고리즘이다.
이진 탐색을 기반으로 하는 알고리즘 답게 정렬되어 있는 배열에만 사용이 가능하며, 시간 복잡도는 O(logN)갖는다.
Lower Bound
Lower Bound는 특정 값의 시작 위치를 찾는 알고리즘이다.
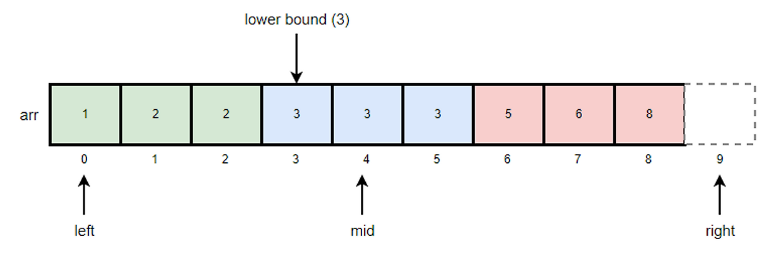
동작 방식
- 초기 left(low)와 right(high)를 배열의 시작 위치, 배열의 길이로 초기화 한다.
- 배열의 중간 값인 mid를 구한다.
- 중간 값과 검색하려는 값(k)을 비교한다.
- 중간 값이 검색 값보다 작으면(mid < k), left 값을 mid + 1로 한다.
- 중간 값이 검색 값도가 크거나 같으면(mid >= k), right 값을 mid로 한다.
- left 가 right보다 크거나 같을 때 까지 2번과 3번을 반복한다.
- 반복이 끝나면 right 값이 Lower Bound가 된다.
코드
public class LowerBoundTest {
public static void main(String[] args) {
int[] arr = {1,2,3,4,4,4,5,6,7,7,8};
System.out.println(lowerBound(arr, 4));
}
static int lowerBound(int[] arr, int k) {
int left = 0;
int right = arr.length;
while(left < right) {
int mid = (left + right) / 2;
int cur = arr[mid];
if(cur < k) left = mid + 1;
else right = mid;
}
return right;
}
}Upper Bound
Lower Bound는 찾고자 하는 값의 시작 위치를 찾는다면,
Upper Bound는 찾고자 하는 값보다 처음으로 큰 값의 시작 위치를 찾는 알고리즘이다.
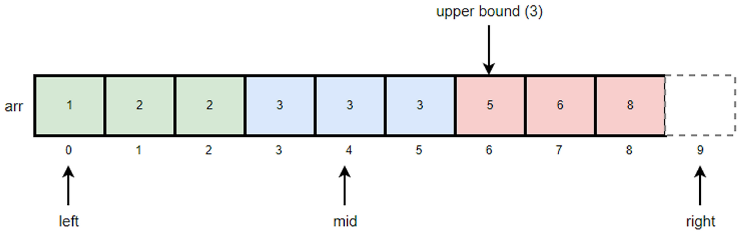
동작 방식
- 초기에 left는 배열의 시작 위치로 right는 배열의 길이로 세팅
- 배열의 중간 값(mid) 가져오기
- 중간 값과 검색 값(k) 비교
- 중간 값이 검색 값보다 작거나 같다면 (mid <= k), left를 mid + 1로 한다.
- 중간 값이 검색 값보다 크다면 (mid > k), right를 mid로 한다.
- left가 right보다 크거나 같을 때 까지 2번과 3번을 반복한다.
- 반복이 끝나면 Upper Bound가 저장된 right를 반환한다.
코드
public class UpperBoundTest { //
public static void main(String[] args) {
// TODO Auto-generated method stub
int[] arr = {1,2,3,4,4,4,5,6,7,7,8};
System.out.println(upperBound(arr, 4));
}
static int upperBound(int[] arr, int k) {
int left = 0;
int right = arr.length - 1;
while(left < right) {
int mid = (left + right) / 2;
int cur = arr[mid];
if(cur <= k) left = mid + 1;
else right = mid;
}
return right;
}
}외우는 법
사람마다 외우는 법은 다를 수 있지만, 내가 외운 방법을 기록해 보겠다.
Lower Bound와 Upper Bound의 코드 상의 차이점이라면, if문에 =이 붙는 위치가 다르다.
나는 이 점을 이용해서 외웠다.
Lower Bound는 내가 원하는 값이 시작하는 위치를 알아내기 위한 알고리즘이다.
나는 right 변수에 그 위치를 저장할 것이기 때문에, mid 값이 k에 포함된 if 절에 right = mid를 해야 한다.
좀 더 쉽게 설명하면,
if(arr[mid] < k) left = mid + 1;
else if(arr[mid > k) right = mid;이 분기에서 Lower Bound와 Upper Bound에 따라 arr[mid] == k 조건을 두는 위치가 정해진다.
Lower Bound는 원하는 값(k)이 시작하는 위치
즉, 값을 반환하는 right에 그 값(k)이 포함 ⇉ arr[mid] == k를 right를 움직이는 아래 조건에 넣어야 한다.
// Lower Bound
if(arr[mid] < k) left = mid + 1;
else if(arr[mid >= k) right = mid;
// else right = mid반면, Upper Bound는 원하는 값(k)보다 큰 값 중 시작 위치
즉 k 값을 right에 포함시키면 안된다.
// Lower Bound
if(arr[mid] <= k) left = mid + 1;
else if(arr[mid > k) right = mid;
// else right = mid정리
Lower Bound는 그 값을 포함하는 시작 위치
Upper Bound는 그 값보다 큰 수(큰 수 중 최소) 중 시작 위치
관련 문제
https://www.acmicpc.net/problem/2805 (나무 자르기 : 이진 탐색, 매개 변수 탐색)
https://www.acmicpc.net/problem/1654 (랜선 자르기 : 이진 탐색, 매개 변수 탐색)
https://www.acmicpc.net/problem/2110 (공유기 설치 : 이진 탐색, 매개 변수 탐색)
https://www.acmicpc.net/problem/13397 (구간 나누기 2 : 이진 탐색, 매개 변수 탐색)
