
1. 문제 상황
프로젝트에서 우리는 알림 서비스를 확장하기 위해 api와 batch, 두 모듈을 운영하였고 두 곳에서 같은 DB에 접근하는 방식을 취하고 있었다.
그런데 문제는 두 모듈에서 동일한 엔티티를 각각 개별적으로 가지고 있는 탓에 한 모듈에서 작업하는 팀원이 특정 엔티티를 변경하면 다른 모듈에서 작업하는 팀원은 수기로 프로젝트의 엔티티를 변경해야 하는 번거로움이 생겼다.
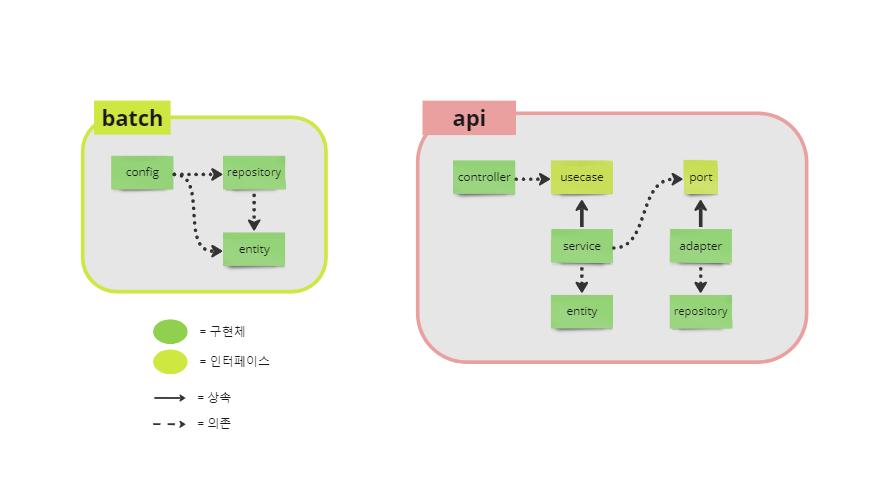
그러나 이 사실을 초기에 몰랐고 application.yml의 spring.jpa.hibernate.ddl-auto 옵션이 update로 설정되어 있어 어느 순간 DB에 쓰기가 발생하였고 내부 데이터가 꼬이게 되었다. 당시 모듈 상황은 아래 그림과 같았다.
2. 문제 해결
그래서 이 문제를 해결하기 위해 멀티 모듈에 대해서 공부하게 되었다. 그 중 이 포스팅의 내용에 따르면 멀티 모듈을 사용하면 공통으로 사용되는 코드를 모듈화할 수 있기 때문에 굳이 번거롭게 코드를 동기화할 필요가 없으며 그에 따른 실수를 미연에 방지할 수 있다고 한다.
- 해당 블로그의 버전은 스프링 부트 1.5.x이기 때문에 현재 2.7 버전을 사용하는 우리 프로젝트와 맞지 않았다. 그래서 우리 프로젝트에 적용할 수 있는 이 글을 찾게 되었다.
1차 고안
초기에는 api와 batch 두 단일 모듈 중 공통으로 사용하는 코드를 모듈로 분리하는 것이 맞지만, 프로젝트에서 api의 비중이 대부분이고 바로 사용하기 위해 임시적으로 batch가 api를 의존하는 형태로 만들 자는 것이 나의 의견이었다.
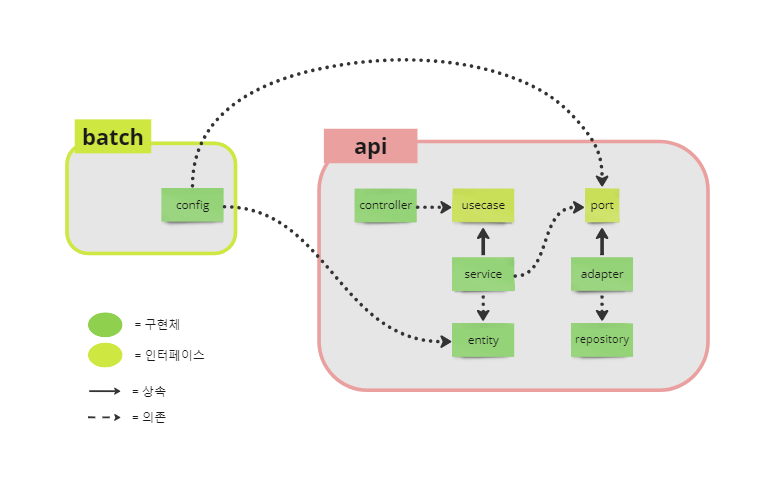
그러나 이는 좋은 방법이 아니었다. batch 모듈은 api와 겹치는 entity와 일부 port만 사용하면 되는데 굳이 불필요한 api의 spring security나 web 의존성을 강제로 추가해야 했고 bulid 시 시간도 오래 걸리게 되었다.
2차 고안
그래서 batch에서 port 부분부터 필요했기 때문에 DB에 접근하는 영속성 부분을 common이라는 새로운 모듈로 분리하였다.
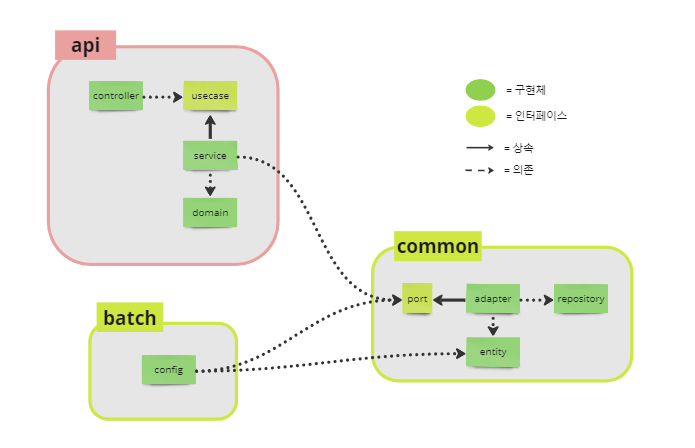
그런데 이렇게 개발을 진행하면 초기에 설계했었던 domain과 entity를 하나로 두어 두 객체에 서로 데이터를 치환하는 작업을 없애자는 것이 성립되지 않는다.
그리고 domain과 entity를 분리하고 batch에서 entity만을 사용하게 되면 batch에서는 domain에 정의되어 있는 기존의 enum 타입의 객체들을 사용할 수 없게 된다. 그리하여 이 방법도 좋은 설계가 아니라고 판단하였다.
3차 고안
2차 고안의 문제점을 해결하기 위해서 batch 모듈도 domain 모듈을 지나서 데이터베이스 영역인 common 모듈로 접근하는 방법으로 변경하였다. batch 모듈도 domain을 사용할 수 있도록 api 모듈에서 domain 과 관련된 코드를 따로 모듈로 분리했다.
그리고 domain 모듈에 jpa 까지만 의존성을 가지게 하고 domain 모듈에 entity를 두는 방식을 채택했다. 그 이유는 domain 모듈과 common 모듈에 각각 domain과 entity를 분리함에 따라 서로 mapping 해야되는 번거로운 작업을 줄이기 위함이다. 이렇게 하면 common 모듈은 domain 모듈을 의존하기 때문에 따로 entity를 두지 않고 domain 모듈의 entity를 사용할 수 있다.
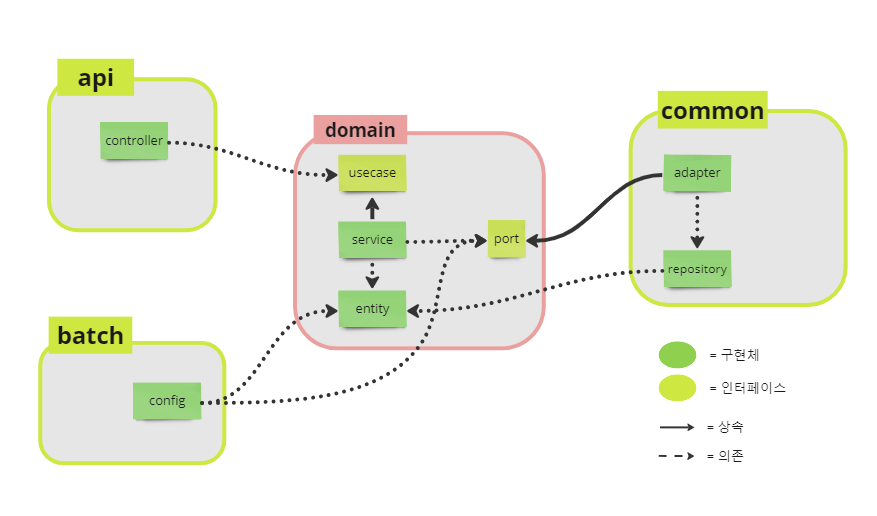
그러나 이 방법에서도 문제가 있었다. 우리는 복잡한 쿼리문을 쓸 때 querydsl을 사용한다. 그런데 common 모듈에 있는 querydsl이 domain 모듈에 있는 entity를 Qclass로 생성하지 못했다.
이 문제 때문에 하루, 이틀을 다른 모듈에 있는 entity를 Qclass로 생성하는 방법을 찾아보다가 gradle에서 script를 작성해서 하는 방법이 있다는 것 까지만 알게 되었다.
그러나 이 방법을 찾아보려 대부분의 웹사이트를 살펴봤는데 대부분 domain과 common을 합쳐서 하나의 모듈로 사용하는 것을 알게 되었다. 왜 그렇게 사용하는지 그 이유를 찾아보다가 이 영상과 이 글을 알게되었다.
영상과 글의 저자는 동일인물이다. 영상에서 말하는 것은 다음과 같다.
도메인 영역이 인프라스트럭쳐(DB 및 infra) 영역을 모르게 설계하는 것이 맞다. 그리고 그게 객체지향 관점에서 더 옳고 도메인 영역을 순수하게 작성하는 것이 나중을 위해서 더 좋다. 하지만 순수성을 위해 실용성을 버리는 것은 어리석은 일이다. 그렇기 때문에 실용성을 포기하면서까지 순수성을 가져갈 필요가 없다고 생각했다.
그래서 나도 판단하기를 우리 프로젝트를 보았을 때 현재 common에서 사용하는 데이터베이스가 RDB와 redis 뿐이고 프로젝트가 RDB 중심인 것에서 그리 벗어나지 않는다면 domain 모듈과 common 모듈을 합쳐서 domain 모듈로 두는 것도 나쁘지 않겠다고 판단했다.
그리하여 여러 고민을 거쳐 탄생한 최종안는 다음과 같다.
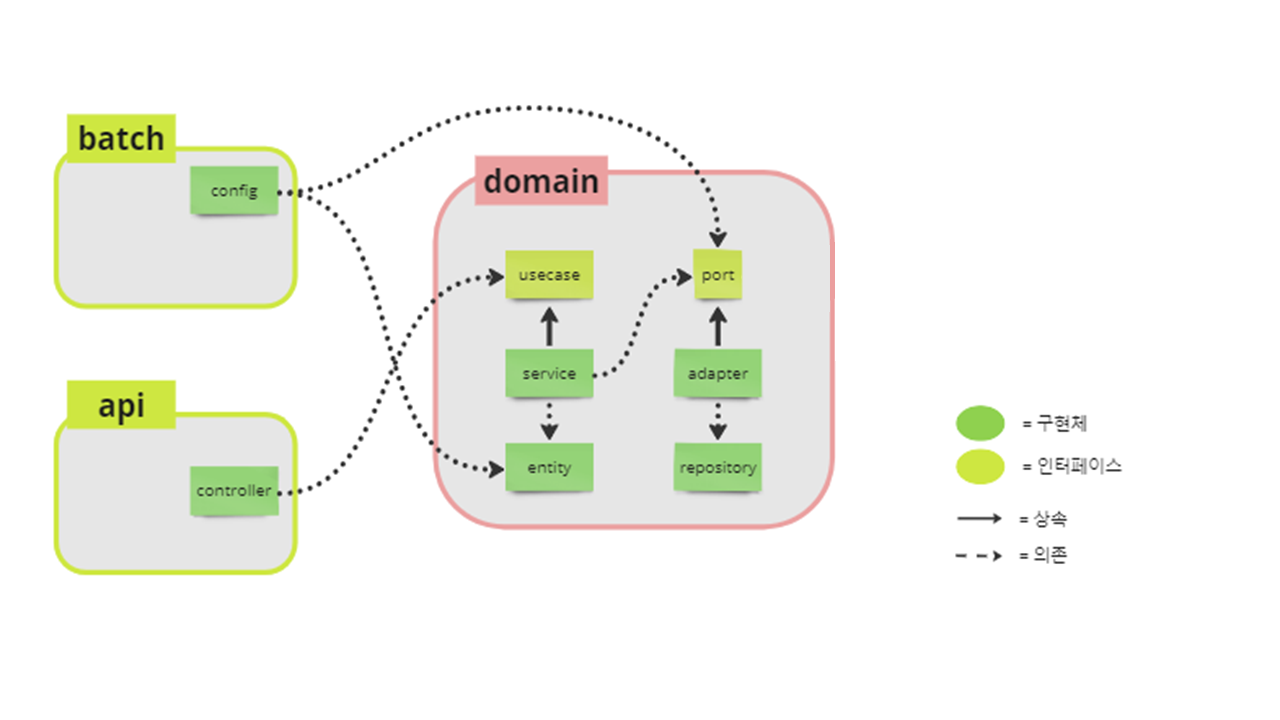
모듈을 분리한 것을 보면 3차 모듈에서 domain과 common을 합쳤으며 이렇게 구성하고 보니 querydsl의 Qclass 생성 문제는 발생하지 않았고 공통 모듈을 구성함에 따라 초기의 목표였던 코드 동기화도 이룰 수 있었다.
마치며..
아직 멀티 모듈에 대해서 완벽하게 이해하고 사용하고 있는 것 같진 않다. 그 이유는 멀티 모듈은 기능이 중점이 아니라 설계가 중점이되는 것이기 때문에 뚜렷한 정답이 없다. 그래서 이번에 Chat gpt와도 엄청나게 말씨름을 했다. 그래도 이 정도면 공부가 많이 된 것 같아서 만족하고 있다.
그러나 Gradle에 관련해서 더 심도있는 공부가 필요하다는 것을 알게 되었다. 과거에 그저 프로그래밍을 잘하는 것도 좋지만 데브옵스나 설계, 빌드 등 여러 기술들을 다루지 못한다면 발목 잡힐 지 모른다는 것을 들은 적이 있다. 따라서 앞으로 나의 개발 인생에서 이러한 것들이 걸림돌이 되지 않도록 깊이 있게 숙달을 해놔야겠다고 생각했다.
3. 알게된 점
1. Component Scan
Component scan은 애플리케이션을 실행하는 영역, 즉 우리 프로젝트 내에서는 batch와 api 모듈의 xxxApplication.java 내부 @SpringBootApplication 어노테이션을 통해서 scan의 대상이 확정된다. 대체적으로 모듈 내의 xxxApplication.java가 있는 레벨에서 bean 스캔의 대상이 정해진다. 아래의 내용을 보자
api (모듈)
ㄴ com
ㄴ example
ㄴ api
ㄴ xxxAppliation.java
ㄴ A
ㄴ B
xxxAppliation.java의 @SpringBootApplication 어노테이션을 통해 xxxApplication.java와 동일한 레벨인 api 안, 즉 A, B 디렉토리 내부 bean이나 component를 찾아서 스프링 컨테이너에 올린다. 그러나 문제는 다음과 같다. 아래의 코드를 보자.
api (모듈)
ㄴ com
ㄴ example1
ㄴ api
ㄴ xxxAppliation.java
ㄴ A
ㄴ B
domain (모듈)
ㄴ com
ㄴ example2
ㄴ domain
ㄴ C
ㄴ D이렇게 디렉토리 구조가 설정되어 있다면 xxxApplication.java는 api 디렉토리 내부의 레벨로 bean 스캔이 정해졌기 때문에 domain의 디렉토리 내부의 bean들이 필요하더라도 사용할 수 없다. 그래서 따로 @SpringBootApplication에 패키지를 추가해줘야한다.
// 이걸 일일이 다 추가해줘야함..
// 모듈이 많아질수록 번거로워짐..
@SpringBootApplication(scanBasePackages = "com.example2.domain")
public class xxxApplication {
...
}
이를 해결하는 간단한 방법은 먼저 두 모듈의 패키지 명을 동일하게 바꾼다. (com.example1, com.example2 에서 모두 com.example로 변경한다.)
그리고 @SpringBootApplication이 있는 java 파일을 example 하위 즉, api 패키지와 동등한 레벨로 위로 한 단계 이동시킨다. 그렇게 하여 변경한 코드는 다음과 같다.
api (모듈)
ㄴ com
ㄴ example
ㄴ xxxAppliation.java
ㄴ api
ㄴ A
ㄴ B
domain (모듈)
ㄴ com
ㄴ example
ㄴ domain
ㄴ C
ㄴ D이렇게 변경하면 spring은 모듈과 관계없이 다음과 같이 패키지 구조를 인식하여 bean 스캔을 한다.
ㄴ com
ㄴ example
ㄴ xxxAppliation.java
ㄴ api
ㄴ A
ㄴ B
ㄴ domain
ㄴ C
ㄴ D이렇게 하면 아까 처음 얘기했던 xxxApplication.java의 bean 스캔 범위를 이용해서 domain까지 bean 스캔을 할 수 있다.
두 모듈 간의 공통 패키지가(com.example) 있고 xxxAppliation.java를 api와 domain 디렉토리의 레벨과 동일하게 설정하였기 때문에 xxxAppliation.java는 api와 domain 디렉토리 내부 bean을 모두 스캔할 수 있게 된다.
이 방법이 꼼수일 수도 있고 관례일 수도 있지만 xxxAppliation.java 파일을 한 단계 위로 올리는 것으로 설정해야하는 코드의 양이 줄어들어 실수도 줄고 많은 이점을 챙길 수 있다고 생각한다.
2. application.yml
이번엔 application.yml과 관련된 것이다. 이것은 보편적으로 잘 알려져 있는 방법이다. 공통적으로 사용하는 모듈에 application-xxx.yml을 만들어두고 실행되는 애플리케이션 모듈에서 application.yml에 include로 xxx를 작성해두면 애플리케이션 실행시 application-xxx.yml를 자동으로 읽어서 application.yml에 해당 옵션을 추가하여 실행한다.
이 방법도 실행되는 애플리케이션이 여러개 있을 때 application.yml에 사용되는 공통 속성을 모듈화하여 불러오기 때문에 코드의 양도 줄일 수 있고 실수도 줄일 수 있는 좋은 방법이다.
// application.yml
// application-db.yml, application-s3.yml, application-redis.yml 를 불러 온 모습.
spring:
profiles:
active: main
include: db, s3, redis추가적으로 profiles의 active를 이용해서 여러가지 설정 중 하나를 선택하여 애플리케이션을 실행하는 방법도 있다. 예를 들어서 application-db.yml의 내용이 아래와 같다고 가정하자.
spring:
profiles: main
datasource:
// ... mysql 설정 내용 ...
---
spring:
profiles: local
datasource:
// .... h2 설정 내용 ...--- 이용하여 profiles를 나누고 각각 profiles에 mysql을 사용하고 싶을 때 쓰는 profiles를 입력하고 h2를 사용하고 싶을 때 쓰는 profiles를 입력해준다. 그러면 aplication.yml에서 active에 원하는 값을 입력하여 둘 중 선택하여 사용할 수 있다.
// application.yml
// 운영 db를 사용하고 싶을 때
spring:
profiles:
active: main
include: db, s3, redis
// 테스트시 h2를 사용하고 싶을때
spring:
profiles:
active: local
include: db, s3, redis3. api & implementation
마지막은 bulid.gradle의 api & implementation 옵션이다. api & implementation 설정으로 상위 모듈로의 확장과 폐쇠를 결정할 수 있다.
먼저 api, domain, database 모듈이 있고 api는 domain을 domain은 database를 의존하며 api와 domain은 아래와 같이 dependency가 설정되어 있다고 가정해보자.
// domain의 bulid.gradle
...
dependency {
implementation project(:database)
}
...
// api의 bulid.gradle
...
dependency {
implementation project(:domain)
} 위의 코드를 보면 api는 domain 모두 implemenation으로 domain과 database를 의존하고 있다. 그렇다면 api는 database의 클래스를 사용할 수 있을까? 정답은 "없다"가 맞다.
그 이유는 implementation 설정은 상위 모듈로의 폐쇠를 의미하기 때문이다. implementation은 하위 모듈이 포함하고 있는 의존성들을 상위 모듈로 연결되는 것을 막는다. 따라서 api 모듈은 domain 내의 클래스를 사용할 순 있지만 database의 클래스는 사용할 수 없게 된다.
그러나 폐쇠가 있다면 확장도 있다. implementation을 api로 변경하면 된다. 변경된 코드는 아래와 같다.
// domain의 bulid.gradle
...
dependency {
api project(:database) // 변경 사항!
}
...
// api의 bulid.gradle
...
dependency {
implementation project(:domain)
} 아래와 같이 의존성을 api로 열어놓으면 api에서도 database의 내부 클래스들을 사용할 수 있다.
참고자료
