
1. 개발 표준
1.1 개발 표준의 필요성
개발 표준은 모든 개발자가 동일한 형태의 소스코드를 만들기 위해 필요하다.
혼자 개발할 땐 어떻게 코드를 짜든 상관없지만 누군가와 협업을 한다면 다른 사람이 읽었을 때 코드를 쉽게 이해할 수 있어야 한다. 그래야 수정도 쉽고 유지보수도 원활하며, 전체 프로젝트의 흐름을 쉽게 파악할 수 있다.
프로젝트 설계의 개념
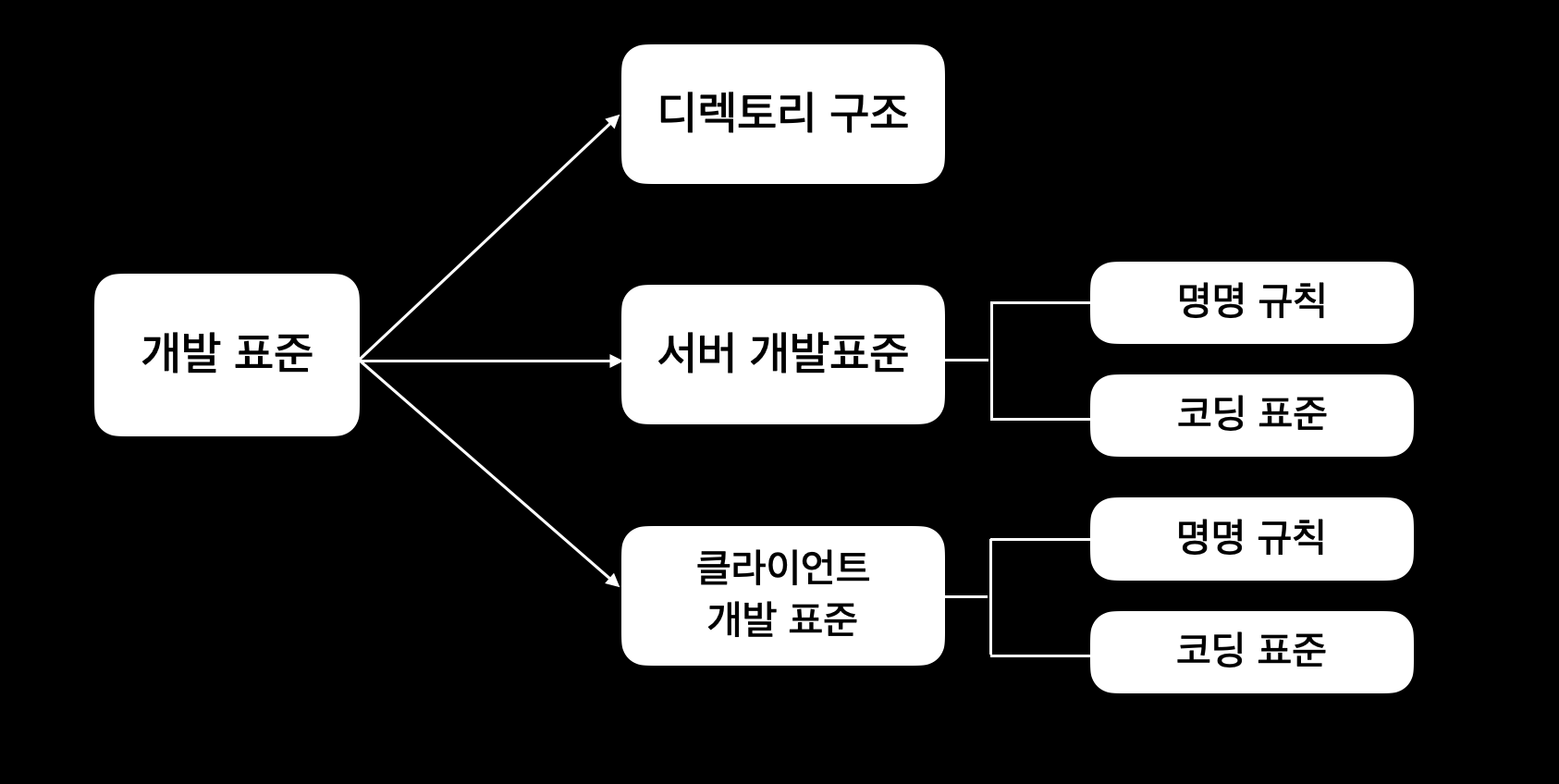
일반적으로 개발 표준은 디렉토리 구조와 서버 및 클라이언트 개발 표준으로 나뉜다.
디렉토리 구조: 디렉토리를 어떤 구조로 배치할지에 대한 규칙을 정하는 것이다.서버 개발 표준: 서버에서 동작하는 자바와 같은 프로그램에 대한 프로그램 구조를 정의하는 것이다.클라이언트 개발 표준: 사용자 화면을 구성하는 HTML, CSS, JS 에 대한 프로그램 구조를 정의한다.
이중 서버 개발 표준의 디렉토리 구조/명명규칙/코딩 표준에 대해 정의하고자 한다.
1.2 디렉토리 구조
지금까지 나는 계층형 아키텍처에 맞게 패키지를 구성했다.
ㄴ root
ㄴ config
ㄴ controller
ㄴ domain
ㄴ repository
ㄴ service
ㄴ security
ㄴ exceptioncontroller, service, repository 로 패키지를 나누고, 패키지 안에 도메인 패키지를 만들어 사용했다.
얼핏 보면 계층대로 구분하여 나름 체계적인 것 같지만 다음과 같은 불편함이 있다.
- 도메인과 서비스가 복잡해졌을 때, 코드를 관리하기 불편하다.
- 계층 간의 의존도도 높아지고, 코드가 여기저기 얽혀 있어서 IDE 도움 없이는 코드를 찾을 수 없었다.
- 테스트도 불편했다.
- 계층 간의 의존도가 높아지니 테스트 역시 하나의 Controller 를 구현하려면 여러 Service 를 불러와야 했다.
- 비즈니스 로직이 바뀌거나 프론트엔드에서 요구사항이 달라진다면 수정할 게 너무 많아진다.
이러한 불편함을 해소하기 위해 헥사고날 아키텍처를 알아봤다.
헥사고날 아키텍처의 가장 큰 특징은 내부와 외부를 철저하게 분리한다는 점이다.
소프트웨어 시스템의 내부와 외부를 분리하여 각각 독립적으로 변경가능하게 설계하여 각 계층의 의존도를 낮춘다. 여기서 내부는 비즈니스 로직이 위치하고, 외부는 사용자 인터페이스, 데이터 베이스, 외부 시스템 등과 같은 요소가 위치한다.
식재료 요구사항을 예시로 설계하면 다음과 같다.
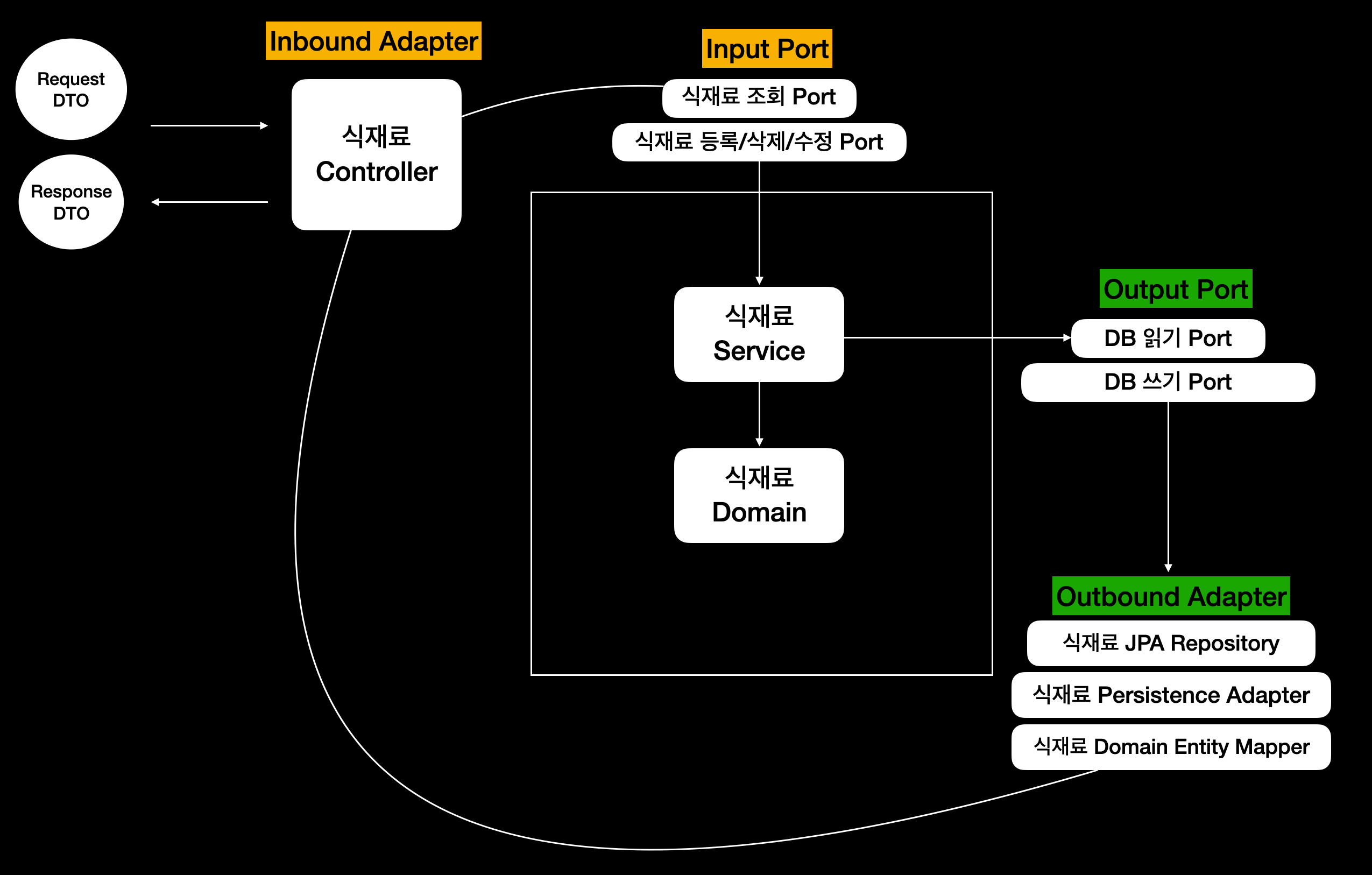
우리는 웹 서비스를 구현하기 때문에 Inbound Adapter 는 Controller 이다. Controller 에서 사용자가 입력한 데이터를 받아 Input Port로 전달한다. 전달된 데이터는 서비스에서 로직을 수행하고 객체를 Output Port 로 넘긴다. 이때 Outbound Adapter 는 Repository 이다. JPA, Querydsl 등 다양한 외부 데이터 베이스 Adapter 가 존재하는데, 우리는 Spring JPA Data 를 사용할 것이다. Persistence Adapter 에서는 말 그대로 영속 상태의 데이터를 가공하여 이를 도메인 형태로 Service에 반환한다.
도메인 객체와 엔티티 객체를 분리해야 한다는 의견도 있고 분리하면 안된다는 의견이 있는데, 우리는 분리하지 않고 도메인 == 엔티티로 구성하여 구현할 예정이다.

분리하는 것이 좋은가, 분리하지 않는 것이 좋은가 혼자 힘으론 답을 얻을 수 없을 것 같아 GPT 친구에게 물어봤다.
일반적으로 엔티티(영속 모델)와 도메인을 분리하여 사용한다고 한다.
도메인 모델은 외부 시스템과의 의존도를 낮추고 비즈니스 규칙과 도메인 개념에만 집중하기 위해서이다. 다만 엔티티와 도메인을 분리하면 Mapper를 따로 만들어서 엔티티는 도메인으로, 도메인은 엔티티로 전환하는 코드를 따로 작성해줘야 한다. 뭐가 더 적절할까 고민해봤지만, 헥사고날 아키텍처가 아직 미숙한 상태에서 관례를 따르는 게 좋다고 판단했다. 하지만 도메인과 엔티티를 합치는 것이 더 편할 경우엔 부분적으로 도메인과 엔티티를 합쳐서 사용하는 방향으로 가는 게 좋을 것 같다.
그러나 차후 개발을 진행하다 보니 엔티티와 도메인을 분리하면 일일이 Mapper를 만들어서 서로의 형태로 전환해줘야 했고 그것에 대한 비용이 상당하다는 것을 알게 되었다.
도메인 영역을 순수하게 유지하고 비즈니스 영역은 비즈니스에만 집중하는 것이 이상적일 수 있지만 개발 실속과 비용에는 불리하게 작용한다는 것을 알게 되었다.
그래서 우리 프로젝트는 도메인과 엔티티를 분리하지 않고 결합된 상태로 사용하도록 결정했다.
헥사고날 아키텍처는 Adapter 와 Port 라는 생소한 개념을 알아야 하고, 자칫하면 과한 아키텍처가 될 수 있는 단점이 있다. 하지만 우리의 프로젝트는 복잡한 비즈니스 로직이 많다. 또한 지금까지 계층형 아키텍처를 사용하며 의존도가 높아지는 바람에 번거로움을 많이 겪었으니, 이번 프로젝트는 헥사고날 아키텍처를 사용해서 개발할 것이다.
- 지금껏 계층형 아키텍처를 사용하여 소프트웨어를 개발했을 때, 다음과 같은 불편함을 겪었다.
- 도메인과 서비스가 복잡해지면 계층간 의존도가 높아져 코드를 관리하기 불편하다.
- 개발자가 지름길(계층을 가로지르는 행위)을 사용하도록 유도한다.
- 테스트가 쉽지 않다.
- 비즈니스 로직이 바뀌거나 요구사항이 변경되면 계층이 단계적으로 연결되어 있어 고쳐야할 코드가 많다.
[참고자료]
1.3 명명규칙
- 기본적인 문법은 구글의 자바 컨벤션 가이드를 따른다.
- 메서드 이름은 반드시 동사 + 명사로 한다.
- 클래스는 명사만, 인터페이스는 형용사/명사만 사용한다.
- 조건/반복문에 중괄호 필수 사용
- 프로그램 내의 모든 변수/함수 이름은 카멜 표기법을 따른다.
- 함수형 인터페이스와 람다식을 지향한다.
- 중복된 코드를 줄일 수 있다.
- 변수/함수의 경우 첫 글자는 소문자로 한다.
- 주석을 최소화한다.
- 중요한 메서드/클래스이거나 부득이하게 필요한 주석이라면 아래 주석 양식에 맞춰 문서화 한다.
- 주석은 Javadoc 기능을 적극 활용한다.
/**
* [작성자] 작성자 이름
* 작성일자 (YYYY.MM.DD 형식으로)
* 메서드 설명
* @param 파라미터 설명
* @throws 예외 설명
* @return 반환값 설명
*//**
* [작성자] NH
* 2023.02.19
* PasswordEncoder를 사용하여 비밀번호를 암호화하는 메서드입니다.
* @param password 사용자 입력 비밀번호
* @throws NotMatchPassword 비밀번호 불일치 언체크 예외
* @return 암호화된 비밀번호
*/1. 4 코딩 표준
- 체크 예외를 반드시 사용해야 하는 경우, 자바독의
@throws를 사용하여 예외가 발생하는 상황을 정확하게 문서화 한다. - 언체크 예외는
@throws목록에 추가하지 않는다. - try-catch 구문이 길어지거나 중복된 코드가 많다면
@RestControllerAdvice를 사용한다.- 컨트롤러에서 모든 예외를 처리하다 보면 중복된 예외 처리 코드가 발생할 수 있다.
- 따라서 예외 처리를 일괄적으로 모아서 관리하여 유지보수가 쉽도록 해야 한다.
/* 예시 */
@Slf4j
@RestControllerAdvice
public class ExceptionHandler {
@org.springframework.web.bind.annotation.ExceptionHandler(BusinessException.class)
public ResponseEntity<ErrorResult> businessException(BusinessException e){
return new ResponseEntity<>(
ErrorResult.create(e.getBaseExceptionType()),
e.getBaseExceptionType().getHttpStatus());
}
}- 생성자는
빌드(Build) 패턴을 사용한다.- 객체가 가진 인자가 많을 경우, 인자들이 어떠한 값인지 헷갈릴 수 있다.
- 생성자에 정의된 인자를 반드시 채워줘야 하는 불편함 존재한다.
- 따라서 생성자를 빌더 패턴으로 생성하여 객체 생성의 유연성을 높인다.
System.out.println대신logger를 사용한다.(@Sl4j)- 각 log는 적절한 level 을 지켜 시스템의 불필요한 출력을 줄인다.
- log의 메시지는 문자열 연산을 사용하지 않는다.
- 순수 비즈니스 로직은
최대 15줄로 제한한다.- 비즈니스 로직을 위한 알고리즘 메서드가 길어질 경우 따로 클래스로 빼서 관리한다.
- 단, 비즈니스 로직 이외, 외부 기술을 위한
@Configuration같은 경우는 예외
N+1 문제가 일어날 수 있는 상황엔 반드시 테스트를 거쳐 확인한다.- cross join은 사용하지 않는다.
- Entity 클래스에는
@Setter를 사용하지 않는다. 로직 상 반드시 필요하다면 setxxx 대신 기능을 나타내는 메서드 명을 사용한다.
[참고 자료]
2. 마치며
우리 프로젝트의 목적은 숨통 끊긴 졸업 프로젝트의 심폐 소생술이기도 하지만 향후 실무에서 만나게 될 대규모 트래픽과 시시각각 변하는 요구사항에 대비하기 위해 예방 주사를 맞는 것과 같다. 따라서 원할한 협업과 프로젝트 목적을 충족시키기 위해선 위와 같은 체계적인 규칙이 필요하며 개발자로서의 성장에 도움이 되리라 기대한다. 🙂
