크게 다음 내용들을 알아본다.
- 함수형 인터페이스
- Stream의 개념
- 병렬 Stream
- Stream과 for-loop의 성능 비교
- Stream에서 외부 지역변수가 final이어야 하는 이유
함수형 프로그래밍이란
- 순수 함수의 조합으로 프로그램을 구현
- 참조 투명성을 지킬 수 있다.
순수 함수란?
외부의 상태를 변경하지 않는 함수
메모리나 I/O 관점에서 사이드 이펙트가 없는 함수여기서 사이드 이펙트는, 다음을 말한다.
1. 변수 값의 변경
2. 자료구조를 제자리에서 수정
3. 객체의 필드값을 설정
4. 예외나 오류 발생. 실행 중단
5. 콘솔, 파일 I/O가 발생
참조 투명성
- 동일한 인자에 대해, 항상 동일한 값을 반환한다.
= 반환값은 매개변수를 제외한 외부 상태(=외부 변수값)에 의존하지 않는다.
이러한 특징들은 프로그램을 예측하기 쉽게 하고, 사이드 이펙트를 최소화하여 특히 동시성 프로그래밍(=여러 작업이 동시에 실행되는 프로그래밍)에서의 개발 난이도를 낮춰 준다.(복잡한 동기화 로직 등을 고려하지 않아도 된다.)
또한, 함수를 변수에 할당할 수 있어, 다른 패러다임에 비해 코드가 간결해지기도 한다.
함수형 인터페이스
- 추상 메소드를 1개만 갖는 인터페이스
- 자바 8 버전에서, 비동기 논블로킹 방식과 함께 함수형 프로그래밍 지원을 위해 도입된 기능.
아래와 같이 정의하고, 사용할 수 있다.
@FunctionalInterface
interface MyFunction1 {
void call(String s);
}
public static void main(String[] args) {
MyFunction1 myFunction1 = str -> System.out.println(str);
myFunction1.call("Hello");
}
// 출력 : Hello
제네릭을 함께 사용하면 편리하다.
@FunctionalInterface
interface MyFunction2<T> {
void call(T t);
}
public static void main(String[] args) {
MyFunction2<String> myFunctionStr = str -> System.out.println(str);
myFunctionStr.call("Hello");
MyFunction2<Integer> myFunctionInt = i -> System.out.println(i);
myFunctionInt.call(1);
/* 출력 :
Hello
1
*/
}@FunctionalInterface 어노테이션의 역할
- 해당 인터페이스가 함수형 인터페이스임을 표시한다.
- 필수는 아니다. 없어도 작동은 잘 한다. 그러나 아래와 같은 장점이 있으니, 붙이는 게 좋다.
- 2개 이상의 추상 메소드가 있으면, 컴파일 타임에 에러를 던져준다.
- 해당 인터페이스는 함수형 인터페이스 용도로 정의된 것임을 표시한다. 즉, 미래에 또 다른 추상 메소드가 추가되어 오류가 발생하는 등의 경우를 사용자가 걱정하지 않게 해준다.
기본 제공되는 함수형 인터페이스
활용도가 높은 함수형 인터페이스들은, 자바에서 이미 제공한다.
Supplier
- 매개변수가 없고, T 타입을 반환한다.
- get()을 통해 실행된다.
@FunctionalInterface
public interface Supplier<T> {
T get();
}
Supplier<Integer> supplier = () -> 1;
System.out.println(supplier.get());
// 출력 : 1Consumer
- T 타입 매개변수를 받고, 반환값이 없다.
- accept() 를 통해 실행된다.
- andThen()이라는 메소드를 제공한다. Consumer의 연쇄적인 사용을 가능하게 한다.
- "현재 Consumer의 로직 + 매개변수로 받는 로직" 을 갖는 Consumer를 반환한다.
- andThen()을 통해 체이닝 방식으로 로직을 추가하고, accept()를 호출하는 시점에 실행된다.
@FunctionalInterface
public interface Consumer<T> {
void accept(T t);
default Consumer<T> andThen(Consumer<? super T> after) {
Objects.requireNonNull(after);
return (T t) -> { accept(t); after.accept(t); };
}
}
public static void main(String[] args) {
// Consumer<String> consumer1 = str -> System.out.println(str);
Consumer<String> consumer1 = System.out::println; // 이와 같은 사용도 가능하다. "메소드 참조" 라고 한다.
consumer1
.andThen(str -> System.out.println(str + " -- 2nd call"))
.andThen(str -> System.out.println(str + " -- 3rd call"))
.accept("target String");
/* 출력 :
target String
target String -- 2nd call
target String -- 3rd call
*/
}Function
- T타입 매개변수를 받고, R타입을 반환한다.
- apply()를 통해 실행된다.
- andThen()에 더해, 로직을 앞에 붙이는 compose()와, 자기 자신을 반환하는 static identity()를 제공한다.
public static void main(String[] args) {
Function<String, Integer> strToInt = Integer::parseInt;
// 입력 문자열에 "-" 를 합하고, int로 바꾸고, x 10 한 값을 반환
System.out.println(strToInt
.compose(str -> "-" + str)
.andThen(i -> i * 10)
.apply("1"));
// 출력 : -10
}Predicate
- T타입을 매개변수로 받고, boolean을 반환한다.
- test()를 통해 실행된다.
- 추가로 and(), or(), negate()(not과 같다.)를 제공한다.
public static void main(String[] args) {
// (s나 a로 시작하고, E로 끝나지 않는지)를 검사
Predicate<String> predicate = str -> str.startsWith("s");
Predicate<String> combinedPredicate = predicate
.or(str -> str.startsWith("a"))
.and(str -> str.endsWith("E")).negate();
List<String> list = Arrays.asList("stringI", "aString", "stringE");
for (String s : list) {
System.out.println(s + " : " + combinedPredicate.test(s));
}
/* 출력 :
stringI : true
aString : true
stringE : false
*/
}Stream이란
개념 및 특징
- 데이터의 흐름을 표준화된 방법으로 쉽게 처리할 수 있도록 지원하는 기능
- Stream API는 자바 8부터 람다식, 함수형 인터페이스 등과 함께 지원
- 데이터를 추상화해서, 쉽게 처리하는 데 자주 사용되는 메소드들(map, reduce, filter...)이 정의되어 있다.
- 일회용이며, 원본 데이터를 변경하지 않는다.
- 생성 시, 원본 데이터를 읽어 별도의 스트림을 생성한다.
- 스트림 연산은, 매개변수로 함수형 인터페이스를 받는다.
연산 종류
스트림이 지원하는 연산은 크게 3종류로 분류된다.
- 생성
- 중간 연산(가공)
- 최종 연산(결과 만들기)
생성
Collection, 배열, 원시 타입(int, long, double)으로부터 스트림을 생성할 수 있다.
// 리스트로부터 생성
List<String> list = Arrays.asList("a", "b", "c");
Stream<String> stream1 = list.stream();
// 배열로부터 생성
String[] arr = new String[]{"a", "b", "c"};
Stream<String> stream2 = Arrays.stream(arr);
// 원시 타입으로 생성
IntStream stream3 = IntStream.range(0, 10);
IntStream stream4 = IntStream.of(3, 6, 9);중간 연산 ~ 최종 연산
중간 연산들은 매개변수로 함수형 인터페이스를 받고, 체이닝이 가능하도록 Stream을 반환한다.
중간 및 최종 연산들은, 이 링크를 참고했다.
연산 수행 시점
실제 연산 수행 시점은, 최종 연산을 호출할 때이다.
중간 연산에서는 연산의 파이프라인을 만들어놓고,
최종 연산 시 그에 따라 동작을 수행한다.
아래 예시에서 확인할 수 있다.
코드
List<String> list = Arrays.asList("str1", "str2");
list.stream()
.peek(str -> System.out.println("peek() running... str = " + str))
.forEach(str -> System.out.println("forEach() running... str = " + str));디버깅 결과
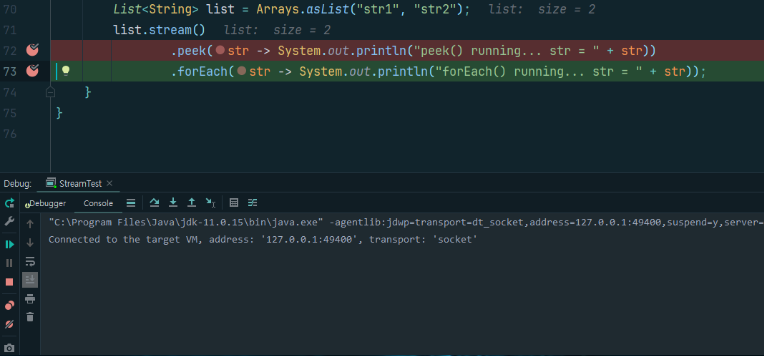
중간 연산인 peek()이 실행되고, 최종 연산인 forEach()가 실행되기 전 시점이다.
아무런 출력도 없는 것을 확인할 수 있다.
(peek과 forEach는 모두, 스트림의 요소를 반복하며 로직을 수행하는 기능이다.)
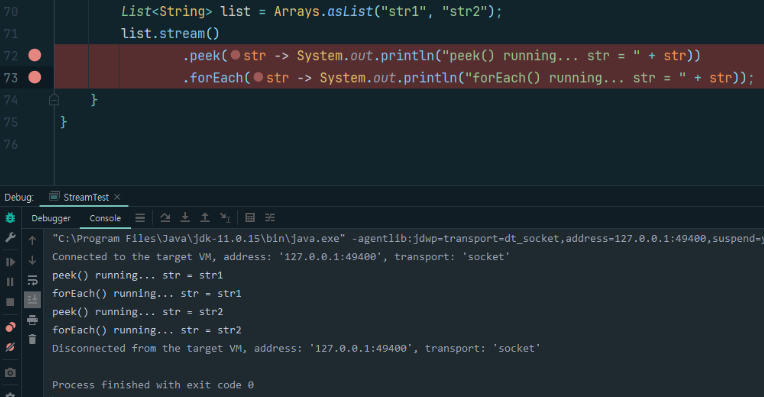
forEach()가 실행된 후, 연산이 수행된다.
중간 연산의 순서를 고려해야 한다.
스트림에서는 연산 순서에 따라서, 연산 횟수가 달라질 수 있다.
아래 예시를 보자.
1, 2, 3의 정수 중, x 10을 한 값이 10 이하인 수만 출력하는 기능이다.
IntStream.range(1, 4)
.map(i -> {
System.out.println("map() 실행됨");
return i * 10;
})
.filter(i -> {
System.out.println("filter() 실행됨");
return i <= 10;
})
.forEach(res -> System.out.println("res = " + res));
/* 출력 :
map() 실행됨
filter() 실행됨
res = 10
map() 실행됨
filter() 실행됨
map() 실행됨
filter() 실행됨
*/수행 횟수 :
map() : 3
filter() : 3
forEach() : 1
이번엔 로직을 다음과 같이 바꿔 보자.
IntStream.range(1, 4)
.filter(i -> {
System.out.println("filter() 실행됨");
return i <= 1;
})
.map(i -> {
System.out.println("map() 실행됨");
return i * 10;
})
.forEach(res -> System.out.println("res = " + res));
/* 출력 :
filter() 실행됨
map() 실행됨
res = 10
filter() 실행됨
filter() 실행됨
*/수행 횟수가 다음과 같이 줄어든 것을 확인할 수 있다.
map() : 1
filter() : 3
forEach() : 1
Stream 병렬 처리
스트림의 parallel() 을 이용하면, 작업을 여러 쓰레드로 처리할 수 있다.
stateful 로직과 사용 시, 동기화 작업에 대한 비용이 추가된다.
따라서 가급적 stateless인 로직만 사용하는 게 좋다.
ForkJoinPool을 기반으로 한다.
수행 과정
- 일정 수준까지 쓰레드를 생성하여 작업을 나누고, (fork phase)
- 각 쓰레드에서 작업을 수행하고, (execution phase)
- 수행 결과를 부모 쓰레드로 넘기며 합쳐서, 결과값을 반환한다. (join phase)
아래 이미지처럼 수행된다.
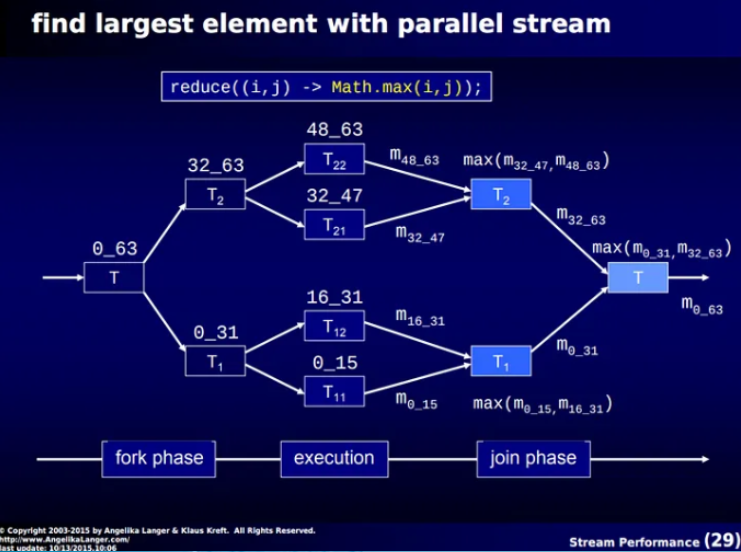
Stream, for-loop 성능 비교
아래 내용을 요약하면,
- for-loop vs 단일 Stream : 가벼운 작업에선 for-loop이 빠르고, 반복 수가 많거나 연산량이 많으면, 비슷해진다.
- 단일 Stream vs 병렬 Stream : 반복 수가 많거나 연산량이 많으면, 병렬 Stream을 고려할 만 하다. 그러나 Stateful한 작업이거나, 분할이 어려운 자료구조이면 추가적인 오버헤드가 있으므로, 직접 해봐야 안다.
라고 할 수 있다.
Java Stream API는 왜 for-loop보다 느릴까?
위 내용을 참고했다.
우선 50만개의 int 데이터를 저장하는 배열을 생성하고,
for-loop와 Sequential Stream(단일 스트림)을 사용하여 max값을 구하는 속도를 비교한다.
코드
int[] ints = 1 ~ 50만까지의 정수를 담는, 길이가 50만인 배열
// for-loop
int[] a = ints;
int e = ints.length;
int m = Integer.MIN_VALUE;
for (int i = 0; i < e; i++) {
if (a[i] > m) {
m = a[i];
}
}
// sequential stream
int m = Arrays.stream(ints).reduce(Integer.MIN_VALUE, Math::max);수행 결과
for-loop : 0.36ms
단일 스트림 : 5.35ms
- primitive 타입을 대상으로 할 땐, 한참 느리다.
컴파일러 단에서 스트림에 비해, for loop에 대한 최적화가 더 잘 되어 있기 때문이다.
다음은 동일한 로직을, int 배열에서 Wrapper 클래스(Integer)를 담는 ArrayList로 바꿔서 수행한다.
수행 결과
for-loop : 6.55ms
단일 스트림 : 8.33ms
Wrapper 클래스를 대상으로 할 땐 차이가 덜해진다.이는 직접 참조와 간접 참조의 효율 차이가, for-loop와 Stream의 성능 차이를 가리기 때문이다.변수 값을 가져올 때, primitive 타입은 한번에 값에 접근할 수 있지만, Wrapper타입은 힙에 저장되므로, 핸들 메모리라는 곳에서 주소값을 가져와서 접근한다.
- 정정!! 자바에서 배열은 객체이므로, 힙에 저장된다. 따라서 배열의 원소에 접근할 때도 간접 참조이다. 위 결과에서 발생한 차이는 배열에 비해 ArrayList가 가진 여러 부가기능들 때문인 것 같다.
참고 링크
Why array values in java is stored in heap? - stackoverflow
순회 비용보다 계산 비용이 높아져도, 효율 차이가 덜해진다.
아래는 위의 단순 비교 로직을 연산량이 많은 slowSin()이라는 함수로 바꾼 후의 결과이다.
수행 결과
int[], for-loop : 11.72ms
int[], 단일 스트림 : 11.85ms
ArrayList, for-loop : 11.84ms
ArrayList, 단일 스트림 : 11.85ms
병렬 스트림의 성능
병렬 스트림 사용으로 성능을 향상시키기 위해서는, 반복 횟수가 충분히 많거나(ex. 길이가 10000 이상인 Collection), 연산이 많은(CPU bound) 작업이어야 한다.
각 쓰레드에의 작업 분할, Thread pool 스케줄링, Garbage Collection 등에 따른 오버헤드가 있기 때문이다.
또한, 아래 설명하는 케이스들에서는 추가적인 오버헤드가 발생한다.
1. Stateful 로직을 가진 병렬 스트림
이런 경우에는, 병렬 스트림 사용에 따른 성능 향상을 체감하기 어렵다.
중복값을 제거하는 distinct()나, 정렬 기능인 sorted() 수행 시, 모든 쓰레드가 수행을 마쳐야 다음 작업으로 넘어갈 수 있다.
아래는 단일 스트림 distinct(), 병렬 스트림 distinct(), 병렬 스트림 distinct() (정렬 X) 를 비교한 내용이다.
코드
// sequential
Arrays.stream(integers).distinct().count();
// parallel, ordered
Arrays.stream(integers).parallel().distinct().count();
// parallel, unordered
Arrays.stream(integers).parallel().unordered().distinct().count();수행 결과
sequential : 6.39ms
parallel, ordered : 34.09ms
parallel, unordered : 9.1ms
2. with LinkedList
LinkedList를 사용하는 경우, fork 단계에서 작업을 분할할 때 오버헤드가 발생한다.
인덱스를 사용한 접근이 아닌, next()의 반복을 통해 접근해야 하기 때문이다.
예시를 통해 쉽게 확인할 수 있다. 아래는 길이 50만의 LinkedList에서 max값을 찾는 연산이다.
코드
// sequential stream
int m = Arrays.stream(ints).reduce(Integer.MIN_VALUE, Math::max);
int m = linkedList.stream().reduce(Integer.MIN_VALUE, Math::max);
// parallel stream
int m = Arrays.stream(ints).parallel().reduce(Integer.MIN_VALUE, Math::max);
int m = linkedList.parallelStream().reduce(Integer.MIN_VALUE, Math::max);
수행 결과
array
sequential : 5.35ms
parallel : 3.35msLinkedList
sequential : 12.74ms
parallel : 19.57ms
그럼에도, CPU 연산이 많은 작업을 수행하는 경우엔 병렬 스트림이 여전히 효과적이다.
아래는 위 1번의 작업을 연산량이 많은 작업으로 대체한 결과이다.
수행 결과
sequential : 11.59ms
parallel, ordered : 6.83ms
parallel, unordered : 6.81ms
위 내용은 작동 환경에 따라 다를 수 있다.
위 for-loop, 단일 스트림, 병렬 스트림간의 비교는 환경에 따라 달라질 수 있다.
따라서 사용을 고려한다면, 사용자가 직접 테스트해보는 것이 적절하다고 한다.
아래는 위의 LinkedList 성능 비교를 다른 작동 환경에서 실행한 결과이다.
수행 결과
sequential : 5.24ms
parallel, ordered : 4.84ms
parallel, unordered : 1.08ms
이전 결과와 다르게, 병렬 스트림의 성능이 훨씬 앞서는 모습이다.
Stream에서 외부 변수 사용시 불변이어야 하는 이유
Stream에서 외부 변수를 사용할 때, 복사본을 사용하기 때문이다.
정확히는, '람다식에서 사용되는 외부 지역변수는 불변이어야 한다' 이다.
이해를 위해, 메모리 구조에 대한 설명이 필요하다.
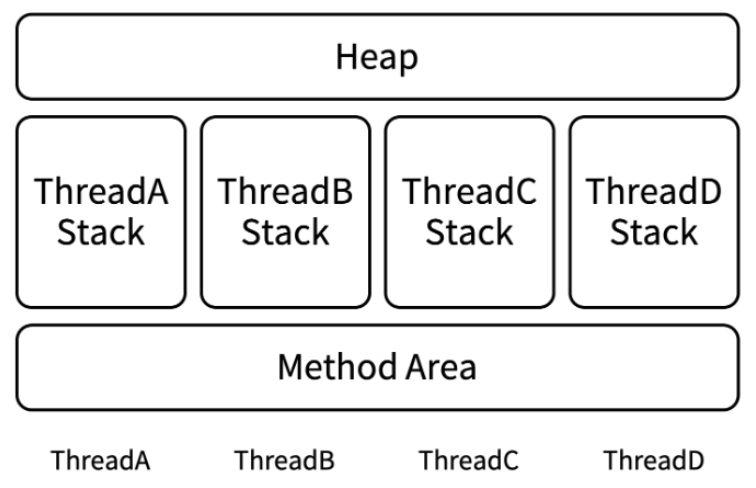
(출처 : https://www.codelatte.io/courses/java_programming_basic/KUYNAB4TEI5KNSJV)
쓰레드들 간에 힙과 메소드 영역은 공유하며, 스택은 개별적인 공간을 사용한다. 즉, 다른 쓰레드의 스택에 접근이 불가능하다.
지역변수를 관리하는 쓰레드(=Thread A)와 람다식을 실행하는 쓰레드(=Thread B)가 다른 경우, Thread B는 Thread A의 지역변수 값을 자신의 스택 영역에 복사해서 사용한다. 이를 람다 캡처링 이라고 한다.
이 과정에서, 사용 중에 원본(=Thread A의 지역변수)에 변경이 발생한다면, 복사본과 동기화가 되지 않아 문제가 발생할 수 있다. 이 때문에 이와 같은 제약조건이 있는 것이다.
반면에, 인스턴스 변수와 static 변수(=클래스 변수)는 이런 조건이 붙지 않는다. 쓰레드 간 공유하는 영역에 위치하기 때문이다.
인스턴스 변수는 힙 영역에, static 변수는 메소드 영역에 저장된다.
[참고 링크]
자바의 함수형 프로그래밍
- Java 8에서 왜 함수형 프로그래밍이 도입되었을까? - tecoble
- 함수형 프로그래밍이란? - mangkyu.tistory
- 람다식과 함수형 인터페이스 - mangkyu.tistory
- @FunctionalInterface 어노테이션 사용은 필수인가? - tutorialspoint
- @FunctionalInterface 어노테이션을 사용하는 이유 - stackoverflow
스트림
- Stream API에 대한 이해 - mangkyu.tistory
- Stream API의 활용 및 사용법 - 기초 - mangkyu.tistory
- Stream API의 고급 활용 및 사용 시의 주의할 점 - mangkyu.tistory
스트림 vs for loop 성능 비교
