기초부터 다지는 Elasticsearch 운영 노하우
10장 내용 정리 및 관련 내용 정리
1. 데이터 노드 추가
클러스터에 노드를 추가하여 적절한 샤드 개수를 지정하면 색인 성능이 올라가는 것을 확인할 수 있다.
샤드 개수 정하기
인덱스의 샤드 개수의 변경은 불가하여 리인덱스로 재색인해야 샤드의 개수를 변경할 수 있다.
샤드의 개수 변경을 허용하지 않는 이유
elasticsearch의 샤드는 내부적으로는 루씬의 인덱스와 대응된다.
각각의 샤드와 루씬 인덱스는 1:1로 대응되고 이 샤드들이 모여서 하나의 인덱스(elasticsearch)를 구성한다.
루씬은 단일 머신에서 동작하는 Stand Alone 검색엔진이고,
샤드 내부에 이러한 독립적인 루씬 라이브러리를 각각 갖고 있는 것이다.
따라서 내부의 루씬은 외부의 엘라스틱서치가 다른 샤드들과 더 큰 데이터셋을 가지고 인덱스를 구성한다는 사실을 전혀 모른다.
이러한 상태에서 샤드의 개수를 변경한다는 것은, 샤드 내부의 각각의 루씬이 갖고 있는 데이터를 모두 재조정하는 것과 같다.
이러한 특징 때문에 엘라스틱서치에서는 샤드의 개수 변경은 불가능하며,
샤드의 변경이 필요한 경우 아예 새로운 인덱스를 생성할 수 있도록 ReIndex API를 사용할 수 있다.
출처: https://jaemunbro.medium.com/elastic-search-%EC%83%A4%EB%93%9C-%EC%B5%9C%EC%A0%81%ED%99%94-68062271fb64클러스터에 존재하는 모든 샤드는 마스터노드에서 관리된다.
따라서 샤드가 많아질 수록 마스터 노드의 부하도 증가한다.
마스터 노드의 부하로 인해 색인과 검색 작업이 느려질 수도 있고, 메모리 문제를 일으킬 가능성도 커질 수 있다. 하지만 너무 커도 문제다. 장애 발생 시 샤드 단위로 데이터가 이동하기 때문에 샤드의 크기가 너무 크면 복구 작업에 부정적인 영향을 미칠 수 있다.
그렇기 때문에 인덱스당 샤드의 개수를 정하는 게 중요하다.
노드당 권장 샤드 개수&용량
1노드당 샤드는 힙메모리 1기가당 20개가 적당하다.
힙메모리 32기가(31기가) 기준 600개 정도가 적당하다.
샤드당 용량은 20GB~40GB가 적당하며, 이보다 높게 저장되는 경우 샤드의 개수를 늘려 용량 조절이필요하다.
인덱스당 샤드의 개수는 샤드의 용량을 보고 정하는게 좋다.
💡참고
elastcisearch 힙메모리 관련 내용
- Xms와 Xmx 수치를 동일하게 할당합니다. - 최소와 최대 힙 크기를 동일하게 할당하지 않으면 힙 메모리 할당량을 확장하는 과정에서 노드가 일시적으로 멈출 수 있습니다. 기본값은 1기가로 되어 있습니다.
- 힙 크기는 최대 시스템 물리 메모리의 절반으로 합니다. - 엘라스틱서치는 힙 메모리 외에도 빠른 검색과 인덱싱 성능을 위해 파일 시스템 캐시를 적극적으로 활용합니다. 이 또한 상당한 메모리를 사용하므로 충분한 여유 메모리를 확보하지 않으면 성능상 문제가 생길 수 있습니다.
- 힙 크기는 최대 30 ~ 31GB 수준을 넘기지 않습니다. - 자바에는 힙 메모리를 빠르고 효율적으로 활용할 수 있도록 Compressed Ordinary Object Pointers 기술이 적용되어 있는데 이는 시스템마다 차이가 있지만 일반적으로 힙 메모리가 최대 32GB를 넘기면 비활성화가 됩니다. 이 경우 충분히 큰 힙 메모리를 할당했음에도 오히려 성능이 급격히 저하되는 현상을 겪을 수 있습니다. 예를 들어, 물리 장비당 단일 노드만 실행한다는 가정하에 물리 메모리가 32GB인 장비라면 16GB 힙 크기를 할당하고, 물리 메모리가 64GB인 장비라면 30~31GB수준의 힙 크기를 할당하는 것이 적정합니다.
2. 정적매핑 적용하기
- 필요한 필드들만 정의해서 사용할 수 있고 불필요한 매핑 정보를 사용하지 않기 때문에 색인 성능을 향상시킬 수 있다.
- 문자열 필드가 많으면 많을수록 분석이 불필요한 필드를 keyword 타입으로 변경해서 성능향상 효과를 볼 수 있다.
3. refresh_interval 변경하기
- elasticsearch는 색인되는 문서들을 메모리 버퍼 캐시에 먼저 저장한 후 특정 조건이 되면 메모리 버퍼 캐시에 저장된 색인 정보나 문서들을 디스크에 세그먼트 단위로 저장한다.
색인된 문서는 이렇게 세그먼트 단위로 저장되어야 검색이 가능해지며, 이런 일련의 작업들을 refresh라고한다. 이 refresh를 얼마나 자주할 것인지를 결정하는 값이 refresh_interval 이다. - dafualt 값은 1초 이고, refresh 작업은 디스크 I/O를 발생시키기 때문에 성능을 저하시킬 수 있다.
- 다량의 문서를 한 번에 인덱스에 저장하는 작업을 진행할 때 refresh_interval을 비활성화 하고 복구 하는 방식으로 작업을 진행하면 색인성능에 도움이 된다.
refresh_interval 변경 방법
curl -X PUT "localhost:9200/ refresh_index/,settings?pretty" -H 'Content-Type: application/json' -d'
{
"index.refresh_interval": "-1"
}색인 작업 이후에는 1s로 다시 원상복귀.
4. bulk API
- bulk API는 한 번에 다량의 문서를 색인,삭제,수정할 때 사용하는 API이다.
색인 시 bulk API를 통해 색인 데이터를 특정 개수 만큼 묶어서 색인하는 것으로 성능을 향상시킬 수 있다.
5. 그외의 방법들
-
별도의 ID 지정없이 색인하기
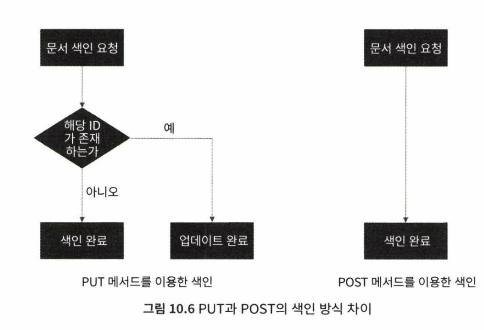
PUT을 이용한 색인보다 POST를 이용한 색인이 조금 더 빠르다. -
레플리카 샤드 개수를 0개로 설정하고 색인하기.
문서 색인이 요청되면 프라이머리 샤드가 완전히 색인이 완료된 이후에 레플리카 샤드를 복제한다.
이렇게 레플리카 샤드의 복제 수행 까지 끝낸 다음 클라이언트에게 수행한 작업에 대한 결과를 리턴한다.
하지만 레플리카 샤드가 없다면 각각 자신이 가지고 있는 샤드만 색인한 후 색인 작업을 마무리한다. 그렇기 때문에 레플리카 샤드가 없다면 전체적인 색인 성능이 향상된다.
대용량의 로그 데이터를 색인할 경우에는 레플리카 샤드 없이 프라이머리 샤드만 두어 문서를 색인한 후 모든 색인이 완료되면 레플리카 샤드를 추가하는 형태로도 운영한다.
