파티셔닝(Partitioning)?
DB에서 크기가 큰 테이블을 작은 단위로 나눠 관리하는 기법.
물리적인 데이터의 분할이 있지만, DB에 접근하는 application의 입장에서는 이를 인식하지 못한다.
파티셔닝, 왜 필요할까?
- 파티션 단위로 I/O 분산, 백업/복구가 가능하므로 대용량의 데이터를 핸들링 해야 할 때 DB 성능이 증가한다.
- 데이터의 물리적 형상이 분리되기 때문에 데이터가 한 번에 손실 될 가능성이 적다.
파티셔닝 구분
-
수평 파티션 분할(샤드)
- 행 단위로 잘라 분할.
- 한 테이블을 같은 스키마를 갖는 여러 작은 테이블로 나누는 기법이다.
- 파티션 키(샤드 키)를 기준으로 데이터를 분할한다.
- 데이터의 수가 작아지고, 이에 따라 인덱스 개수도 작아져 성능 향상으로 이어진다.
- 데이터 찾는 과정이 복잡해지기 때문에 latency가 증가한다.
-
수직 파티션 분할
- 특정 컬럼을 기준으로 쪼개 저장하는 형태.
- 스키마가 분할 된다.
- 하나의 엔터티를 2개 이상으로 분리하는 작업.
- 자주 사용하는 컬럼 위주로 데이터를 분리하여 성능을 향상 시킬 수 있다.
- SELECT 시 불필요한 컬럼까지 메모리에 올리지 않아 한번에 읽어들일 수 있는 ROW가 늘어난다.
- 같은 타입의 데이터가 저장되기 때문에 저장 시 압축률을 높일 수 있다.
수평 파티셔닝 기법
-
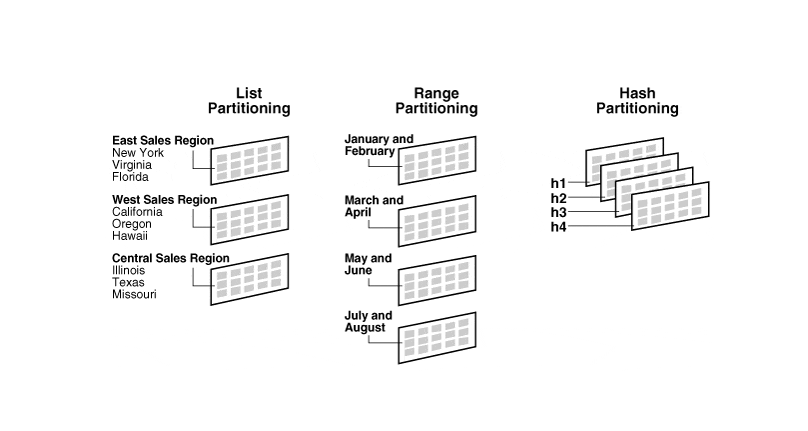
Range Partitioning
파티션 키의 범위를 기준으로 데이터를 분할.
여러 파티션에 균등하게 나눌 수 있는 경우 유용하게 사용 가능하다.
ex. [날짜(년도)] 기준으로 분할CREATE TABLE User ( id INT NOT NULL, name VARCHAR(30), date DATE NOT NULL DEFAULT '1970-01-01') PARTITION BY RANGE (YEAR(date)) ( PARTITION p0 VALUES LESS THAN (2010) , PARTITION p1 VALUES LESS THAN (2011) , PARTITION p2 VALUES LESS THAN (2012) , PARTITION p3 VALUES LESS THAN MAXVALUE); -
List Partitioning
고정 된 키 값을 기준으로 데이터를 분할.
ex. [지역 명] 기준으로 분할CREATE TABLE User ( id INT NOT NULL, name VARCHAR(30), date DATE NOT NULL DEFAULT '1970-01-01', region VARCHAR(30) NOT NULL) PARTITION BY LIST (region) ( PARTITION p0 VALUES IN ('KR/Seoul') , PARTITION p1 VALUES IN ('KR/Busan') , PARTITION p2 VALUES IN ('KR/Daejeon') , PARTITION p3 VALUES IN (NULL)); -
Hash Partitioning
Hash함수 결과값을 기준으로 데이터를 분할.
범위(Range Partitioning), 특정한 키 값(List Partitioning)으로 데이터를 균등 분할 하기 어려울 때 사용한다.※ 새롭게 파티션이 추가 될 때 파티션에 저장 된 모든 레코드가 재배치되어 많은 부하가 발생한다.
ex. 사용자 id에 대한 해시값을 기준으로 10개의 파티션으로 분할
CREATE TABLE User ( id INT NOT NULL, name VARCHAR(30), date DATE NOT NULL DEFAULT '1970-01-01') PARTITION BY HASH (id) PARTITIONS 10;인덱스는 파티션 단위로 생성된다.
파티션 된 테이블에서 인덱스는 정렬 되지 않은 상태로 존재하며 탐색 시점에 정렬된다.파티션 된 테이블에서의 인덱스 정렬
- 여러 파티션에 대한 데이터 스캔
- 조건에 맞는 파티션의 레코드를 우선순위 큐에 저장
- 큐 내에서 인덱스에 따라 정렬 수행
참고자료
https://gmlwjd9405.github.io/2018/09/24/db-partitioning.html
https://velog.io/@litien/%ED%8C%8C%ED%8B%B0%EC%85%94%EB%8B%9DPartitioning

어제의 나보다 더 나은 사람이 되자