컴파일러
컴파일: 소스코드를 컴퓨터가 이해할 수 있는 기계어 형식으로 번역하는 것
컴파일러: 컴파일을 해주는 소프트웨어
Ex) GCC, Clang, MSVC 등
인터프리터
python, Javascript 등은 컴파일을 필요로 하지 않는다.
인터프리팅: 사용자가 작성한 스크립트를 그때 그때 번역하여 CPU에 전달
인터프리터: 인터프리팅을 처리해주는 프로그램
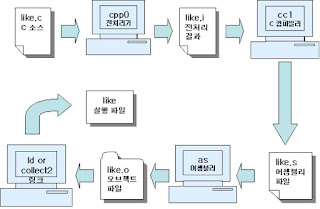
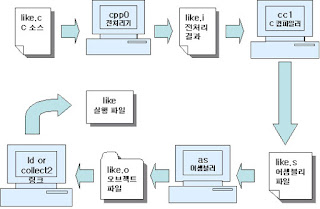
컴파일 과정
전처리(Preprocess), 컴파일(Compile), 어셈블(Assemble), 링크(Link)
- 예제 코드
// Name: add.c
#include "add.h"
#define HI 3
int add(int a, int b) { return a + b + HI; } // return a+b
// Name: add.h
int add(int a, int b);
<컴파일 과정 속 컴파일>
어떤 언어로 작성된 소스 코드(Source Code)를 다른 언어의 목적 코드(Object Code)로 번역하는 것.
전처리
컴파일러가 소스 코드를 어셈블리어로 컴파일하기 전에, 필요한 형식으로 가공하는 과정
- 주석 제거
- 매크로 치환
- 파일 병합
gcc에서 -E 옵션을 사용하여 소스 코드의 전처리 결과를 확인할 수 있다.
$ gcc -E add.c > add.i
$ cat add.i
# 1 "add.c"
# 1 "<built-in>"
# 1 "<command-line>"
# 31 "<command-line>"
# 1 "/usr/include/stdc-predef.h" 1 3 4
# 32 "<command-line>" 2
# 1 "add.c"
# 1 "add.h" 1
int add(int a, int b);
# 2 "add.c" 2
int add(int a, int b) { return a + b + 3; }컴파일
소스 코드를 어셈블리어로 번역하는 것. 이 과정에서 컴파일러는 소스 코드의 문법을 검사, 코드에 문법적 오류가 있다면 컴파일 멈추고 에러 출력.
컴파일러는 코드를 번역할 때 몇몇 조건을 만족하면 최적화 기술을 적용하여 효율적인 어셈블리 코드를 생성한다. gcc에서는 -O -O0 -O1 -O2 -O3 -Os -Ofast -Og 등의 옵션을 사용할 수 있다.
Ex) 아래의 opt.c를 최적화하여 컴파일.
// Name: opt.c
// Compile: gcc -o opt opt.c -O2
#include <stdio.h>
int main() {
int x = 0;
for (int i = 0; i < 100; i++) x += i; // x에 0부터 99까지의 값 더하기
printf("%d", x);
}컴파일러는 반복문을 어셈블리어로 옮기는 것이 아니라, 반복문의 결과로 x가 가질 값을 직접 계산하여 이를 대입하는 코드를 생성한다.
0x0000000000000560 <+0>: lea rsi,[rip+0x1bd] ; 0x724
0x0000000000000567 <+7>: sub rsp,0x8
0x000000000000056b <+11>: mov edx,0x1356 ; hex((0+99)*50) = '0x1356' = sum(0,1,...,99)
0x0000000000000570 <+16>: mov edi,0x1
0x0000000000000575 <+21>: xor eax,eax
0x0000000000000577 <+23>: call 0x540 <__printf_chk@plt>
0x000000000000057c <+28>: xor eax,eax
0x000000000000057e <+30>: add rsp,0x8
0x0000000000000582 <+34>: ret-S 옵션을 이용하면 소스 코드를 어셈블리 코드로 컴파일할 수 있다.
$ gcc -S add.i -o add.S
$ cat add.S
.file "add.c"
.intel_syntax noprefix
.text
.globl add
.type add, @function
add:
.LFB0:
.cfi_startproc
push rbp
.cfi_def_cfa_offset 16
.cfi_offset 6, -16
mov rbp, rsp
.cfi_def_cfa_register 6
mov DWORD PTR -4[rbp], edi
mov DWORD PTR -8[rbp], esi
mov edx, DWORD PTR -4[rbp]
mov eax, DWORD PTR -8[rbp]
add eax, edx
add eax, 3
pop rbp
.cfi_def_cfa 7, 8
ret
.cfi_endproc
.LFE0:
.size add, .-add
.ident "GCC: (Ubuntu 7.5.0-3ubuntu1~18.04) 7.5.0"
.section .note.GNU-stack,"",@progbits어셈블
컴파일로 생성된 어셈블리어 코드를 ELF 형식의 목적 파일(Object file)로 변환하는 과정. 윈도우에서 어셈블하면 목적 파일은 PE 형식을 가지게 된다.
ELF란?
유닉스 계열 운영체제의 실행, 오브젝트 파일, 공유 라이브러리, 또는 코어 덤프를 할 수 있게 하는 바이너리 파일.
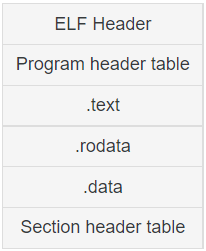
다음은 gcc의 -c 옵션을 통해 add.S를 목적 파일로 변환하고 결과를 16진수로 출력한 것이다.
$ gcc -c add.S -o add.o
$ file add.o
add.o: ELF 64-bit LSB relocatable, x86-64, version 1 (SYSV), not stripped
$ hexdump -C add.o
00000000 7f 45 4c 46 02 01 01 00 00 00 00 00 00 00 00 00 |.ELF............|
00000010 01 00 3e 00 01 00 00 00 00 00 00 00 00 00 00 00 |..>.............|
00000020 00 00 00 00 00 00 00 00 10 02 00 00 00 00 00 00 |................|
00000030 00 00 00 00 40 00 00 00 00 00 40 00 0b 00 0a 00 |....@.....@.....|
00000040 55 48 89 e5 89 7d fc 89 75 f8 8b 55 fc 8b 45 f8 |UH...}..u..U..E.|
00000050 01 d0 5d c3 00 47 43 43 3a 20 28 55 62 75 6e 74 |..]..GCC: (Ubunt|
00000060 75 20 37 2e 35 2e 30 2d 33 75 62 75 6e 74 75 31 |u 7.5.0-3ubuntu1|
00000070 7e 31 38 2e 30 34 29 20 37 2e 35 2e 30 00 00 00 |~18.04) 7.5.0...|
00000080 14 00 00 00 00 00 00 00 01 7a 52 00 01 78 10 01 |.........zR..x..|
00000090 1b 0c 07 08 90 01 00 00 1c 00 00 00 1c 00 00 00 |................|
000000a0 00 00 00 00 14 00 00 00 00 41 0e 10 86 02 43 0d |.........A....C.|
000000b0 06 4f 0c 07 08 00 00 00 00 00 00 00 00 00 00 00 |.O..............|
...링크
여러 목적 파일들을 연결하여 실행 가능한 바이너리로 만드는 과정.
링크가 필요한 이유는?
// Name: hello-world.c
// Compile: gcc -o hello-world hello-world.c
#include <stdio.h>
int main() { printf("Hello, world!"); }위 코드에서 printf 함수를 호출하지만 해당 함수의 정의는 hello-world.c에 없고 libc라는 공유 라이브러리에 존재한다. libc는 gcc의 기본 라이브러리 경로에 있는데 링커는 바이너리가 printf를 호출하면 libc의 함수가 실행될 수 있도록 한다. 링크를 거치고 나면 실행 가능한 프로그램이 완성된다.
$ gcc add.o -o add --unresolved-symbols=ignore-in-object-files
$ file add
add: ELF 64-bit LSB shared object, x86-64, version 1 (SYSV), dynamically linked, interpreter /lib64/l, ...add.o를 링크하는 명령어이다. 링크 과정에서 링커는 main 함수를 찾는데 add의 소스 코드에 main 함수가 없으므로 에러가 발생할 수 있다. 이를 방지하기 위해 --unresolved-symbols를 컴파일 옵션에 추가했다.
디스어셈블과 디컴파일
디스어셈블
기계어를 어셈블리어로 재번역하는 과정. 어셈블의 역과정.
다음 명령어로 디스어셈블된 결과를 확인할 수 있다.
$ objdump -d ./add -M intel
...
000000000000061a <add>:
61a: 55 push rbp
61b: 48 89 e5 mov rbp,rsp
61e: 89 7d fc mov DWORD PTR [rbp-0x4],edi
621: 89 75 f8 mov DWORD PTR [rbp-0x8],esi
624: 8b 55 fc mov edx,DWORD PTR [rbp-0x4]
627: 8b 45 f8 mov eax,DWORD PTR [rbp-0x8]
62a: 01 d0 add eax,edx
62c: 5d pop rbp
62d: c3 ret
62e: 66 90 xchg ax,ax
...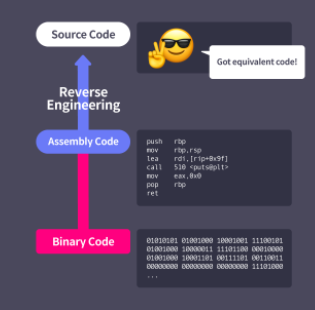
디컴파일
어셈블리어보다 고급 언어로 바이너리를 번역.
어셈블리어와 기계어는 거의 일대일로 대응되어 오차없는 디스어셈블러 개발 가능.
고급 언어와 어셈블리어 사이에는 이런 대응 관계가 없다. 따라서 디컴파일러는 일반적으로 바이너리의 소스 코드와 동일한 코드를 생성하지는 못한다. 그러나 이 오차가 바이너리의 동작을 왜곡하지는 않고 디스어셈블러보다 압도적으로 분석 효율을 높여주기 때문에 디컴파일러를 사용하는 것이 유리하다.
ex) Hex Rays, Ghidra, IDA 등
프로그램: 컴퓨터가 실행해야 할 명령어의 집합, 바이너리라고도 불림
전처리: 소스 코드가 컴파일에 필요한 형식으로 가공되는 과정
컴파일: 소스 코드를 어셈블리어로 번역하는 과정
어셈블: 어셈블리 코드를 기계어로 번역하고, 실행 가능한 형식의 변형하는 과정
링크: 여러 개의 목적 파일을 하나로 묶고, 필요한 라이브러리와 연결해주는 과정
디스어셈블: 바이너리를 어셈블리어로 번역하는 과정
디컴파일: 바이너리를 고급 언어로 번역하는 과정
