1. Intro
- GPT-3 'Few Shot' 성능에 관하여
- 한계: tuning 필요 -> In-Context Learning / 모델 사이즈 증가
2. 기존 문제점 / 한계
문제점
- Fine-tuning 해줘야 한다
- 기존 LLM : Dataset -> 사전학습
- GPT: 입력 받은 문장으로 다음 단어 예측: Autoregressive
- BERT: 문장 중간의 감춰진 단어 예측: Mask Prediction
- 추가적인 Fine-Tuning 진행
ex) 번역 LLM 만들고 싶어!
- Autoregressive / Mask Prediction 둘 중 하나로 데이터 사전 학습 후,
번역 dataset으로 다시 tuning
한계
- Labeling Dataset 많이 필요
- Fine Tuning 과정에서 model이 일반화 능력이 떨어진다.
- 사람마다 차이가 존재한다.
3. GPT-3
1. trend (접근 방법)
- In-Context Learning: 전혀 학습을 하지 않고, 사전 학습된 모델로 새로운 문제를 해결 시, 예시 제공
- Model Capacity: model size 키워서 더 많은 parameter를 얻는다
2. GPT-3 가정
- Fine-Tuning X -> model size up + In-Context Learning
3. 방법
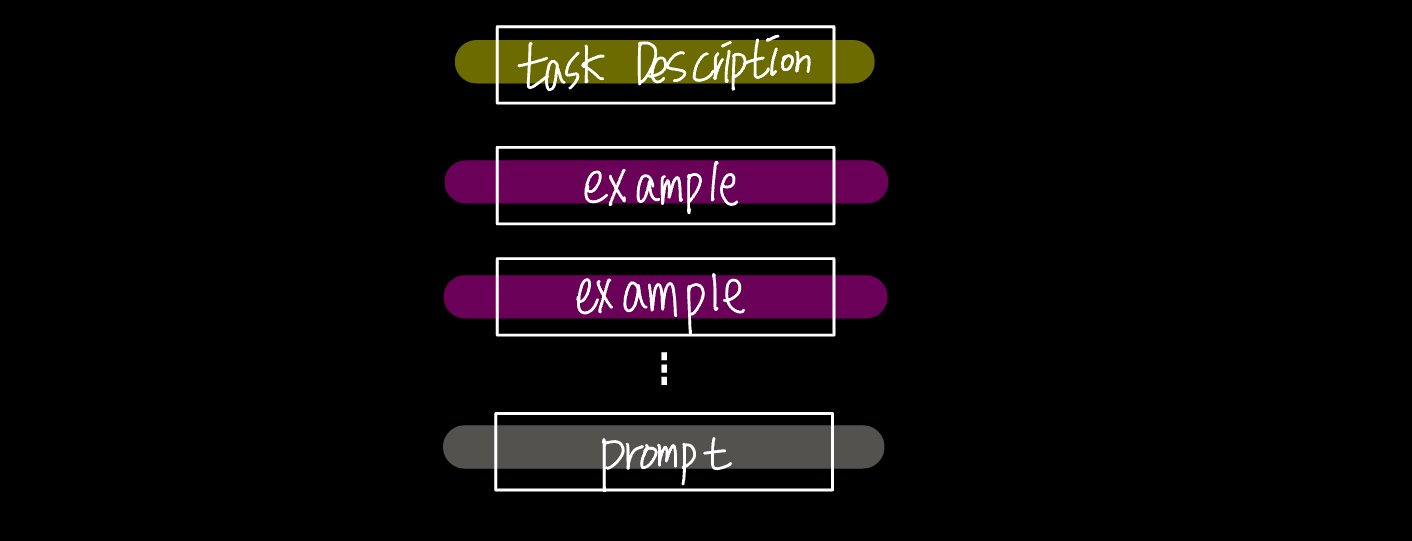
three solution of In-Context Learning
-
Zero-Shot : 모델에게 문제만 설명 / 예시 제공 X

-
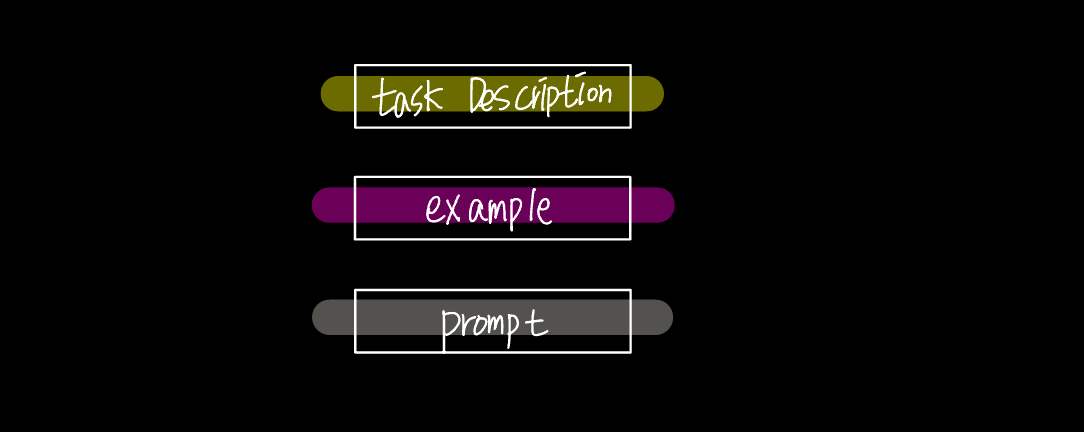
One-Shot : 모델에게 문제 설명 + 하나의 예시 제공
-
Few-Shot : 모델에게 문제 설명 + 여러개의 예시 제공