0531~0605 완료
🤩 Automatic Evaluation의 Purpose 자체는, 결국 Gold Standard로 여겨지는 Human Reference(혹은 evaluation)에서 자유로워지기 위함.
BLEU (Bilingual Evaluation Understudy Score) 논문 링크
- Automatic Machine Translation Evaluation 방법 中 하나
🤔 How dose one measure translation performance?
The closer a machine translation is to a professional human translation, the better it is.
- BLEU를 측정하기 위해서 필요한 two ingredients
① a numerical "translation closeness" metric (번역 유사성을 수치화하는 지표)
② a corpus of good qulaity human reference translations(양질의 인간 참조 번역 모음)
- 인간 번역과의 유사성(closeness to one or more reference human translations)을 수치화하여 번역 Quality를 평가하고, 여러 Reference 번역과 단어 및 구문 일치 정도를 기반으로 함.
- BLEU의 동작 방식
😛 요약
N-gram Precision을 사용하여 Candidate translation과 Reference translation 간의 일치(match)를 평가하고, 번역 길이를 고려한 Penalty를 부과하여 적절한 길이의 번역을 권장.
- 단어 및 구문 일치 (n-gram precision): Candidate translation에서 reference translation과 일치하는 'uni • bi• tri • 4-gram' 등, N-gram의 비율을 계산함. 일치하는 단어와 구문의 비율이 높을수록 Precision가 높아짐.
- Modified precision: Candidate translation이 overgenerated 단어를 사용하여 높은 Precision을 달성하지 않도록, 각 단어가 Reference translation에서 등장하는 최대 횟수를 기준으로 조정함.
- Brevity penalty
- BLEU의 장점
① Quick
② Inexpensive
③ Language-independent
④ Human Evaluation과 크게 상관관계가 있음
⑤ Little marginal cost (한계 비용이 적음)
ROUGE (Recall-Oriented Understudy for Gisting Evaluation) 논문 링크
- Automatic Machine Summarization Evaluation 방법 中 하나
- 총 4가지의 다른 ROUGE 방법이 존재함(ROUGE-N, ROUGE-L, ROUGE-W, ROUGE-S)
- ROUGE-N: N-gram Co-Occurrence Statistics (base on Recall)
Candidate summarization과 Reference summarization 간의 N-gram recall을 측정함. - ROUGE-L: Longest Common Subsequence
두 Summarization 간의 LCS를 기반으로 Summarization의 Cognateness(유사성)을 평가함. 두 Summarization 간의 LCS 길이를 계산하여 F-Score를 구함. - ROUGE-W: Weighted Longeest Common Subsequence
기존 LCS 단점을 보완하기 위해 연속적인 일치의 길이에 Weighted 하는 방식.😎 기존 LCS 단점
기존의 LCS Algorithm은 두 문자열 간의 공통된 부분 문자열의 길이를 계산함. 그러나, 그 부분 문자열이 각 문자열 내에서 얼마나 떨어져 있고, 또 얼마나 밀접하게 연속적으로 위치해 있는지 등을 고려하지 않음. 이는 두 문자열 사이의 실제 Precision을 충분히 반영하지 못할 수도 있다는 한계가 있음.
- ROUGE-S: Skip-Bigram Co-Occurence Statistics
문장 내의 arbitrary gaps을 허용(=순서만 맞으면 인정, 단어 순서에 민감하다는 의미)하는 pair of word을 기반으로 summarization을 평가함. skip-bigram의 중복을 count하여 candidate summarization과 reference summarization 간의 co-occurence를 측정함.
MoverScore 논문 링크
- 이전 기존 지표들은 텍스트의 표면적 유사성에 의존하고 있음. 이를 해결하기 위해 MoverScore이 등장함.
-
(1) 시스템 및 Reference 텍스트의 Contextualized 표현 (2) 시스템 출력과 Reference 간의 Semantic 거리를 측정하여 Representation 간의 거리의 조합을 기반으로 구축됨.
-
Soft alignments에 의존함.
BERTScore 논문 링크
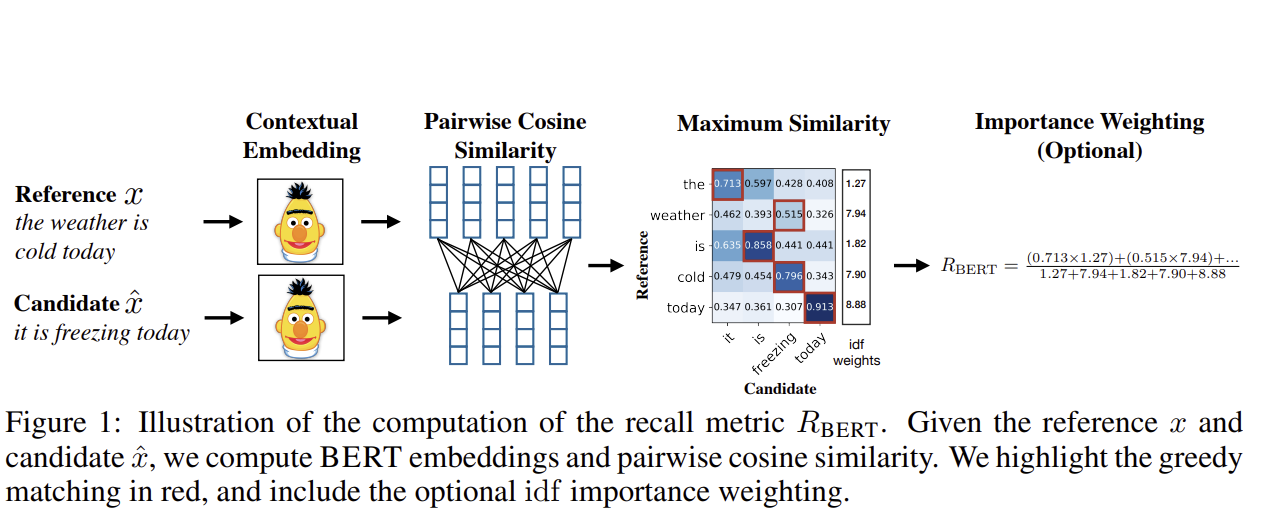
- Contextual embeddings을 사용하여 Reference 문장에 있는 각각의 Token으로 Candidate 문장에 있는 각각의 Token에 대한 Similarity score을 계산함.
😋 Contextual embeddings 장점
(1) 문장 내의 Token의 구체적인 사용을 포착 O
(2) 연속적인 정보를 포착 O
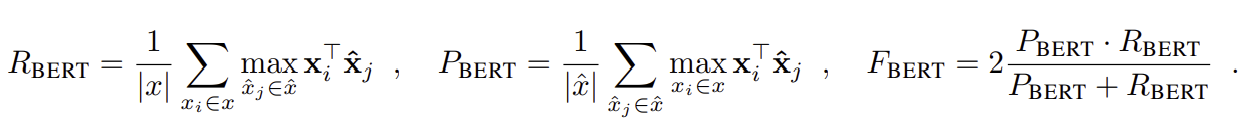
The complete score matches each token in x to a token in xˆ to compute recall, and each token in xˆ to a token in x to compute precision. We use greedy matching to maximize the matching similarity score,2 where each token is matched to the most similar token in the other sentence. We combine precision and recall to compute an F1 measure. For a reference x and candidate xˆ, the recall, precision, and F1 scores are(...)
- Recall: Reference x의 각 토큰 x^i에 대해 Candidate x^의 모든 token 중에서 가장 유사한 토큰 x^j를 찾음.
- Precision: Candidate x^의 각 token x^j에 대해 Reference x의 모든 token 중에서 가장 유사한 token x^i를 찾음.
- F1-score: 1, 2의 조화 평균 계산함.
UNION(UNreferenced metrIc for evaluating OpeneNded story generation) 논문 링크
-
Reference 없이 Genereated Story의 Quality를 측정.
"(...)there are many plausible outputs for the same input, which may differ substantially in literal or semantics from the limited number of given references."
동일한 입력에 대해 여러 가지 가능한 출력이 존재할 수 있는데, 생성된 출력은 주어진 Reference와 Lexically(문자적)으로 혹은 Semantically(의미적)으로 크게 다를 수 있음. 일치도만으로 평가하는 것에는 무리가 있음.
-
Human-written stories의 negative samples을 통해 훈련된 UNION이 Negative stories에 가해진 Perturbation을 Recover하는 방식으로 작동함.
😊 Negative Sampling 방법 4가지
1. Repetition : Lexical Repetition / Senetence-level Repetition 사용
2. Substitution: Word-level Substitution(단어 수준 대체) / Senetence Substitution(문장 수준 대체)
3. Reordering: Sentence Reordering(문장 재배열)
4. Negation Alteration: Negation Addition/Removal(부정어 추가/제거)
😉 Perturbation란?
: 원래 상태나 위치에서 벗어나게 하는 작은 변화 또는 교란을 의미. 시스템이나 환경에 외부로부터 가해진 작은 변화로, 그 결과로 시스템이 반응하거나 변화하는 것을 나타냄.
- Heuristic Rule(경험 • 실증적 바탕으로 문제를 해결하는 방법)을 사용함.
MANPLTS 논문 링크
-
UNION의 발전 모델
-
스토리를 생성할 시, 사용되는 제어 가능한 요소를 구조적으로 표현한 Plot(Plot manipulation)을 사용하여 보다 포괄적으로 Implausible한 스토리 세트를 생성하여 이전의 문제를 해결함.
😒 이전의 문제
Repetition, Contradiction, 텍스트 수준의 관련 없는 콘텐츠 생성과 같은 가능한 시스템 단점을 모방하기 위해 Heuristically manipulated한 예시에 의존함.
자연스러움 부족 • 특성 단순화(기계가 생성한 비논리적 스토리가 가질 수 있는 다양한 특성을 반영하지 못함) • 평가 정확도 저하
-
Plot manipulation과 Adversarial filtering techniques을 사용
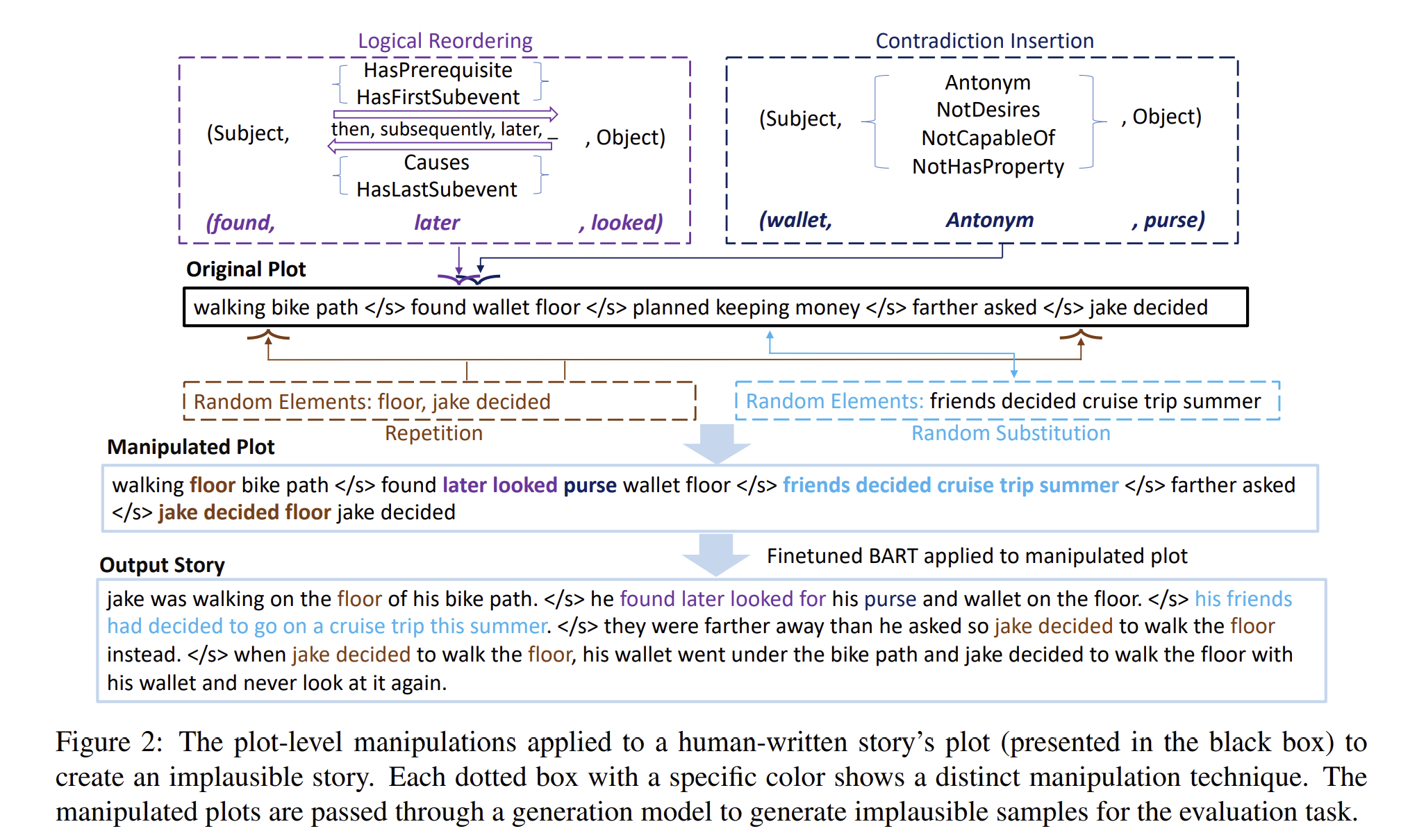
⇒ Plot manipulation : 스토리의 구조적 요소인 Plot을 변형하여 비논리적인 스토리를 생성함.
1. Non-logically Ordered Plots: Plot 내 개념들을 논리적 순서에 맞지 않게 재배치
2. Contradiction Insertion: Plot 내 특정 요소에 반대되는 개념을 삽입하여 모순 발생
3. Repetition Insertion: Plot 내 특정 요소를 반복하여 삽입
4. Random Substitution: Plot 내 일부 요소를 무작위로 대체⇒ Adversarial filtering techniques
1. 각 Content에 대해 N개의 기계 생성 문장 준비 후, Worst 문장들을 임의로 선택하여 Set A를 생성
2. 반복 학습 및 교체: 총 2개의 부분(임의로 ɑ, ʙ로 구분)으로 나뉨
- ɑ: Classifier가 High/Low quality의 문장을 구분하는 학습을 위해 사용
- ʙ: Set A의 Low quality을 새로운 Adversarial 문장으로 교체하는데 사용
3. 1~2 과정 반복
CTC(Compression, Transduction, and Creation) 논문 링크
- 광범위한 언어 생성 작업 및 Quality 측정에 대한 Design of metrics를 용이하게 하는 Unifying perspective를 제안함.
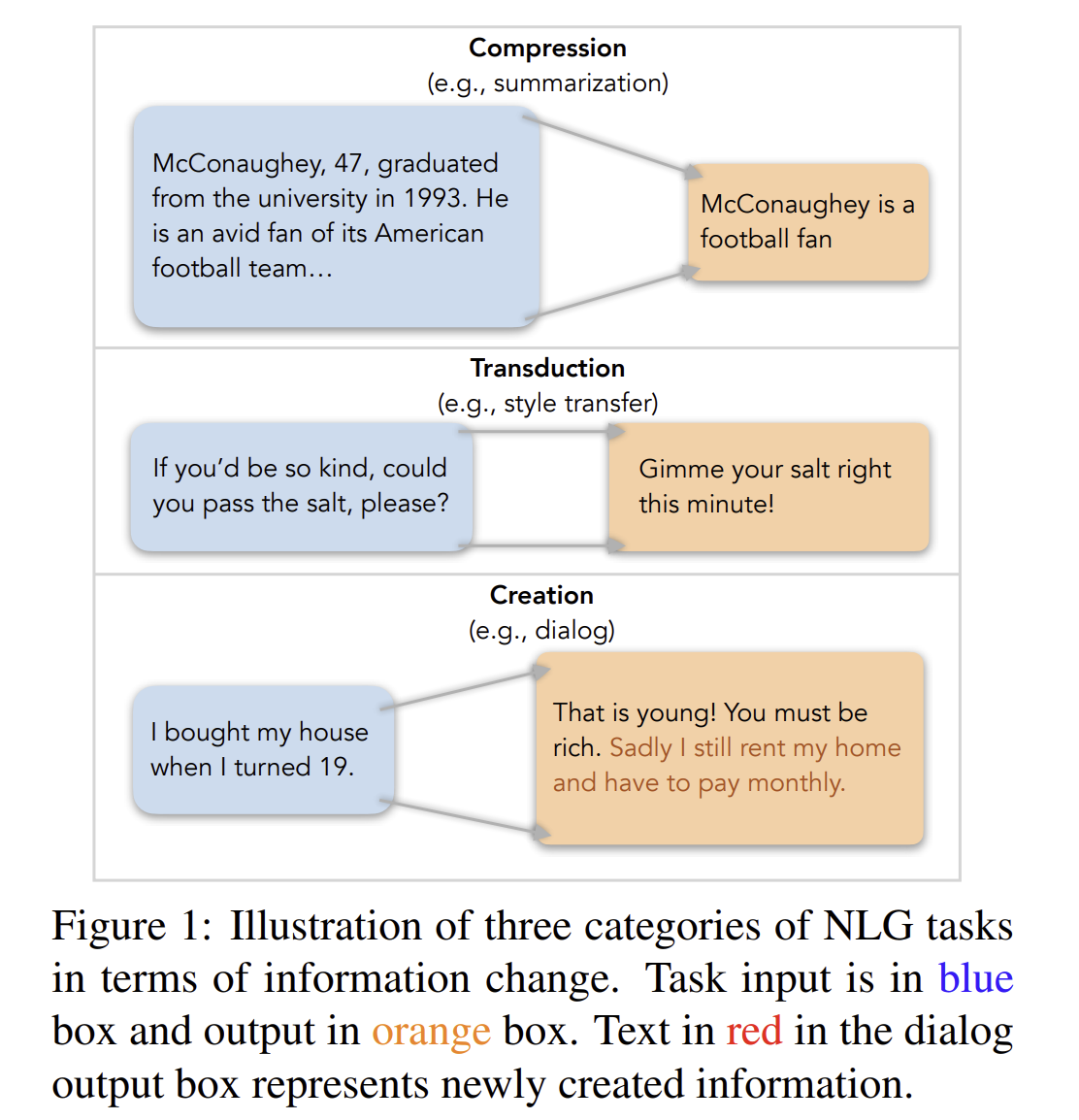
-
NLG task를 3가지로 분류함.
(1) Compression (e.g. summarization)
: Input에서 가장 중요한 정보를 간결하게 서술해야 함. 즉, Output은 (1) Consistency (2) Relevance 해야 함.
(2) Transduction (e.g. text rewriting)
: Output이 Input 내용을 정확하게 보존해야 함. 즉, Preservation는 Input과 Output 간의 Information alignment를 측정함.
(3) Creation (e.g. dialog)
: Input의 Top에 New information이 추가된 Output을 생성함. Ouput, Input, 외부 소스 간의 Information alignment은 본질적으로 어떻게 생성된 Content가 문맥과 잘 어울리는지, Content가 외부 소스에 grounding하여 얼마나 의미 있는 내용인지에 대해 평가함. -
예측을 위해서 Information alignment(생성된 Output의 정보가 Input의 정보와 어떻게 overlap하는지에 대해 평가)을 근사화하는 Self-supervised models을 이용함.
StoryER 논문 링크
- StoryER의 Output
(1) 사람들의 선호도와 일치하는 Prefrence Score
(2) 구체적인 Rating과 이에 상응하는 신뢰도
(3) 다양한 측면(ex. 오프닝, 캐릭터 형성 등)에 대한 comments
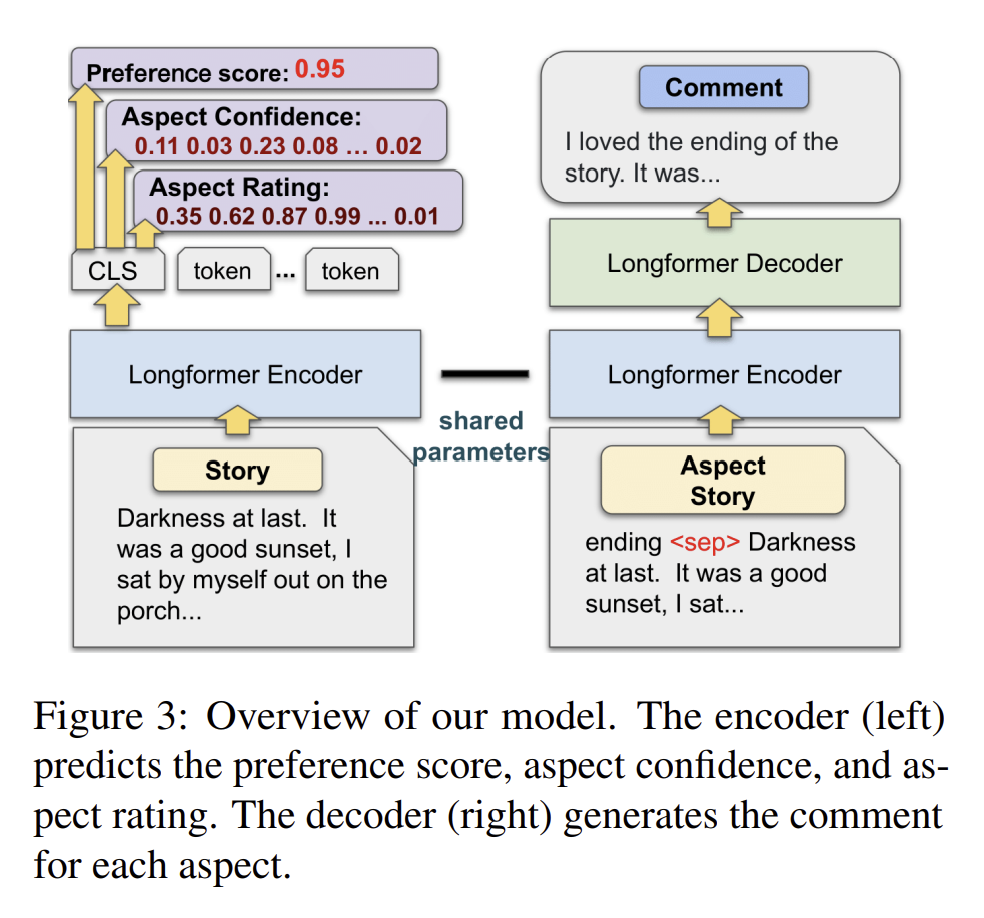
-
Longformer-Encoder-Decoder(LED)를 파인튜닝함.
-
3가지의 sub-task로 이루어짐.
(1) Preference Score Prediction (Ranking)
: 2가지 스토리에 대해 Ranking하여 평가 점수를 예측함.
(2) Aspect Confidence and Rating Prediction (Rating)
: 각 항목에 대해 Multi-class cross-entropy loss for the aspect confidence와 binary cross-entropy loss을 계산함. (이는 Encoder의 특성을 이용함.)
(3) Comment Generation (Reasoning)
: 주어진 항목과 스토리를 기반으로 comments를 생성함. (MLE 사용)◆ Encoder의 특성
Longer former encoder는 'input: 스토리' → '각 token의 context를 포함한 고차원 vector(즉, 스토리의 중요한 포인트를 가지고 있는 feature vector)'로 변환하는데, 이를 통해 Rating함.
UNIEVAL 논문 링크
-
Unified multi-dimensional evaluator
-
Boolean Question Answering (QA) task의 평가 프레임
-
T5를 Backbone model로 사용하여, Unspervised setting을 이용함.
BARTScore 논문 링크
- 생성된 스토리를 Pre-trained sequence-to-sequence models을 사용하여 모델링한 텍스트 생성 문제로 개념화함. (즉, 생성된 텍스트가 얼마나 잘 작성되었는지를 평가하는 것을 별도의 평가 문제로 보지 않고, 텍스트를 생성하는 과정의 일부로 봄. PLMs을 사용하기 때문에 가능.)
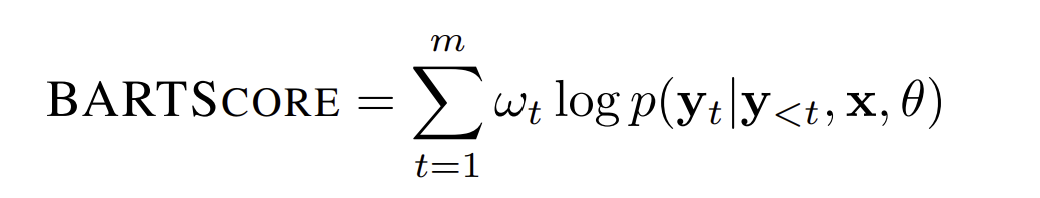
- BART가 생성한 이야기의 Conditional likelihood를 계산
"(...)four methods for using BARTSCORE based on different generation directions."
- Faithfulness: 원본 텍스트를 기반으로 가설이 생성될 가능성에 대해서 측정
- Precision: Gold reference를 기반으로 가설을 구성할 수 있고, precision에 집중된 시나리오에 대해 적합한지에 대해서 평가
- Recall: Gold reference가 얼마나 쉽게 가설에 의해 생성될 수 있는지에 대해 정량화
- F-score: Precision과 Recall의 산술 평균. Reference 텍스트와 Generated 텍스트 간의 Semantic overlap을 평가하는데 널리 사용됨.
T5Score 논문 링크
- Modern embedding-based metrics for evaluation of generated text는 2가지의 Paradigms로 나뉨.
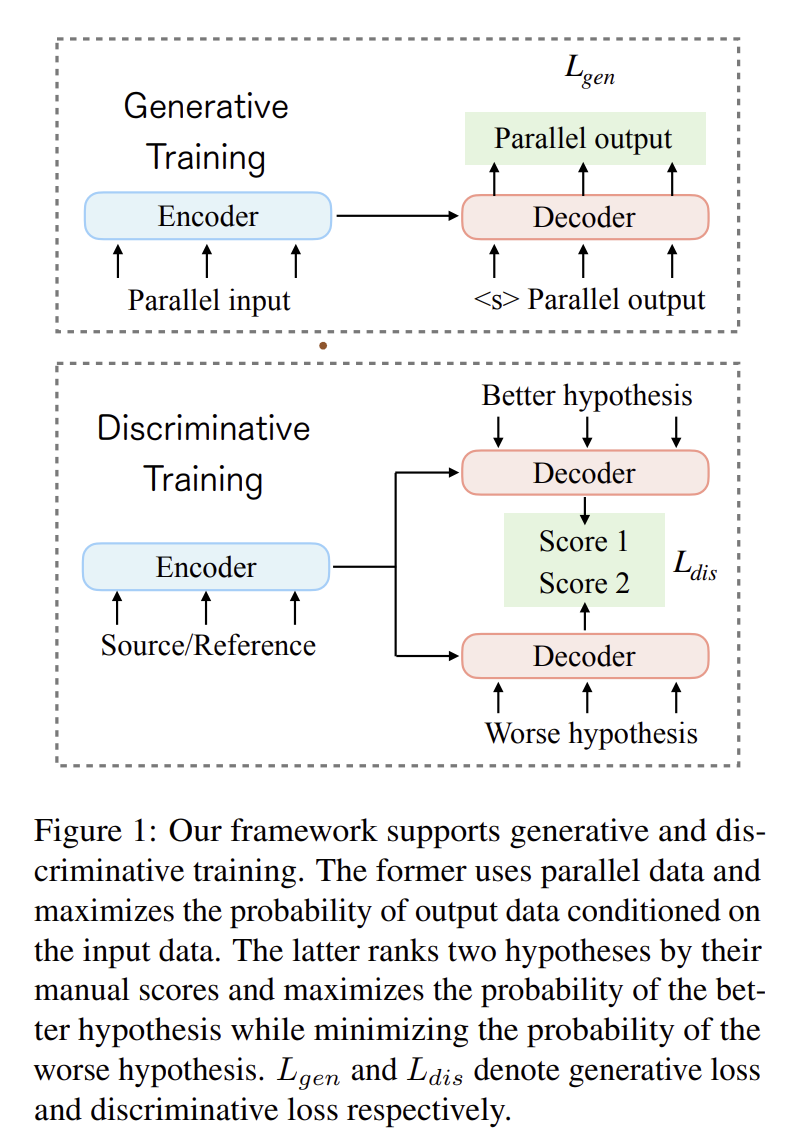
- Discriminative metrics
: supervised human annotations에 따라서 output의 높은 quality를 예측하기 위해 훈련됨.
‣ 장점: good OR bad output을 구분하는 문제에 대해서 최적화 가능- Generative metrics
: generative model의 가능성을 기반으로 텍스트를 평가하기 위해 훈련됨.
‣ 장점: 풍부한 raw 텍스트를 사용하여 generative 메트릭 훈련 가능😮 2가지 paradigms의 장점을 결합하여 supervised + unsupervised을 사용한 framework 제안
- Generative quality에 대해 인간이 판단할 수 있을 경우 Contrastive loss을 사용한 Discriminative + Standard negative log likelihood loss을 사용한 Generative을 모두 활용함
GPTScore (Generative Pre-Trained models to SCORE generated texts) 논문 링크
- Emergent abilities(e.g. zero-shot instruction, in-context learning, COT)를 활용하여 생성된 텍스트를 평가함.
👌 Emergent abilities의 공통점
annotation이 달린 예시가 적거나, 아예 없는 경우에도 사용자가 정의한 요구 사항을 처리할 수 있음
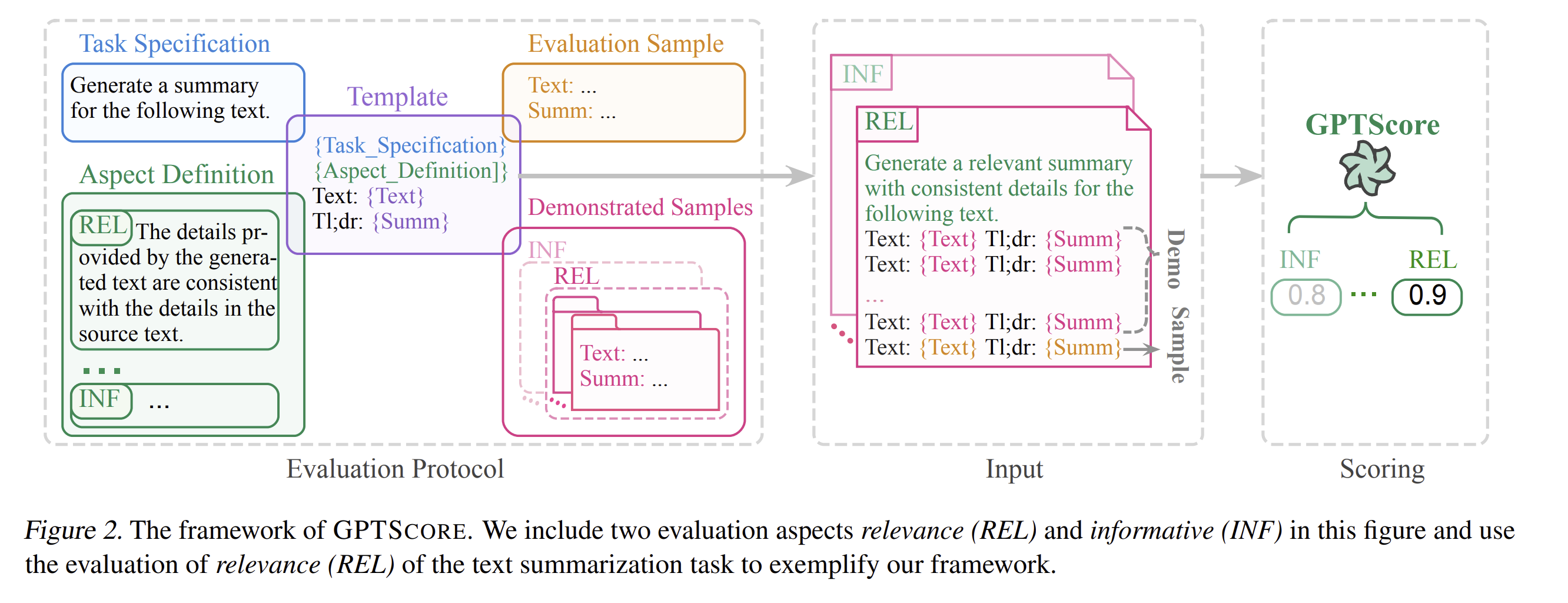
-
Evaluation protocol
(a) 일반적으로 텍스트가 생성되는 방법을 설명함. (e.g. 텍스트를 기반으로 인간에 대한 응답 생성)
(b) 바람직한 평가 측면의 세부 사항을 문서화하는 aspect 정의(e.g. 응답은 이해할 수 있게끔 직관적이어야 함)
(c) 평가 샘플이 model의 학습을 촉진할 수 있도록 적당한 예시 샘플과 함께 evaluation protocol을 제공함.
⇒ PLM을 사용하여 evaluation protocol을 기반으로 텍스트의 생성 가능성을 계산. -
Core idea of GPTSCORE
Generative pre-training model은 주어진 Instruction와 Context에 따라 높은 Qulity의 생성 텍스트에 대해 더 높은 확률로 할당이 가능함.
