가상 면접 사례로 배우는 대규모 시스템 설계 기초 (알렉스 쉬 저)를 읽고 정리합니다.

새해가 되면서 스터디를 진행했는데, 노션에만 열심히 적는게 아까워서 벨로그에도 올려봅니다👀
아니 근데 마크다운 양식인데도 복사 붙여넣기 했을 때 깨지는게 많아서 일일이 수정해야 하네요..? 처음부터 블로그에 쓸 걸 😇
🖥 단일 서버 시스템 구성
💡 웹, DB, 캐시 등이 모두 서버 한 대에서 실행된다면?
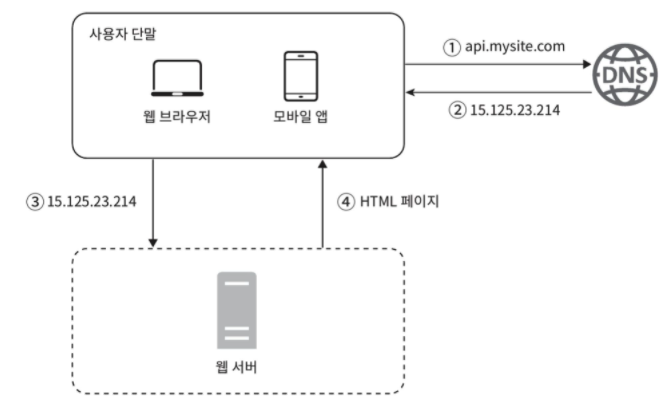
도메인 이름을 IP 주소로 변환하는 과정을 거쳐 사용자가 웹 사이트에 접속하고, 해당 IP 주소에서 HTTP 요청과 응답이 오고 간다.
🤔 사용자가 늘어나도 해당 구조를 그대로 유지하나?
💡 당근빠따 안되기 때문에 아래 행위 고려하기
데이터베이스 서버 분리
- 웹/모바일 트래픽 처리용 서버와 데이터베이스 서버를 분리해서 독립적으로 확장한다.
- 데이터베이스는 시스템에 따라 RDB 또는 NoSQL을 선택할 수 있다.
수직적 규모 확장 (= 스케일 업)
- 서버에 고사양 자원 (더 좋은 CPU, 더 많은 RAM, …)을 추가하는 행위
- 장점 : 트래픽 양이 적을 때 단순하니 좋은 선택
- 단점
1. 한계 존재 : 하나의 서버에 무한대의 자원을 추가할 수 없다 (당연함)
2. 장애 대응 : 장애 자동 복구 (failover)이나 다중화 방안 X (고가용성 X)
수평적 규모 확장 (= 스케일 아웃)
- 더 많은 서버를 추가해 성능을 개선하는 행위
- 대규모 애플리케이션에 적합
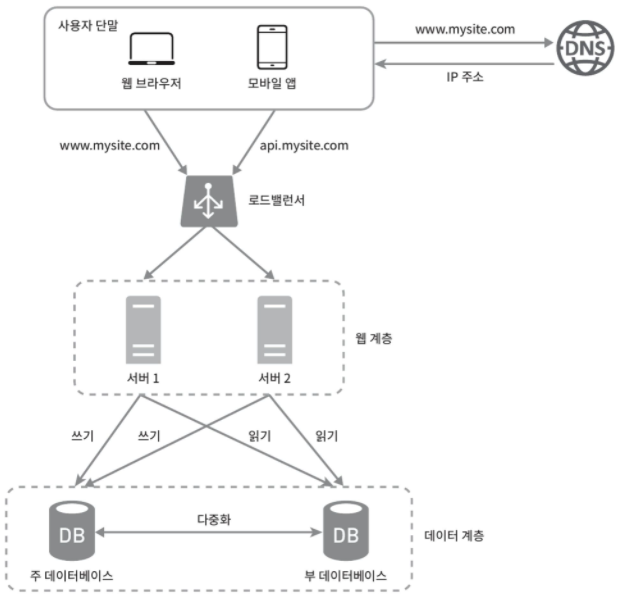
로드 밸런서
-
등장 배경
- 사용자가 웹 서버에 바로 연결되면 서버 상태에 서비스가 직접적인 영향을 받는다
- 사용자가 몰리면 웹 서버 응답 속도가 느려지거나, 접속이 어려워진다
👉 부하 분산기, 또는 로드 밸런서를 이용해 위 문제를 해결하고자 함
-
역할
- 부하 분산 집합에 속한 웹 서버들에게 트래픽 부하를 고르게 분산한다.
-
동작 방식
- 사용자는 웹 서버가 아닌 로드 밸런서의 공개 IP로 접속한다.
- 로드 밸런서는 요청을 사설 IP 주소를 이용해 웹 서버와 통신한다.
- 로드 밸런서는 부하 분산 집합에 존재하는 웹 서버들에게 요청을 분산하여 나눠준다.
-
웹 가용성 향상
- 서버 1이 다운되면 로드 밸런서는 서버 2에게 트래픽을 전송한다.
👉 웹 사이트 전체가 다운되는 일 방지 가능
- 유입 트래픽이 증가하면 웹 서버 계층에 더 많은 서버를 추가해서, 로드밸런서가 적절하게 서버로 트래픽을 나눠주게 만든다.
👉 많은 트래픽을 간단하게 관리할 수 있음
- 서버 1이 다운되면 로드 밸런서는 서버 2에게 트래픽을 전송한다.
데이터베이스 다중화
- master-slave 관계 설정
- master (주서버)
- 쓰기 연산 지원 (insert, update, delete). 데이터 원본 저장
- slave (부서버)
- 읽기 연산만 지원 (only read). 마스터의 데이터 사본을 전달받는다
- 보통 서비스는 읽기를 많이 하니까, 슬레이브 데이터베이스 수가 더 많은게 보편적
- master (주서버)
- 장점
- 성능 개선 : 데이터 변경 연산은 마스터로, 읽기 연산은 슬레이브로 분산되므로 병렬 처리 가능한 쿼리 수가 늘어난다.
- 안정성 : 데이터베이스 서버 일부에 장애가 발생하거나 파괴되어도 사본이 남아있으므로 데이터는 보존된다.
- 가용성 : 데이터베이스 서버 일부에 장애(이하생략) 다른 서버에 있는 데이터를 가져오면 되므로 서비스는 중단되지 않는다.
- 예시
- 부서버가 한대인데 다운 발생
- 읽기 연산이 일시적으로 주서버에 전달됨
- 새로운 부서버가 올라와 장애 서버 대체
- 부서버가 여러대인데 그 중 하나에 다운 발생
- 나머지 부서버들로 읽기 연산 분산
- 새로운 부서버가 올라와 장애 서버 대체
- 주서버가 다운
- 부서버 한대면 해당 서버가 주 서버를 대체하며, 읽기/쓰기 연산이 일시적으로 주 서버에서 처리
- 부서버 데이터가 최신 데이터가 아닌 경우 복구 스크립트를 활용
- 다중 마스터 구조, 원형 다중화 구조를 도입해 해결할 수도 있음
- 부서버가 한대인데 다운 발생
개선된 구조
⚡️ 난 응답 시간도 개선하고 싶어요!
💡 캐시와 CDN을 이용해 응답 시간 개선하기
캐시 : DB 부하를 줄여요~
- 의미
- 처리가 오래 걸리는 연산 결과 또는 자주 참조되는 데이터를 메모리에 두고, 이후 요청을 보다 빠르게 처리해주는 저장소
- 어플리케이션 성능은 데이터베이스 호출 수에 크게 좌우된다 (디스크까지 다이빙하기 힘드니까)
- 캐시 계층
- 데이터가 잠시 보관되는 곳으로 DB보다 훨씬 빠르다.
- 캐시 계층을 이용해 DB 부하를 줄이고, 캐시 계층 규모를 독립적으로 확장시킬 수 있다
- 캐시 주도 전략 : 캐시에 없으면 DB 조회하는 방식!
- 주의할 점
- 캐시는 데이터 갱신은 적지만, 참조는 자주 일어나는 데이터에 적절하다
- 휘발성 메모리를 사용하므로, 중요한 데이터는 지속적 저장소에 두어야 한다.
- 데이터가 계속 캐시에 남는 걸 막기 위해, 적절한 만료 기한을 두어야 한다.
- 단일 트랜잭션을 이용, 지속적 저장소의 데이터와 캐시에 있는 데이터의 일관성을 관리해야 한다.
- 단일 장애 지점(SPOF)이 되는 걸 막기 위해 캐시 서버를 분산시켜야 한다.
- 캐시 메모리를 과할당하여 데이터 방출(eviction) 현상을 방지한다.
- 캐시가 꽉 차는 경우를 대비하여 데이터 방출(eviction) 정책을 마련한다.
- LRU : 마지막으로 사용된 시점이 가장 오래된 친구부터 방출
- LFU : 사용된 빈도가 가장 낮은 친구부터 방출
- FIFO : 가장 먼저 캐시에 들어온 친구부터 방출
콘텐츠 전송 네트워크 (CDN) : 정적 컨텐츠는 웹 서버를 거치지 않아요~
- 의미
- 정적 콘텐츠 전송에 쓰이는 지리적으로 분산된 서버의 네트워크. 정적 파일을 캐싱한다.
- 요청 경로, 쿼리 스트링, 쿠키, 헤더 등을 이용해 HTML 페이지 캐시하는 방식
- 동작 방식
- 사용자가 웹 사이트에 방문하면, 해당 사용자에게 물리적으로 제일 가까운 CDN 서버가 정적 컨텐츠를 전달해준다.
- 만약 컨텐츠가 CDN에 없다면 웹 서버에서 가져온다. 캐시를 활용하는거 맞아요.
- 고려할 점
- 서드파티 제공자가 운영하므로 비용에 주의한다.
- 시간에 민감한 콘텐츠의 만료 시한에 주의한다.
- CDN이 죽었을 경우 어떻게 처리할건지 주의한다.
- 아직 만료되지 않은 콘텐츠에 문제가 생긴 경우, 콘텐츠 무효화 처리가 필요하다.
🤖 웹 계층의 수평적 확장
💡 사용자 세션 정보와 같은 상태 정보를 웹 계층에서 제거해 웹 수평적 확장을 구현한다.
무상태 웹 계층 : 상태 정보를 DB에 저장해요~
- 상태 정보 의존적인 아키텍처
- 상태를 서버에 저장하기 때문에, 동일 클라이언트의 요청은 항상 동일 서버로 전송되어야 한다.
- 로드밸런서가 고정 세션 기능을 제공해주지만, 부담이 크다.
- 로드밸런서 뒷단에 서버의 추가와 제거가 어려워지고, 장애 대응도 빡세다.
- 무상태 아키텍처
- 클라 요청은 어떤 웹 서버로든 전송될 수 있다.
- 웹 서버는 상태 정보가 필요하면, 웹 서버와 물리적으로 분리된 상태 저장소에서 정보를 가져온다.
- 따라서 구조가 단순하고, 안정적이고, 확장에 유연해진다.
💽 가용성을 높이자
💡 높은 가용성을 위해 데이터 센터를 여러개 지원하는게 필수적!
데이터 센터
- 지리적 라우팅
- 장애가 없는 상황에서 사용자가 가장 가까운 데이터 센터로 안내되는 것
- geoDNS : 사용자 위치에 따라 도메인 이름을 어떤 IP 주소로 변환할지 결정해주는 DNS 서비스
- 데이터 센터 중 하나에 장애 발생하면, 가까운 데이터 센터로 트래픽이 전송된다.
- 장애가 없는 상황에서 사용자가 가장 가까운 데이터 센터로 안내되는 것
- 다중 데이터 센터 아키텍처 구현을 위한 기술 난제
- 트래픽 우회 : 올바른 데이터 센터로 트래픽 보내는 방법
- 데이터 동기화 : 데이터센터마다 다른 데이터베이스를 쓴다면, 페일오버 전략이 필요하다.
- 보통 데이터를 여러 데이터 센터에 걸쳐 다중화한다.
- 테스트와 배포 : 웹 사이트와 어플리케이션을 여러 위치에서 테스트해봐야 한다. 배포 자동화를 통해 모든 데이터 센터에 동일한 서비스를 설치하는 걸 도울 수 있다.
⛑ 더 큰 시스템을 위하여
💡 시스템 컴포넌트를 분리해 각각 독립적으로 확장될 수 있는 구조를 만들어야 한다.
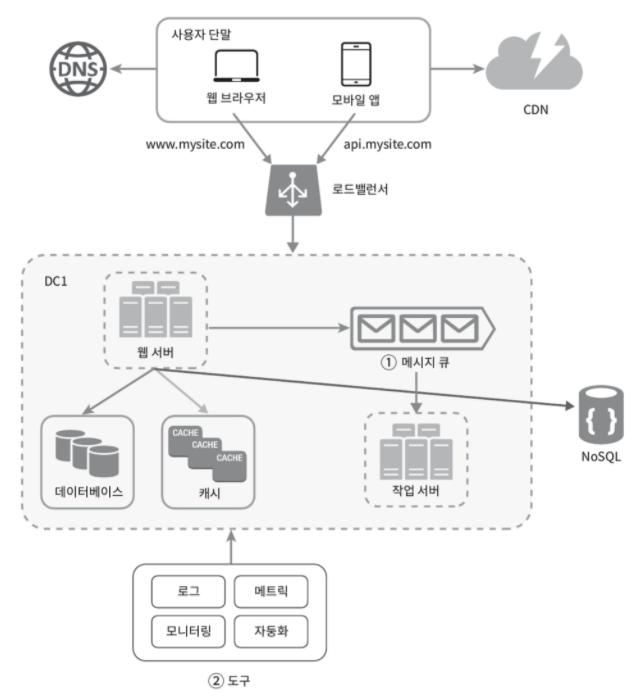
메시지 큐
- 의미
- 데이터 무손실을 보장하는 비동기 통신을 지원하는 컴포넌트. 보통 메시지 버퍼 역할
- 뭔 🐕소리야? : 한번 메시지 큐에 저장되면 데이터를 꺼내 갈 때까지 안전히 보관된다는 소리
- 메시지 큐 기본 아키텍처
- 입력 서비스 ( = 생산자 또는 발행자)가 메시지를 만들어 메시지 큐에 발행한다.
- 큐에 연결된 서비스 혹은 서버 ( = 소비자 도는 구독자)가 메시지를 받아, 역할을 수행한다.
- 장점
- 서비스, 또는 서버 간 결합이 느슨해짐 → 규모 확장성이 보장되어 안정적
- 생산자는 소비자가 죽어도 메시지를 발행할 수 있고, 소비자는 생산자가 죽어도 메시지를 수신할 수 있다.
- 큐가 크면 소비자를 추가하고, 큐가 비어있으면 소비자를 줄이는 방식!
- 서비스, 또는 서버 간 결합이 느슨해짐 → 규모 확장성이 보장되어 안정적
로그, 메트릭, 자동화
- 로그
- 시스템 오류와 문제를 찾기 위한 에러 로그 모니터링
- 로그를 단일 서비스로 모아주는 서비스를 이용하면 다중 서버 환경에서 편리하다
- 메트릭
- 사업 현황에 대한 정보와 시스템 현재 상태에 대한 정보를 얻을 수 있다.
- 유용한 메트릭 친구들
- 호스트 단위 메트릭 : CPU, memory, disk I/O에 관한 친구들
- 종합 메트릭 : DB 계층 성능, 캐시 계층 성능에 관한 친구들
- 핵심 비즈니스 메트릭 : 일별 능동 사용자, 수익, 재방문에 관한 친구들
- 자동화
- 시스템이 크고 복잡해지면 생산성을 높이기 위한 자동화 시스템을 도입하자.
- CI, 빌드, 테스트, 배포 등…
개선된 구조 2
📈 DB 규모를 확장하자
💡 저장할 데이터가 많아졌어요 뭘 해야 돼요 DB를 확장해야 돼요
수직적 확장
- 의미
- 기존 서버에 더 많은 고성능 자원 증설해주기
- 성능을 아주~~ 좋게 만들어서 많은 데이터를 처리할 수 있게 하는 방법
- 단점
- 증설 한계가 있어용
- SPOF 위험성
- 서버 성능이 좋아질 수록 비용이 따블로 든다
수평적 확장
- 의미
- 더 많은 서버를 추가하기
- 샤딩 : 데이터베이스를 샤드라는 작은 단위로 분할하는 것. 모든 샤드는 같은 스키마를 공유하지만, 보관하는 데이터에는 중복이 없다.
- 고려할 점
- 샤딩 키(=파티션 키)를 정해야 해요 : 데이터가 어떻게 분산될지 정하는 하나 이상의 컬럼
- 샤딩 키를 이용해 올바른 DB에 질의를 보낼 수 있다.
- 효율적인 처리를 위해 데이터를 고르게 분할 할 수 있는 샤딩 키를 지정한다.
- 샤딩을 도입하면 시스템이 이렇게 복잡해져요
데이터의 재샤딩- 데이터가 너무 많아졌을 때, 샤드간 데이터 분포가 균등하지 않아 샤드 소진이 발생할 때 재 샤딩이 필요하다.
- 안정 해시 기법으로 해결 가능!
유명인사 (= 핫스팟 키)- 특정 샤드에 질의가 집중되어 서버 과부하 걸리는 문제
- 자주 쓰이는 데이터 (유명인사)가 모두 한 샤드에 저장될 경우, 해당 유명인사 각각에 샤드를 할당해야 한다.
조인과 비정규화- 하나의 데이터베이스를 여러 샤드 서버로 나누었으니, 여러 샤드에 걸친 데이터를 조인하기 어려워진다.
- 해결하기 위해 데이터베이스를 비정규화하여 하나의 테이블에서 질의를 수행한다.
- 샤딩 키(=파티션 키)를 정해야 해요 : 데이터가 어떻게 분산될지 정하는 하나 이상의 컬럼

호그와트 장학생