SQL
⬇️
관계대수 연산의 조합
즉, 여러가지 연산이 들어가있을 거임.
SELECT, PROJECT, JOIN, 등 여러가지 형태의 연산자들의 조합을 나올 것이고
이걸 실제 저장파일에 대해서 실행을 할거임.
최적화의 필요 이유:
같은 SELECT 연산 하나라도 하나의 파일에 SELECT를 처리하는 방법이 여러가지 있음.
처리 방법마다 성능, 처리 시간이 다 다름.
저장되어 있는 파일의 저장 구조에 따라 시간이 다름.
따라서 모두 따져보고 best를 골라야함.
따라서, 각 연산자별 처리 방법인 알고리즘에 대해서 소개를 할거임.
<17.3.1 SELECT 연산의 구현>
학생 테이블이
물리적 데이터에 파일로 저장되어 있음.
순차 파일 / 해시파일 등으로 저장되어 있을 수 있음. 그리고 여러가지 인덱스가 있을 수 잇음.
설계자들의 설계 구조에 따라서 달라짐.
나이가 20세인 학생 검색/SELECT
(SELECT 어떤 조건들을 만족하는 투플을 골라내는 연산)
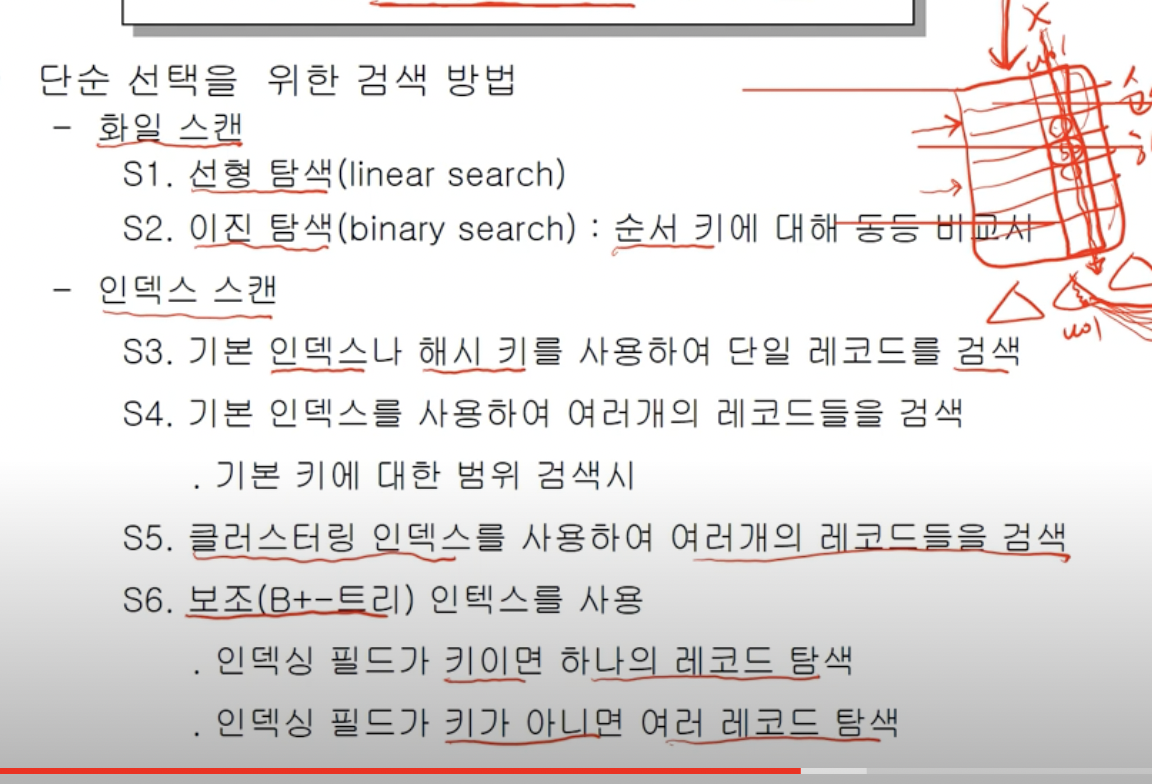
SELECT 연산 처리 방법1)
테이블을 파일로 저장할 때 여러가지 저장 경우으 ㅣ수가 있음.
학번/이름/학과/나이에 대해 정렬 가능.
방법1) 선형탐색
: 앞에서부터 차례대로 스캔하는 것.
제일 간단한 방법임.
If 파일이 나이에 대해서 정렬된 경우, 앞에서부터 안 찾고 이진 탐색하는게 더 나을것임.
선형 탐색은 어떤 경우에도 항상 적용 가능.
방법2) 이진 탐색
: 가운데부터 비교 그리고 탐색 범위 반씩 줄임. 정렬되어 있다는 가정.)
이진 탐색은 정렬기준(순서키)에 대해서 탐색하느 경우에만 선택 가능.
방법3) 나이에 대한 색인이 있는 경우
Index를 통해서 검색.
방법4) 기본 index
(인덱스는 기본 index, hash index 등이 이씀…)
기본 key가 나이일 때 사용 가능.
기본키에 대해서 검색하면 기본 Index를 사용해서 검색.
방법4) clustering index
클러스터링 인덱스가 있으면 20세들이 있는 블럭의 주소 한개가 나옴.
그러면 20세인 사람들이 모여있는(clustering) 것을 볼 수 있음.
방법5) 보조 index
주소가 여러개 나오면, 보조 index에 대해서 기본 key가 아니면 그 여러가지 주소를 이용해서 탐색 가능.
…
SELECT연산인 경우,
SELECT 연산 기본 조건이 기본키이냐 아니냐/
파일이 찾고자 하는 조건에 대해서 정렬되어 있느냐 아니냐/
Index가 만들어져있느냐 아니냐/
등의 상황에 맞춰서 SELECT를 처리할 수 있는 방법이 여러가지 있음.
해당 예제는 S1, S2, S5, S6 적용 가능.
선형 탐색은 언제든 적용 가능.
즉. 하나의 SELECT연산 처리 경우의수가 여러가지 있다!
<17.3.2 JOIN 연산의 구현>
학생 테이블 존재. 학과 테이블 존재.
학생과 학과 JOIN 연산 방법은?
방법1) 중첩 루프 조인
For문 처럼 튜플 하나에 대해서 학과 튜플을 모두 반복해서 매칭이 되는지를 일일이 비교.
그리고 다음 투플에 대해서 반복.
방법2) 단일 루프 조인
학과에 대한 색인이 있을 경우, 중첩루프를 사용하지 않고, 학생을 조건으로 색인을 검색해서 해당 색인에 해당되는 학과가 어딨는지, 즉, 레코드를 조회.
색인이 있는 경우에만 사용 가능.
방법3) 정렬-합병 조인
학생 테이블을 조인 조건으로 다시 테이블을 정렬함.
학과 테이블을 조인의 조건에 해당되는 열로 정렬함.
그러면 양쪽을 쭉 스캔하며서 merge하듯이 할 수 있음.
근데 정렬이 되어있어야함. 그래서 일단 sort 한 후에 merge 할 수 있음.
방법4) 해시조인
학생 테이블을 해시 테이블로 바꿈.
학과 테이블도 조인 조건에 해당되는 열에 대해서 해싱을 함.
학생 테이블 해싱값 0인 것은 학과 테이블 해싱값 0인 것과 조인.
얘는 중첩 루프 조인보다 훨씬 간단함.
하나의 연산이 처리될 수 있는지가 뭑 ㅏ있고 그들 사이의 성능이 어떻게 되는지를 이해해야 최종적으로 질의의 최적화 결과를 보고
현재 구조에서는 A구조가 최적이니 더 좋은 방법이 나오기 위해서는 데이터베이스 테이블 저장하는 구조나 인덱스 매커니즘을 이렇게 바꿔야겠다는 근거가 되는 것임.
따라서 여러가지 연산의 경우의 수와 비용에 대한 이해가 필요함
