자료구조가 뭐지?
자료구조란 데이터에 편리하게 접근하고 변경하기 위해서 데이터를 저장하거나 조직하는 방법을 의미한다.
웹에서도 결국 데이터를 가져오고 원하는대로 가공하여 보여주는 것이 목적이라는 것을 생각하면 웹기술의 근간이라고도 볼 수 있는 것이다.
자료구조는 목적에 따라 맞는 형식이 다르다. 모든 목적에 맞는 자료구조는 없다.
따라서 내가 이 데이터를 가지고 무얼 하고 싶은지를 잘 파악하고 그것에 맞는 자료구조를 택하는 것이 매우 중요하다.
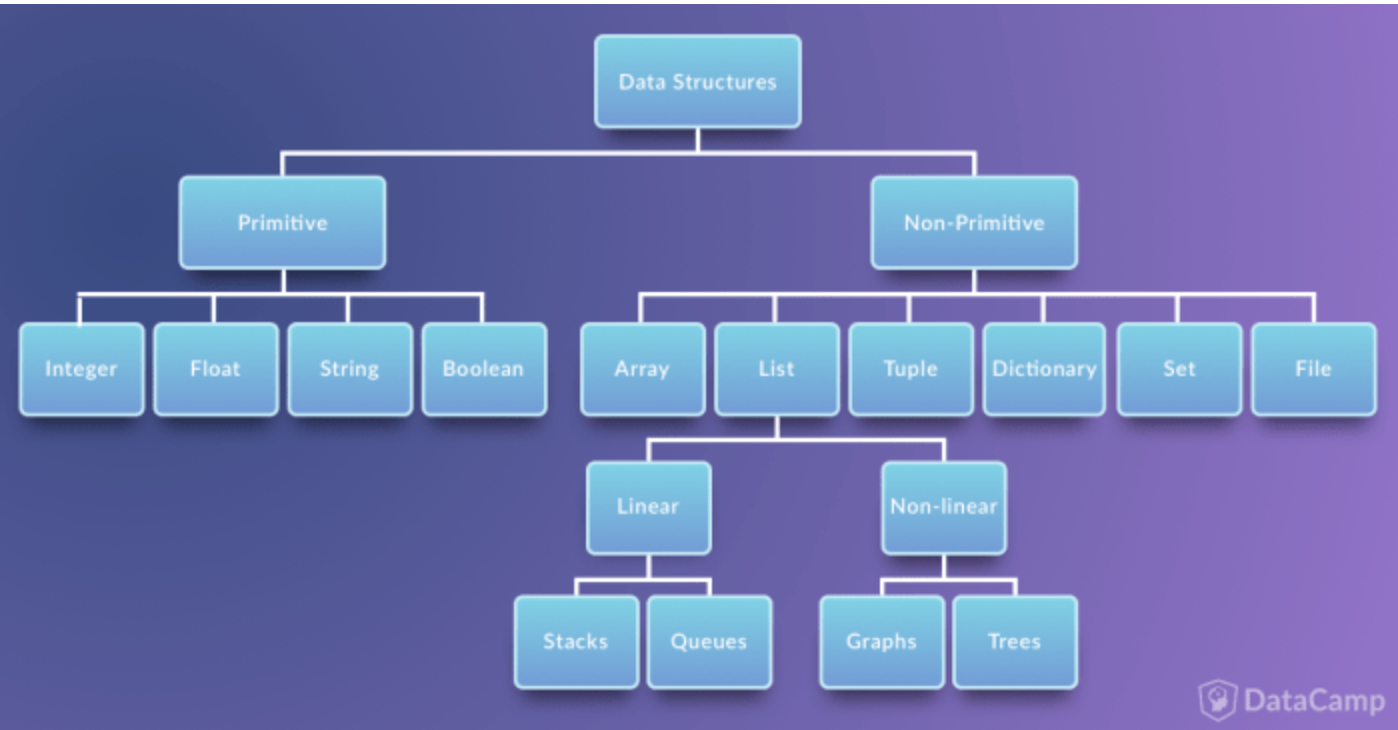
위 그림에서
Primitive Data Structure는 프로그래밍에서 사용되는 기본 데이터 타입을 의미한다. Javascript는 변수선언 시 type을 엄격하게 따지지 않는 언어라 잊고 있었는데 C# 같은 경우 변수 선언시 변수의 타입도 명확하게 지정해줘야 했었다.
Non-Primtive Data Sturcture는 primitive type과 달리 단순하게 데이터를 저장하는 구조가 아니라 여러 데이터를 목적에 맞게 효과적으로 저장하는 자료 구조이다. 이 중에서도 list는 다시 두 타입으로 나눠지는데 Linear Data Structure에는 저장되는 자료의 전후관계가 1:1인 stacks, queues 등이 있고 Non-Linear Data Structure에는 데이터 항목 사이의 관계가 1:n 또는 n:m인 trees, graphs 등이 있다.
다 어디서 조각조각 주워듣기는 했었는데 체계적으로 정리해보는 건 처음이다.
Array
가장 기초적이고 단순하면서도 가장 자주 사용되는 자료구조이다.
Array의 특징
- 가장 큰 특징은 순차적(ordered)으로 데이터를 저장한다는 점이다. 주로 서로 연결된 데이터들을 순차적으로 저장할때 사용한다. 혹은 순서가 상관 없더라도 서로 연결된 데이터들을 저장할때 많이 사용한다. 이 데이터들은 메모리상에서 실제 바로 옆에 위치한다.
- 자료는 넣는 순서대로 저장된다. 즉, 늦게 들어가면 꼬리에 달라붙는다.
- 수정 가능하다.
- 중복값도 가능하다.
- 순서가 있으므로 index 지정이 가능하다. index는 0부터 시작한다.
- Array의 요소가 array가 되는 multi-dimentional array가 가능하다.
Array의 단점
- 메모리가 실질적으로 순서대로 되어있기 때문에 중간에서 한 요소를 삽입하거나 삭제하면 삭제된 요소로부터 뒤에 위치한 모든 요소들을 각각 이동시켜주어야 한다. 이는 자료를 처리하는 속도에 영향을 줄 수 있다.
- 배열은 메모리가 순차적이어야 하다보니 처음 생성시 어느정도 메모리를 미리 할당한다(pre-allocation).그러나 처음에 잡아놓은 메모리 이상으로 요소들이 많아지면 메모리를 더 할당해야 할 필요가 있다. 이를 resizing이라 하는데 이 경우 새롭게 할당한 배열에 기존 배열을 복사하고 추가용량에 해당하는 배열을 뒤에 붙여넣는 식으로 진행되는데 상대적으로 시간이 오래걸리는 편이다. 따라서 데이터의 사이즈가 급변하는 경우에는 적절치 않은 자료구조임을 알 수 있다.
그럼 언제 배열을 쓰는게 적절할까?
- 순차열적인 데이터를 저장할때
- 어떤 특정 요소를 빠르게 읽어야 할때 (indexing)
- 데이터의 사이즈가 급변하게 자주 변하지 않을때
- 요소를 자주 추가, 삭제해야 하지 않을때
Set
Set은 또 뭔가요?
Set는 array나 list 처럼 순열 자료구조이다. 그러나 순서의 개념이 존재하지 않는다.
Set의 특징
- 삽입 순서대로 저장되지 않아서 특정한 순서를 기대할 수 없다.
- 수정 가능하다.
- 동일한 값이 여러번 삽입 시 한번만 저장된다. 중복저장이 불가능하다.
- 빠른 검색이 필요할때 주로 쓰인다.
Set의 구조

Set에서 요소들이 저장될 때의 순서는,
- 저장할 요소의 값의 해쉬값을 구한다.
- 해쉬값에 해당하는 공간(bucket)에 값을 저장한다.
bucket에 저장하기 때문에 순서가 없고 값이 동일할 경우 해쉬값도 같기 때문에 중복 저장이 안 된다.
해쉬값을 기반으로 저장하기 때문에 특정 값을 포함하고 있는지를 확인하는 look up이 매우 빠르다. Set의 총 길이와 관계 없이 해쉬값 계산 후 해당 bucket을 확인하면 되기 때문이다.
언제쓸거야 Set?
- 중복된 값을 골라내야 할때
- 빠른 look up을 해야 할때
- 순서는 상관 없을때
