[CloudClub]AWS Glue
1. AWS Glue란? :
-
데이터 분석에서 ETL이 가장 많은 시간을 소요(약 70%), 사용되는 데이터와 원본 데이터 간에 갭 존재 -> 적절한 ETL Transformation필요 : AWS Lambda, AWS Glue, Amazon EMR 제공
1) AWS Lambda: 트리거 기반의 서버리스 코드 실행 엔진 / 실시간 데이터 처리
2) AWS Glue: 이벤트 기반의 서버리스 ETL 엔진 / 대량의 데이터, Spark 사용
3) Amazon EMR: Spark 및 Hive가 실행되는 하둡 / 코드기반의 환경 -
그 중 AWS Glue는 고객이 분석을 위해 손쉽게 데이터를 준비하고 로드할 수 있게 지원하는 완전관리형 ETL(추출, 변환 및 로드) 서비스
-
간편하고 유연하며 비용 효율적인, 완전 관리형, 서버리스, ETL 서비스
-
개발자 친화적(툴보다는 메뉴얼 코드 제공/코드에 기반), Apache Spark 환경, Python과 Scala코드 지원
-
AWS의 다양한 데이터 스토어를 소스로 활용 (Aurora, RDS, S3, Redshift, DynamoDB) -> 다양한 데이터 작업에 편리
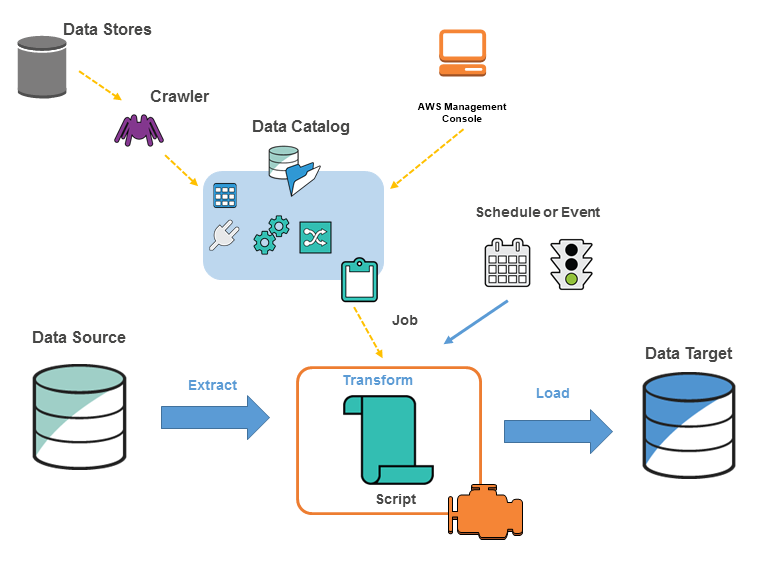
2. AWS Glue 구성 요소:
1) 데이터 카탈로그:
- 데이터에 대한 하나의 뷰를 제공 / 데이터 스토어에 어떤 데이터가 있는지
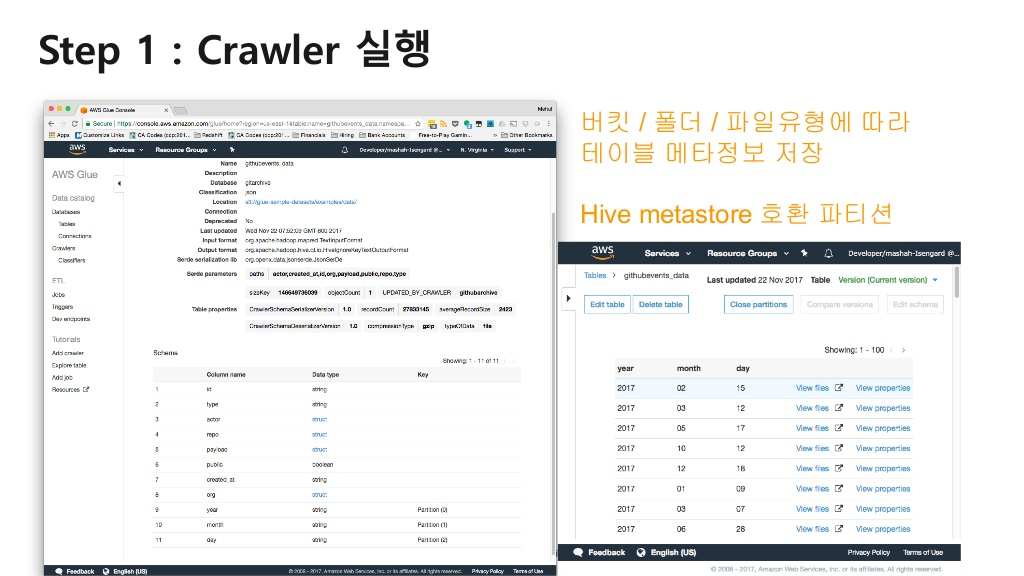
- Apache Hive Metastore와 호환가능, AWS 서비스들과 통합, 자동 크 롤러 기능(원하는 데이터 소스를 지정하여 샘플 데이터를 통해 스키마를 생성)
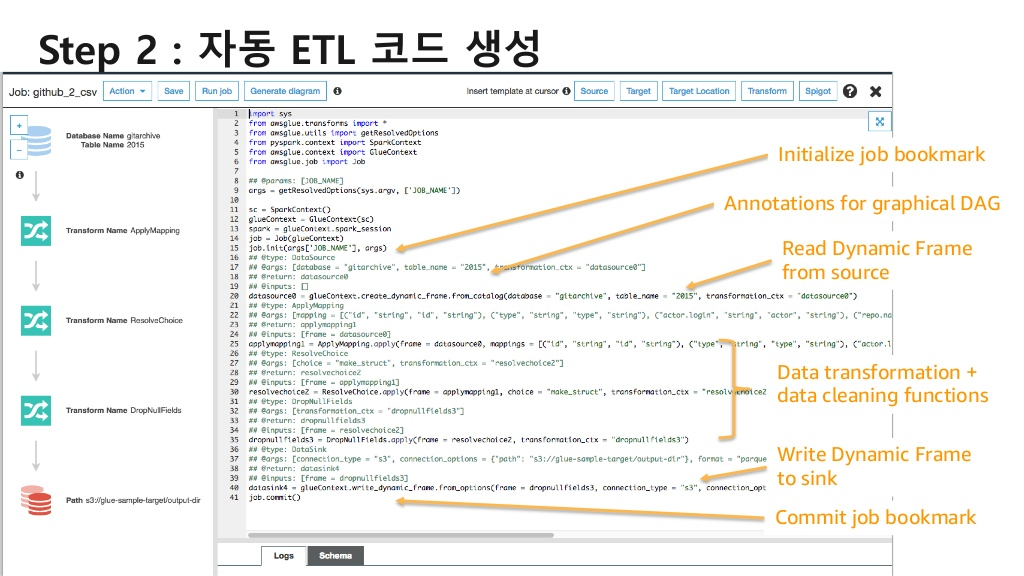
2) Job 생성: 자동으로 ETL 코드를 생성, Python과 Apache Spark기반, 편집, 디버깅, 공유 가능
3) Job 실행: 서버리스 기반으로 실행, 유연한 스케줄링, 모니터링과 경고 옵션
3. 데이터 카탈로그:
- Data Source: S3, JDBC호환 데이터베이스, DynamoDB
- 크롤러는 자동적으로 데이터 스키마를 찾아서 저장
- Apache Hive Metastore와 호환
- 데이터의 검색과 ETL 작업을 가능
- 테이블 스키마 정보와 컬럼 레벨 통계 정보를 포함
- 데이터 카탈로그는 매뉴얼하게, DDL문을 통해서 등으로 생성 가능
ex)
- 테이블 상세 정보 포함
- 자동적으로 파티션 구조 파악
- 스키마 변경 탐지 및 버전 관리
- 빠르게 필요한 데이터에 대한 검색
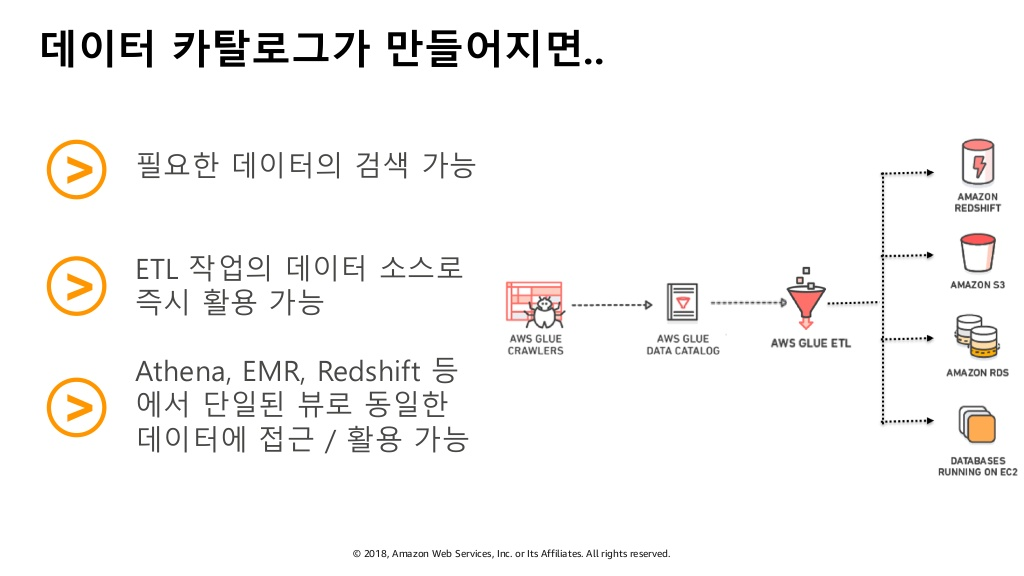
4. ETL서비스
- 서버리스 데이터 변환작업
- Apache Spark 기반
- 클릭 몇번으로 생성되는 ETL 코드
- 수정/추가가 가능한 PySpark와 Scala코드
- 반복 일정과 이벤트에 따른 Job 스케줄링
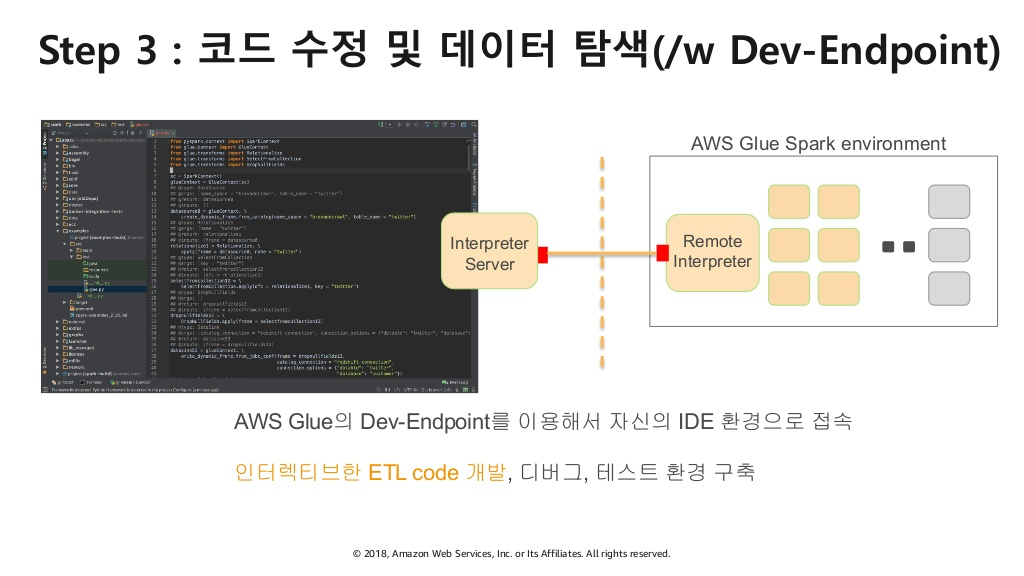
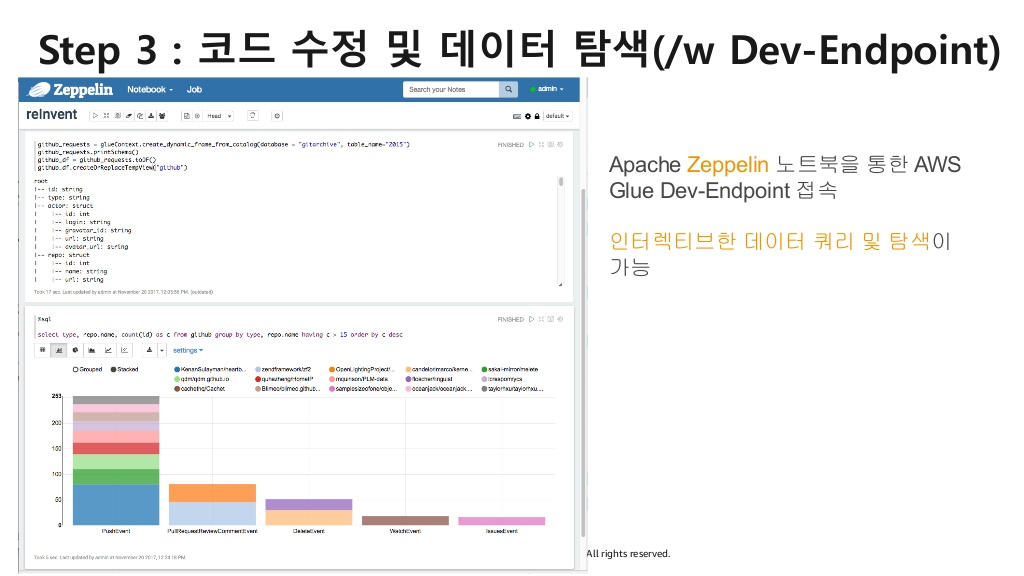
- Zeppelin, PyCharm등 익숙한 환경에서 수정, 디버그, 테스트가 가능하도록 Dev Endpoint 제공
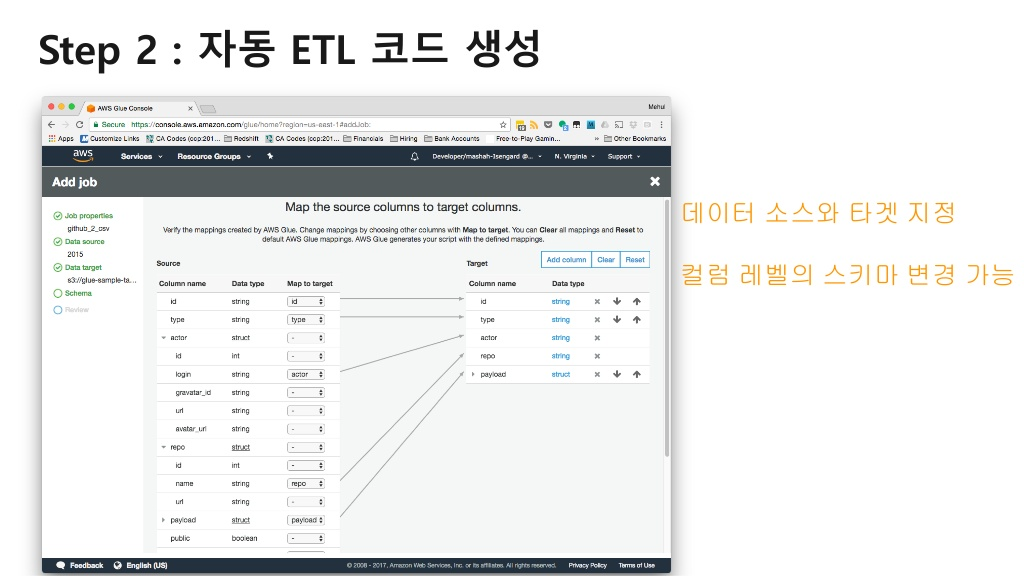
1) Job 생성 - 콘솔에서 코드 생성
2) Job 북마크 - 북마크 기능을 통해 지속적으로 추가되는 데이터에 대한 중복 작업 관리 가능 / Enable, Disable, Pause 등의 옵션을 사용해서 증분된 데이터 처리 가능
3) Job 스케줄링과 모니터링 - 이벤트 기반 Job을 실행 가능하며, 여러 Job 사이에 의존성 설정 가능
4) Job 실행(서버리스) - Job 실행하기 위해서 자동적으로 인프라를 생성하고 사용한만큼만 과금
5. ETL 주요 단계
1) 데이터 소스에 Crawler를 통해 데이터 카탈로그 생성
2) 컬럼 단위의 맵핑을 통해 자동 코드 생성
3) 편리한 환경에서 자유롭게 코드 수정 및 테스트
4) 실제 운영 환경에서 Job스케줄링 및 실행

6. AWS Glue 활용 패턴
1. 데이터 웨어하우스의 로그데이터 분석
2. 다양한 데이터 스토어에 대한 통합된 뷰
3. S3 데이터 레이크에 대한 쿼리 수행
4. 이벤트 기반 ETL 파이프라인
