5/31 ~ 6/13
트랜잭션, 성능 개선
Github
1-2 시스템 요구사항
지난번에 음식 배달 플랫폼의 주문 플로우를 비슷하게 구현하였습니다.
필수 요구사항
가게에서 가게의 주문 확인의 수정을 원합니다. 내용은 다음과 같습니다.
1) 가게에서 주문을 확인할 때 한번에 너무 많은 페이지가 보입니다. (페이징 구현)
2) 주문 월간, 주간, 일자별로 데이터를 확인할 수 있었으면 좋겠습니다. (주문 일자별 확인)
상세 요구사항
해당 기능을 수정하면서 성능 상 어떤 문제가 있는지 파악하고 개선해주세요.
기존에 작업했던 delivery-server에서 작업을 진행해주세요.
선택 요구사항
트랜잭션이란 무엇인가에 대해 고민해보시고 결제 부분까지 완성해보세요.
외부 결제 API와 연결하지 않도록 합니다.
제출 결과물
1) 코드를 작성한 GitHub Repository 주소
2) 성능 개선 경험을 적은 발표 자료
3) 트랜잭션에 대한 발표자료 (선택사항)
Hint!
실행 계획, 인덱스, 트랜잭션(선택)
주의사항!
요구사항에 적히지 않은 문제에 대해서는 스스로 정의하고 분석을 진행해주세요.
해야할 일
백만 개의 주문 데이터 생성
가게 주문 확인 페이징 구현
주문 일자별 확인
트랜잭션 스크립트 패턴을 도메인 모델 패턴으로 리팩토링
결제 기능 구현
주문 과정에서의 예외 처리
기본적인 REST API 규칙이나 등등.. 도 빼먹지말고 생각하기
백만 개의 주문 데이터 생성
1. 애플리케이션 레벨에서 배치 처리
유지보수와 유연성
데이터베이스에 종속적이지 않은 솔루션
2. 데이터베이스 내부에서 SQL PROCEDURE 사용
성능, 리소스 절약
데이터베이스에 종속적인 솔루션
이전에 진행했던 NotProd 파일에서 데이터를 추가하는 방식 대신, 더 빠르고 사용 경험이 없었기 때문에 SQL PROCEDURE를 사용했고, 총 3007500개의 order 데이터를 삽입했다.
DELIMITER //
CREATE PROCEDURE InsertOrderData()
BEGIN
DECLARE start_date DATE DEFAULT '1997-01-01';
DECLARE day_count INT DEFAULT 0;
DECLARE order_count INT DEFAULT 0;
DECLARE contact_num BIGINT DEFAULT 1000000000;
DECLARE total_days INT DEFAULT DATEDIFF(NOW(), start_date);
WHILE day_count <= total_days DO
SET order_count = 0;
WHILE order_count < 100 DO
-- 레스토랑 1의 주문 생성
INSERT INTO `orders` (restaurant_id, contact, address, status, created_at)
VALUES (1, contact_num + day_count * 100 + order_count,
CONCAT('엔터팰리스', order_count + 1, '차'),
'ACCEPTED', DATE_ADD(start_date, INTERVAL day_count DAY));
INSERT INTO order_menu (order_id, menu_id, quantity)
VALUES (LAST_INSERT_ID(), 1, 1);
INSERT INTO order_option (order_menu_id, option_detail_id)
VALUES (LAST_INSERT_ID(), 1);
-- 레스토랑 2의 주문 생성
INSERT INTO `orders` (restaurant_id, contact, address, status, created_at)
VALUES (2, contact_num + day_count * 100 + order_count,
CONCAT('엔터팰리스', order_count + 1, '차'),
'ACCEPTED', DATE_ADD(start_date, INTERVAL day_count DAY));
INSERT INTO order_menu (order_id, menu_id, quantity)
VALUES (LAST_INSERT_ID(), 3, 1);
INSERT INTO order_option (order_menu_id, option_detail_id)
VALUES (LAST_INSERT_ID(), 6);
-- 레스토랑 3의 주문 생성
INSERT INTO `orders` (restaurant_id, contact, address, status, created_at)
VALUES (3, contact_num + day_count * 100 + order_count,
CONCAT('엔터팰리스', order_count + 1, '차'),
'ACCEPTED', DATE_ADD(start_date, INTERVAL day_count DAY));
INSERT INTO order_menu (order_id, menu_id, quantity)
VALUES (LAST_INSERT_ID(), 5, 1);
INSERT INTO order_option (order_menu_id, option_detail_id)
VALUES (LAST_INSERT_ID(), 10);
SET order_count = order_count + 1;
END WHILE;
SET day_count = day_count + 1;
END WHILE;
END //
프로시저를 실행한 후 애플리케이션에서 호출하여 데이터를 삽입했다.
@Slf4j
@Profile("!prod")
@RequiredArgsConstructor
@Configuration
public class NotProd {
@Autowired
private JdbcTemplate jdbcTemplate;
private final OrderRepository orderRepository;
@Bean
public ApplicationRunner initNotProd() {
return args -> {
if (orderRepository.existsById(1L)) {
System.out.println("Data already exists in the database, skipping insertion.");
return;
}
try {
jdbcTemplate.execute("CALL InsertOrderData();");
DateTimeFormatter formatter = DateTimeFormatter.ofPattern("yyyy-MM-dd HH:mm:ss");
LocalDateTime now = LocalDateTime.now();
System.out.println("Data initialized in database at " + now.format(formatter));
} catch (Exception e) {
e.printStackTrace();
}
};
}
}페이징 구현
1. 오프셋 기반 페이지네이션
페이지 번호와 페이지 크기를 기반으로 데이터를 가져오는 방식
대량의 데이터를 다룰 경우 성능 저하가 발생할 수 있다.
페이지를 요청하는 도중에 데이터의 변화가 있으면 중복 데이터가 발생할 수 있다.
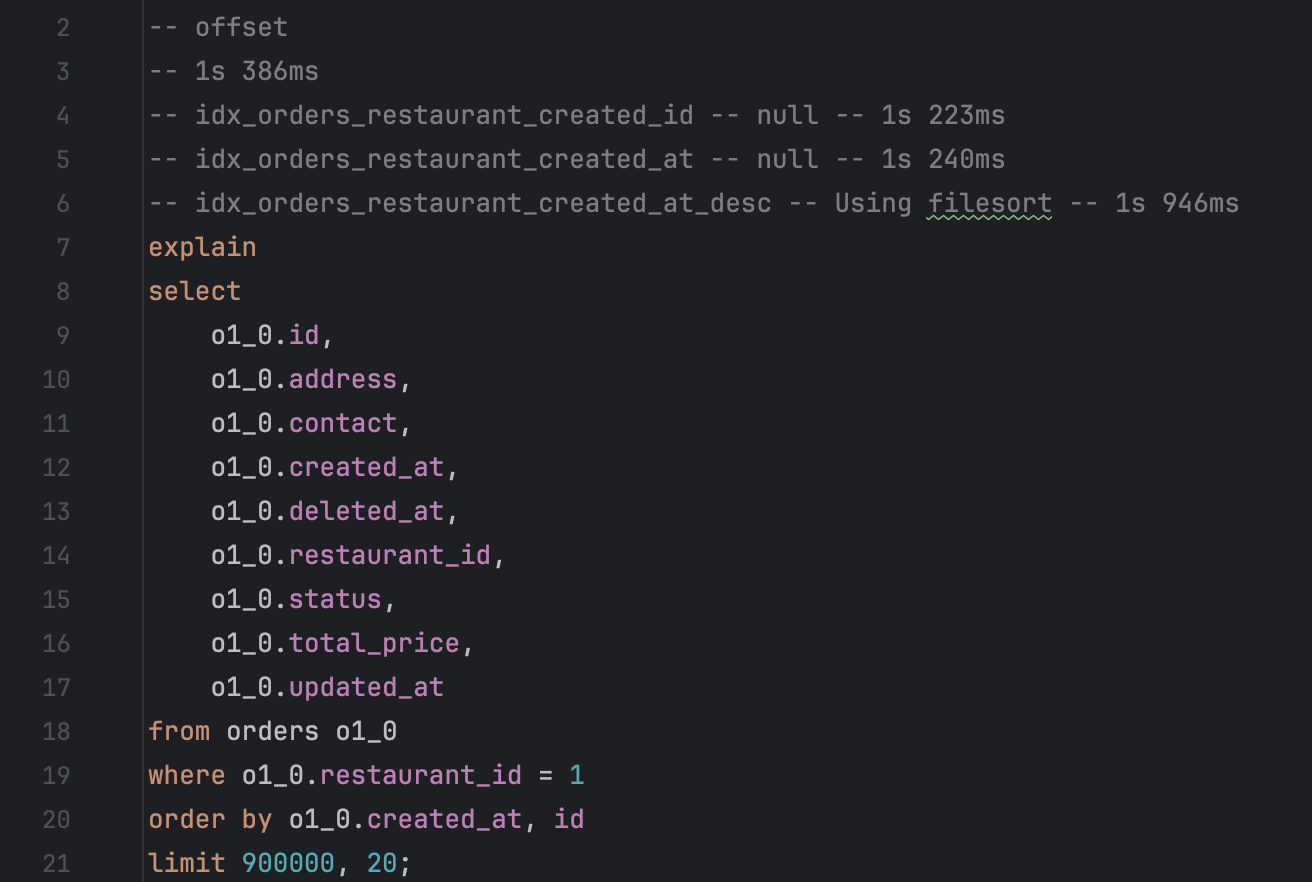
select
o1_0.id,
o1_0.address,
o1_0.contact,
o1_0.created_at,
o1_0.deleted_at,
o1_0.restaurant_id,
o1_0.status,
o1_0.total_price,
o1_0.updated_at
from orders o1_0
where o1_0.restaurant_id=1
order by o1_0.id desc
limit 900000, 20;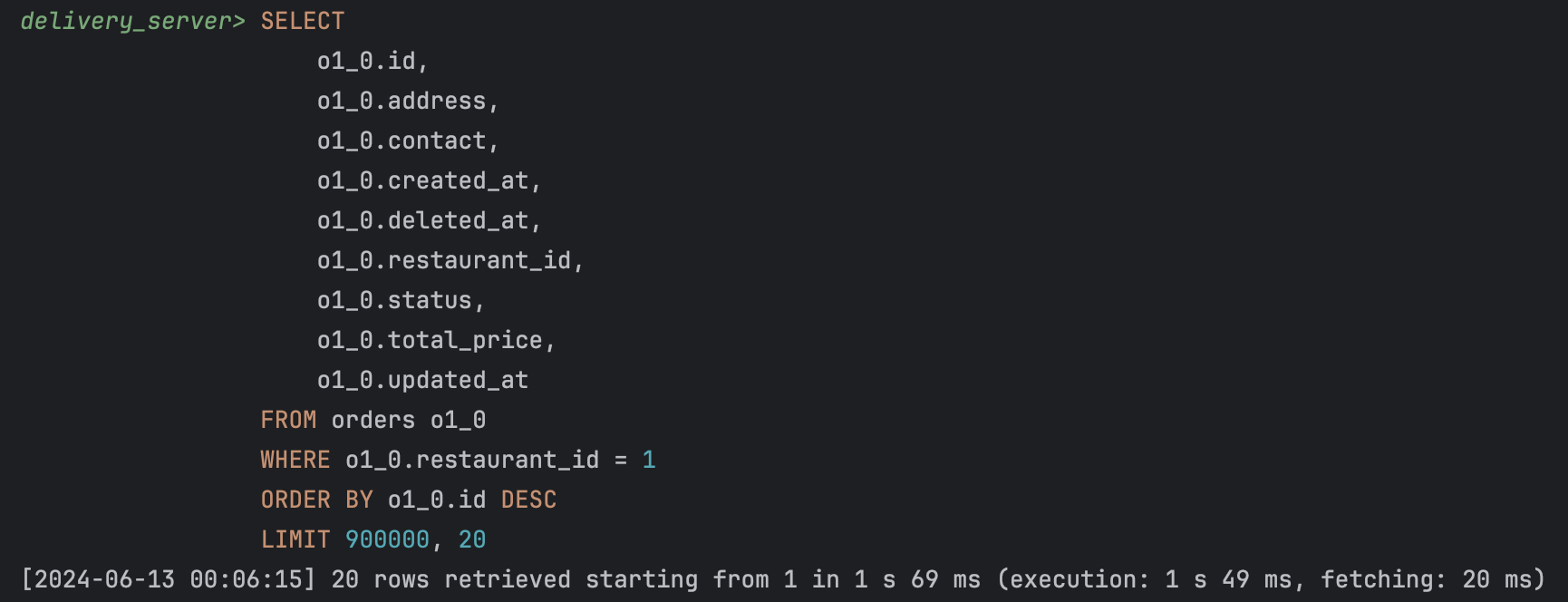
90만번째 데이터에서부터 20개의 데이터를 출력하는 데 1s 69ms 소요되었다.
2. 커서 기반 페이지네이션
마지막으로 가져온 데이터의 키를 기준으로 다음 데이터를 가져오는 방식
대량의 데이터를 다룰 때도 성능 저하가 적다.
기준이 있기 때문에 1페이지에서 바로 5페이지로 뛰어 넘어갈 수 없다.
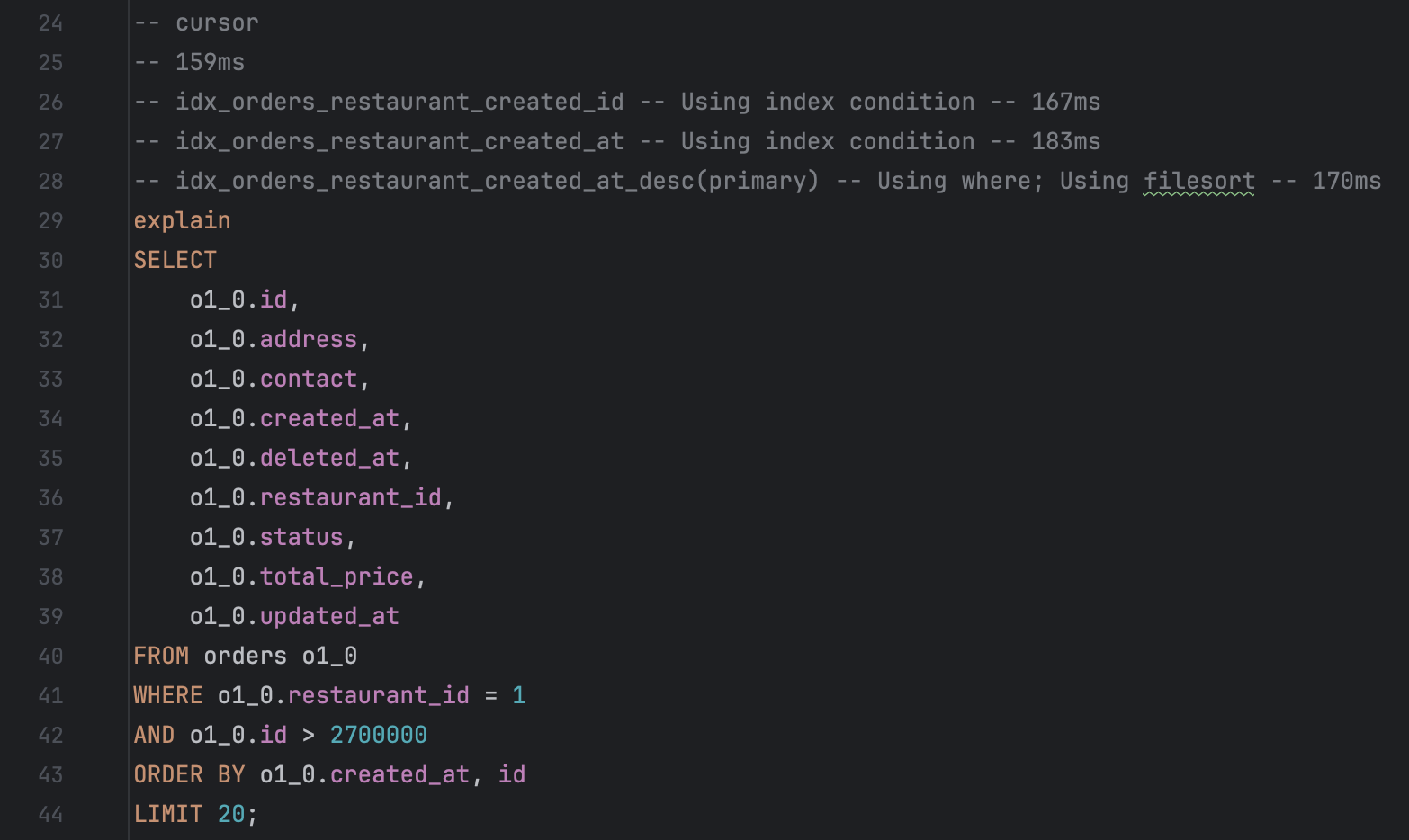
SELECT
o1_0.id,
o1_0.address,
o1_0.contact,
o1_0.created_at,
o1_0.deleted_at,
o1_0.restaurant_id,
o1_0.status,
o1_0.total_price,
o1_0.updated_at
FROM orders o1_0
WHERE o1_0.restaurant_id = 1
AND o1_0.id > 2700000
ORDER BY o1_0.id
LIMIT 20;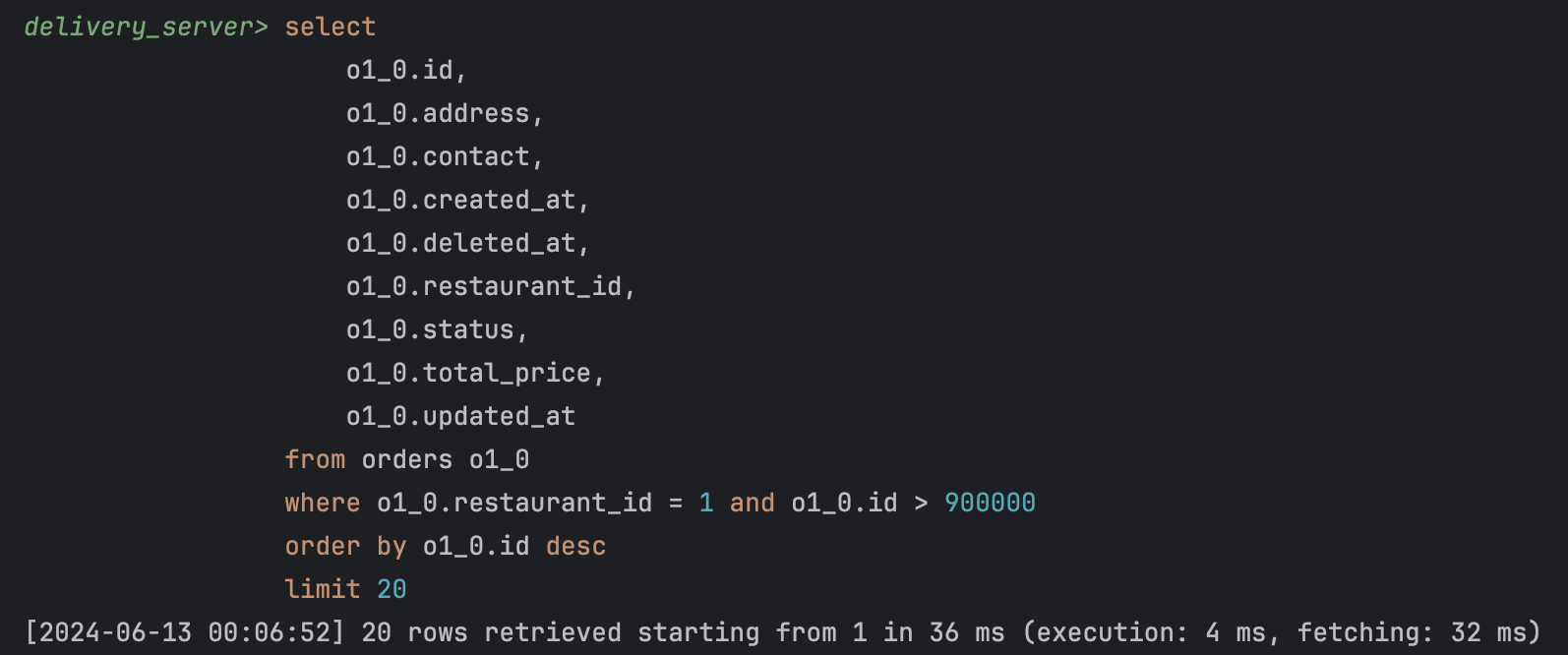
90만번째 데이터에서부터 20개의 데이터를 출력하는 데 36ms 소요되었다.
대량의 데이터를 다루기에 적합한 커서 기반 페이지네이션 방식을 적용했다.
주문 일자별 확인
1. 오프셋 기반 페이지네이션
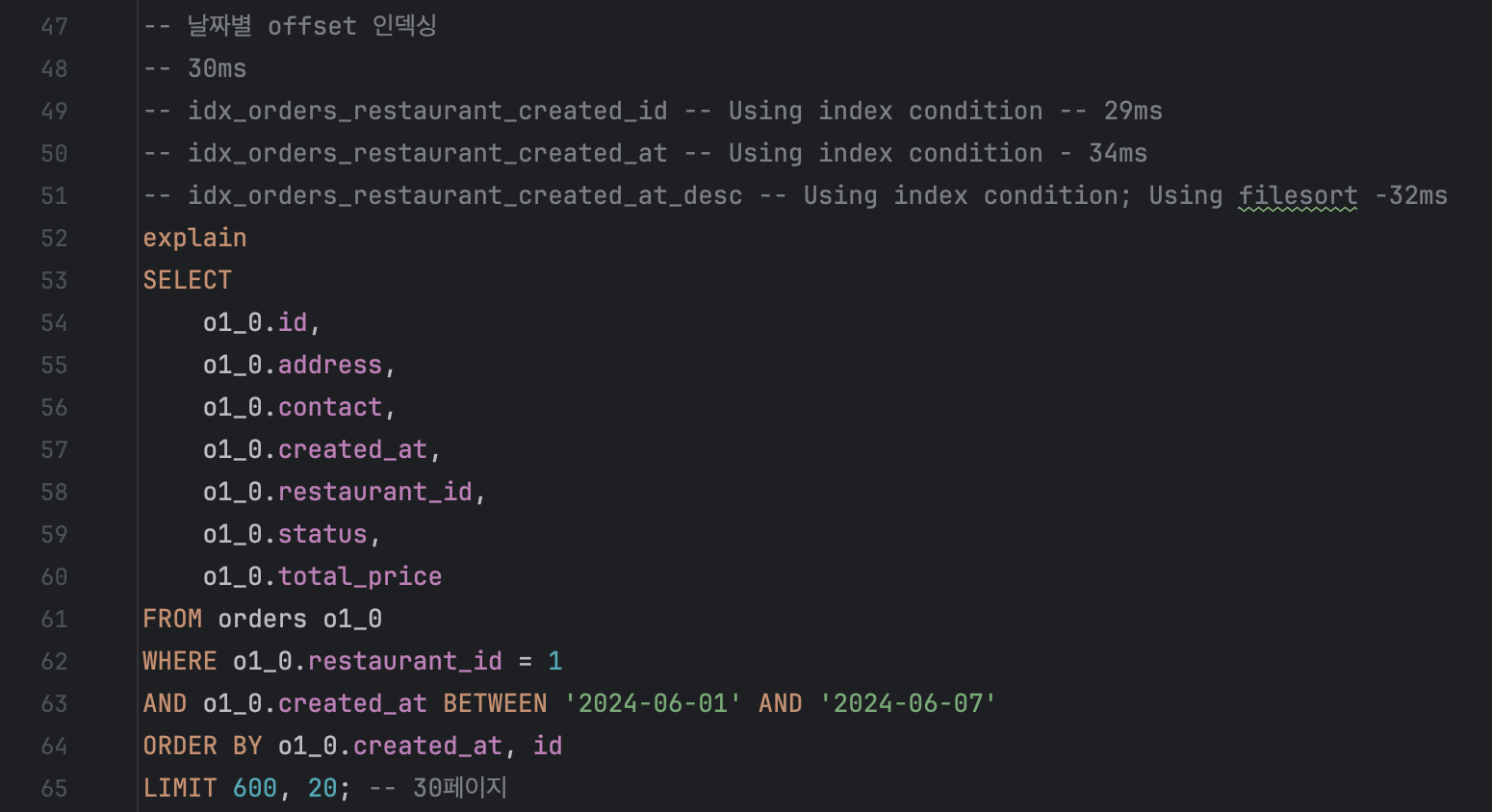
SELECT
o1_0.id,
o1_0.address,
o1_0.contact,
o1_0.created_at,
o1_0.restaurant_id,
o1_0.status,
o1_0.total_price
FROM orders o1_0
WHERE o1_0.restaurant_id = 1
AND o1_0.created_at BETWEEN '2024-06-01' AND '2024-06-07'
ORDER BY o1_0.id DESC
LIMIT 600, 20;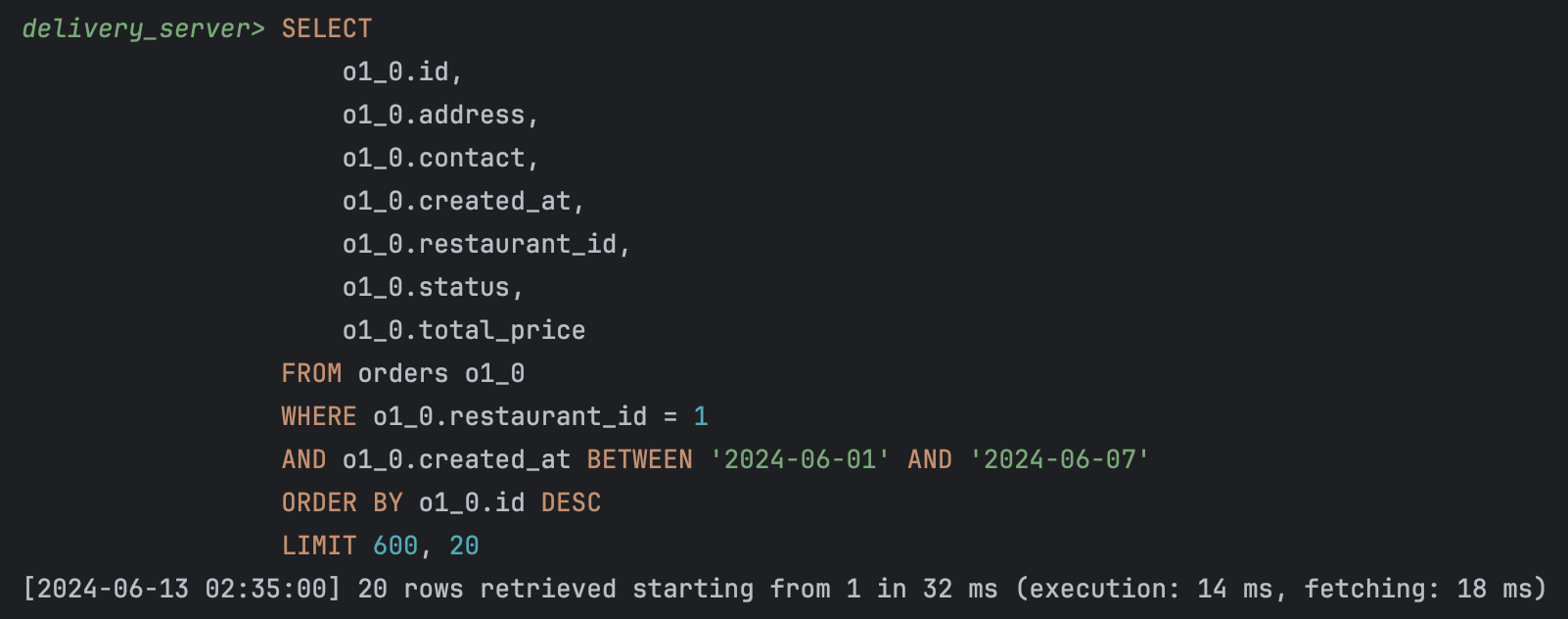
첫 600개의 레코드를 건너뛰고, 그 다음 20개의 레코드를 출력하는 데 32ms 소요되었다.
2. 커서 기반 페이지네이션
SELECT
o1_0.id,
o1_0.address,
o1_0.contact,
o1_0.created_at,
o1_0.restaurant_id,
o1_0.status,
o1_0.total_price
FROM orders o1_0
USE INDEX (idx_orders_restaurant_created_id)
WHERE o1_0.restaurant_id = 1
AND o1_0.created_at BETWEEN '2024-06-01' AND '2024-06-07'
AND o1_0.id > 3005700
ORDER BY o1_0.id DESC
LIMIT 20;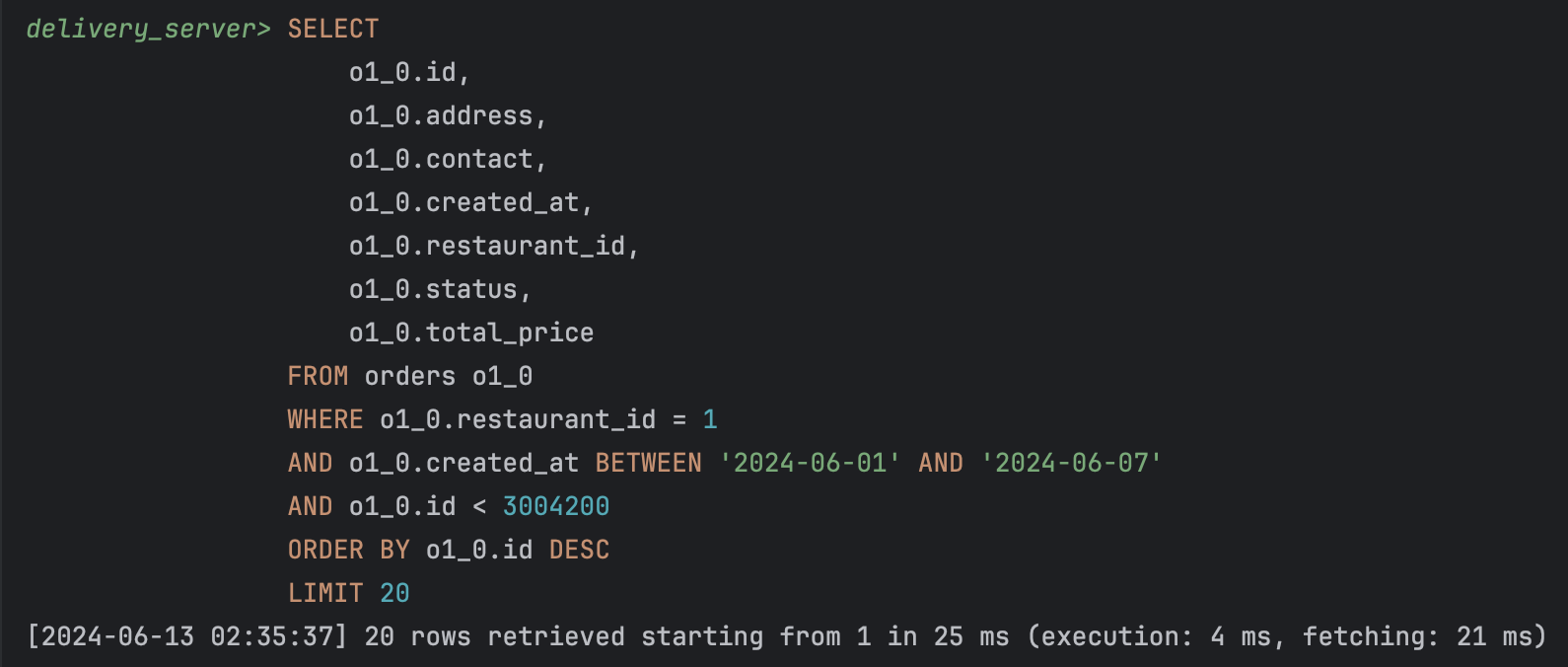
id보다 작은 레코드를 가져와서 다음 페이지를 반환하는 데 25ms 소요되었다.
인덱싱
좋은 Index 설정 기준
카디널리티가 높을 수록 좋다, 선택도가 낮을 수록 좋다.
- 중복도가 낮아 값들이 대부분 다른 값을 가짐
조회 활용도가 높을 수록 좋다.
- 실제 작업에서의 활용도가 높을 수록 좋다.
데이터 삽입, 수정, 삭제 빈도가 낮을 수록 좋다.
- 데이터가 삽입, 수정, 삭제되면 인덱스 테이블도 갱신되어야 한다.
- LIKE와 사용할 경우에는 %를 뒤에 사용 (앞에 사용되면 Full Scan)
- JOIN, WHERE, ORDER BY에 자주 사용되는 컬럼에 사용
새로운 데이터가 추가되면 인덱싱 된 컬럼의 테이블이 수정되어야 하기 때문에 INSERT의 경우 효율이 좋지 않다.
테이블에 인덱스가 많을수록 삽입 시 업데이트해야 하는 인덱스의 수가 많아지기 때문에 삽입 성능이 저하될 수 있다.
다중 조건 검색, 범위 검색, 정렬을 사용할 경우 복합 인덱스를 사용하면 효율적이다.
--> 인덱스 최소화, 복합 인덱스 사용
Clustered Index
Non-Clustered Index
찾아보기
EXPLAIN
possible_keys
쿼리에서 사용할 수 있는 인덱스의 목록
key
실제로 사용된 인덱스
filtered
인덱스를 사용한 조건. 낮을수록 많은 데이터가 필터링 되었다는 의미
인덱스가 얼마나 효율적으로 조건을 만족하는 데이터를 걸러내는지 판단
Extra
null: 인덱스 사용이 불필요한 경우, 특별한 조치가 필요 없는 경우, 쿼리가 매우 간단한 경우, 최적화가 잘 되어있는 경우
Using index: 인덱스만으로 필요한 데이터를 모두 검색할 수 있음 - 효율적
Using where: 인덱스를 사용하지 않고 WHERE 조건으로 행을 필터링 - 비효율적
Using filesort: 데이터가 메모리가 아닌 디스크에 정렬되어야 함 - 성능 저하
인덱스 설정 후 오프셋 기반 페이지네이션
날짜별 오프셋 기반 페이지네이션
인덱스 설정 후 커서 기반 페이지네이션
날짜별 커서 기반 페이지네이션
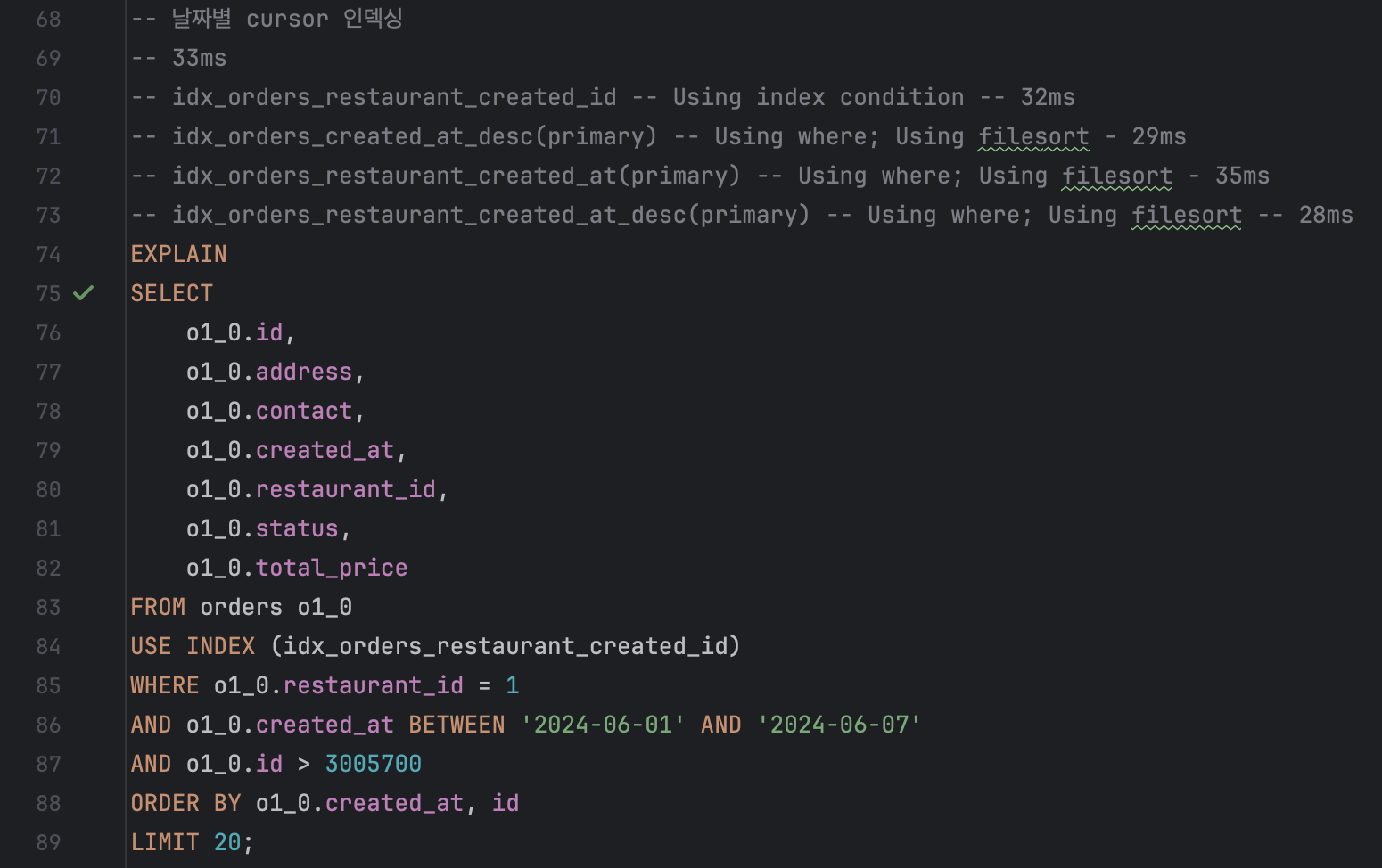
인덱스를 적용하지 않았을 때와 적용했을 때의 뚜렷한 차이가 없다..
단일 인덱스, 복합인덱스, 인덱스의 순서, 정렬을 재설정하고 실행해보았지만 설정 전 후 별 차이가 없었다.
참고
페이징
왜 오프셋 페이징보다 커서 페이징일까?
Spring Data JPA의 Page와 Slice
[QueryDsl] Page, Slice (페이지네이션, 무한 스크롤)
도메인 모델 패턴
트랜잭션 스크립트 패턴 vs 도메인 모델 패턴
